该项目是流量预处理与分类验证的一个统一实现,力求使用清晰的项目结构与最少的代码实现预设功能,目前支持的模型只有1dcnn、app-net两种,后续会进行更新。代码已经开源至露露云的github,如果能帮助你,就给鼠鼠点一个star吧!!!
提取网络数据流量的负载、包长序列、统计(当前版本还未实现)的特征,转为
npy格式进行持久化存储,基于flowcontainer库
-
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置preprocess的参数,以下是一个示例preprocess: traffic_path: ../traffic_path/android # 原始pcap的路径 datasets: ../datasets/android # 预处理后npy文件的路径 packet_num: 4 # 负载特征参数:流的前4包的负载 byte_num: 256 # 负载特征参数:每个包的前256个字节 ip_length: 128 # 包长特征参数:提取流前128个包长序列 threshold: 4 # 阈值:流包长小于4时舍弃 train_size: 0.8 # 训练集所占比例
其中对于前
packet_num个包的前byte_num字节可以如图说明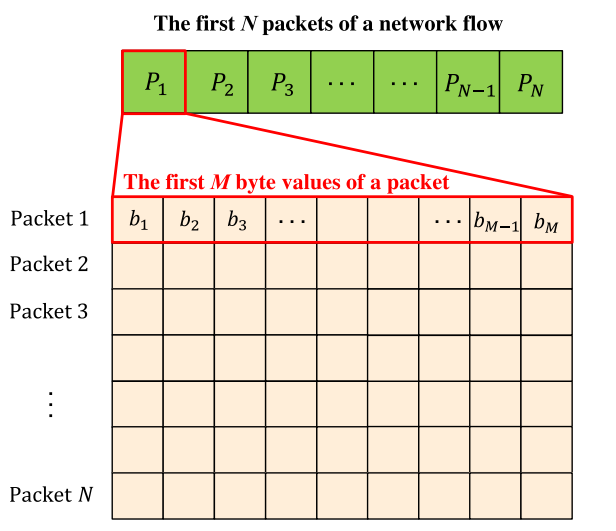
负载、包长均作了舍长补短的操作,以达到特定的格式。
-
预处理脚本运行:
环境说明: python最好使用3.7版本, 否则安装numpy==1.21.6, 否则容易有报错
配置
yaml_path即配置文件路径,然后运行代码entry/1_preprocess_with_flowcontainer.pydef main(): yaml_path = r"../configuration/traffic_classification_configuration.yaml" cfg = setup_config(yaml_path) # 获取 config 文件 pay, seq, label = getPcapIPLength( cfg.preprocess.traffic_path, cfg.preprocess.threshold, cfg.preprocess.ip_length, cfg.preprocess.packet_num, cfg.preprocess.byte_num) split_data(pay,seq,label,cfg.preprocess.train_size,cfg.preprocess.datasets) if __name__=="__main__": main()
-
样本字典补齐:运行完后,得到一个字典输出,将该字典复制到配置文件的
test/label2index下label2index: {'qq': 0, '微信': 1, '淘宝': 2}
-
