![]()

This project is an implementation of the Barnes-Hut algorithm for approximating the gravitational forces between objects in a system. It is commonly used in astrophysical simulations to model the motion of celestial bodies, such as planets and stars. The simulation can be initialized with the positions, masses, and velocities of the objects, and will iteratively update the positions and velocities based on the gravitational forces acting on them.

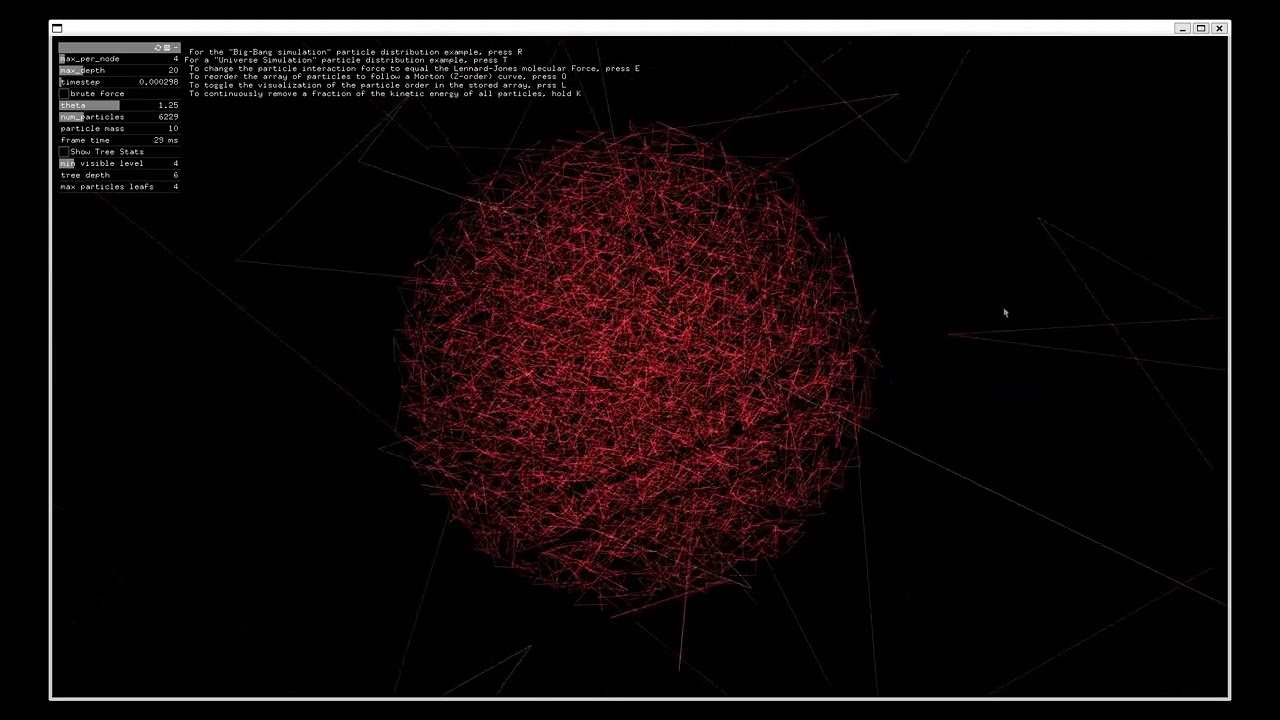
The basic idea behind the Barnes-Hut algorithm is to divide the system into a grid of cells and to approximate the forces between objects in a cell using the center of mass and total mass of the cell. This allows the simulation to scale to systems with a large number of objects, as the calculation of forces between each object would become computationally infeasible. To improve the accuracy of the simulation, the size of the cells can be decreased, which will result in a more precise calculation of the forces between objects. However, this will also increase the computational cost of the simulation.
This project was made for the Advanced Programming course at the Technical University of Munich. Authors: Phillip Jurašić & Islam Elgamal Supervision: Gerasimos Chourdakis
References: Barnes, J., & Hut, P. (1986). A hierarchical O(N log N) force-calculation algorithm. Nature, 324(6096), 446-449.
