Home
Experimenting with Clang optimization, C++17 and loop-unrolling to produce a class based C++17 version of Kokke's AES-C (https://github.com/kokke/tiny-AES-c)
Why bother manually loop-rolling if the compiler will optimize and loop-unroll for you?
It turns out that even using CLang -Ofast, whilst able to significantly close the gap between an unrolled and looping implementation, it still leaves the (optimized) loop-unrolled version 8% faster.
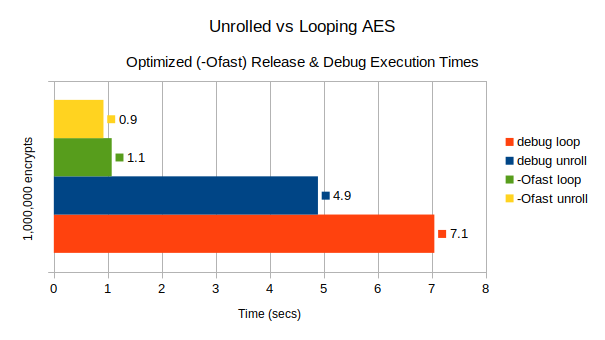
Graph 1. Execution times 1,000,000 encrypts - loop-unrolled vs looping AES (256) implementation. The mean of 6 x 1,000,000 timings were taken with different keys and plain text encrypted AES-256.
N.B. 1 Whilst it is not surprising that loop-unrolling is 30% faster than looping when compiling with CLang in Debug mode - it is interesting to note that the loop-unrolled implementation is still 8% faster than the looping implementation when compiling with CLang in Release mode with the maximum optimization mode selected with -Ofast.
N.B. 2 Using CLang maximum optimization setting -Ofast improved performance by up to 7 fold!
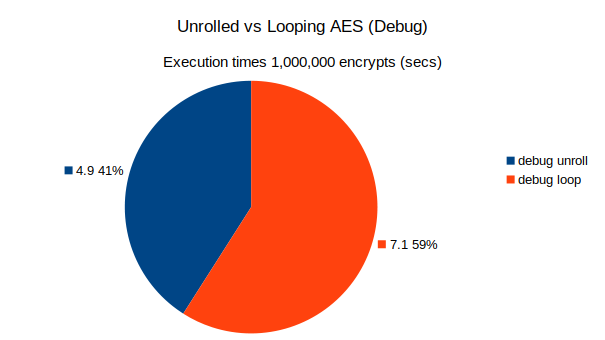
Graph 2. Separating out the data for CLang compiling in CLang Debug Mode
Manual optimization by loop-unrolling improves performance in debug mode...
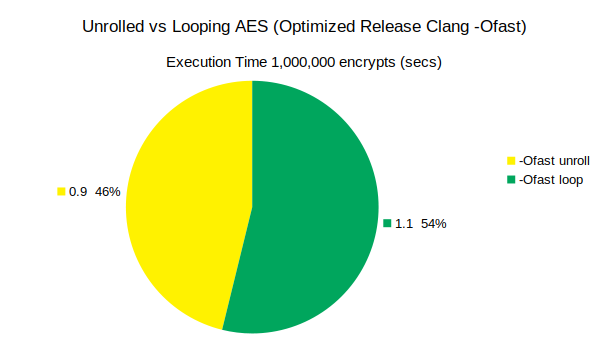
Graph 3. Separating out the data for CLang compiling in Release Mode -Ofast
Manual optimization by loop-unrolling improves performance even with CLang -Ofast