Releases: huggingface/transformers
Patch release: v4.36.1
v4.36: Mixtral, Llava/BakLlava, SeamlessM4T v2, AMD ROCm, F.sdpa wide-spread support
New model additions
Mixtral
Mixtral is the new open-source model from Mistral AI announced by the blogpost Mixtral of Experts. The model has been proven to have comparable capabilities to Chat-GPT according to the benchmark results shared on the release blogpost.

The architecture is a sparse Mixture of Experts with Top-2 routing strategy, similar as NllbMoe architecture in transformers. You can use it through AutoModelForCausalLM interface:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B", torch_dtype=torch.float16, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-8x7B")
>>> prompt = "My favourite condiment is"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]The model is compatible with existing optimisation tools such Flash Attention 2, bitsandbytes and PEFT library. The checkpoints are release under mistralai organisation on the Hugging Face Hub.
Llava / BakLlava
Llava is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.

The Llava model was proposed in Improved Baselines with Visual Instruction Tuning by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
- [
Llava] Add Llava to transformers by @younesbelkada in #27662 - [LLaVa] Some improvements by @NielsRogge in #27895
The integration also includes BakLlava which is a Llava model trained with Mistral backbone.
The mode is compatible with "image-to-text" pipeline:
from transformers import pipeline
from PIL import Image
import requests
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "USER: <image>\nWhat does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud\nASSISTANT:"
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs)And you can find all Llava weights under llava-hf organisation on the Hub.
SeamlessM4T v2
SeamlessM4T-v2 is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text. It is an improvement on the previous version and was proposed in Seamless: Multilingual Expressive and Streaming Speech Translation by the Seamless Communication team from Meta AI.
For more details on the differences between v1 and v2, refer to section Difference with SeamlessM4T-v1.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
PatchTST
The PatchTST model was proposed in A Time Series is Worth 64 Words: Long-term Forecasting with Transformers by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
At a high level, the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:

- [Time series] Add PatchTST by @psinthong in #25927
- [Time series] Add PatchTST by @kashif in #27581
PatchTSMixer
The PatchTSMixer model was proposed in TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer’s capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
CLVP
The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in Better speech synthesis through scaling by James Betker.
Phi-1/1.5
The Phi-1 model was proposed in Textbooks Are All You Need by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in Textbooks Are All You Need II: phi-1.5 technical report by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
TVP
The text-visual prompting (TVP) framework was proposed in the paper Text-Visual Prompting for Efficient 2D Temporal Video Grounding by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as ‘prompts’, into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model’s ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
- TVP model by @jiqing-feng in #25856
DINOv2 depth estimation
Depth estimation is added to the DINO v2 implementation.
- Add DINOv2 depth estimation by @NielsRogge in #26092
ROCm support for AMD GPUs
AMD's ROCm GPU architecture is now supported across the board and fully tested in our CI with MI210/MI250 GPUs. We further enable specific hardware acceleration for ROCm in Transformers, such as Flash Attention 2, GPTQ quantization and DeepSpeed.
- Add RoCm scheduled CI & upgrade RoCm CI to PyTorch 2.1 by @fxmarty in #26940
- Flash Attention 2 support for RoCm by @fxmarty in #27611
- Reflect RoCm support in the documentation by @fxmarty in #27636
- restructure AMD scheduled CI by @ydshieh in #27743
PyTorch scaled_dot_product_attention native support
PyTorch's torch.nn.functional.scaled_dot_product_attention operator is now supported in the most-used Transformers models and used by default when using torch>=2.1.1, allowing to dispatch on memory-efficient attention and Flash Attention backend implementations with no other package than torch required. This should significantly speed up attention computation on hardware that that supports these fastpath.
While Transformers automatically handles the dispatch to use SDPA when available, it is possible to force the usage of a given attention implementation ("eager" being the manual implementation, where each operation is implemented [step by step](https://github.com/huggingface/transformers/blob/9f18cc6df0b7e0d50f78b9e9fc...