This project was made with only Linux in mind. There is no guarantee this would work on any other OS. Please also insure that at least g++ version 10 is installed and set as default.
You need cmake, glm, libmorton and C++ boost installed for this project to work. gtest is used for our unit tests and openframeworks for the visualizations. The following commands will install them. The last two lines are for building gtest on your machine.
apt-get install g++-11 cmake
apt-get install -y libglm-dev libboost-all-dev libgtest-dev
# Possibly need to run the following commands to build gtest
cd /usr/src/gtest
cmake CMakeLists.txt && make
cd -
# Clone and install libmorton
git clone https://github.com/Forceflow/libmorton.git
cd libmorton && mkdir build && cd build && cmake .. && make && make install
For GUI and visualization, follow the instructions on https://openframeworks.cc/setup/linux-install/ and to run the 3D live particle visualization:
cd visualizer
sudo make
make runTo compile and execute the project, run the following commands:
mkdir build && cd build && cmake ..
make barnes-hut
./simulation/barnes-hut- Creates a folder called
build, navigates into it, and creates the makefile - Compiles and links the project
- Runs the executable. This produces a .csv file called output.csv as an output of the simulation
- Installs all the python dependencies for visualizing the results from requirements.txt
- Runs the python script for visualizing the behavior of the system of particles over a set period of time in 3D space with dynamic POV
Our simulation can output .csv files to be visualized in Paraview using the default CSV importer and TableToPoints filter. To do so, simply specify the --csv flag when running (e.g. ./barnes-hut --csv)
To get a full list of available CLI parameters, run ./barnes-hut --help.
To run the 3D visualization, you need to install open frameworks and possibly the addon ofxGui. The installation directory should be called OF and installed next to the project folder.
Idea contributed by Philipp Jurašić and Islam Elgamal
Space is cool, and as admirers of science, we want to know how it works. In this project, we want to play god and create our own galaxy.
We want to approximate the effect of gravity in the formation of gas clouds and the clustering of stars over long periods of time. This will be done by simulating the attractive forces between thousands of particles (representing stars and other celestial bodies).
The Barnes-Hut algorithm is commonly used in computational physics, specifically to approximately compute n-body interactions.
{kind=link}

In this sprint we will implement the n-body problem and a basic Barnes-Hut approximation. The program will randomly generate initial conditions for testing and the result will be outputted for visualization. We will compare the result of the brute force "reference" solution with the Barnes-Hut algorithm.
- Generate an array of initial masses, positions, and velocities of a system of bodies in 3D space.
- Create a brute force n-body simulation O(n*n) (will be later used as a unit test for verification)
- Create a function for space-dividing an array of coordinates into an octree data structure.
- Implement the Barnes Hut algorithm for simulating the system of bodies over a specified duration of time.
- Create a unit test, that compares the brute force reference solution with the Barnes-Hut approximation for a small test dataset
- Output a time series of the resulting positions of all bodies into a file (e.g. .csv with timestamps) that can be visualized with external tools (e.g. Python script)
In this sprint, we will add visualization capabilities to the project, allow the user to configure simulation settings via a config file or command line parameters. The code will be restructured in an Object Oriented way such that the data structure will be based on classes. The functions will be abstracted with interfaces such that they can be switched to any arbitrary interaction function.
- Add the ability to specify parameters like the initial conditions, timestep size, simulation duration, etc. in either a configuration file or as command line parameters.
- Implement appropriate access control modifiers for functions and variables.
- Apply appropriate usage of references and pointers for optimal memory allocation.
- Add the ability to visualize the dynamics of the simulation in 3D space.
- Abstract the interaction function of the bodies (and add an example of how to use it, e.g. gravity potential and Lennard Jones potential)
- Abstract the space-dividing function
- Clean up and refactor the code
- Create a Second Order Integrator for the Barnes-Hut Simulation
- Create an Interactive GUI for the Simulation
- Support Different Initial Conditions
Molecular dynamics simulation using the newly added Lennard Jones potential. By gradually removing energy from the system, the particles start forming hexagonal crystaline structures.

