Releases: huggingface/transformers
Patch release v4.39.2
Patch release v4.39.1
Release v4.39.0
v4.39.0
🚨 VRAM consumption 🚨
The Llama, Cohere and the Gemma model both no longer cache the triangular causal mask unless static cache is used. This was reverted by #29753, which fixes the BC issues w.r.t speed , and memory consumption, while still supporting compile and static cache. Small note, fx is not supported for both models, a patch will be brought very soon!
New model addition
Cohere open-source model
Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with Cohere's industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
- Strong accuracy on RAG and Tool Use
- Low latency, and high throughput
- Longer 128k context and lower pricing
- Strong capabilities across 10 key languages
- Model weights available on HuggingFace for research and evaluation
- Cohere Model Release by @saurabhdash2512 in #29622
LLaVA-NeXT (llava v1.6)
Llava next is the next version of Llava, which includes better support for non padded images, improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications.
- Better world knowledge and logical reasoning.
- Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s.*
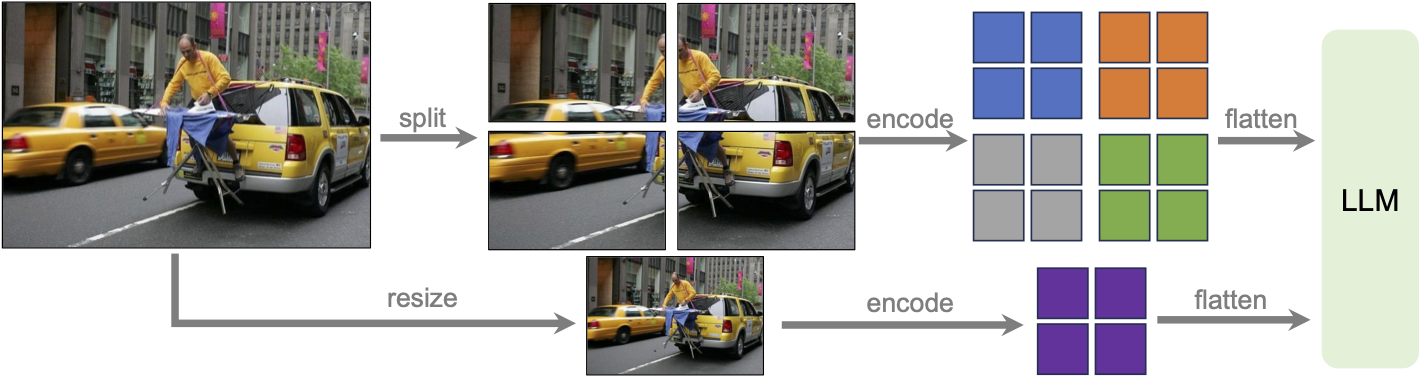
LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
MusicGen Melody
The MusicGen Melody model was proposed in Simple and Controllable Music Generation by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or audio codes, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
PvT-v2
The PVTv2 model was proposed in PVT v2: Improved Baselines with Pyramid Vision Transformer by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
- Add PvT-v2 Model by @FoamoftheSea in #26812
UDOP
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
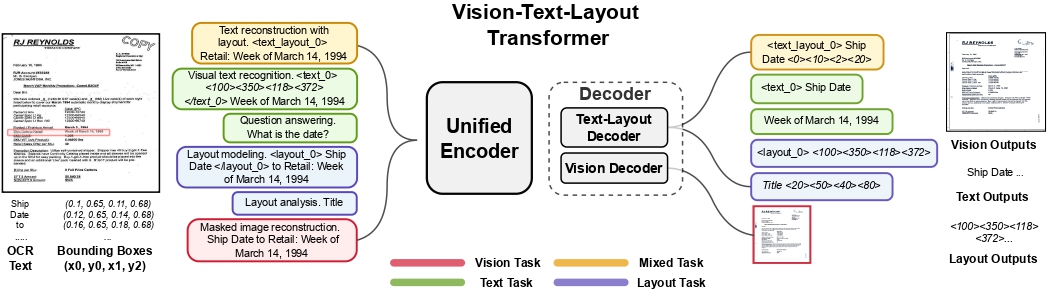
UDOP architecture. Taken from the original paper.
