Cześć, na wstępie chcę zaznaczyć, aby całą pracę włożoną w to repozytorium potraktować bardziej jako obszerny artykuł mający na celu wprowadzić czytelnika w teorie budowy kompilatora. Zebrane tutaj informacje są krótkim podsumowaniem zdobytej wiedzy na temat procesu kompilacji po stronie frontendu. Przykłady omawiane są w języku C-podobnym oraz oczywiście w języku polskim ;). Możliwe, że artykuł nie pokrył wszystkich tematów związanych z kompilacją, jednak dopiąłem wszelkich starań by tak było. Artykuł będzie co jakiś czas ulepszany, dodam, że chętnie przyjmę jakiekolwiek sugestie drogą mailowa.
- 1.0. Preprocessing
- 1.1. Analiza leksykalna - skanowanie
- 1.1.0 Jak działa lekser?
- 1.1.1 Wyrażenia regularne
- 1.1.2 NFA - Niedeterministyczny Automat Skończony
- 1.1.3 Maximal Munch
- 1.1.4 DFA - Deterministyczny Automat Skończony
- 1.1.5 Tranzycje
- 1.1.6 Flex
- 1.1.7 Identyfikatory
- 1.2. Analiza składniowa - parsowanie
- 1.2.0 Jak działa parser?
- 1.2.1 Gramatyka bezkontekstowa
- 1.2.2 Niejednoznaczność
- 1.2.2.0 Niejednoznaczność Priorytetu
- 1.2.2.1 Wiszący If-Else
- 1.2.2.2 Gramatyka Niejednoznaczna
- 1.2.3 Drzewo składniowe
- 1.2.4 Hierarchia Chomsky’ego
- 1.2.5 Analiza zstępująca
- 1.2.5.0 Przeszukiwanie wszerz
- 1.2.5.1 Przeszukiwanie wgłąb
- 1.2.5.2 LL(1)
- 1.2.5.3 Tablice LL(1)
- 1.2.5.4 Zbiory First i Follow
- 1.2.6 Analiza wstępująca
- 1.2.6.0 Redukcje, Przesunięcia, Uchwyty
- 1.2.6.1 Gdzie szukamy uchwytów?
- 1.2.6.2 Jak szukamy uchwytów?
- 1.2.6.3 Automaty, Elementy LR(0)
- 1.2.6.4 LR(0)
- 1.2.6.5 SLR(1)
- 1.2.6.6 Niejednoznaczność SLR(1), SLR(k)
- 1.2.6.7 LR(1)
- 1.2.6.8 LALR(1)
- 1.2.7 Bison
- 1.3. Analiza semantyczna
- 1.3.0 Zasięg widoczności
- 1.3.0.0 Zakres statyczny
- 1.3.0.1 Zakres dynamiczny
- 1.3.1 System typów
- 1.3.0 Zasięg widoczności
Pierwszym etapem w drodze do utworzenia programu jest napisanie kodu źródłowego. Na tym etapie nie dzieje się zbytnio dużo. Otwieramy ulubiony edytor tekstu lub dedykowane IDE. Warto wspomnieć, że podczas pracy nad danym projektem staramy trzymać się pewnej hierarchi. Każdą inną różniącą się funcjonalność trzymiemy w osobnych plikach, pliki o podobnej charakterystyce trzymamy w jednym projekcie, a ogół projektów trzymamy w rozwiązaniu (rekomendowana hierarchia plików w Visual Studio), natomiast produkt końcowy składać się będzie zwykle z różnych rozwiązań. Przykładem może być firma, która zatrudnia dwie grupy programistów, w której jedna zajmuje się rozwiązaniami nad GUI, a druga nad rozwiązaniami dotyczącymi mechaniki aplikacji, obie grupy pracują nad inną specyfikacją aplikacji (wspomniany przykład to jedynie uproszczenie całej sytuacji, w rzeczywistości jest to bardziej skomplikowane).
Kompilacja to proces tłumaczenia kodu źródłowego napisanego w języku A do kodu w języku B, najczęściej kompilowane są języki wyższego poziomu do języka niższego poziomu (lub kodu maszynowego). Kompilator to złożony program liczący często setki tysięcy linii kodu. Pisanie takiego programu lub jego zrozumienie nie jest proste, większość naukowców lub programistów profesjonalnie zajmujących się współtworzeniem kompilatora często nigdy go w pełni nie kończą. Niemniej jednak osoby związane z programowaniem, które pracują z jakąkolwiek formą obliczeń lub zajmujacych się algorytmiką powinny znać chociażby podstawy kompilatora. Dodatkowym pobocznym zadaniem kompilatora jest interpretacja argumentów, które dostaje w formie linii komend. Nie będziemy natomiast zajmować się interfejsem ze względu na podobną metodykę, którą wprowadzimy w głównej części programu.
Kompilator przetwarza kod źródłowy (source language) na kod w języku docelowym (target language), wyróżniamy jeszcze jeden język, mianowicie język, za pomocą, którego napisany został kompilator. Oficjalnie językiem pierwszego kompilatora był kod maszynowy, ponieważ nie istniał wtedy jeszcze inny kompilator za pomocą, którego moglibyśmy skompilować nasz kod. W momencie, w którym mieliśmy nasz pierwszy kompilator powstawały coraz to nowsze i wydajniejsze wersje (proces określany jako bootstraping).
W przypadku języka C w pierwszym etapie kompilacji specjalny program nazywany preprocessorem parsuje pliki źrodłowe w celu:
- Załączenia kodu z plików wskazanych dyrektywą #include,
- Konwersji makro definicji na stałe wskazane przez dyrektywę #define,
- Zamiany makro definicji na kod,
- Włączenia lub wyłączenia danej części kodu wskazanej dyrektywą #if, #elif i #endif.
Warto wiedzieć, że istnieje możliwość stworzenia makro funkcji z nieznaną liczbą argumentów oraz makra generyczne, które dodatkowo utrudniają pracę preprocesorowi. GCC umożliwia spojrzenie na to jak nasz kod został sparsowany przez preprocessor:
gcc -E <input>.c -o <output>.iW następnym etapie omówiona zostania analiza leksykalna, nazwa ta pochodzi od programu, który ją wykonuje czyli leksera inaczej nazywanego skanerem.