In this sprint, we will analyze and optimize the performance and computation time of the program. The focus will be to study how much impact each section of the code has on the total runtime and the effect of each optimization step taken to reduce computation time.
-
Measure how much time is consumed during each section in the code (single and multithreaded profiles at the bottom of the README)
-
Utilize at least three different optimization techniques and study their impact on total runtime
-
At least one function should utilize vectorized instructions
-
Try Feedback-Directed Compiler Optimization (FDO) in g++ using the -fprofile-generate and -fprofile-use flags (8% improvement with large particle systems >5k). (Optional: Compare to performance using -fauto-profile and Linux perf)
-
Switched from shared_ptr to unique_ptr implementation for the tree (Improved tree build times by slightly, reduced memory footprint)
-
Only leaf nodes store a vector of pointers, reducing the number of stored particle pointers in our implementation from the previous O(N*log(N)) to N
-
Replacing th the Particle pointers with integer offsets into the particle vector (32 bits per particle in a leaf node instead of 64 bits for the unique_ptr), reducing the size of the Tree object by replacing
bool leafandstd::vector<Tree> brancheswithTree* branches(nullptrthen automatically means it is a leaf) reduces the storage per Octree Node by1 byte for bool + 2*64 bit for vector = 9bytes: 10% performance jump, reduced memory footprint. -
Sorting the particle array before the simulation to improve cache coherence (In single-threaded benchmark UNIVERSE4 with 30k particles, 10s and 0.1s timestep the execution time was reduced from 1m13.605 to 55.010s. That is a 30% improvement in execution time) (Valgrind Cache reports confirmed, that L1 hit rate was improved)
-
Compare ways of computing forces: branchless by subtracting the "self interaction" force at the end, or checking if the interacting particle is itself every iteration. The result varies depending on how expensive the force computation is. The branchless implementation is about 5% slower for Lennard Jones potentials (two more force evaluations per particle), 5% faster for gravity (less branching)
-
Is passing the position vector by value faster than by reference in the computeAcceleration function? (73% slower: 17.3s by value, 10.0s by reference)
-
Compare if by value and by reference make a difference in Tree.cpp selectOctant() and lessThanTheta(). (No measurable difference. 10s by value, 10s by reference)
-
OpenMP parallel for loop for multithreading the simulation.
-
OmenMP dynamic scheduling for the simulation loop. (Improved performance by 12% in the UNIVERSE4 benchmark) Due to load imbalance between threads, the dynamic scheduling algorithm is more efficient in this scenario. The level of imbalance depends heavily on the distribution you are trying to simulate, e.g. if particles are clustered together in certain regions, load imbalance could be quite high.
-
Brute force optimizations:
- Single-threaded, vectorized: 9.57s
- Single-threaded, vectorized, subtraction instead of position comparison: 9.91s
- Multi-threaded, vectorized, parallel inner loop: 36.86s (16cores)
- Multi-threaded, vectorized, parallel outer loop: 1.13s (16cores)
-
OpenMP for explicit SIMD for vectorization. (All our attempts resulted in longer runtimes than. GLM already uses some SIMD instructions for the vector math)
-
OpenMP parallel for loop for multithreading the tree construction. (Construction is memory bound and was slower using OpenMP tasks for recursive parallelization, except for very large numbers of particles)
-
Imroved logging performance slightly by adding some noexcept statements
Single-threaded gperf analysis: Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 98.38 4.26 4.26 120000 0.00 0.00 Tree::computeAccFromPos(glm::vec<3, double, (glm::qualifier)0> const&, double) const 0.46 4.28 0.02 120000 0.00 0.00 Tree::insert(std::unique_ptr<Particle, std::default_delete<Particle> >) 0.46 4.30 0.02 _init 0.23 4.31 0.01 96 0.00 0.00 std::vector<Tree, std::allocator<Tree> >::~vector()Multi-threaded gperf analysis with 16 cores: Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls s/call s/call name 71.08 1.18 1.18 6786 0.00 0.00 Tree::computeAccFromPos(glm::vec<3, double, (glm::qualifier)0> const&, double) const 16.27 1.45 0.27 266225 0.00 0.00 Tree::insert(std::unique_ptr<Particle, std::default_delete<Particle> >) 7.23 1.57 0.12 17 0.01 0.01 Tree::computeCOM() 3.61 1.63 0.06 387 0.00 0.00 std::vector<Tree, std::allocator<Tree> >::~vector() 1.81 1.66 0.03 135658 0.00 0.00 Tree::createBranches()
