- Challenge Information
- Tools Used
- Data Information
- Understanding the Data set
- Merging and finding correlations
- Conclusion
- References
- I have written most of the statements and references used for the soil information in the README.md file to keep the ipynb files clean.
- I have divided the python notebooks into 5 different notebooks. (Each notebook is having it's own description below)
- Total Time taken to complete this challenge :
Coding- 10 HoursDocumentation- 2 Hours
- Please have a look at the directory structure below :

jupyterlab- For writing python scripts.github- Version Controlling (Private Repository)Python Packages used: Geopandas, Pandas, Matplotlib, KeplerGl, Seaborn, Shapely.
- The Data has been taken from Natural Resources Conservation Service Soils (United States Department of Agriculture) [1]
- Data Description
RaCA_data_columns_expl- This data gives the information about the columns of the general location and pedons dataset and most importantly the breakdown of the RaCA side ID codeRaCA_general_location- This data gives the coordinates (exact locations) of the RCA Site IDs.RaCA_samples- This data contains all the samples of the pedons of each RCA site id with the soil properties in it.RaCA_SOC_pedons- This data contains the information of pedons and number of samples which were taken from each pedon.
What are Pedons?- Pedons are three-dimensional bodies of soil with lateral dimensions large enough to permit the study of horizon shapes and relations. Here a three-dimensional sample of a soil just large enough to show the characteristics of all its horizons. [2]What is a SOC?- Soil Organic Carbon, read more here - Soil organic carbon (SOC) refers only to the carbon component of organic compounds. Soil organic matter (SOM) is difficult to measure directly, so laboratories tend to measure and report SOC. [3]

Picture depecting a Pedon [4]
RaCA site ID - Code
RaCA site ID = CxxyyLzz
C = placeholder character (C,A,X or F)
xx = RaCA Region/old MO number (01 - 18)
yy = statistical group # for MO (number varies by region)
L = land use/land cover type (C=Cropland, F=Forest land, P=Pastureland, R=Rangeland, W=Wetland, and X=CRP)
zz = Plot # within the group
- The best way to start working on data is to know for which locations are you working on.
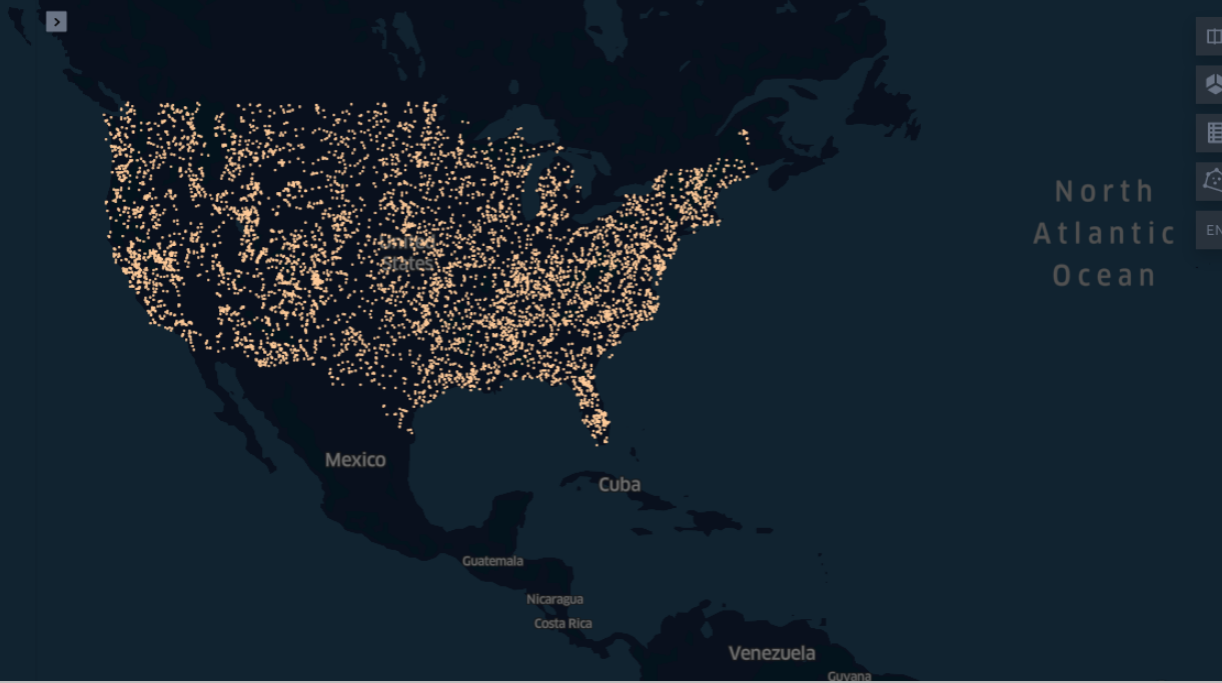
- I imported the csv file into dataframe and converted it to a geodataframe from
data\RaCA_general_location.csv - Using KeplerGl I understood the Points belong to USA, and output can be seen in here or in
output\images\1_locationpoints_usa.png. - I processed the Longitude and Latitude of the data, and created a geodataframe with the geometry column and saved the processed out in geojson format for future use and saved the file in
processed_data\general_location_processed.geojson
{kind=link}
- I imported the csv file into dataframe using the pandas library from
data\RaCA_SOC_pedons.csv - I found some identifiers and I removed the duplicate identifiers from the pedons dataframe which were of no use.