Proces skanowania rozpoczyna się od momentu, w którym lekser na wejście dostaje gotowy plik podczas, którego tnie kod źródłowy na leksemy, leksemami nazywamy pasujący do danego wyrażenia ciąg znaków, w których skład wchodzą słowa kluczowe, liczby, znaki specjalne itd. Jak później można się przekonać, leksery ściśle współpracują z parserami. Mając dany leksem, skaner konwertuje go na istniejący token w przypadku gdy takowy istnieje. W zależności od języka i dla wygody tokeny są grupowane, przykładowo int, float i char będą należały do tej samej grupy tokenów skojarzonych z typami zmiennych. Żeby zobaczyć czym są tokeny oraz, że niektóre z nich posiadają atrybuty warto spojrzeć na poniższy kod:
while (137 < i)
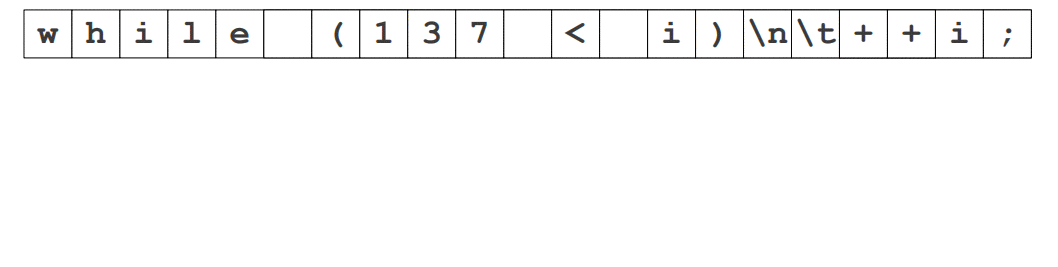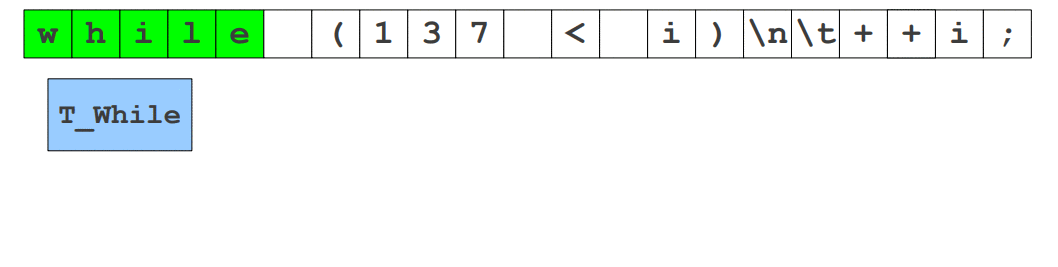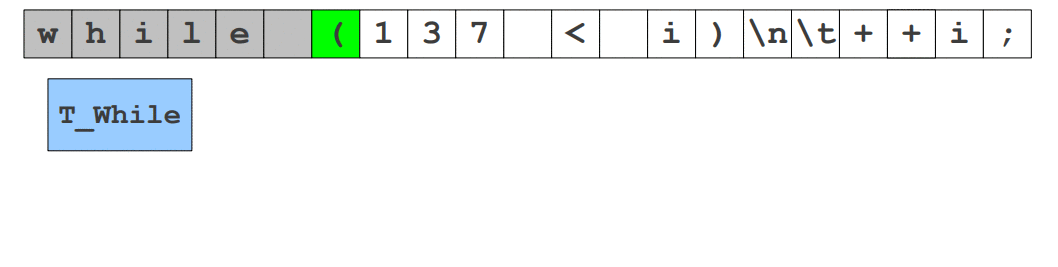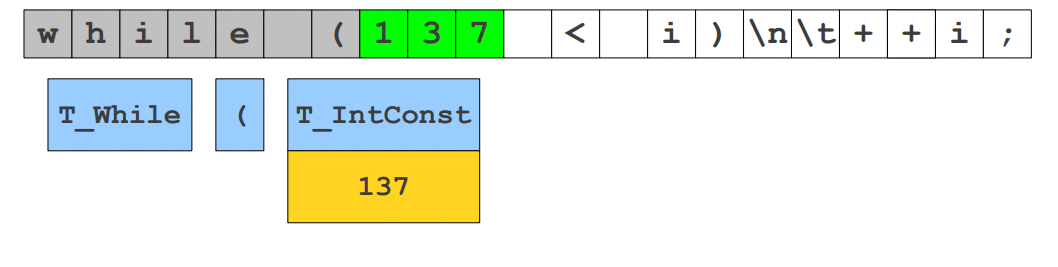
++i;W wielu źródłach słowo leksem używane jest jako zamiennik słowa token, natomiast starsze źródła podają, że leksem jest ciągiem znaków i nabiera on znaczenia w momencie gdy znaleziony został odpowiadający mu token. Początkowo while będzie leksemem składających się z pięciu znaków, jednak zostanie ono zamienione na token T_While (reprezentujące słowo kluczowe), który informuje nas o tym, że jest to deklaracja pętli. W powyższym kodzie liczba 137 jest leksemem składającym się z cyfr, natomiast dopasowana, jest tokenem reprezentującym liczbę całkowitą T_IntConst posiadającym atrybut , w której przechowana zostanie liczba. Poniższa animacja obrazuje to jeszcze lepiej. Poniższą animacje (jak i większość, które tu zobaczysz) stworzyłem na bazie prezentacji o analizie leksykalnej wykładanej na Stanfordzie.
 Znaki specjalne takie jak klamry i nawiasy, które wzbogacają gramatykę języka z reguły posiadają swój własny odpowiadający im token (zazwyczaj słowa kluczowe również posiadają swój własny token), dodatkowo tokeny należace do tej samej grupy są po prostu grupowane (tak jak wcześniej wspomniane tokeny typów zmiennych), natomiast nic nie znaczące spacje, tabulacje lub komentarze są pomijane. Inny przykład tym razem z wikipedii świetnie obrazuję jak lekser przeanalizował kod źródłowy:
Znaki specjalne takie jak klamry i nawiasy, które wzbogacają gramatykę języka z reguły posiadają swój własny odpowiadający im token (zazwyczaj słowa kluczowe również posiadają swój własny token), dodatkowo tokeny należace do tej samej grupy są po prostu grupowane (tak jak wcześniej wspomniane tokeny typów zmiennych), natomiast nic nie znaczące spacje, tabulacje lub komentarze są pomijane. Inny przykład tym razem z wikipedii świetnie obrazuję jak lekser przeanalizował kod źródłowy:
int suma = 3 + 2;| Leksemy | Kategoria |
|---|---|
| int | Identyfikator typ zmiennej całkowitej |
| suma | Identyfikator zmiennej |
| = | Operator przypisania |
| 3 | Literał całkowitoliczbowy |
| + | Operator dodawania |
| 2 | Literał całkowitoliczbowy |
| ; | Znacznik końca wyrażenia |
Omawiane wcześniej przykłady są jednymi z najprostszych do rozwiązania dla skanera. Weźmy pod uwagę fakt, że w C++ jest możliwość tworzenia szablonów, dla poniższego przykładu patrząc z perspektywy leksera wyodrębnienie zagnieżdżonego std::vector nie jest prostym zadaniem:
std::vector<std::vector<int>> vecRównież gdy ktoś użył słów kluczowych jako nazwy zmiennej w języku Pascal:
if then then then = else; else else = ifW powyższych przykładach nie należy zastanawiać się nad tym jak skaner odróżnił słowa kluczowe od identyfikatorów bo po prostu tego nie zrobił, na tym etapie skaner ma za zadanie przeskanować tekst i zwrócić otrzymane w wyniku tej operacji tokeny. Cała więc trudność tkwi w napisaniu odpowiednich reguł opisujących leksem, reguły te przyjeły nazwę wyrażeń regularnych. Wyrażenia regularne mają za zadanie znaleźć szukane przez nas ciągi znaków przez, które lekser będzie w stanie zwrócić odpowiedni token. Przykładem może być leksem reprezentujący liczbę, tworząc wyrażenie regularne zakładamy, że będzię to ciąg znaków 0-9, cytując "...specyfikacja języka programowania obejmuje szereg reguł które definiują składnię leksykalną. Składnia leksykalna jest zazwyczaj opisana za pomocą wyrażeń regularnych. Definiują one zbiór możliwych sekwencji znakowych które tworzą pojedyncze tokeny. Lekser przetwarza oddzielone znakami białymi ciągi znaków i dla każdego ciągu znaków podejmuje akcję zazwyczaj produkując token, bądź ogłasza błąd analizy leksykalnej....". Wiedząc to wszystko nasuwa się pytanie: jak napisać swój własny skaner? Zacznijmy od tego, że nikt nie piszę własnych lekserów od zera, są ku temu dwa powody: ilość czasu jaką trzeba było by poświęcić na napisanie kodu od zera oraz błędy, które bardzo prawdopodobnie pojawią się podczas pisania na piechotę. Obecnie do pisania lekserów używa się generatorów. Do stworzenia skanera posłużyć się można programem Flex, który wygeneruje nam nasz własny kod skanera (kod skanera w języku C, ponieważ brakuje nam jeszcze kodu parsera gdzie całość zostanie skompilowana jako jeden program). Flex (Fast Lex) to następca oraz nowsza alternatywa wobec generatora Lex. Jednak zanim napiszesz swój własny skaner, warto zobaczyć jak wyrażenia regularne zostały zaimplementowane.