Contributors
Assets 2
Patch release: v4.35.2
A patch release was made for the following commit:
- [
tokenizers] update tokenizers version pin #27494
to fix all the issues with versioning regarding tokenizers and huggingface_hub
Patch release: v4.35.1
Safetensors serialization by default, DistilWhisper, Fuyu, Kosmos-2, SeamlessM4T, Owl-v2
New models
Distil-Whisper
Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller, and performs within 1% word error rate (WER) on out-of-distribution data. It was proposed in the paper Robust Knowledge Distillation via Large-Scale Pseudo Labelling.
Distil-Whisper copies the entire encoder from Whisper, meaning it retains Whisper's robustness to different audio conditions. It only copies 2 decoder layers, which significantly reduces the time taken to auto-regressively generate text tokens:

Distil-Whisper is MIT licensed and directly available in the Transformers library with chunked long-form inference, Flash Attention 2 support, and Speculative Decoding. For details on using the model, refer to the following instructions.
Joint work from @sanchit-gandhi, @patrickvonplaten and @srush.
- [Assistant Generation] Improve Encoder Decoder by @patrickvonplaten in #26701
- [WhisperForCausalLM] Add WhisperForCausalLM for speculative decoding by @patrickvonplaten in #27195
- [Whisper, Bart, MBart] Add Flash Attention 2 by @patrickvonplaten in #27203
Fuyu
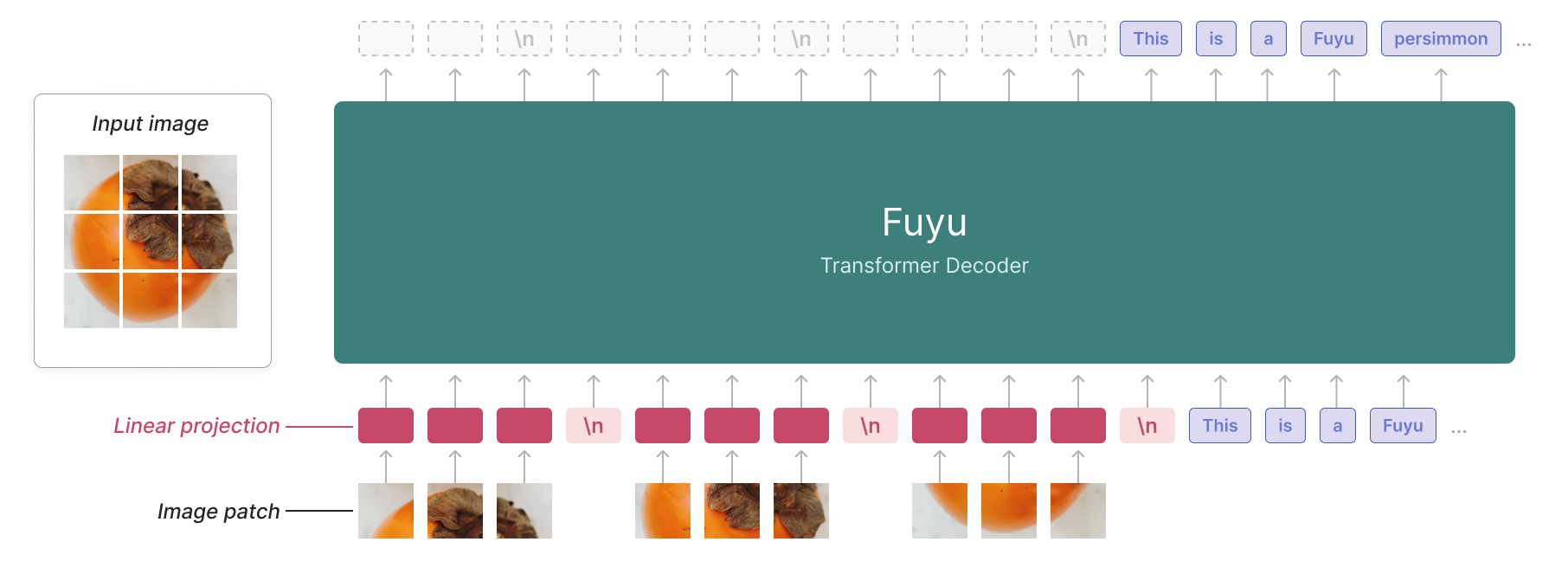
The Fuyu model was created by ADEPT, and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
The authors introduced Fuyu-8B, a decoder-only multimodal model based on the classic transformers architecture, with query and key normalization. A linear encoder is added to create multimodal embeddings from image inputs.