- I selected only the columns which were needed in the requirement along with the identifiers.
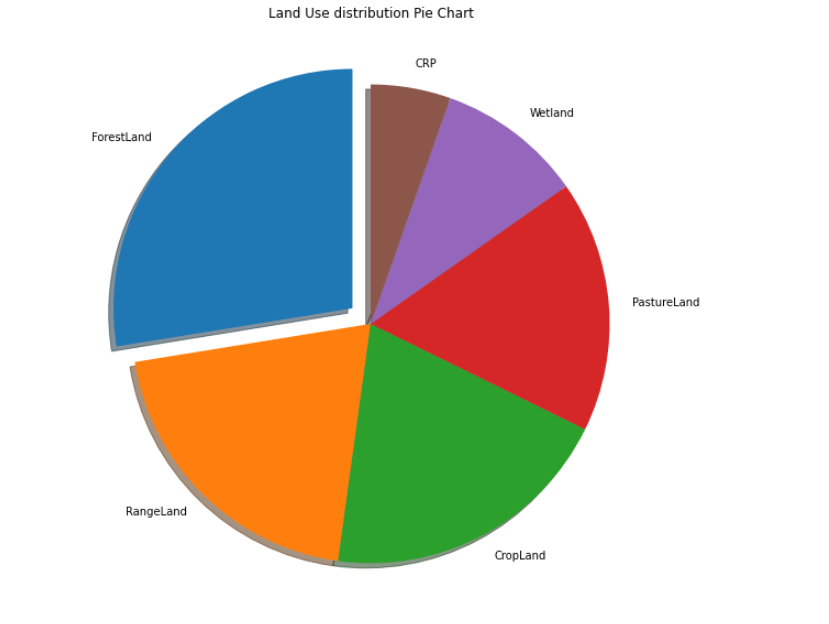
- I fetched the Land Use from the upedon column, and using a pie plot understood the distribution of the pedons(samples) from different LandUse and the output can be seen in here or in
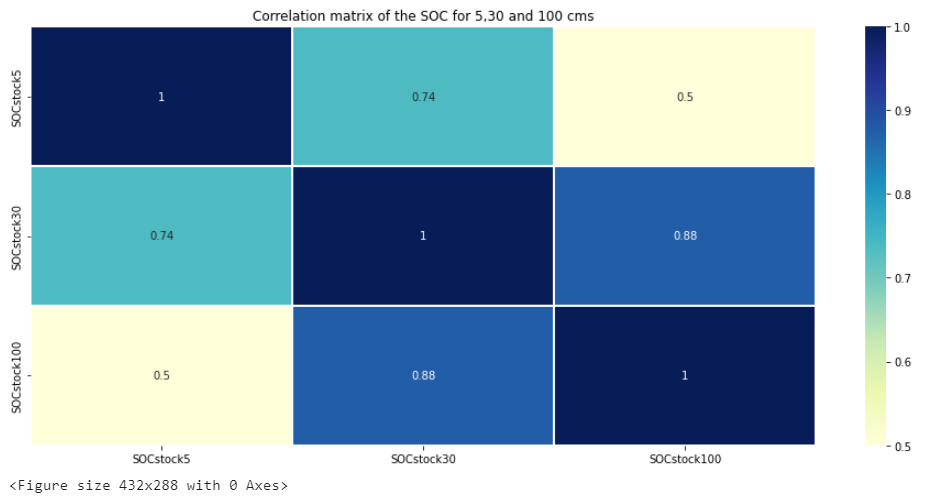
output\images\2_landuse_distribution_pie.png - I plotted the corelation matrix and found out SOCstoc100 and SOCstock30 are highly corelated output can be seen here or in
output\images\2_correlationmatrix_soc.png - I saved the processed dataframe to a csv which will be used further in
processed_data\pedons_processed.csv
{kind=link}
{kind=link}
- I imported the csv file into dataframe using the pandas library from
data\RaCA_samples.csv - I found some identifiers and I removed the duplicate identifiers from the samples dataframe which were of no use.