- Add UDOP by @NielsRogge in #22940
Mamba
This model is a new paradigm architecture based on state-space-models, rather than attention like transformer models.
The checkpoints are compatible with the original ones
- [
Add Mamba] Adds support for theMambamodels by @ArthurZucker in #28094
StarCoder2
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
- Starcoder2 model - bis by @RaymondLi0 in #29215
SegGPT
The SegGPT model was proposed in SegGPT: Segmenting Everything In Context by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
- Adding SegGPT by @EduardoPach in #27735
Galore optimizer

With Galore, you can pre-train large models on consumer-type hardwares, making LLM pre-training much more accessible to anyone from the community.
Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Galore is based on low rank approximation of the gradients and can be used out of the box for any model.
Below is a simple snippet that demonstrates how to pre-train mistralai/Mistral-7B-v0.1 on imdb:
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()Quantization
Quanto integration
Quanto has been integrated with transformers ! You can apply simple quantization algorithms with few lines of code with tiny changes. Quanto is also compatible with torch.compile
Check out the announcement blogpost for more details
Exllama 🤝 AWQ
Exllama and AWQ combined together for faster AWQ inference - check out the relevant documentation section for more details on how to use Exllama + AWQ.
- Exllama kernels support for AWQ models by @IlyasMoutawwakil in #28634
MLX Support
Allow models saved or fine-tuned with Apple’s MLX framework to be loaded in transformers (as long as the model parameters use the same names), and improve tensor interoperability. This leverages MLX's adoption of safetensors as their checkpoint format.
- Add mlx support to BatchEncoding.convert_to_tensors by @Y4hL in #29406
- Add support for metadata format MLX by @alexweberk in #29335
- Typo in mlx tensor support by @pcuenca in #29509
- Experimental loading of MLX files by @pcuenca in #29511
Highligted improvements
Notable memory reduction in Gemma/LLaMa by changing the causal mask buffer type from int64 to boolean.
Remote code improvements
- Allow remote code repo names to contain "." by @Rocketknight1 in #29175
- simplify get_class_in_m...
Contributors
Assets 2
v4.38.2
Fix backward compatibility issues with Llama and Gemma:
We mostly made sure that performances are not affected by the new change of paradigm with ROPE. Fixed the ROPE computation (should always be in float32) and the causal_mask dtype was set to bool to take less RAM.
YOLOS had a regression, and Llama / T5Tokenizer had a warning popping for random reasons
- FIX [Gemma] Fix bad rebase with transformers main (#29170)
- Improve _update_causal_mask performance (#29210)
- [T5 and Llama Tokenizer] remove warning (#29346)
- [Llama ROPE] Fix torch export but also slow downs in forward (#29198)
- RoPE loses precision for Llama / Gemma + Gemma logits.float() (#29285)
- Patch YOLOS and others (#29353)
- Use torch.bool instead of torch.int64 for non-persistant causal mask buffer (#29241)
v4.38.1
Fix eager attention in Gemma!
- [Gemma] Fix eager attention #29187 by @sanchit-gandhi
TLDR:
- attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ attn_output = attn_output.view(bsz, q_len, -1)Contributors
Assets 2
v4.38: Gemma, Depth Anything, Stable LM; Static Cache, HF Quantizer, AQLM
New model additions
💎 Gemma 💎
Gemma is a new opensource Language Model series from Google AI that comes with a 2B and 7B variant. The release comes with the pre-trained and instruction fine-tuned versions and you can use them via AutoModelForCausalLM, GemmaForCausalLM or pipeline interface!
Read more about it in the Gemma release blogpost: https://hf.co/blog/gemma
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto", torch_dtype=torch.float16)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)You can use the model with Flash Attention, SDPA, Static cache and quantization API for further optimizations !