Tree construction is fast, taking up ~2% of the runtime in the single threaded example using 10k particles and theta=1.5, but it is also the only part of our code that's not parallelized. That's why in the multithreaded example the construction overhead becomes more and more noticeable. Assuming that it is the only serial part of our code, Amdahl's law gives us a theoretically possible speedup of 50x. In reality the speedup is much lower, presumably due to the overhead of moving data between threads and serial portions of the code that went under our radar.  After some further investigations, we found that the static scheduling of the OpenMP parallel for loop was the problem. The load was not balanced between the threads, so the slowest thread would always be the bottleneck, while the other would be sitting idle. By switching to dynamic scheduling, the speedup per core became similiar to the brute force version.
After some further investigations, we found that the static scheduling of the OpenMP parallel for loop was the problem. The load was not balanced between the threads, so the slowest thread would always be the bottleneck, while the other would be sitting idle. By switching to dynamic scheduling, the speedup per core became similiar to the brute force version.
 Nonetheless, both algorithms perform far below the theoretical limit, eventhough the algorithms should parallelize well.
Nonetheless, both algorithms perform far below the theoretical limit, eventhough the algorithms should parallelize well.
The SoA implementation is very much WIP, and not on par with SoA yet.
-
[] Tree construction using OpenMP tasks and std::upper_bound for the binary search.
-
[] CUDA?
-
Vectorization of the tree traversal (Traverse a batch of particles at once, e.g. the batches of
countparticles in a leaf?) -
Merge Center of Mass computation with the tree building: difference within measurement uncertainty, and the implementation becomes even less readable. Not worth it.
-
Improved particle sorting/reordering by reducing memory allocations and copying
-
[] VTune profiling for further optimization, it's still saying that there are many scalar instructions. (Improved using XSIMD for batched traversal)
Operation Time Bounding box 2 ms Sorting indices 10 ms Reordering particles 13 ms Tree construction 16 ms Centers of mass 13 ms Force Traversal 267 ms -
Tree traversal
recursive_forceis incorrect and slow (the same number of evaluations as the brute force version???) -> the theta comparison had a bug -
Make sure the last particle is also being added to the tree
-
Confirm that the tree construction is correct (Looks good according to the visualizer)
-
Try custom quicksort implementation for the particle array (Same performance as std::sort)
-
Parallel center of mass computations (decreased performance for systems >10k particles)
-
Vectorization of the innermost particle loop (leaf/near field)
-
Vectorization of the far field loop using the centers of mass
This project uses out-of-core construction as described in Coherent Out-of-Core Point-Based Global Illumination, and by the Blog post articles of Jeroen Baert. The used libraries are libmorton library for vectorized generation of morton codes and XSIMD to implement vectorized traversal of batches of particles.
@article {10.1111:j.1467-8659.2011.01995.x,
journal = {Computer Graphics Forum},
title = {{Coherent Out-of-Core Point-Based Global Illumination}},
author = {Kontkanen, Janne and Tabellion, Eric and Overbeck, Ryan S.},
year = {2011},
publisher = {The Eurographics Association and Blackwell Publishing Ltd.},
ISSN = {1467-8659},
DOI = {10.1111/j.1467-8659.2011.01995.x}
}
@Misc{libmorton18,
author = "Jeroen Baert",
title = "Libmorton: C++ Morton Encoding/Decoding Library",
howpublished = "\url{https://github.com/Forceflow/libmorton}",
year = "2018"}