- I selected only the columns which were needed in the requirement along with the identifiers.
- I found a sample id is duplicated
C0408C011-1and I discarded the sample. - I saved the processed dataframe to a csv which will be used further in
processed_data\sample_data_processed.csv
- I have imported the processed data from the
processed_datafolder. - For Merging the sample and pedon dataframe I used the columns
upedonandrcasiteidand named assamples_pedons_df - For merging the
sample_pedons_dfand thelocation_gdfI used the columnrcasiteid - I merged all three data and stored it as a geojson format as
processed_data\pedon_sample_location.geojsonfile
- I have imported the processed merged data
processed_data\pedon_sample_location.geojsonfile - I found the total na values of each column.
- I took a sample of caco3 and found out the mean for each Land_Use is quite different, so I cannot replace the missing value with the mean of the complete data set.
- I grouped the data with LandUse and using mean of the series I replaced the fillna.
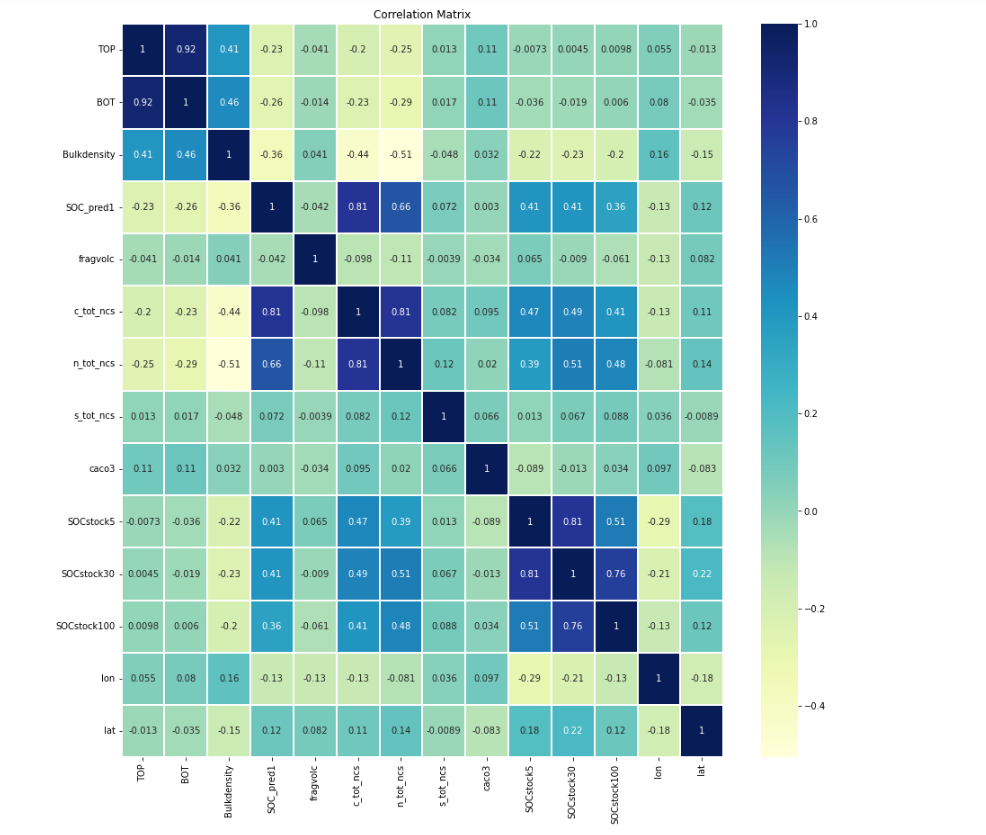
- I plotted the correlation matrix of the complete merged dataset which can be seen here or in
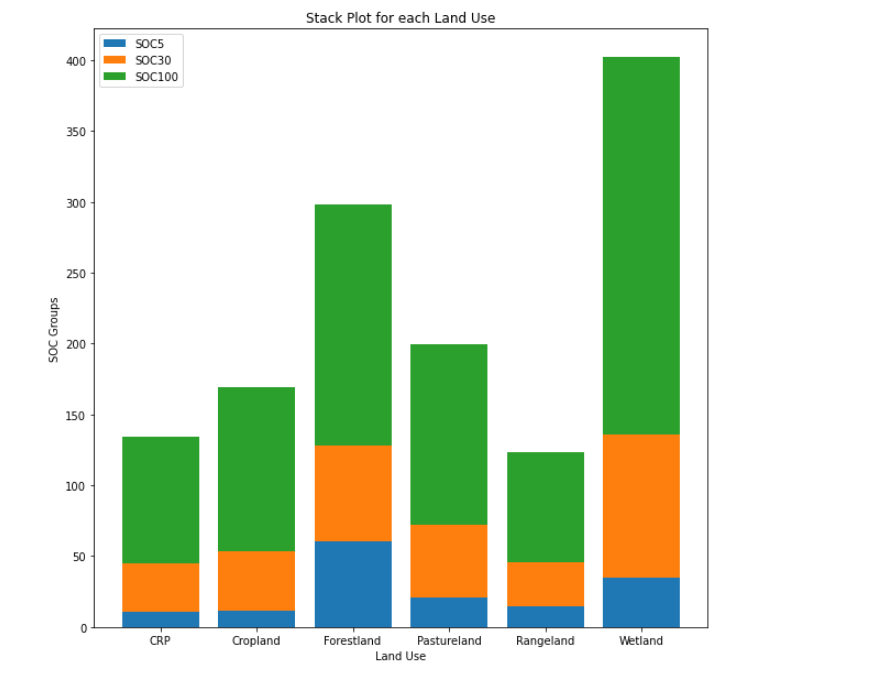