By treating image tokens like text tokens and using a special image-newline character, the model knows when an image line ends. Image positional embeddings are removed. This avoids the need for different training phases for various image resolutions. With 8 billion parameters and licensed under CC-BY-NC, Fuyu-8B is notable for its ability to handle both text and images, its impressive context size of 16K, and its overall performance.
Joint work from @molbap, @pcuenca, @amyeroberts, @ArthurZucker
SeamlessM4T

The SeamlessM4T model was proposed in SeamlessM4T — Massively Multilingual & Multimodal Machine Translation by the Seamless Communication team from Meta AI.
SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
SeamlessM4TModel can perform all the above tasks, but each task also has its own dedicated sub-model.
Kosmos-2
The KOSMOS-2 model was proposed in Kosmos-2: Grounding Multimodal Large Language Models to the World by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.

KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale dataset of grounded image-text pairs GRIT. The spatial coordinates of the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective entity text spans (for example, a snowman followed by <patch_index_0044><patch_index_0863>). The data format is similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
Owl-v2
OWLv2 was proposed in Scaling Open-Vocabulary Object Detection by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up OWL-ViT using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
- Add OWLv2, bis by @NielsRogge in #26668
🚨🚨🚨 Safetensors by default for torch serialization 🚨🚨🚨
Version v4.35.0 now puts safetensors serialization by default. This is a significant change targeted at making users of the Hugging Face Hub, transformers, and any downstream library leveraging it safer.
The safetensors library is a safe serialization framework for machine learning tensors. It has been audited and will become the default serialization framework for several organizations (Hugging Face, EleutherAI, Stability AI).
It was already the default loading mechanism since v4.30.0 and would therefore already default to loading model.safetensors files instead of pytorch_model.bin if these were present in the repository.
With v4.35.0, any call to save_pretrained for torch models will now save a safetensors file. This safetensors file is in the PyTorch format, but can be loaded in TensorFlow and Flax models alike.
- Loading a
safetensorsfile and having a warning mentioning missing weights unexpectedly - Obtaining completely wrong/random results at inference after loading a pretrained model that you have saved in
safetensors
If you wish to continue saving files in the .bin format, you can do so by specifying safe_serialization=False in all your save_pretrained calls.
- Safetensors serialization by default by @LysandreJik in #27064
Chat templates
Chat templates have been expanded with the addition of the add_generation_prompt argument to apply_chat_template(). This has also enabled us to rework the ConversationalPipeline class to use chat templates. Any model with a chat template is now automatically usable through ConversationalPipeline.
- Add add_generation_prompt argument to apply_chat_template by @Rocketknight1 in #26573
- Conversation pipeline fixes by @Rocketknight1 in #26795
Guides
Two new guides on LLMs were added the library:
- [docs] LLM prompting guide by @MKhalusova in #26274
- [docs] Optimizing LLMs by @patrickvonplaten in #26058
Quantization
Exllama-v2 integration
Exllama-v2 provides better GPTQ kernel for higher throughput and lower latency for GPTQ models. The original code can be found here.
You will need the latest versions of optimum and auto-gptq. Read more about the integration here.
AWQ integration
AWQ is a new and popular quantization scheme, already used in various libraries such as TGI, vllm, etc. and known to be faster than GPTQ models according to some benchmarks. The original code can be found here and here you can read more about the original paper.