- Flash Attention 2
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto", torch_dtype=torch.float16, attn_implementation="flash_attention_2"
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)- bitsandbytes-4bit
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto", load_in_4bit=True
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)- Static Cache
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b", device_map="auto"
)
model.generation_config.cache_implementation = "static"
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)Depth Anything Model
The Depth Anything model was proposed in Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data by Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao. Depth Anything is based on the DPT architecture, trained on ~62 million images, obtaining state-of-the-art results for both relative and absolute depth estimation.

- Add Depth Anything by @NielsRogge in #28654
Stable LM
StableLM 3B 4E1T was proposed in StableLM 3B 4E1T: Technical Report by Stability AI and is the first model in a series of multi-epoch pre-trained language models.
StableLM 3B 4E1T is a decoder-only base language model pre-trained on 1 trillion tokens of diverse English and code datasets for four epochs. The model architecture is transformer-based with partial Rotary Position Embeddings, SwiGLU activation, LayerNorm, etc.
The team also provides StableLM Zephyr 3B, an instruction fine-tuned version of the model that can be used for chat-based applications.
⚡️ Static cache was introduced in the following PRs ⚡️
Static past key value cache allows LlamaForCausalLM' s forward pass to be compiled using torch.compile !
This means that (cuda) graphs can be used for inference, which speeds up the decoding step by 4x!
A forward pass of Llama2 7B takes around 10.5 ms to run with this on an A100! Equivalent to TGI performances! ⚡️
- [
Core generation] Adds support for static KV cache by @ArthurZucker in #27931 - [
CLeanup] Revert SDPA attention changes that got in the static kv cache PR by @ArthurZucker in #29027 - Fix static generation when compiling! by @ArthurZucker in #28937
- Static Cache: load models with MQA or GQA by @gante in #28975
- Fix symbolic_trace with kv cache by @fxmarty in #28724
generate is not included yet. This feature is experimental and subject to changes in subsequent releases.
from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
import torch
import os
# compilation triggers multiprocessing
os.environ["TOKENIZERS_PARALLELISM"] = "true"
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
device_map="auto",
torch_dtype=torch.float16
)
# set up the static cache in advance of using the model
model._setup_cache(StaticCache, max_batch_size=1, max_cache_len=128)
# trigger compilation!
compiled_model = torch.compile(model, mode="reduce-overhead", fullgraph=True)
# run the model as usual
input_text = "A few facts about the universe: "
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda").input_ids
model_outputs = compiled_model(input_ids)Quantization
🧼 HF Quantizer 🧼
HfQuantizer makes it easy for quantization method researchers and developers to add inference and / or quantization support in 🤗 transformers. If you are interested in adding the support for new methods, please refer to this documentation page: https://huggingface.co/docs/transformers/main/en/hf_quantizer
HfQuantizerclass for quantization-related stuff inmodeling_utils.pyby @poedator in #26610- [
HfQuantizer] Move it to "Developper guides" by @younesbelkada in #28768 - [
HFQuantizer] Removecheck_packages_compatibilitylogic by @younesbelkada in #28789 - [docs] HfQuantizer by @stevhliu in #28820
⚡️AQLM ⚡️
AQLM is a new quantization method that enables no-performance degradation in 2-bit precision. Check out this demo about how to run Mixtral in 2-bit on a free-tier Google Colab instance: https://huggingface.co/posts/ybelkada/434200761252287
- AQLM quantizer support by @BlackSamorez in #28928
- Removed obsolete attribute setting for AQLM quantization. by @BlackSamorez in #29034
🧼 Moving canonical repositories 🧼
The canonical repositories on the hugging face hub (models that did not have an organization, like bert-base-cased), have been moved under organizations.
You can find the entire list of models moved here: https://huggingface.co/collections/julien-c/canonical-models-65ae66e29d5b422218567567
Redirection has been set up so that your code continues working even if you continue calling the previous paths. We, however, still encourage you to update your code to use the new links so that it is entirely future proof.
- canonical repos moves by @julien-c in #28795
- Update all references to canonical models by @LysandreJik in #29001
Flax Improvements 🚀
The Mistral model was added to the library in Flax.