output\images\5_correlation_matrix.png - Using the mean of each SOC (For each LandUse group), I have plottd a stack plot which can be seen here or in
output\images\5_stackplot_soc_landuse.png - I have explained the difference between the Categorical and Numerical values in the markdown field.
- I have saved the final merged data in different formats (ESRIShape, GeoJSON, CSV and HTML-Kelper) in their respective output folders.
- I have used KeplerGL package to observe the pattern of the data, and are listed below :
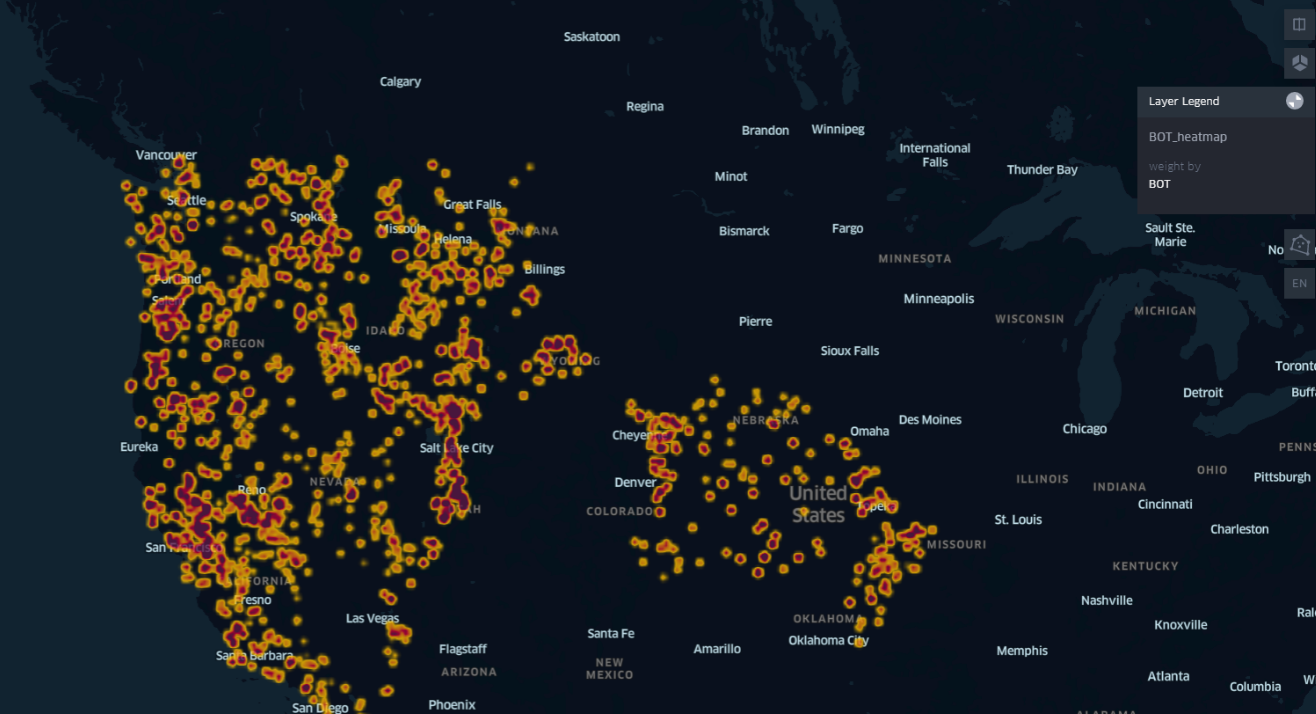
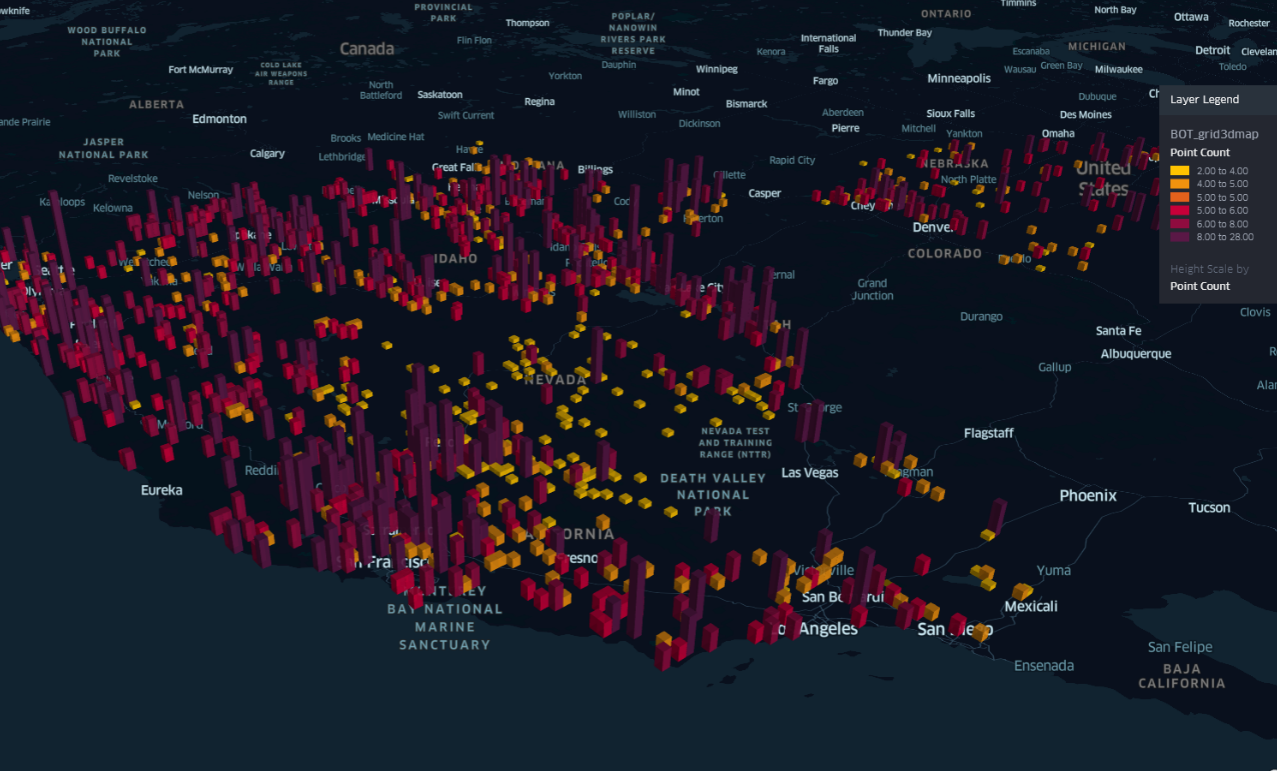
- HeatMap of the BOT (Bottom) Column which show the place where the most depth pedons were taken from, the picture can be found here or in