We support AWQ inference with original kernels as well as kernels provided through autoawq package that you can simply install with pip install autoawq.
- [
core/Quantization] AWQ integration by @younesbelkada in #27045
We also provide an example script on how to push quantized weights on the hub on the original repository.
Read more about the benchmarks and the integration here
GPTQ on CPU !
You can now run GPTQ models on CPU using the latest version of auto-gptq thanks to @vivekkhandelwal1 !
- Add support for loading GPTQ models on CPU by @vivekkhandelwal1 in #26719
Attention mask refactor
We refactored the attention mask logic for major models in transformers. For instance, we removed padding_mask argument which was ambiguous for some users
- Remove ambiguous
padding_maskand instead use a 2D->4D Attn Mask Mapper by @patrickvonplaten in #26792 - [Attention Mask] Refactor all encoder-decoder attention mask by @patrickvonplaten in #27086
Flash Attention 2 for more models + quantizat...
Contributors
Assets 2
Patch release: v4.34.1
v4.34: Mistral, Persimmon, Prompt templating, Flash Attention 2, Tokenizer refactor
New models
Mistral
Mistral-7B-v0.1 is a decoder-based LM with the following architectural choices:
- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out-of-vocabulary tokens.
Persimmon
The authors introduced Persimmon-8B, a decoder model based on the classic transformers architecture, with query and key normalization. Persimmon-8B is a fully permissively licensed model with approximately 8 billion parameters, released under the Apache license. Some of the key attributes of Persimmon-8B are long context size (16K), performance, and capabilities for multimodal extensions.
- [
Persimmon] Add support for persimmon by @ArthurZucker in #26042
BROS
BROS stands for BERT Relying On Spatiality. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
- Add BROS by @jinhopark8345 in #23190
ViTMatte
ViTMatte leverages plain Vision Transformers for the task of image matting, which is the process of accurately estimating the foreground object in images and videos.
- Add ViTMatte by @NielsRogge in #25843
Nougat
Nougat uses the same architecture as Donut, meaning an image Transformer encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
- Add Nougat by @NielsRogge and @molbap in #25942
Prompt templating
We've added a new template feature for chat models. This allows the formatting that a chat model was trained with to be saved with the model, ensuring that users can exactly reproduce that formatting when they want to fine-tune the model or use it for inference. For more information, see our template documentation.
- Overhaul Conversation class and prompt templating by @Rocketknight1 in #25323
🚨🚨 Tokenizer refactor
- [
Tokenizer] attemp to fix add_token issues by @ArthurZucker in #23909 - Nit-added-tokens by @ArthurZucker in #26538 adds some fix to #23909 .
🚨Workflow Changes 🚨:
These are not breaking changes per se but rather bugfixes. However, we understand that this may result in some workflow changes so we highlight them below.
- unique_no_split_tokens attribute removed and not used in the internal logic
- sanitize_special_tokens() follows a deprecation cycle and does nothing
- All attributes in SPECIAL_TOKENS_ATTRIBUTES are stored as AddedTokens and no strings.
- loading a slow from a fast or a fast from a slow will no longer raise and error if the tokens added don't have the correct index. This is because they will always be added following the order of the added_tokens but will correct mistakes in the saved vocabulary if there are any. (And there are a lot in old format tokenizers)
- the length of a tokenizer is now max(set(self.get_vocab().keys())) accounting for holes in the vocab. The vocab_size no longer takes into account the added vocab for most of the tokenizers (as it should not). Mostly breaking for T5
- Adding a token using tokenizer.add_tokens([AddedToken("hey", rstrip=False, normalized=True)]) now takes into account rstrip, lstrip, normalized information.
- added_tokens_decoder holds AddedToken, not strings.
- add_tokens() for both fast and slow will always be updated if the token is already part of the vocab, allowing for custom stripping.
- initializing a tokenizer form scratch will now add missing special tokens to the vocab.