- Flax mistral by @kiansierra in #26943
TensorFlow Improvements 🚀
With Keras 3 becoming the standard version of Keras in TensorFlow 2.16, we've made some internal changes to maintain compatibility. We now have full compatibility with TF 2.16 as long as the tf-keras compatibility package is installed. We've also taken the opportunity to do some cleanup - in particular, the objects like BatchEncoding that are returned by our tokenizers and processors can now be directly passed to Keras methods like model.fit(), which should simplify a lot of code and eliminate a long-standing source of annoyances.
- Add tf_keras imports to prepare for Keras 3 by @Rocketknight1 in #28588
- Wrap Keras methods to support BatchEncoding by @Rocketknight1 in #28734
- Fix Keras scheduler import so it works for older versions of Keras by @Rocketknight1 in #28895
Pre-Trained backbone weights 🚀
Enable loading in pretrained backbones in a new model, where all other weights are randomly initialized. Note: validation checks are still in place when creating a config. Passing in use_pretrained_backbone will raise an error. You can override by setting
config.use_pretrained_backbone = True after creating a config. However, it is not yet guaranteed to be fully backwards compatible.
from transformers import MaskFormerConfig, MaskFormerModel
config = MaskFormerConfig(
use_pretrained_backbone=False,
backbone="microsoft/resnet-18"
)
config.use_pretrained_backbone = True
# Both models have resnet-18 backbone weights and all other weights randomly
# initialized
model_1 = MaskFormerModel(config)
model_2 = MaskFormerModel(config)- Enable instantiating model with pretrained backbone weights by @amyeroberts in #28214
Introduce a helper function load_backbone to load a backbone from a backbone's model config e.g. ResNetConfig, or from a model config which contains backbone information. This enables cleaner modeling files and crossloading between timm and transformers backbones.
from transformers import ResNetConfig, MaskFormerConfig
from transformers.utils.backbone_utils import load_backbone
# Resnet defines the backbone model to load
config = ResNetConfig()
backbone = load_backbone(config)
# Maskformer config defines a model which uses a resnet backbone
config = MaskFormerConfig(use_timm_backbone=True, backbone="resnet18")
backbone = load_backbone(config)
config = MaskFormerConfig(backbone_config=ResNetConfig())
backbone = load_backbone(config)- [
Backbone] Use `load_backbone...
Contributors
Assets 2
Patch release v4.37.2
Selection of fixes
- Protecting the imports for SigLIP's tokenizer if sentencepiece isn't installed
- Fix permissions issue on windows machines when using trainer in multi-node setup
- Allow disabling safe serialization when using Trainer. Needed for Neuron SDK
- Fix error when loading processor from cache
- torch < 1.13 compatible
torch.load
Commits
- [Siglip] protect from imports if sentencepiece not installed (#28737)
- Fix weights_only (#28725)
- Enable safetensors conversion from PyTorch to other frameworks without the torch requirement (#27599)
- Don't fail when LocalEntryNotFoundError during processor_config.json loading (#28709)
- Use save_safetensor to disable safe serialization for XLA (#28669)
- Fix windows err with checkpoint race conditions (#28637)
- [SigLIP] Only import tokenizer if sentencepiece available (#28636)
Patch release: v4.37.1
A patch release to resolve import errors from removed custom types in generation utils
- Add back in generation types #28681
v4.37 Qwen2, Phi-2, SigLIP, ViP-LLaVA, Fast2SpeechConformer, 4-bit serialization, Whisper longform generation
Model releases
Qwen2
Qwen2 is the new model series of large language models from the Qwen team. Previously, the Qwen series was released, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Qwen2 is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. It is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
- Add qwen2 by @JustinLin610 in #28436
Phi-2
Phi-2 is a transformer language model trained by Microsoft with exceptionally strong performance for its small size of 2.7 billion parameters. It was previously available as a custom code model, but has now been fully integrated into transformers.