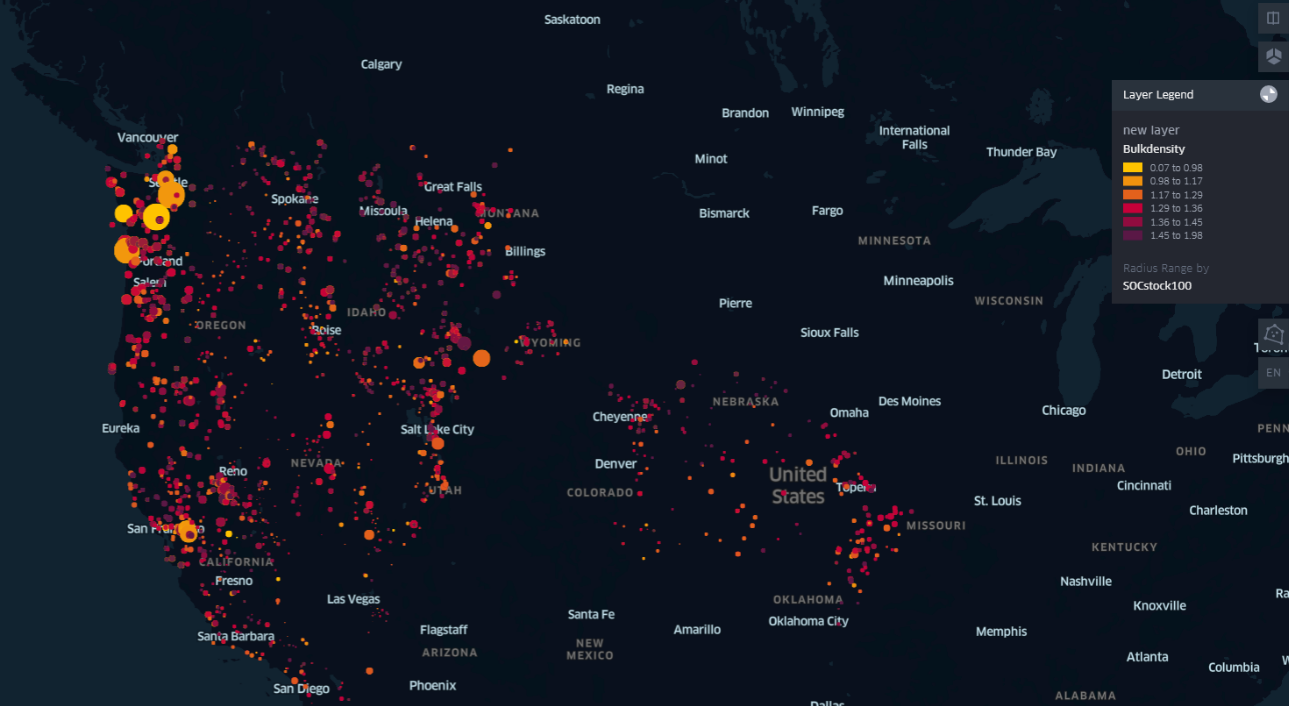
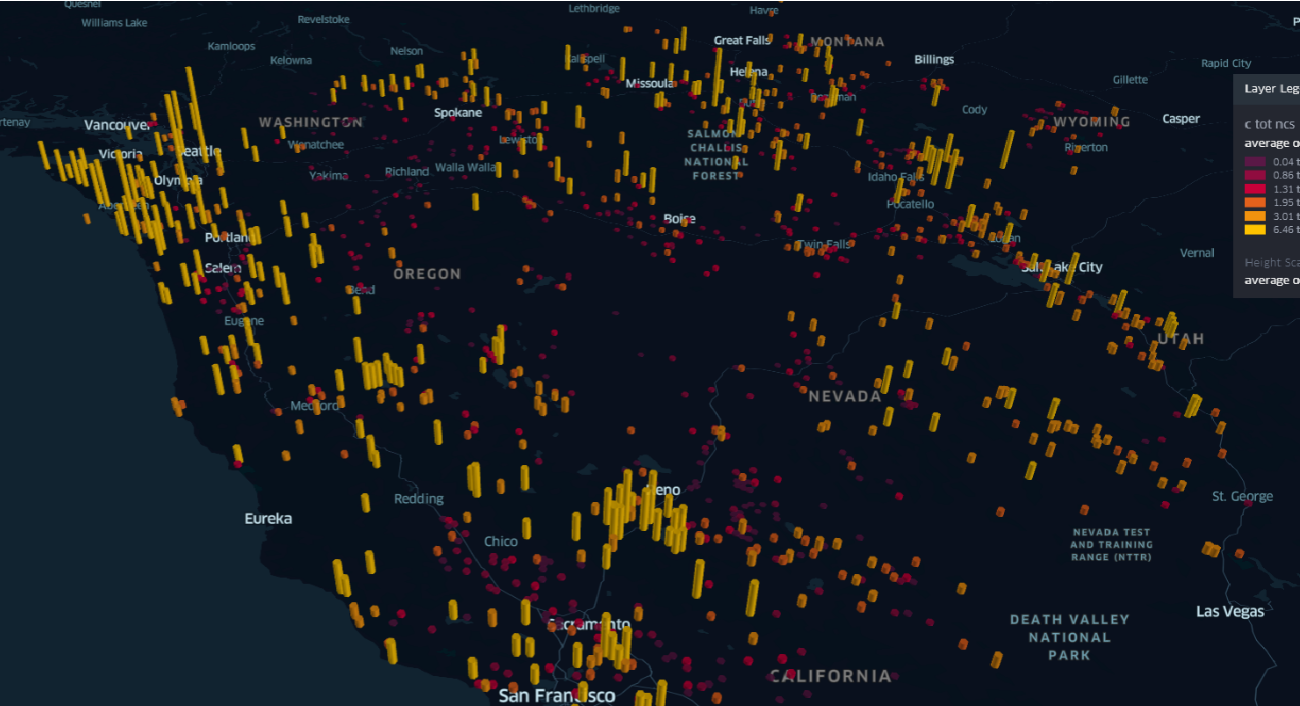
output\images\heatmap_BOT.pngand the same can be seen in the grid3map here or inoutput\images\grid3dmap_BPT.png\ - Radius map of the Bulkdensity and SOCStock100 where the color code will show the bulkdensity and the radius of the point will tell the SOCstock100 content. The pciture can be found here or in
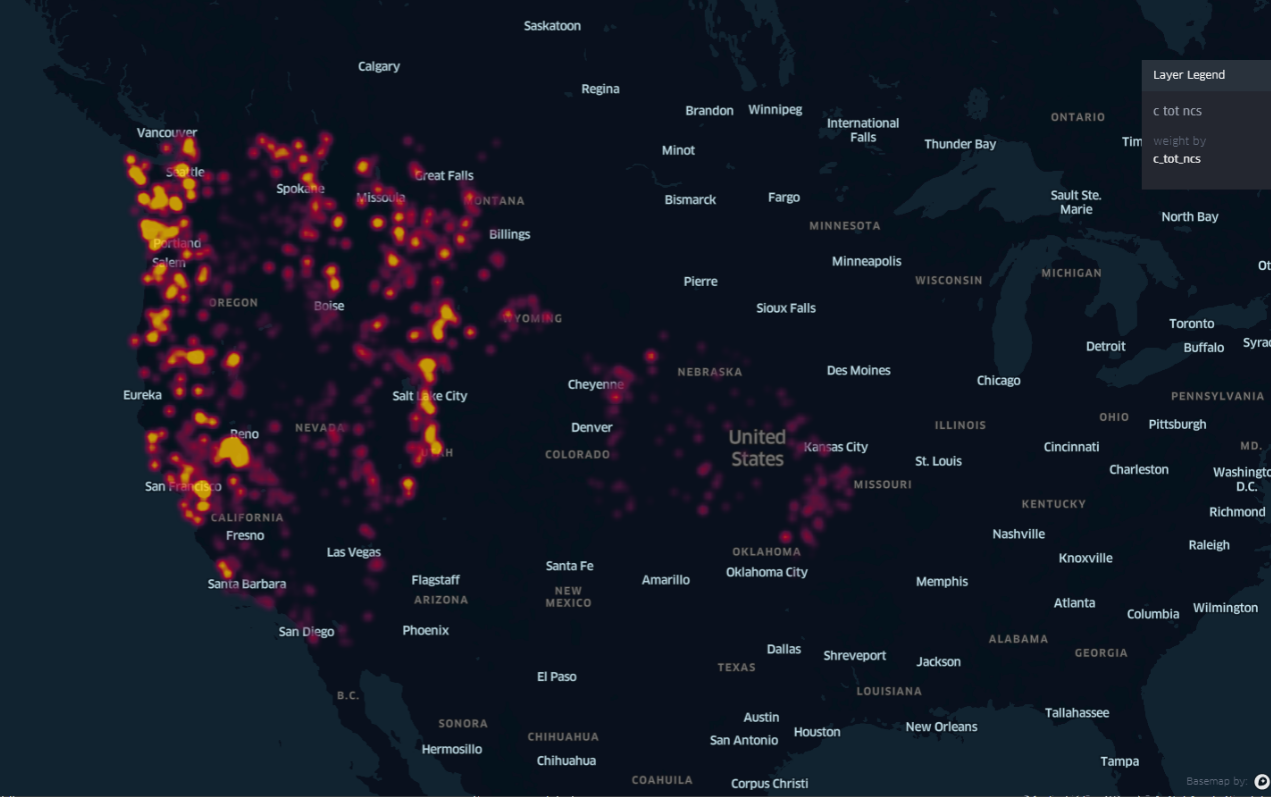
output\images\radiusmap_bulkdensity_SOCstock100.png - Heat map and the grid3dmap of the c_tot_ncs can be found here-heatmap and here-3dmap
or in