Wyrażenia regularne (regular expression) używane są wszędzie tam gdzie w ciągu znaków zależy nam na wyszukaniu słowa klucza. Nic więc dziwnego, że używane są w różnego typu programach skanujących tekst. Składnią regexów są tzw. metaznaki w skład, którego wchodzi alfabet, cyfry lub znaki specjalne. Wyrażenia regularne najlepiej pokazać na przykładach:
| Wyrażenie regularne | Opis | Pasujący ciąg znaków |
|---|---|---|
| while | Brak znaków specjalnych | while |
| [abc] | Jakakolwiek litera ze zbioru {a, b, c} | a, b, c |
| [a-z] | Jedna mała litera od a do z | a, b, c, ... x, y, z |
| a*b | 0 lub więcej wystąpień a oraz litera b | b, ab, aab, aaab... |
| (a|c)b | a lub c oraz b | ab, ac |
| (+|-)?[0-9]+ | Liczba całkowita bez znaku lub z znakiem +/- | 4, -18, +389, 258963 |
Warto wspomnieć, że wyrażenia regularne posiadają swoje ograniczenia, jednym z głównym problemów jest zliczanie wystąpień wywiązująych się z teorii pumping lemma. Przypuśćmy, że szukamy takiego słowa, które z lewej i prawej strony ma tyle samo wystąpień znaku a, natomiast pośrodku oczekujemy znaku b. Pasujące słowa to np. aabaa, aba, aaaabaaaa. Niestety, ale tego typu reguły nie jesteśmy w stanie uzyskać za pomocą regexów. Jedynie co moglibyśmy zrobić to wyszukać znaną nam liczbę wystąpień po lewej i prawej stronie lub nieznaną liczbę n wystąpień po lewej stronie i m wystąpień po prawej stronie. Wspomniany problem nie zalicza się do "składni gramatyki bezkontekstowej" (o tym już za chwilę). Wyrażenia regularne mogą zostać zaimplementowane za pomocą automatów skończonych (finite automata), w której wyróżniamy dwa główne NFA (Nondeterministic Finite Automata) i DFA (Deterministic Finite Automata). Automaty najlepiej wytłumaczyć obrazując ich działanie. Na poniższej animacji okrąg oznacza stan (state), w którym się znajdujemy, natomiast strzałka (transition) oznacza przejście w inny stan gdy zajdzie podany warunek, ostatni znów podwójny okrąg wskazuje na stan akceptacji (accepting state), automat akceptuje stringa jesli znajduje się w stanie akceptacji (na poniższych trzech animacjach przedstawiony jest NFA).
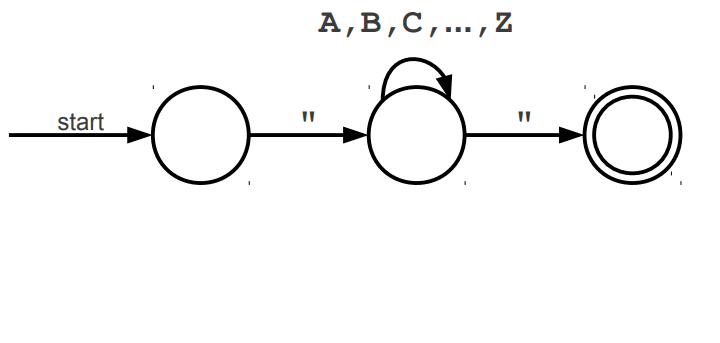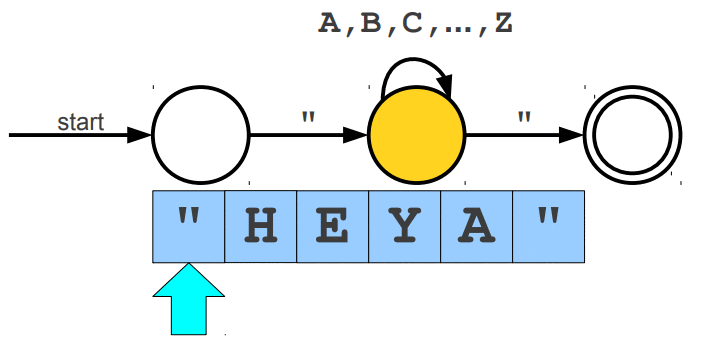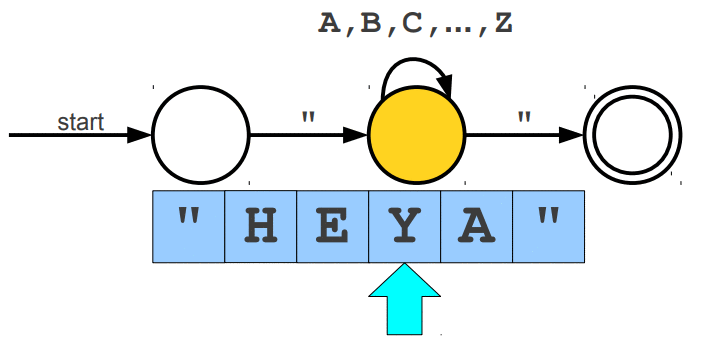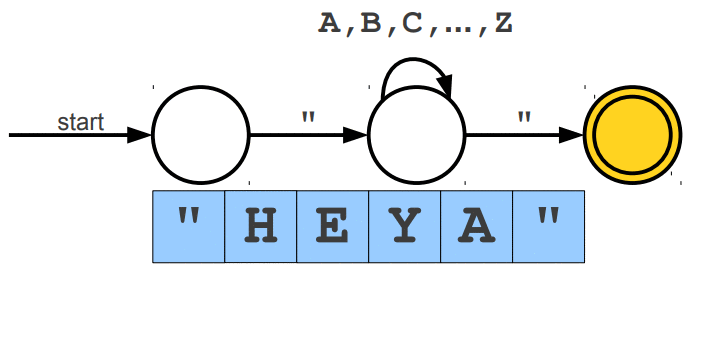
Poniżej animacje przejść w automatach, które nie zaakceptowały wejścia, w pierwszej brakuje kolejnego przejścia na końcu stanu akceptacji, natomiast w drugiej brakuje warunku przejścia dzięki któremu przeszlibyśmy do stanu akceptacji.