- [Phi2] Add support for phi2 models by @susnato in #28211
- [Phi] Extend implementation to use GQA/MQA. by @gugarosa in #28163
- update docs to add the
phi-2example by @susnato in #28392 - Fixes default value of
softmax_scaleinPhiFlashAttention2. by @gugarosa in #28537
SigLIP
The SigLIP model was proposed in Sigmoid Loss for Language Image Pre-Training by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
- Add SigLIP by @NielsRogge in #26522
- [SigLIP] Don't pad by default by @NielsRogge in #28578
ViP-LLaVA
The VipLlava model was proposed in Making Large Multimodal Models Understand Arbitrary Visual Prompts by Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee.
VipLlava enhances the training protocol of Llava by marking images and interact with the model using natural cues like a “red bounding box” or “pointed arrow” during training.
- Adds VIP-llava to transformers by @younesbelkada in #27932
- Fix Vip-llava docs by @younesbelkada in #28085
FastSpeech2Conformer
The FastSpeech2Conformer model was proposed with the paper Recent Developments On Espnet Toolkit Boosted By Conformer by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
FastSpeech 2 is a non-autoregressive model for text-to-speech (TTS) synthesis, which develops upon FastSpeech, showing improvements in training speed, inference speed and voice quality. It consists of a variance adapter; duration, energy and pitch predictor and waveform and mel-spectrogram decoder.
- Add FastSpeech2Conformer by @connor-henderson in #23439
Wav2Vec2-BERT
The Wav2Vec2-BERT model was proposed in Seamless: Multilingual Expressive and Streaming Speech Translation by the Seamless Communication team from Meta AI.
This model was pre-trained on 4.5M hours of unlabeled audio data covering more than 143 languages. It requires finetuning to be used for downstream tasks such as Automatic Speech Recognition (ASR), or Audio Classification.
- Add new meta w2v2-conformer BERT-like model by @ylacombe in #28165
- Add w2v2bert to pipeline by @ylacombe in #28585
4-bit serialization
Enables saving and loading transformers models in 4bit formats - you can now push bitsandbytes 4-bit weights on Hugging Face Hub. To save 4-bit models and push them on the hub, simply install the latest bitsandbytes package from pypi pip install -U bitsandbytes, load your model in 4-bit precision and call save_pretrained / push_to_hub. An example repo here
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
model.push_to_hub("ybelkada/opt-125m-bnb-4bit")- [bnb] Let's make serialization of 4bit models possible by @poedator in #26037
- [
Docs] Add 4-bit serialization docs by @younesbelkada in #28182
4D Attention mask
Enable passing in 4D attention masks to models that support it. This is useful for reducing memory footprint of certain generation tasks.
Improved quantization support
Ability to customise which modules are quantized and which are not.
- [
Awq] Enable the possibility to skip quantization for some target modules by @younesbelkada in #27950 - add
modules_in_block_to_quantizearg in GPTQconfig by @SunMarc in #27956
Added fused modules support
- [docs] Fused AWQ modules by @stevhliu in #27896
- [
Awq] Add llava fused modules support by @younesbelkada in #28239 - [
Mixtral/Awq] Add mixtral fused modules for Awq by @younesbelkada in #28240
SDPA Support for LLaVa, Mixtral, Mistral
- Fix SDPA correctness following torch==2.1.2 regression by @fxmarty in #27973
- [
Llava/Vip-Llava] Add SDPA into llava by @younesbelkada in #28107 - [
Mixtral&Mistral] Add support for sdpa by @ArthurZucker in #28133 - [SDPA] Make sure attn mask creation is always done on CPU by @patrickvonplaten in #28400
- Fix SDPA tests by @fxmarty in #28552
Whisper: Batched state-of-the-art long-form transcription
All decoding strategies (temperature fallback, compression/log-prob/no-speech threshold, ...) of OpenAI's long-form transcription (see: https://github.com/openai/whisper or section 4.5 in paper) have been added. Contrary to https://github.com/openai/whisper, Transformers long-form transcription is fully compatible with pure FP16 and Batching!