output\images\heatmap_c_tot_ncs.pngandoutput\images\grid3dmap_c_tot_ncs.png - Radius map of the SOCstock100 with the Land_Use can be found here or in
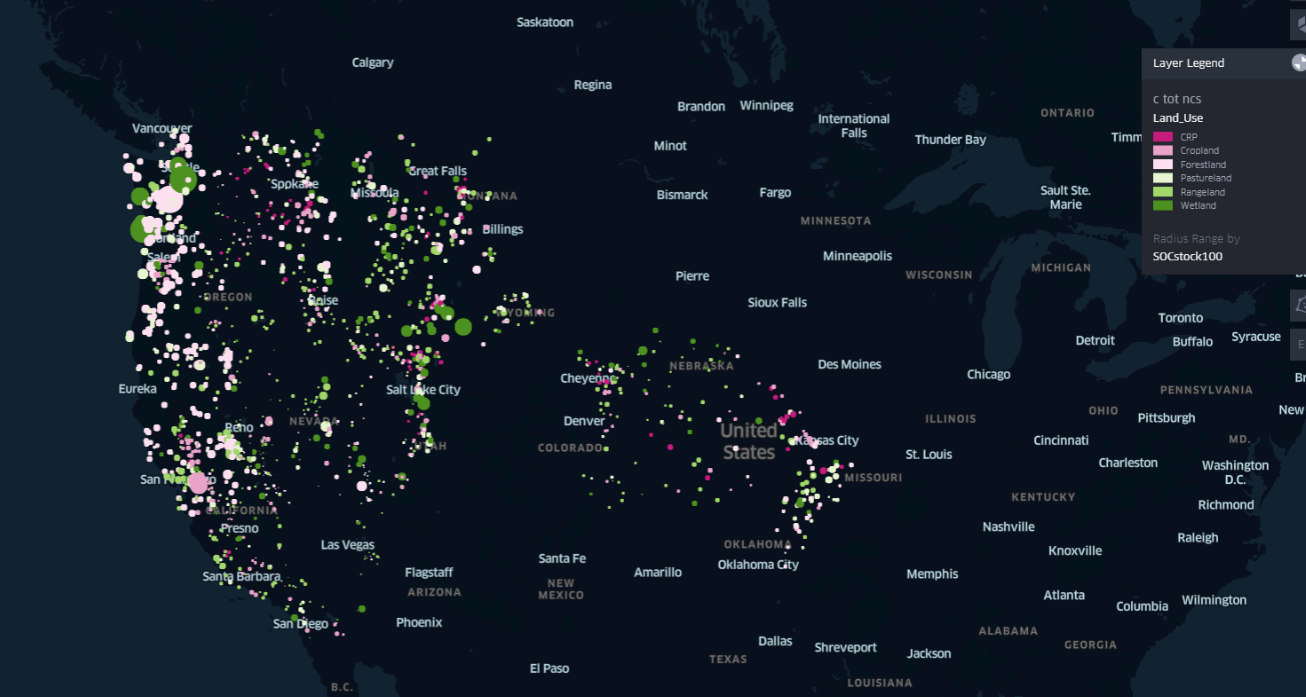
output\images\radiumsmap_LandUse_SOCstock100.png
- HeatMap of the BOT (Bottom) Column which show the place where the most depth pedons were taken from, the picture can be found here or in
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- The West coast of United States of America (Specially Portland and Seattle) have the most Soil Organic Carbon at 100cms (SOCStock100) and the most total combustion carbon (c_tot_ncs).
- We also see a bit of spike in Soil Organic Carbon at 100cms (SOCStock100) and total combustion carbon (c_tot_ncs) in the area near to Salt Lake City.
- [1] https://www.nrcs.usda.gov/wps/portal/nrcs/detail/soils/survey/?cid=nrcs142p2_054164#data_tables
- [2] https://www.sciencedirect.com/topics/earth-and-planetary-sciences/pedon
- [3] https://www.agric.wa.gov.au/measuring-and-assessing-soils/what-soil-organic-carbon#:~:text=Soil%20organic%20carbon%20(SOC)%20refers,to%20measure%20and%20report%20SOC
- [4] https://www.researchgate.net/profile/Eyasu-Elias/publication/343450769/figure/fig3/AS:921214222626816@1596645994352/a-Pedon-solum-and-soil-individual-in-a-landscape-b-a-typical-soil-profile-Source.jpg
{kind=link}