Basic implementation of Controller RNN from Neural Architecture Search with Reinforcement Learning and Learning Transferable Architectures for Scalable Image Recognition.
- Uses Keras to define and train children / generated networks, which are defined in Tensorflow by the Controller RNN.
- Define a state space by using
StateSpace, a manager which adds states and handles communication between the Controller RNN and the user. Controllermanages the training and evaluation of the Controller RNNNetworkManagerhandles the training and reward computation of a Keras model
At a high level : For full training details, please see train.py.
# construct a state space
state_space = StateSpace()
# add states
state_space.add_state(name='kernel', values=[1, 3])
state_space.add_state(name='filters', values=[16, 32, 64])
# create the managers
controller = Controller(tf_session, num_layers, state_space)
manager = NetworkManager(dataset, epochs=max_epochs, batchsize=batchsize)
# For number of trials
sample_state = ...
actions = controller.get_actions(sample_state)
reward = manager.get_reward(actions)
controller.train()This is a very limited project.
- Note: The controller eventually overfits to produce a single model always (generally a high performance model, but not always the highest). It seems there os a requirement to have a pool of controllers to avoid this overfitting, which would need distributed training. However, since the exploration rate is so high, there is a large set of very good models that are generated during the training process, and the controller yields a pretty strong model as well.
- It doesnt have support for skip connections via 'anchor points' etc. (though it may not be that hard to implement it as a special state)
- A lot of the details of the Controller were found in slides etc and not in the paper so I had to take many liberties when re-implementing it.
- Learning rate, regularization strength, discount factor, exploration, beta value for EWA accuracy, clipping range etc are all random values (which make somewhat sense to me)
- Single GPU model only. There would need to be a lot of modifications to this for multi GPU training (and I have just 1)
Implementation details were found from:
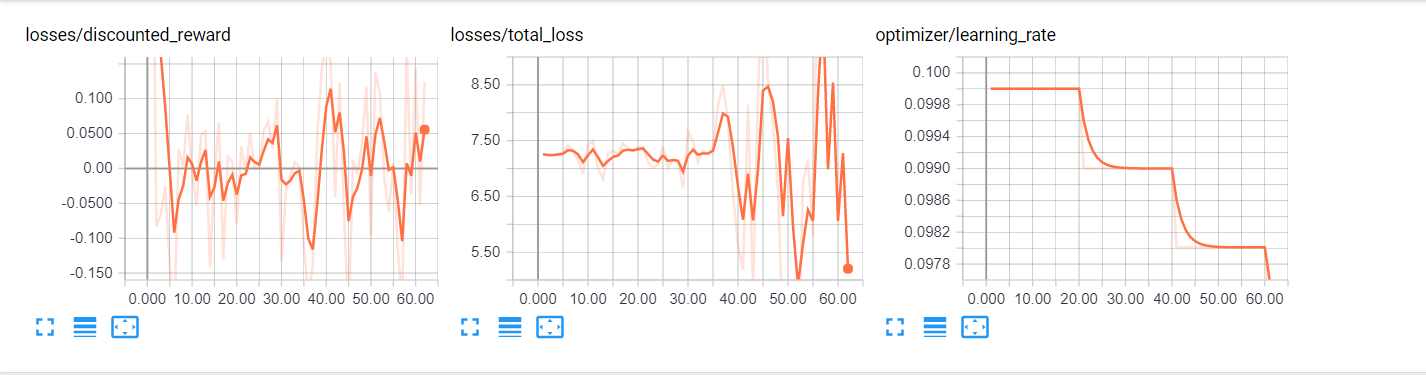
I tried a toy CNN model with 4 CNN layers with different filter sizes (16, 32, 64) and kernel sizes (1, 3) to maximise score in 10 epochs of training on CIFAR-10.
After 50 steps, it converges to the "state space" of (3x3, 64)-(3x3, 64)-(3x3, 32)-(3x3, 64). Interestingly, this model performs very slightly better than a 4 x (3x3, 64) model, at least in the first 10 epochs.
- Keras >= 1.2.1
- Tensorflow-gpu >= 1.2
Code heavily inspired by wallarm/nascell-automl