- stripping is not always done for special tokens! 🚨 Only if the AddedToken has lstrip=True and rstrip=True
- fairseq_ids_to_tokens attribute removed for Barthez (was not used)
➕ Most visible features:
- printing a tokenizer now shows
tokenizer.added_tokens_decoderfor both fast and slow tokenizers. Moreover, additional tokens that were already part of the initial vocab are also found there. - faster
from_pretrained, fasteradd_tokensbecause special and non special can be mixed together and the trie is not always rebuilt. - faster encode/decode with caching mechanism for
added_tokens_decoder/encoder. - information is fully saved in the
tokenizer_config.json
For any issues relating to this, make sure to open a new issue and ping @ArthurZucker.
Flash Attention 2
FA2 support added to transformers for most popular architectures (llama, mistral, falcon) architectures actively being contributed in this issue (#26350). Simply pass use_flash_attention_2=True when calling from_pretrained
In the future, PyTorch will support Flash Attention 2 through torch.scaled_dot_product_attention, users would be able to benefit from both (transformers core & transformers + SDPA) implementations of Flash Attention-2 with simple changes (model.to_bettertransformer() and force-dispatch the SDPA kernel to FA-2 in the case of SDPA)
- [
core] Integrate Flash attention 2 in most used models by @younesbelkada in #25598
For our future plans regarding integrating F.sdpa from PyTorch in core transformers, see here: #26557
Lazy import structure
Support for lazy loading integration libraries has been added. This will drastically speed up importing transformers and related object from the library.
Example before this change:
2023-09-11 11:07:52.010179: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
python3 -c "from transformers import CLIPTextModel" 3.31s user 3.06s system 220% cpu 2.893 total
After this change:
python3 -c "from transformers import CLIPTextModel" 1.70s user 1.49s system 220% cpu 1.447 total
- [Core] Add lazy import structure to imports by @patrickvonplaten in #26090
Bugfixes and improvements
- Fix typo by @susnato in #25966
- Fix Detr CI by @ydshieh in #25972
- Fix
test_load_img_url_timeoutby @ydshieh in #25976 - nn.Identity is not required to be compatible with PyTorch < 1.1.0 as the minimum PyTorch version we currently support is 1.10.0 by @statelesshz in #25974
- Add
Pop2Pianospace demo. by @susnato in #25975 - fix typo by @kai01ai in #25981
- Use main in conversion script by @ydshieh in #25973
- [doc] Always call it Agents for consistency by @julien-c in #25958
- Update RAG README.md with correct path to examples/seq2seq by @tleyden in #25953
- Update training_args.py to remove the runtime error by @sahel-sh in #25920
- Trainer: delegate default generation values to
generation_configby @gante in #25987 - Show failed tests on CircleCI layout in a better way by @ydshieh in #25895
- Patch with accelerate xpu by @abhilash1910 in #25714
- PegasusX add _no_split_modules by @andreeahedes in #25933
- Add TFDebertaV2ForMultipleChoice by @raghavanone in #25932
- deepspeed resume from ckpt fixes and adding support for deepspeed optimizer and HF scheduler by @pacman100 in #25863
- [Wav2Vec2 Conformer] Fix inference float16 by @sanchit-gandhi in #25985
- Add LLaMA resources by @eenzeenee in #25859
- [
CI] Fix red CI and ERROR failed should show by @ArthurZucker in #25995 - [
VITS] tokenizer integration test: fix revision did not exist by @ArthurZucker in #25996 - Fix Mega chunking error when using decoder-only model by @tanaymeh in #25765
- save space when converting hf model to megatron model. by @flower-with-safe in #25950
- Update README.md by @NinoRisteski in #26003
- Falcon: fix revision propagation by @LysandreJik in #26006