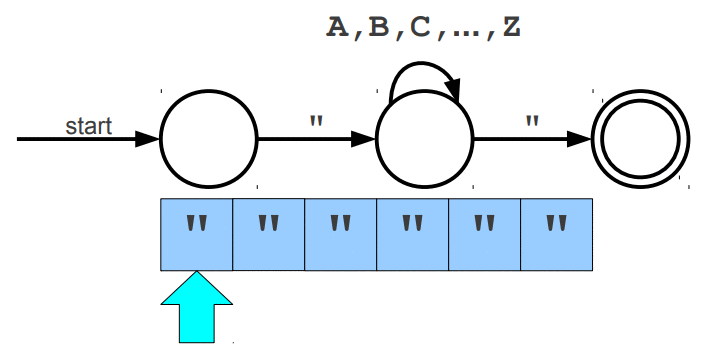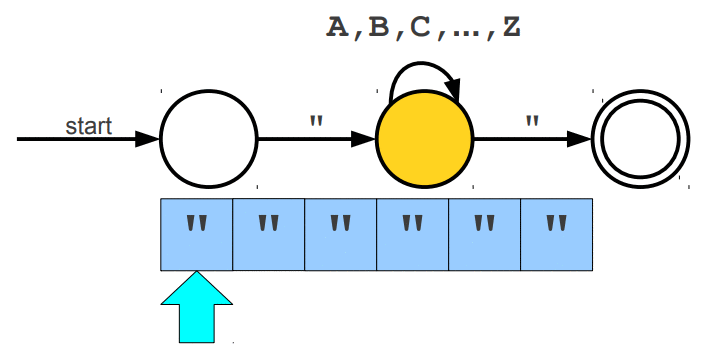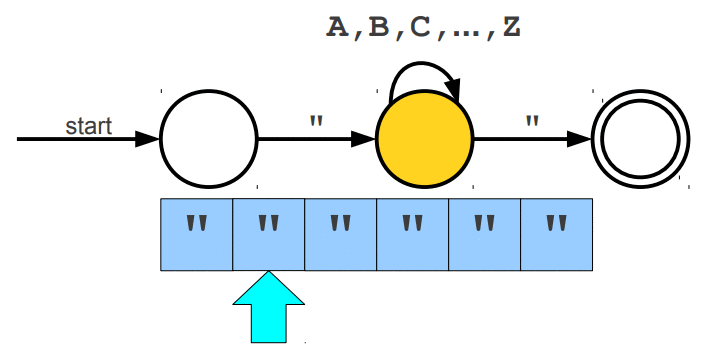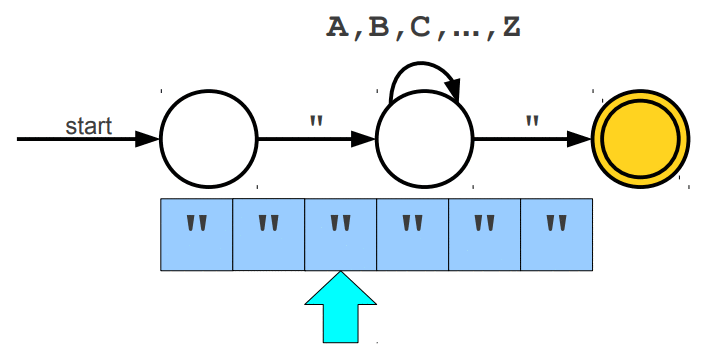
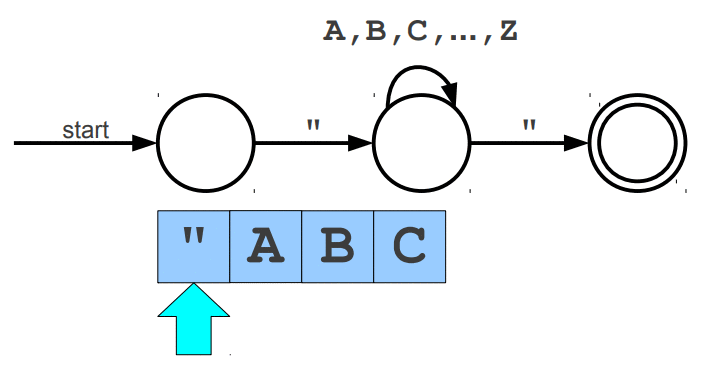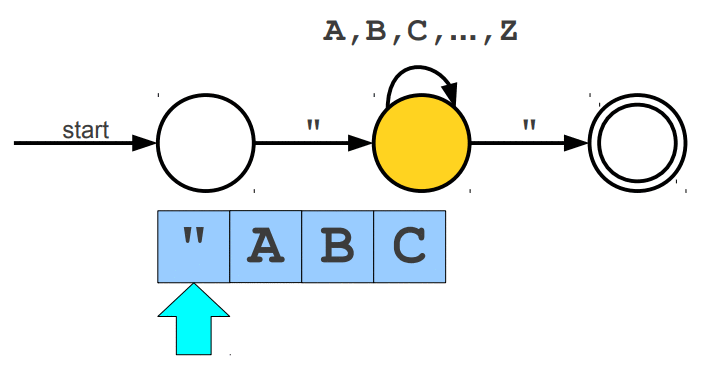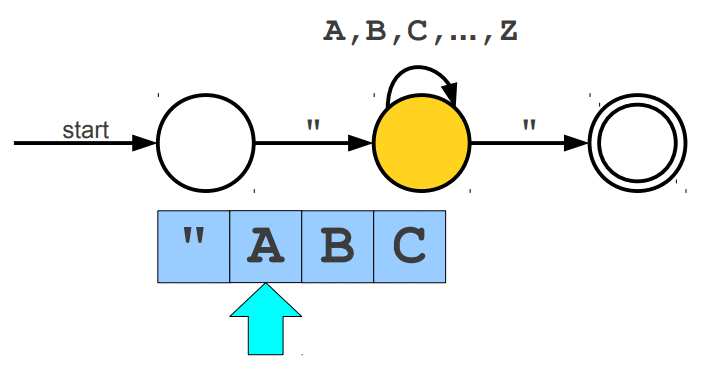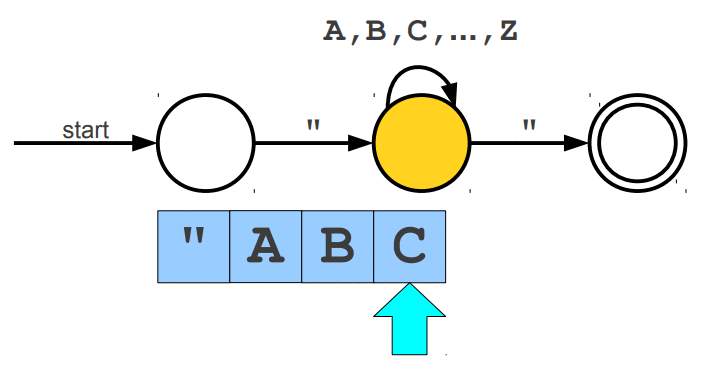
Cytując "Celem automatu jest rozstrzygnięcie w skończonej ilości kroków, czy dowolne słowo należy, czy też nie należy do języka badanego przez automat. Teoria automatów jest efektem badań zapoczątkowanych przez A. Turinga. Automat reaguje na określone sygnały, zmieniając swój stan. Jeśli ustalimy, że sygnały będą reprezentowane przez poszczególne litery alfabetu, zdefiniujemy stan początkowy automatu oraz dopuszczalne stany końcowe, to automat może testować dowolne słowo, startując ze stanu początkowego. Słowo zostanie rozpoznane przez automat i uznane za poprawne, jeżeli rezultatem działania będzie założony stan końcowy."
