{kind=link}
{kind=link}
Detect emotions in audio with this speech emotion detection project. The system analyzes voice recordings and categorizes them into emotions. Utilizing the RAVDESS dataset, the model is trained to recognize a wide range of emotional expressions using mel spectograms features.
In the realm of audio signal processing, Mel spectrogram stands as a crucial tool for extracting meaningful features from sound waves. The Mel spectrogram is a visual representation of the spectrum of frequencies in an audio signal, but with an emphasis on how the human ear perceives these frequencies.
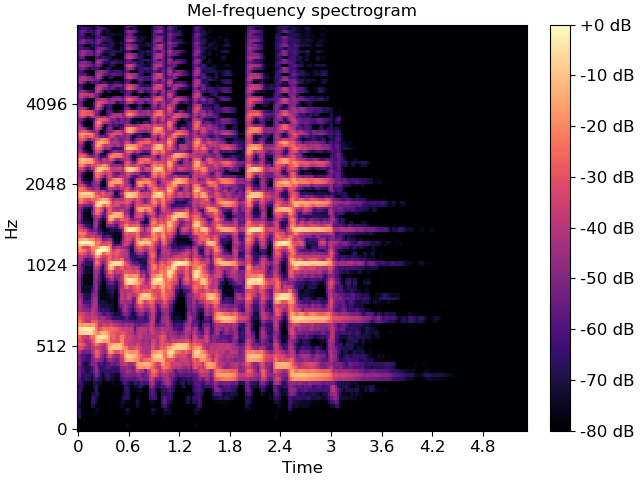
Here's how it plays a pivotal role in the detection of emotions:
- Mel spectrograms divide the audio signal into multiple frequency bands, mimicking the non-linear frequency response of the human ear. This ensures that the representation aligns more closely with how humans perceive different pitches.
- Utilizing Mel spectrograms aids in capturing essential features from the audio, highlighting nuances that are crucial for emotion detection. These features include variations in pitch, intensity, and duration that are indicative of different emotional states.
In this speech emotion detection project, Mel spectrograms are employed as a key component in the feature extraction pipeline. This enables the model to effectively analyze voice recordings and categorize them into emotions creating a robust and accurate system for emotional expression recognition.
Neutral, Calm, Happy, Sad, Angry, Fear, Disgust, Surprised

git clone git@github.com:edworId/speech_emotion.git Edmundo Lopes Silva |
|---|