- TF-OPT attention mask fixes by @Rocketknight1 in #25238
- Fix small typo README.md by @zspo in #25934
- 🌐[i18n-KO] Translated
llm_tutorial.mdto Korean by @harheem in #25791 - Remove Falcon from undocumented list by @Rocketknight1 in #26008
- modify context length for GPTQ + version bump by @SunMarc in #25899
- Fix err with FSDP by @muellerzr in #25991
- fix _resize_token_embeddings will set lm head size to 0 when enabled deepspeed zero3 by @kai01ai in #26024
- Fix CircleCI config by @ydshieh in #26023
- Add
tgsspeed metrics by @CokeDong in #25858 - [VITS] Fix nightly tests by @sanchit-gandhi in #25986
- Added HerBERT to README.md by @Muskan011 in #26020
- Fix vilt config docstring parameter to match value in init by @raghavanone in #26017
- Punctuation fix by @kwonmha in #26025
- Try to fix training Loss inconsistent after resume from old checkpoint by @dumpmemory in #25872
- Fix Dropout Implementation in Graphormer by @alexanderkrauck in #24817
- Update missing docs on
activation_dropoutand fix DropOut docs for SEW-D by @gau-nernst in #26031 - Skip warning if tracing with dynamo by @angelayi in #25581
- 🌐 [i18n-KO] Translated
llama.mdto Korean by @harheem in #26044 - [
CodeLlamaTokenizerFast] Fix fixset_infilling_processorto properly reset by @ArthurZucker in #26041 - [
CITests] skip failing tests until #26054 is merged by @ArthurZucker in #26063 - only main process should call _save on deepspeed zero3 by @zjjMaiMai in #25959
- docs: update link huggingface map by @pphuc25 in #26077
- docs: add space to docs by @pphuc25 in #26067
- [
core] Import tensorflow inside relevant methods...
Contributors
Assets 2
Patch release: v4.33.3
Patch release: v4.33.2
Falcon, Code Llama, ViTDet, DINO v2, VITS
Falcon
Falcon is a class of causal decoder-only models built by TII. The largest Falcon checkpoints have been trained on >=1T tokens of text, with a particular emphasis on the RefinedWeb corpus. They are made available under the Apache 2.0 license.
Falcon’s architecture is modern and optimized for inference, with multi-query attention and support for efficient attention variants like FlashAttention. Both ‘base’ models trained only as causal language models as well as ‘instruct’ models that have received further fine-tuning are available.
- Falcon port #24523 by @Rocketknight1
- Falcon: Add RoPE scaling by @gante in #25878
- Add proper Falcon docs and conversion script by @Rocketknight1 in #25954
- Put Falcon back by @LysandreJik in #25960
- [
Falcon] Remove SDPA for falcon to support earlier versions of PyTorch (< 2.0) by @younesbelkada in #25947
Code Llama
Code Llama, is a family of large language models for code based on Llama 2, providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks.
- [
CodeLlama] Add support forCodeLlamaby @ArthurZucker in #25740 - [
CodeLlama] Fix CI by @ArthurZucker in #25890
ViTDet
ViTDet reuses the ViT model architecture, adapted to object detection.
- Add ViTDet by @NielsRogge in #25524
DINO v2
DINO v2 is the next iteration of the DINO model. It is added as a backbone class, allowing it to be re-used in downstream models.
- [DINOv2] Add backbone class by @NielsRogge in #25520
VITS
VITS (Variational Inference with adversarial learning for end-to-end Text-to-Speech) is an end-to-end speech synthesis model that predicts a speech waveform conditional on an input text sequence. It is a conditional variational autoencoder (VAE) comprised of a posterior encoder, decoder, and conditional prior.
Breaking changes:
- 🚨🚨🚨 [
Refactor] Move third-party related utility files intointegrations/folder 🚨🚨🚨 by @younesbelkada in #25599
Moves all third party libs (outside HF ecosystem) related utility files inside integrations/ instead of having them in transformers directly.