Na początku kilka faktów:
- każde wyrażenie regularne jesteśmy w stanie zamienić na NFA
- mając stringa o długości m jesteśmy w stanie znaleźć słowo klucz w czasie O(mn^2)
Dlaczego NFA i DFA są tak mocno związane z wyrażeniami regularnymi? Głównie ze względu na prostotę z jaką możemy ukazać problem za pomocą stanów i przejść po grafie. DFA to automat, który szczegółowo opisuję każdy węzeł oraz jego jedno przejście (rozgałęzienie). NFA natomiast traktowane jest jako "symboliczna" i "skrócona" wersja DFA. W automacie niedeterministycznym, dla danego stanu, nie jest wymaganym by wychodziło dokładnie jedno przejście. Takich przejść może nie być, może być jedno, lub może być ich wiele. Podobnie, automat niedeterministyczny może mieć wiele stanów początkowych. NFA będąc w danym stanie z, którego nie ma juz przejścia zmuszone jest wrócić się po węzłach tak aby znaleźć odpowiednią tranzycję do wykonania, stąd szybkość algorytmów bazujących na NFA jest stosunkowo wolniejsza. Wyrażenia regularne zaimplementowane za pomocą DFA wykonują się szybciej od tych zaimplementowanych w sposób NFA, jednakże minusem jest większa ilość pamięci, której potrzebują. Swoją drogą, skoro mamy kilka przejść z jednego węzła tak naprawdę nie wiemy, które się wykona stąd właśnie nazwa "niedeterminisyczny" automat skończony i stąd potrzeba wracania się po stanach (backtracking) w przypadku podjęcia złej decyzji. Dla ciekawych tematem polecam zobaczyć czym jest Automat Büchiego
Wyrażenia regularne to nie tylko szukanie klucza w stringu, ale szukanie najdłuższego pasującego klucza. "Maximal Munch" to inaczej "The Longest Match", najdłuższe pasujące wyrażenie. Mając wiele wyrażeń regularnych w jaki sposób zaimplementować "Maximal Munch"? Trzy niezbędne czynności to:
- zamiana wyrażeń regularnych na NFA
- uruchomienie wszystkich NFA równocześnie, zachowując ostatni wynik (last match)
- gdy wszystkie automaty są w stanie, w którym nie ma przejść to zwróć last match i zacznij szukać ponownie w miejscu, w którym skończyłeś