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置train/test的参数,以下是一个示例train: train_pay: ../TrafficClassificationPandemonium/datasets/android/train/pay_load.npy # train_seq: ../npy_data/test/test/ip_length.npy train_seq: ../TrafficClassificationPandemonium/datasets/android/train/ip_length.npy train_sta: None train_label: ../TrafficClassificationPandemonium/datasets/android/train/label.npy test_pay: ../TrafficClassificationPandemonium/datasets/android/train/pay_load.npy test_seq: ../TrafficClassificationPandemonium/datasets/android/train/ip_length.npy test_sta: None test_label: ../TrafficClassificationPandemonium/datasets/android/train/label.npy BATCH_SIZE: 128 epochs: 50 # 训练的轮数 lr: 0.001 # learning rate model_dir: ../TrafficClassificationPandemonium/checkpoint # 模型保存的文件夹 # model_name: cnn1d.pth # 模型的名称 model_name: app-net.pth # 模型的名称 test: evaluate: False # 如果是 True, 则不进行训练, 只进行评测 pretrained: False # 是否有训练好的模型# # # {'Chat': 0, 'Email': 1, 'FT': 2, 'P2P': 3, 'Streaming': 4, 'VoIP': 5, 'VPN_Chat': 6, 'VPN_Email': 7, 'VPN_FT': 8, 'VPN_P2P': 9, 'VPN_Streaming': 10, 'VPN_VoIP': 11} label2index: {'qq': 0, '微信': 1, '淘宝': 2} confusion_path: ../TrafficClassificationPandemonium/result/confusion/ConfusionMatrix-app-net.png
-
**运行脚本:**运行代码
entry/2_train_test_model.py
-
参数配置:打开
configuration/traffic_classification_configuration.yaml配置文件,配置test的参数的evaluate与pretrained为True -
**运行脚本:**运行代码
entry/2_train_test_model.py
-