In order to get the previous usage you should be changing your call to the following:
- from transformers.deepspeed import HfDeepSpeedConfig
+ from transformers.integrations import HfDeepSpeedConfigBugfixes and improvements
- [DOCS] MusicGen Docs Update by @xNul in #25510
- [MINOR:TYPO] by @cakiki in #25646
- Pass the proper token to PEFT integration in auto classes by @sgugger in #25649
- Put IDEFICS in the right section of the doc by @sgugger in #25650
- TF 2.14 compatibility by @Rocketknight1 in #25630
- Fix bloom add prefix space by @ArthurZucker in #25652
- removing unnecesssary extra parameter by @rafaelpadilla in #25643
- Adds
TRANSFORMERS_TEST_BACKENDby @vvvm23 in #25655 - stringify config by @AleksanderWWW in #25637
- Add input_embeds functionality to gpt_neo Causal LM by @gaasher in #25659
- Update doc toctree by @ydshieh in #25661
- Add Llama2 resources by @wonhyeongseo in #25531
- [
SPM] PatchspmLlama and T5 by @ArthurZucker in #25656 - [
GPTNeo] Add input_embeds functionality to gpt_neo Causal LM by @ArthurZucker in #25664 - fix wrong path in some doc by @ydshieh in #25658
- Remove
utils/documentation_tests.txtby @ydshieh in #25680 - Prevent Dynamo graph fragmentation in GPTNeoX with torch.baddbmm fix by @norabelrose in #24941
⚠️ [CLAP] Fix dtype of logit scales in init by @sanchit-gandhi in #25682- Sets the stalebot to 10 AM CEST by @LysandreJik in #25678
- Fix
pad_tokencheck condition by @ydshieh in #25685 - [DOCS] Added docstring example for EpsilonLogitsWarper #24783 by @sanjeevk-os in #25378
- correct resume training steps number in progress bar by @pphuc25 in #25691
- Generate: general test for decoder-only generation from
inputs_embedsby @gante in #25687 - Fix typo in
configuration_gpt2.pyby @susnato in #25676 - fix ram efficient fsdp init by @pacman100 in #25686
- [
LlamaTokenizer] make unk_token_length a property by @ArthurZucker in #25689 - Update list of persons to tag by @sgugger in #25708
- docs: Resolve typos in warning text by @tomaarsen in #25711
- Fix failing
test_batch_generationfor bloom by @ydshieh in #25718 - [
PEFT] Fix peft version by @younesbelkada in #25710 - Fix number of minimal calls to the Hub with peft integration by @sgugger in #25715
- [
AutoGPTQ] Add correct installation of GPTQ library + fix slow tests by @younesbelkada in #25713 - Generate: nudge towards
do_sample=Falsewhentemperature=0.0by @gante in #25722 - [
from_pretrained] Simpler code for peft by @ArthurZucker in #25726 - [idefics] idefics-9b test use 4bit quant by @stas00 in #25734
- ImageProcessor - check if input pixel values between 0-255 by @amyeroberts in #25688
- [
from_pretrained] Fix failing PEFT tests by @younesbelkada in #25733 - [ASR Pipe Test] Fix CTC timestamps error message by @sanchit-gandhi in #25727
- 🌐 [i18n-KO] Translated
visual_question_answering.mdto Korean by @wonhyeongseo in #25679 - [
PEFT] Fix PeftConfig save pretrained when callingadd_adapterby @younesbelkada in #25738 - fixed typo in speech encoder decoder doc by @asusevski in #25745
- Add FlaxCLIPTextModelWithProjection by @pcuenca in #25254
- Generate: add missing logits processors docs by @gante in #25653
- [DOCS] Add example for HammingDiversityLogitsProcessor by @jessthebp in #25481
- Generate: logits processors are doctested and fix broken doctests by @gante in #25692
- [CLAP] Fix logit scales dtype for fp16 by @sanchit-gandhi in #25754
- [
Sentencepiece] make surelegacydo not requireprotobufby @ArthurZucker in #25684 - fix encoder hook by @SunMarc in #25735
- Docs: fix indentation in
HammingDiversityLogitsProcessorby @gante in #25756 - Add type hints for several pytorch models (batch-3) by @nablabits in #25705