Przypuśćmy, że mamy sytuacje, w której analizujemy ciąg znaków DOUBDOUBLE oraz, że mamy do dyspozycji trzy tokeny T_Do, T_Double, T_Mystery, które reprezentują kolejno: słowo kluczowe do, słowo kluczowe double, string zawierający jedną literę małą lub dużą. Token o najwyższym priorytecie umieszczony jest najwyżej. Animacja przedstawiająca nasz problem:
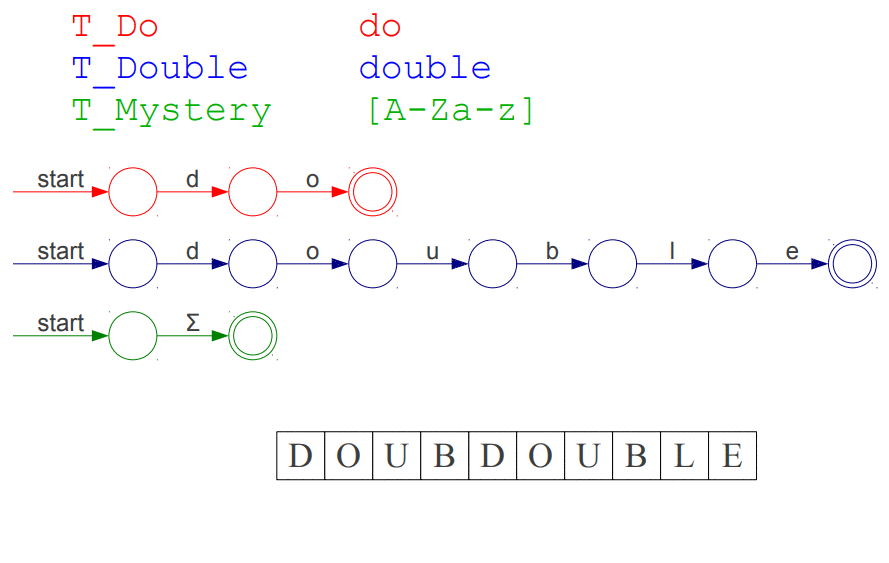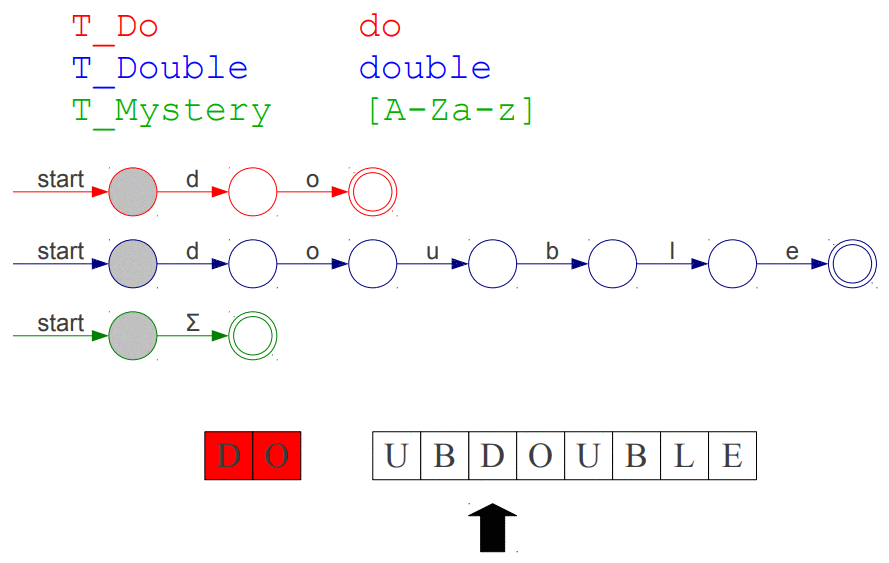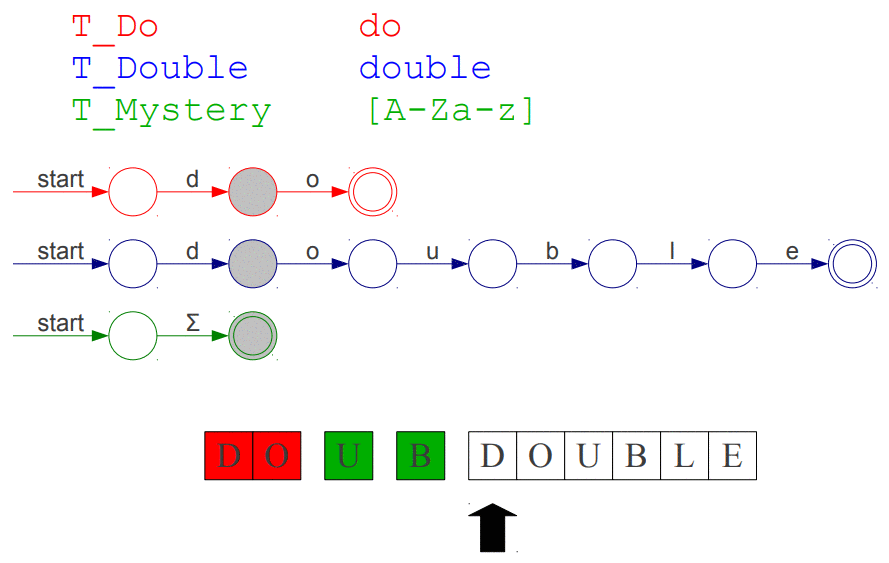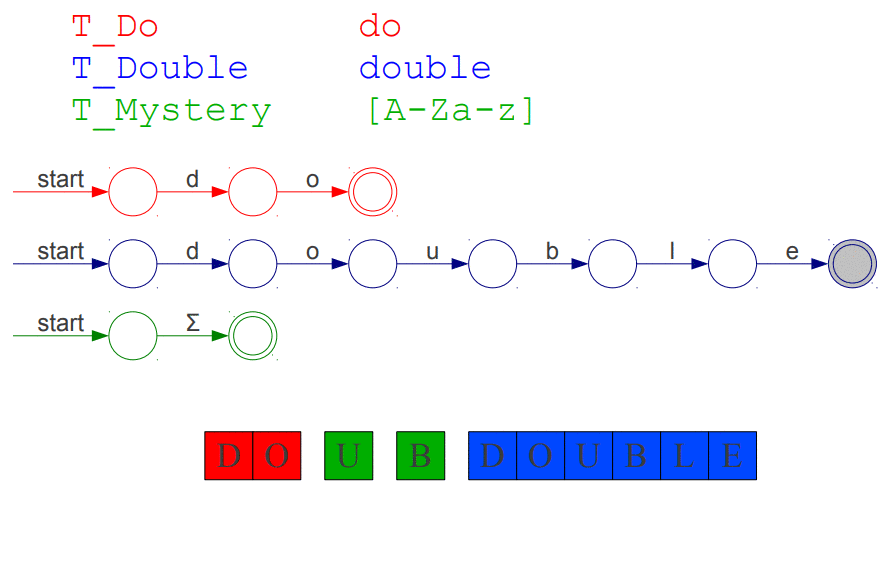
Powyższa animacja być może i wygląda na trzy automaty deterministyczne uruchomione jednocześnie jednak w rzeczywistości ukazuje ona jak NFA działa "wewnątrz", starajmy się raczej wyobrazić, że nasz punkt początkowy jest jeden od którego wychodzą trzy przejścia do odpowiednich węzłów (jeden węzeł "start").
Kilka faktów:
- każde wyrażenie regularne jesteśmy w stanie zamienić na DFA (najpierw na NFA a później na DFA)
- mając stringa o długości m jesteśmy w stanie znależć klucz w czasie O(m)
Główna różnica między NFA to taka, że w tym przypadku posiadamy jeden stan początkowy, jedno przejście z każdego stanu oraz jeden stan akceptacji. Siła automatów niedeterministycznych jest dokładnie taka sama, jak deterministycznych, dla każdego niedeterministycznego automatu skończonego istnieje równoważny mu automat deterministyczny. Wyrażenia regularne zaimplementowane na wzór DFA są szybkie jednak mocno obciążają pamięć (często używana jest hybryda). Jeśli już jesteśmy przy automatach skończonych to warto wspomnieć, że zwykle automaty te podczas skanowania tekstu posiadają tzw. lookahead character tj. znak aktualnie rozpatrywany oraz jeden znak wprzód (w wielu przypadkach znacznie ułatwia to skanowanie i podejmowanie decyzji wykonywanych przez automat).
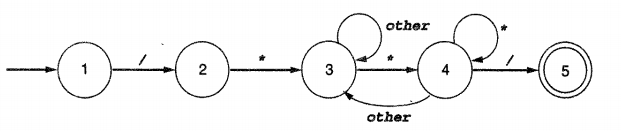
/* Poniżej przestawiam DFA
do rozróżniania komentarzy
wieloliniowych w C.
*/
Dla zainteresowanych tematem polecam sprawdzić jak działają automaty Mealy’ego, Moore’a, legendarną maszynę Turinga oraz sposób w jaki możemy przeprowadzać działania na automatach utworzonych z wyrażen regularnych - Thompson's construction.
