OpenPifPaf DeepSparse Pipeline #788
Conversation
…tionizing_open_pif_paf
Co-authored-by: corey-nm <109536191+corey-nm@users.noreply.github.com>
…/github.com/neuralmagic/deepsparse into feature/damian/productionizing_open_pif_paf
|
I moved some of the postprocessing from visualization to the pipeline, so the user receives human-readable output from the pipeline and thus the pipeline can be also used efficiently in the server. |
Co-authored-by: corey-nm <109536191+corey-nm@users.noreply.github.com>
There was a problem hiding this comment.
Great work @dbogunowicz
following @corey-nm 's comments in vit-pose let's get a simple readme up (can be a quick follow up). also as discussed offline let's do a brief check on postprocessing times using our new logging tools :)
|
@bfineran , per pre_process_latency[s] 0.0044 +- 0.0015
engine_forward_latency[s] 0.1699 +- 0.0173
post_process_latency[s] 0.0050 +- 0.0010No red flags here seems that on average both pre- and post-processing steps are two OOM smaller than the engine forward. |
DeepSparse pipeline for OpenPifPaf
Sanity checks:
Use in the server
Use for the user:
Simple private unittest (not in the repo, since we do not have any zoo model yet):
The test was green
Investigation of the necessity of external OpenPifPaf helper function
As illustrated by the diagram from the original paper, once the image has been encoded into PIF or PAF (or CIF and CAF, same meaning here, those are just two naming conventions by the authors from the two different papers) tensors, they need to be later decoded into annotations.
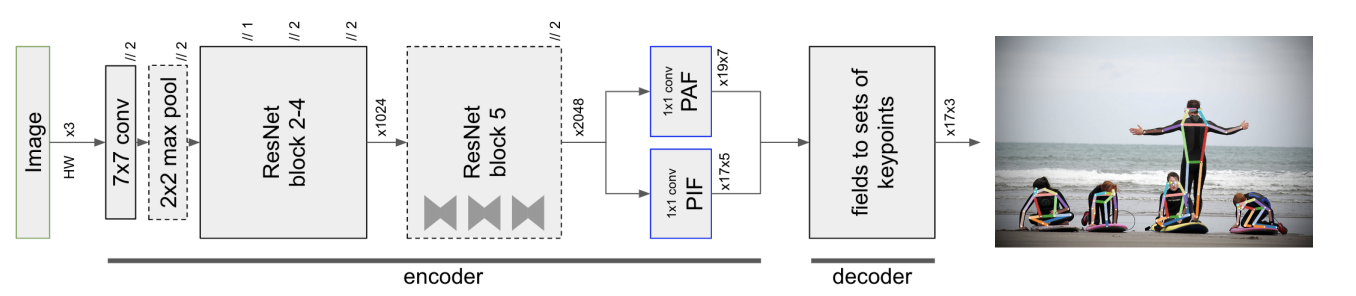
Once the neural network outputs CIF and CAF tensors, they are processed by an algorithm described below:
For speed reasons, the decoding is actually implemented in C++ and libtorch:
https://github.com/openpifpaf/openpifpaf/src/openpifpaf/csrcThis is the part that I am right now unable to properly implement in the DeepSparse repo, so I mock it in the following way:
On the pipeline instantiation
First, we fetch the default
modelobject (also a second argument, which is the last epoch of the pre-trained model) from the factory. Note, thismodelwill not be used for inference, we need to pull the information about the heads of this model:model_cpu.head_metas: List[Cif, Caf]. This information will be consumed to create a (set of) decoder(s) (objects that map "fields", raw network output, to human-understandable annotations).Note: The
CifandCafobjects seem to be dataset-dependent. They hold e.g. the information about the expected relationship of the joints of the pose (skeleton).Hint: Instead of returning Annotation objects, the API supports returning annotations as JSON serializable dicts. This is probably what we should aim for, especially when we want to deploy OpenPifPaf inference in the Server.
In the default scenario (I suspect for all the pose estimation tasks), the
self.processorwill be aMultiobject that holds a singleCifCafdecoder.Other available decoders:
{ openpifpaf.decoder.cifcaf.CifCaf, openpifpaf.decoder.cifcaf.CifCafDense, # not sure what this does openpifpaf.decoder.cifdet.CifDet, # I think this is just for the object detection task openpifpaf.decoder.pose_similarity.PoseSimilarity, # for pose similarity task openpifpaf.decoder.tracking_pose.TrackingPose # for tracking task }On the engine output preprocessing
We are passing the CIF and CAF values directly to the processor (through the private function,
self.processorby default does also batching and inference). This is the functionality that we would like to fold into our computational graph (I suppose):