CausalTree split criterions fix and fit optimization #557
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
jeongyoonlee
requested changes
Oct 14, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Proposed changes
Hi, this PR contains several fixes for causal trees issues I have recently found:
It turned out that
sum_totalandsq_sum_totalattributes inRegressionCriterionwere calculated using weights as multipliers. However, in CausalTree these weights have two values: eps for control, 1 for treatment. So, total outcome values for a tree split were incorrect. Link: _criterion.pyxThere was incorrect calculation of
weighted_n_node_samplesattribute inRegressionCriterion. It is important to get the right impurity values and feature importance. Links: _criterion.pyx, _tree.pyxThere is a more efficient way of calculating node and children impurity for each split.
CausalTreefit()measurements clearly show this:Additional code for time measurements: test.zip
Related issue: #541.
So, I added
NodeInfoandSplitStatestructs incriterion.pyxfor clarity and updatedCausalRegressionCriterion. These steps allowed me to get rid of the loops inCausalMSEand even make this class more concise.Curiously, the qini score with synthetic data has slightly changed since this update.
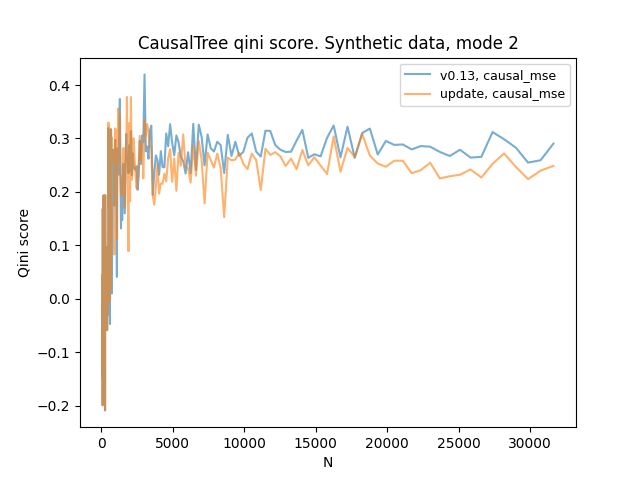
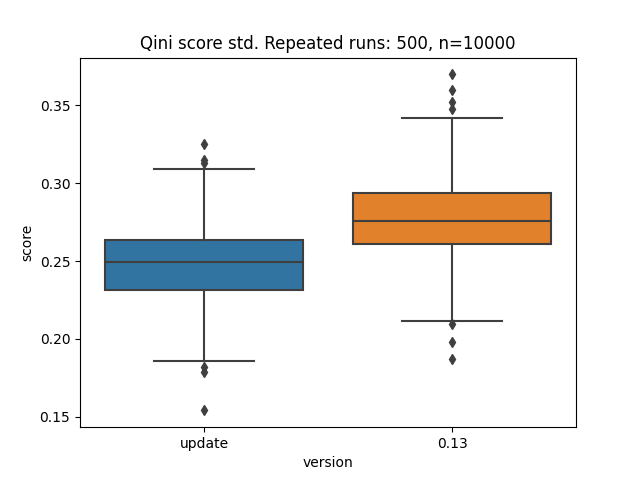
Additional updates:
conftest.pyto get the desired type of regression synthetic data in any test file.Types of changes
What types of changes does your code introduce to CausalML?
Put an
xin the boxes that applyChecklist
Put an
xin the boxes that apply. You can also fill these out after creating the PR. If you're unsure about any of them, don't hesitate to ask. We're here to help! This is simply a reminder of what we are going to look for before merging your code.Further comments