Tak jak wspomniałem aby przejście z jednego stanu do drugiego zostało wykonane musi zostać spełniony warunek dla danej tranzycji. Jeśli chodzi o deterministyczne automaty skończone sprawa wydaje się jasna, aby przejść do danego stanu pobieramy kolejny znak z stringa następnie wykonujemy przejście dla istniejącej tranzycji. W przypadku gdy automat znajdując się w stanie s nie posiada tranzycji dla danego znaku zgłaszany jest błąd analizy leksykalnej. W przypadku NFA istnieje możliwość wystąpienia tzw. ε tranzycji, gdzie (jak można się później przekonać w artykule) ε (epsilon) to symbol dowolny oznaczający pustego stringa. ε tranzycja pozwala na zmiane stanu w automacie bez pobierania symboli z wejścia. Żeby to lepiej zoobrazować zobaczcie poniższy automat NFA dla wyrażenia regularnego a*:
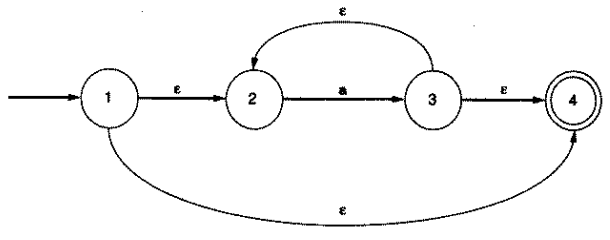
Przykładową ε tranzycją będąc w stanie 1 jest tranzycja do stanu 2 i 4 tj. będąc w stanie 1 i nie pobierając żadnego znaku z stringa automat wykona tranzycje do stanu 2 lub 4. W automacie NFA wyróżniamy jeszcze ε-closure. ε-closure to zbiór wszystkich stanów do których można przejść za pomocą jednego lub więcej ε. Innymi słowy ε-closure to zbiór wszystkich stanów do których możemy przejść z aktualnego stanu nie pobierając żadnego znaku z stringa. Dla powyższego automatu wyróżniamy następujące ε-closure dla każdego z stanów (definiując zbiory definiujemy również przejście do obecnego stanu):
1 = { 1, 2, 4}
1 = { 2 }
3 = { 2, 3, 4}
4 = { 4 }
Wreszcie doszliśmy do momentu, w którym sami możemy się sprawdzić jako projektanci leksera. Teraz w zależności od tego co chcielibyśmy osiągnąć skaner dla każdego przypadku będzie się diametralnie różnił. Wszędzie tam gdzie wyrażenia regularne nie wystarczają jesteśmy w stanie zaimplementować lekser. Flex to program, które na wejście przyjmuję plik składający się z trzech sekcji, z której pierwsza to sekcja definicji np. stałych, #include itd., druga to sekcja zasad, która składa się z listy zdefiniowanych wyrażeń regularnych oraz z akcji, która zostanie wykonana gdy dane wyrażenie regularne zostanie spełnione (np. wywołanie funkcji i zwrócenie tokenu), oraz z sekcji trzeciej składającego się z "kodu użytkownika". Tak jak wspomniałem na początku nagłówka o analizie leksykalnej, lekser ściśle współpracuje z parserem, dlatego też Flex współpracuje z generatorem parserów tj. Bison'em. Czym są parsery? Jak działają? Dlaczego sam lekser nie wystarcza? To wszystko znajdziecie poniżej. Tutaj umieściłem nagłówek o Bison'ie oraz liste bardzo dobrych tutoriali dla zaczynających przygodę z Flex & Bison, których nie ma sensu duplikować. Tutaj zostawiam linka dla tych, którzy chcieliby dowiedzieć się jak pisać wyrażenia regularne tak aby były one poprawnie interpretowane.
Na początku wspomniałem, że tokeny słów kluczowych posiadają swoje własne zdefiniowane regexy, okazuje się, że nie jest to reguła, którą musi spełniać każdy kompilator. Warto zaznaczyć, że zarezerwowane słowa muszą posiadać większy priorytet od identyfikatorów tzn. ich regexy powinny być zdefiniowane przed regexem identyfikatora przez co skaner rozpatruje najpierw słowa kluczowe. Istnieje również inne zabezpieczenie przed tym gdy uzytkownik będzie chciał użyć słowa kluczowego jako identyfikator. Należy pamiętać, że każda definicja wyrażenia regularnego kosztuje nas sporo pamięci w przypadku użycia generatora Flex, który tworzy tabele do ich wyszukiwania. Projektanci skanera wyróżniają druga metodę polegającą na zdefiniowanu tabeli składającej się z stringa i wskaźnika na funkcję. Tabela ma za zadanie reprentować parę słowo zarezerwowane + akcja. W przypadku gdy lekser dopasuje regex identyfikatora następuję wyszukiwanie binarne w tablicy słów kluczowych i zostaje podjęta odpowiednia przypisana mu akcja. W przypadku gdy słowo nie zostanie znalezione zwracany jest token T_Identity. W ten właśnie sposób znacznie oszczędzamy na pamięci kosztem nieodczuwalnego spowolnienia kompilatora.
W następnym etapie omówiona zostanie analiza składniowa podczas, której parser manipuluje otrzymanymi przez leksera tokenami.
Jeśli kompilator znalazł się na etapie analizy składniowej oznacza to, że nasz kod jest leksykalnie poprawny, tj. udało się stworzyć tokeny z każdego znaku (lub ciągu znaków) znalezionego w pliku. Właściwie analize składniową ciężko nazwać następnym etapem ponieważ lekser i parser pracują nieustannie rownocześnie obok siebie (przykładowo parser może chcieć pobrać kolejny token funkcją skanera o nazwie GetToken() gdy zajdzie taka potrzeba), jednak dla uproszczenia napisałem, że jest to kolejny etap, dlatego na tym etapie zakładamy, że tokeny zostały poprawnie przekierowane do pliku z którego teraz nasz parser zacznie czytać. Przykładowy kod poprawny leksykalnie:
while (ip < z)
++ip;Teraz obrazek ilustrujący na jakim etapie się znajdujemy, nasz kod został pocięty na leksemy z których utworzone zostały następujące tokeny:

Kolejny przykład kodu poprawnego leksykalnie:
do[for] = new 0;Obrazek ilustrujący utworzone tokeny:
 Jak widać coś poszło nie tak, nasz kod faktycznie jest poprawny leksykalnie, ale niektóre z tych tokenów to słowa kluczowe, przykładem jest
Jak widać coś poszło nie tak, nasz kod faktycznie jest poprawny leksykalnie, ale niektóre z tych tokenów to słowa kluczowe, przykładem jest for, które zostało użyte jako identyfikator (gdzieś wcześniej) prawdopodobnie jakiejś liczby całkowitej, lub do użyte prawdopodobnie jako nazwa tablicy.
Podczas analizy składniowej parser z wcześniej przygotowanych przez leksera tokenów stara się dopasować istniejącą strukturę (pattern), w przypadku gdy jej nie znajdzie zwróci błąd analizy składniowej. Podczas skanowania naszym alfabetem były znaki ASCII lub Unicode czyli po prostu kod źródłowy, podczas parsowania naszym alfabetem jest zestaw utworzonych tokenów. Podczas skanowania używaliśmy wyrażeń regularnych do opisu leksemów, które później skonwertowane zostały na odpowiadający im token. Niestety, ale w przypadku parsowania wyrażenia regularne okazują się zbyt słabe do opisania struktury gramatycznej. W tym przypadku konieczne jest użycie innego narzędzia głównie ze względu na fakt, iż opis struktury gramatycznej może być bardzo złożoną strukturą rekurencyjną.
Context-Free Grammar lub po prostu CFG to zestaw zasad za pomocą, których opisywane są struktury rozumiane przez parsera. Przypuśćmy, że chcemy opisać operacje arytmetyczne takie jak dodawanie, odejmowanie, mnożenie i dzielenie. Po lewej przedstawiono zasady dla operacji arytmetycznych, natomiast po prawej utworzona struktura z działania
10 * (1 + 2)

-
EiOp, symbole nieterminalne, rozpoczynajace się dużymi literami np. A, B, C. Znak nieterminalny jest symboliczny tzn. za pomocą niego opisujemy inne symbole do, których może się on rozwinąć (na przykładach poniżej wszystko się wyjaśni)-
int,(),+,-,*,/, symbole terminalne, rozpoczynajace się małymi literami np. e, f, g. Znak terminalny jest dosłowny tzn. podczas parsowania nic nie rozwijamy i szukamy dokładnie tego co jest reprezentowane przez ten znak (będą to uprzednio utworzone przez skanera tokeny).- symbol dowolny (symbol terminalny lub symbol nieterminalny), zwykle oznaczany małymi literami greckimi np. α, γ. Ktoś mógłby zapytać po co wprowadzać kolejną reprezentację skoro mamy już symbol nieterminalny, który potencjalnie może składać się z innych symboli? Jest to bowiem przydatne przy opisie gramatyki (o tym później). Niektóre małe litery alfabetu greckiego zarezerwowane są dla specjanych przypadkow jak np. epsilon
εoznaczający pustego stringa.