混淆矩阵的展现
默认在
result/confusion下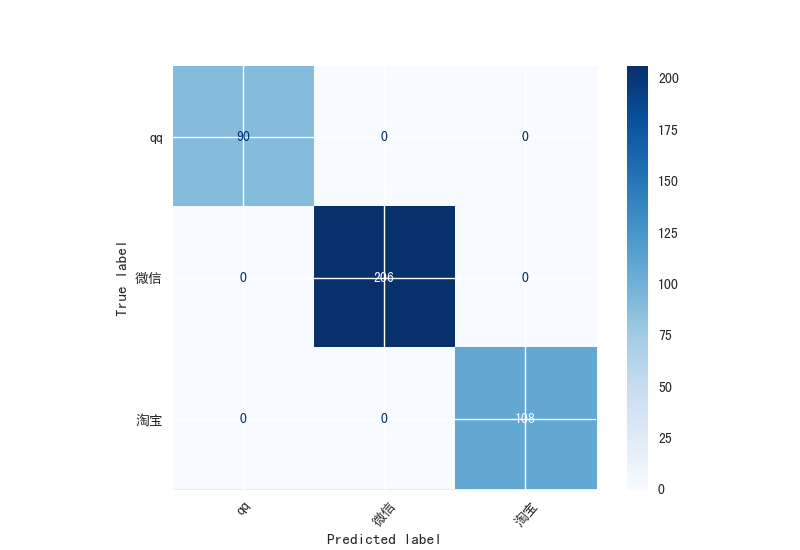
-
acc、loss曲线的展现训练中或者训练后,使用
tensorboard --logdir /result/tensorboard进行查看
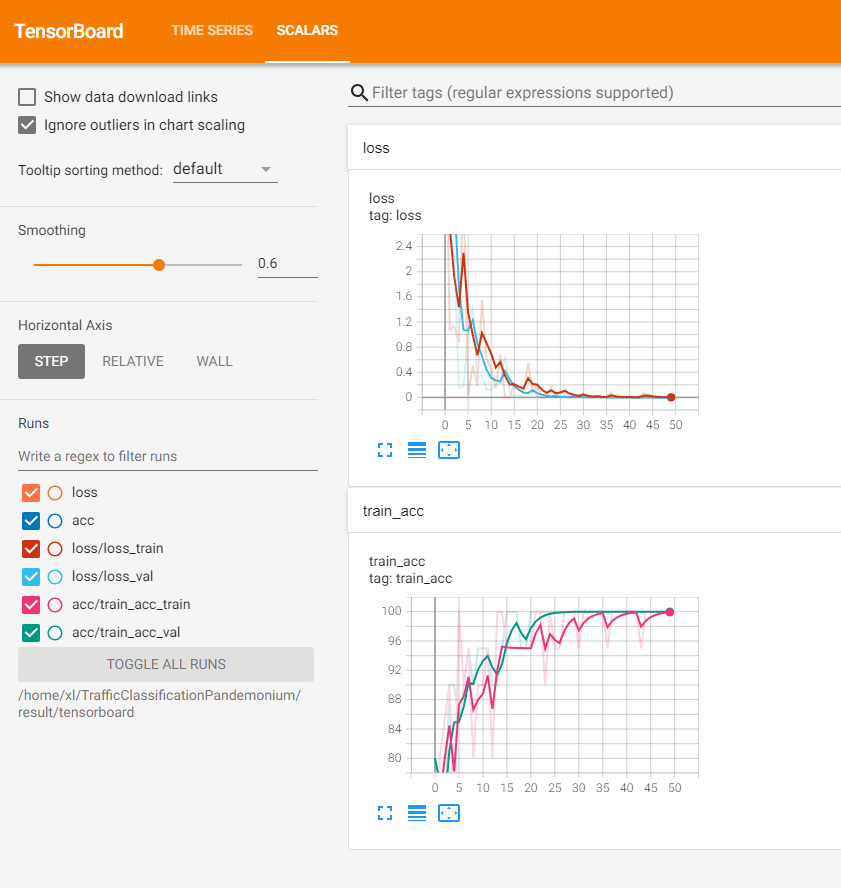
-
新增模型:按照
models下面的示例进行新增,模型都有两个返回,一个是分类结果,一个是重构结果(框架为了兼容后续上传的模型) -
切换模型:在
entry/2_train_test_model.py的20/21行进行导入切换即可,下图为一维卷积与appnet的切换示例
-
增加了基于
splitCap.exe分流预处理,并且除了提取负载与包长序列后,支持提取统计特征(26维度)。26维度统计分别为
"Avg_syn_flag", "Avg_urg_flag", "Avg_fin_flag", "Avg_ack_flag", "Avg_psh_flag", "Avg_rst_flag", "Avg_DNS_pkt", "Avg_TCP_pkt", "Avg_UDP_pkt", "Avg_ICMP_pkt", "Duration_window_flow", "Avg_delta_time", "Min_delta_time", "Max_delta_time", "StDev_delta_time", "Avg_pkts_lenght", "Min_pkts_lenght", "Max_pkts_lenght", "StDev_pkts_lenght", "Avg_small_payload_pkt", "Avg_payload", "Min_payload", "Max_payload", "StDev_payload", "Avg_DNS_over_TCP", "Num_pkts"从
entry.pcap2npy/1_preprocess_with_splitCap_1.py进入配置文件preprocess下路径要为windows格式
运行完的预览图,可以看到有statistic.npy的统计特征文件
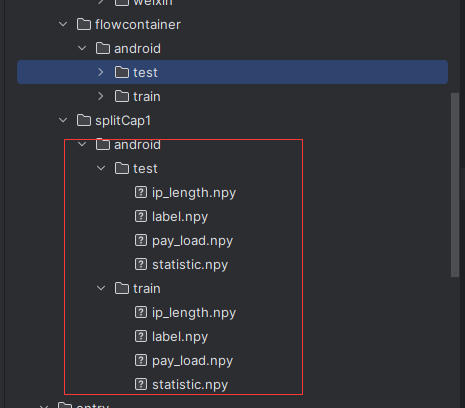
- 增加了基于
cic-meterflower工具对pcap的处理,将pcap处理为csv格式文件
使用
entry/pcap2csv/1_preprocess_with_cic.py,参考博客流量预处理-3:利用cic-flowmeter工具提取流量特征修改相应的路径变量注意:pcap路径与名称在使用该方式处理时不能出现中文,否则报错。
运行完的预览图,可以看到已经对中文进行改名,出现各个标签的csv文件
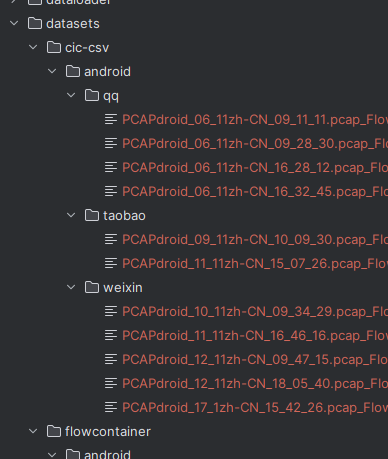
当前更新对运行项目是无影响的,也就是说如果你是仅仅使用项目而不进行扩展的话,此处更新是透明的,对当前仓库版本的代码可以不进行同步。 代码已经推送开源至露露云的github,如果能帮助你,就给鼠鼠点一个star吧!!!