- Correct attention mask dtype for Flax GPT2 by @liutianlin0121 in #25636
- fix a typo in docsting by @statelesshz in #25759
- [idefics] small fixes by @stas00 in #25764
- Add docstrings and fix VIVIT examples by @Geometrein in #25628
- [
LlamaFamiliy] add a tip about dtype by @ArthurZucker in #25794 - Add type hints for several pytorch models (batch-2) by @nablabits in #25557
- Add type hints for pytorch models (final batch) by @nablabits in #25750
- Add type hints for several pytorch models (batch-4) by @nablabits in #25749
- [idefics] fix vision's
hidden_actby @stas00 in #25787 - Arde/fsdp activation checkpointing by @arde171 in #25771
- Fix incorrect Boolean value in deepspeed example by @tmm1 in #25788
- fixing name position_embeddings to object_queries by @Lorenzobattistela in #24652
- Resolving Attribute error when using the FSDP ram efficient feature by @pacman100 in #25820
- [
Docs] More clarifications on BT + FA by @younesbelkada in #25823 - fix register by @zspo in #25779
- Minor wording changes for Code Llama by @osanseviero in #25815
- [
LlamaTokenizer]tokenizenits. by @ArthurZucker in #25793 - fix warning trigger for embed_positions when loading xglm by @MattYoon in #25798
- 🌐 [i18n-KO] Translated peft.md to Korean by @nuatmochoi in #25706
- 🌐 [i18n-KO]
model_memory_anatomy.mdto Korean by @mjk0618 in #25755 - Error with checking args.eval_accumulation_steps to gather tensors by @chaumng in #25819
- Tests: detect lines removed from "utils/not_doctested.txt" and doctest ALL generation files by @gante in #25763
- 🌐 [i18n-KO] Translated
add_new_pipeline.mdto Korean by @heuristicwave in #25498 - 🌐 [i18n-KO] Translated
community.mdto Korean by @sim-so in #25674 - 🤦update warning to If you want to use the new behaviour, set `legacy=… by @ArthurZucker in #25833
- update remaining
Pop2Pianocheckpoints by @susnato in #25827 - [AutoTokenizer] Add data2vec to mapping by @sanchit-gandhi in #25835
- MaskFormer,Mask2former - reduce memory load by @amyeroberts in #25741
- Support loading base64 images in pipelines by @InventivetalentDev in #25633
- Update README.md by @NinoRisteski in #25834
- Generate: models with custom
generate()returnTrueincan_generate()by @gante in #25838 - Update README.md by @NinoRisteski in #25832
- minor typo fix in PeftAdapterMixin docs by @tmm1 in #25829
- Add flax installation in daily doctest workflow by @ydshieh in #25860
- Add Blip2 model in VQA pipeline by @jpizarrom in #25532
- Remote tools are turned off by @LysandreJik in #25867
- Fix imports by @ydshieh in #25869
- fix max_memory for bnb by @SunMarc in #25842
- Docs: fix example failing doctest in
generation_strategies.mdby @gante in #25874 - pin pandas==2.0.3 by @ydshieh in #25875
- Reduce CI output by @ydshieh in #25876
- [ViTDet] Fix doc tests by @NielsRogge in #25880
- For xla tensors, use an alternative way to get a unique id by @qihqi in #25802
- fix ds z3 checkpointing when
stage3_gather_16bit_weights_on_model_save=Falseby @pacman100 in #25817 - Modify efficient GPU training doc with now-available adamw_bnb_8bit optimizer by @veezbo in #25807
- [
TokenizerFast]can_save_slow_tokenizeras a property for whenvocab_file's folder was removed by @ArthurZucker in #25626 - Save image_processor while saving pipeline (ImageSegmentationPipeline) by @raghavanone in #25884
- [
InstructBlip] FINAL Fix instructblip test by @younesbelkada in #25887 - Add type hints for tf models batch 1 by @nablabits in #25853
- Update
setup.pyby @ydshieh in #25893 - Smarter check for
is_tensorby @sgugger in #25871 - remove torch_dtype override by @SunMarc in #25894
- fix FSDP model resume optimizer & schedu...