For more information see: #27658.
- [Whisper] Finalize batched SOTA long-form generation by @patrickvonplaten in #27658
Generation: assisted generation upgrades, speculative decoding, and ngram speculation
Assisted generation was reworked to accept arbitrary sources of candidate sequences. This enabled us to smoothly integrate ngram speculation, and opens the door for new candidate generation methods. Additionally, we've added the speculative decoding strategy on top of assisted generation: when you call assisted generation with an assistant model and do_sample=True, you'll benefit from the faster speculative decoding sampling 🏎️💨
- Generate:
assisted_decodingnow accepts arbitrary candidate generators by @gante in #27751 - Generate: assisted decoding now uses
generatefor the assistant by @gante in #28031 - Generate: speculative decoding by @gante in #27979
- Generate: fix speculative decoding by @gante in #28166
- Adding Prompt lookup decoding by @apoorvumang in #27775
- Fix _speculative_sampling implementation by @ofirzaf in #28508
torch.load pickle protection
Adding pickle protection via weights_only=True in the torch.load calls.
Build methods for TensorFlow Models
Unlike PyTorch, TensorFlow models build their weights "lazily" after model initialization, using the shape of their inputs to figure out what their weight shapes should be. We previously needed a full forward pass through TF models to ensure that all layers received an input they could use to build their weights, but with this change we now have proper build() methods that can correctly infer shapes and build model weights. This avoids a whole range of potential issues, as well as significantly accelerating model load times.
- Proper build() methods for TF by @Rocketknight1 in #27794
- Replace build() with build_in_name_scope() for some TF tests by @Rocketknight1 in #28046
- More TF fixes by @Rocketknight1 in #28081
- Even more TF test fixes by @Rocketknight1 in #28146
Remove support for torch 1.10
The last version to support PyTorch 1.10 was 4.36.x. As it has been more than 2 years, and we're looking forward to using features available in PyTorch 1.11 and up, we do not support PyTorch 1.10 for v4.37 (i.e. we don't run the tests against torch 1.10).
Model tagging
You can now add custom tags into your model before pushing it on the Hub! This enables you to filter models that contain that tag on the Hub with a simple URL filter. For example if you want to filter models that have trl tag you can search: https://huggingface.co/models?other=trl&sort=created
- [
core/ FEAT] Add the possibility to push custom tags usingPreTrainedModelitself by @younesbelkada in #28405 - e.g.
from transformers import AutoModelForCausalLM
model_name = "HuggingFaceM4/tiny-random-LlamaForCausalLM"
model = AutoModelForCausalLM.from_pretrained(model_name)
model.add_model_tags(["tag-test"])
model.push_to_hub("llama-tagged")Bugfixes and improvements
- Fix PatchTSMixer Docstrings by @vijaye12 in #27943
- use logger.warning_once to avoid massive outputs by @ranchlai in #27428
- Docs for AutoBackbone & Backbone by @merveenoyan in #27456
- Fix test for auto_find_batch_size on multi-GPU by @muellerzr in #27947
- Update import message by @NielsRogge in #27946
- Fix parameter count in readme for mixtral 45b by @CyberTimon in #27945
- In PreTrainedTokenizerBase add missing word in error message by @petergtz in #27949
- Fix AMD scheduled CI not triggered by @ydshieh in #27951
- Add deepspeed test to amd scheduled CI by @echarlaix in #27633
- Fix a couple of typos and add an illustrative test by @rjenc29 in #26941
...
Contributors
Assets 2
Patch release: v4.36.2
Patch release to resolve some critical issues relating to the recent cache refactor, flash attention refactor and training in the multi-gpu and multi-node settings:
- Resolve training bug with PEFT + GC #28031
- Resolve cache issue when going beyond context window for Mistral/Mixtral FA2 #28037
- Re-enable passing
configtofrom_pretrainedwith FA #28043 - Fix resuming from checkpoint when using FDSP with FULL_STATE_DICT #27891
- Resolve bug when saving a checkpoint in the multi-node setting #28078