简要:由原先各个模型独立抽象出了一个
base_model模型基类,由该基类继承nn.Module类,定义抽象方法forward与data_trans,方便不同模型进行各自的数据变换
-
为什么要改?
dataloader给模型输入的数据格式是固定死的,给每一个模型设定不同的dataloader违背了项目多个模型统一代码原则,而不同模型对于数据的输入样式是不同的,为了适用于之后会加入项目的模型,抽象出一个基类,设定一个data_trans抽象方法,每一个模型都根据模型的输入去实现该方法即可,这样做到了不更改dataloader的目的,做到代码复用 -
dataloader给定的数据样式?分析日志可以给出以下各个维度下
dataloader给定的数据shape[2024-03-23 17:19:38,802 INFO] 是否使用 GPU 进行训练, cuda [2024-03-23 17:19:44,781 INFO] 成功初始化模型. [2024-03-23 17:19:44,814 INFO] pcap 文件大小, torch.Size([404, 1, 1024]); seq文件大小:torch.Size([404, 128, 1]); sta文件大小: torch.Size([404, 1024]); label 文件大小: torch.Size([404]) [2024-03-23 17:19:44,851 INFO] pcap 文件大小, torch.Size([404, 1, 1024]); seq文件大小:torch.Size([404, 128, 1]); sta文件大小: torch.Size([404, 1024]); label 文件大小: torch.Size([404]) [2024-03-23 17:19:44,851 INFO] 成功加载数据集.
负载pay: [batch_size,1,m*n]
包长seq: [batch_size,seq_len,1]
统计sta: [batch_size,sta_len]
- m*n是预处理的前m个包的前n个字节,这里目前写的是4*256也就是1024
- seq_len是预处理的前ip_length个包长,这里目前是128
- sta_len是预处理的统计维度,在10号更新的数据下是26
-
由于前期中的使用
继承改善了模型结构,这里只需要写一个py文件就可以了""" @Description: 二维卷积神经网络 """ from math import sqrt import torch import torch.nn as nn from models.base_model import BaseModel class Cnn2d(BaseModel): def __init__(self, num_classes=12): super(Cnn2d, self).__init__() # 卷积层+池化层 self.features = nn.Sequential( nn.Conv2d(kernel_size=5,in_channels=1,out_channels=32,stride=1,padding=2), # b,32,32,32 nn.MaxPool2d(kernel_size=2), # b,32,16,16 nn.Conv2d(kernel_size=5,in_channels=32,out_channels=64,stride=1,padding=2), # b,64,16,16 nn.MaxPool2d(kernel_size=2), # b,64,8,8 ) # 全连接层 self.classifier = nn.Sequential( # 29*64 nn.Flatten(), nn.Linear(in_features=64 * 64, out_features=1024), # 1024:64*64 nn.Dropout(0.5), nn.Linear(in_features=1024, out_features=num_classes) ) def forward(self, pay, seq, sta): pay, seq, sta = self.data_trans(pay, seq, sta) pay = self.features(pay) # 卷积层, 提取特征 pay = self.classifier(pay) # 分类层, 用来分类 return pay, None def data_trans(self, x_payload, x_sequence, x_sta): # 转换 x_0,x_1,x_2 = x_payload.shape[0],x_payload.shape[1],x_payload.shape[2] x_payload = x_payload.reshape(x_0,x_1,int(sqrt(x_2)),int(sqrt(x_2))) return x_payload, x_sequence, x_sta def cnn2d(model_path, pretrained=False, **kwargs): """ CNN 1D model architecture Args: pretrained (bool): if True, returns a model pre-trained model """ model = Cnn2d(**kwargs) if pretrained: checkpoint = torch.load(model_path) model.load_state_dict(checkpoint['state_dict']) return model def main(): a = sqrt(1024) x_pay = torch.rand(8,1,1024) cnn = Cnn2d() x = cnn(x_pay,x_pay,x_pay) if __name__=="__main__": main()
模型结构:
两个卷积+池化的组合,卷积核大小都是5X5,池化层的核大小都是2X2
-
在
train_test_model.py中,改动from utils.set_config import setup_config # from models.cnn1d import cnn1d as train_model # from models.app_net import app_net as train_model from models.cnn2d import cnn2d as train_model
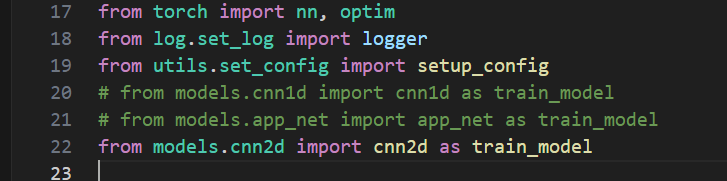
即可!
-
开始训练!
[2024-03-28 21:20:53,317 INFO] Epoch: [47][2/4], Loss 0.0001 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:53,345 INFO] Epoch: [47][3/4], Loss 0.0000 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:53,544 INFO] * Prec@1 100.000 [2024-03-28 21:20:53,716 INFO] Epoch: [48][1/4], Loss 0.0001 (0.0002), Prec@1 100.000 (100.000) [2024-03-28 21:20:53,723 INFO] Epoch: [48][3/4], Loss 0.0000 (0.0003), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,066 INFO] Epoch: [48][0/4], Loss 0.0000 (0.0000), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,105 INFO] Epoch: [48][1/4], Loss 0.0014 (0.0007), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,146 INFO] Epoch: [48][2/4], Loss 0.0001 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,153 INFO] Epoch: [48][3/4], Loss 0.0000 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,331 INFO] * Prec@1 100.000 [2024-03-28 21:20:54,537 INFO] Epoch: [49][1/4], Loss 0.0080 (0.0055), Prec@1 99.219 (99.609) [2024-03-28 21:20:54,558 INFO] Epoch: [49][3/4], Loss 0.0000 (0.0058), Prec@1 100.000 (99.505) [2024-03-28 21:20:54,880 INFO] Epoch: [49][0/4], Loss 0.0000 (0.0000), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,929 INFO] Epoch: [49][1/4], Loss 0.0001 (0.0001), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,970 INFO] Epoch: [49][2/4], Loss 0.0013 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:54,982 INFO] Epoch: [49][3/4], Loss 0.0000 (0.0005), Prec@1 100.000 (100.000) [2024-03-28 21:20:55,147 INFO] * Prec@1 100.000
-
修改测试文件切换为测试模式
Model Classification report: [2024-03-28 21:26:19,166 INFO] ------------------------------ [2024-03-28 21:26:19,172 INFO] precision recall f1-score support qq 1.00 1.00 1.00 90 微信 1.00 1.00 1.00 206 淘宝 1.00 1.00 1.00 108 accuracy 1.00 404 macro avg 1.00 1.00 1.00 404 weighted avg 1.00 1.00 1.00 404 [2024-03-28 21:26:19,175 INFO] Prediction Confusion Matrix: [2024-03-28 21:26:19,175 INFO] ------------------------------ [2024-03-28 21:26:19,845 INFO] Predicted: qq 微信 淘宝 Actual: qq 90 0 0 微信 0 206 0 淘宝 0 0 108