Gramatykę bezkontekstową opisujemy za pomocą notacji BNF, w której istnieją dwa sposoby rozwijania symboli przez drzewo parsujące (parse tree) nazywane derywacją (derivation). Poniżej przedstawiono: Leftmost Derivation (derywacja lewostronna) tj. w każdym kolejnym kroku rozwijany jest pierwszy z lewej symbol nieterminalny, Rightmost derivation (derywacja prawostronna) tj. w każdym kolejnym kroku rozwijany jest pierwszy z prawej symbol nieterminalny. Proszę zwróćcie uwagę na różnice w jakiej opisywana jest zasada i derywacja. Na pierwszej ilustracji dotyczącej CFG strzałka po lewej stronie jest zdecydowanie chudsza niż ta po prawej są to szczegóły jednak wciąż bardzo istotne. Na ich podstawie wiemy kiedy autor miał na myśli ukazanie derywacji (konstrukcji), a kiedy ukazanie opisu zasady (definicji). Poniżej grubsza strzałka opisująca proces derywacji.

{kind=link}

Warto wiedzieć, że sładnia wyrażeń regularnych nie może zostać użyta do opisu gramatyki bezkontekstowej.
Przykładowo Kleene Closure * w wyrażeniach regularnych oznacza 0 lub więcej wystąpień, dla a*b, dopasowane zostałyby słowa ab, b, aaaaab, taka funkcjonalność nie jest jednak wspierana przez CFG. Głównym powodem jest brak konieczności istnienia takiego operatora (notacja BNF zapewnia nam możliwość użycia rekurencji).
Podczas rozwijania struktur CFG natrafić możemy na niejednoznaczność (ambiguity). Tak jak w przypadku niedeterministycznego automatu skończonego nie wiemy, która czynność zostanie wykonana tutaj nie wiemy jak nasza struktura drzewa zostanie zbudowana tj. może zostać zbudowana na kilka rożnych sposobów (w ten sposób mogą powstać dwa kompletnie różne drzewa). Sytuacja jest na tyle nieciekawa, że nie ma konkretnego algorytmu na rozwiązanie tego typu problemu. W tym przypadku mamy dwie opcję, pierwsza z nich to zmiana gramatyki języka, druga to określenie, która zasada gramatyczna ma pierwszeństwo.
Rozważmy proste działanie matematyczne 34 - 3 * 42, oraz zdefiniowane przez nas zasady gramatyki:

Rozwijając strukturę z lewej strony otrzymamy zły wynik oraz następujące drzewo:

Rozwijając strukturę z prawej strony otrzymamy:

Przy derywacji lewostronnej najpierw wykonana zostanie operacja odejmowana, a dopiero później mnożenia (co jest oczywiście błędem). Zmieniając gramatykę języka na taką, w której użycie nawiasów jest obowiązkowe wykluczamy tym samym błędne rozgałęzienie drzewa:

Często jednak zmiana gramatyki nie wchodzi po prostu w grę. Innym sposobem na pozbycie się problemu jest zadeklarowanie najpierw operacji mnożenia i dzielenia (to one zostaną najpierw dopasowane), a później dodawania i odejmowania. Dodam, iż zasada gramatyczna często nazywana jest produkcją ponieważ produkuje ona stringa za pomocą derywacji.
Rozważmy produkcję A -> (A) gdzie A to symbol nieterminalny, ( i ) to symbole nieterminalne. Taki rodzaj produkcji jest niepoprawny, gramatyka ta nie generuje żadnego stringa. Dzieje się ponieważ zasada gramatyczna definiuje strukturę rekurencyjną składającą się wyłącznie z symbolu, który występuje rekurencyjnie tj. w produkcji brakuje innego symbolu nieterminalnego, który często nazywany jest jako base case. Produkcja ta nie posiada symbolu na którym może bazować przez co każda derywacja narażona jest na nieskończoną pętlę.
Spójrzcie proszę na poniższą gramatykę:

Z wyrażenia if (1) if (0) other else other (przyjmujemy, że other to część kodu wykonywana w ifach) otrzymujemy następujące drzewa:


Który z nich jest poprawny zależy od sposobu interpretacji przez nas samych:
if (1) { if (1) {
if (0) {} vs. if (0) {}
}
else {} else {}
}
Wspomniany problem to tzw. dangling else problem, polegający na trudności w rozróżnieniu do którego wyrażenia if dany else należy.
Gramatyka może być niejednoznaczna mimo to wciąż tworzyć unikalne struktury drzewa tzn. taka, w której algorytm parsujący dla derywacji lewostronnej i prawostronnej tworzy różne struktury drzewa jednak dające ten sam rezultat (w literaturze określane jako inessential ambiguity). Taka gramatyka dotyczy w szczególności operacji, w których kolejność nie ma znaczenia. Najprostszymi przykładami będą operacje dodawania i mnożenia. W przypadku, w którym niejednoznaczność nie gra roli interesuje nas tak naprawdę efekt końcowy (wyliczona wartość z operacji mnożenia). Zauważmy, że mogą istnieć kompletnie dwie różne struktury drzewa (a * b) * c = a * (b * c) wciąż dające ten sam rezultat. Niemniej jednak algorytm parsujący powinien rozróżniać tego typu przypadki i stosować się tylko do jednej z wymienionych struktur uniemożliwiając tym samym powstawanie innych.
Podczas parsowania utworzone zostaje drzewo składniowe, tzw. Concrete Syntax Tree (CST) to drzewo odzwierciedlające nasz kod źródłowy w postaci tokenów, bardziej przydatnym typem drzewa okazuje się być Abstract Syntax Tree (AST), które zachowuje najbardziej przydatne informacje w celu dalszej obróbki również w postaci tokenów, różnica pomiędzy CST i AST jest taka, że AST stara się na bieżąco wyliczać wartości oraz usuwać niepotrzebne tokeny.
Kod źrodłowy: a[index] = 4 + 2;
CST: a [ index ] = 4 + 2; -> drzewo dokładnie odzwierciedlające nasz kod źródłowy
AST: a index = 6 -> drzewo z wyliczonymi wartościami, nawiasy zostały pominięte ponieważ token T_Index sam w sobie reprezentuje komórkę w tablicy
Zanim przejdziemy do algorytmów parsujących chciałbym dodać kilka słów na temat hierarchi Chomsky'ego. Naszą gramatykę języka reprezentujemy za pomocą notacji BNF lub EBNF (wersja rozszerzona, która dodatkowo zawiera np. wyrażenia opcjonalne), są to niezwykle przydatne i potężne narzędzia, jednak równie ważne jest by znać ich ograniczenia. Widzieliśmy przykłady, w których gramatyka może być niejednoznaczna produkując tym samym nieoczekiwaną strukturę drzewa. Tym razem postaram się przytoczyć inne przypadki, w których gramatyka może być zbyt rozbudowana lub niemożliwa wręcz do skonstruowania przez parsera. Warto zadać sobie pytanie, w jakich przypadkach użycie notacji BNF jest potrzebne, a w jakich należałoby użyć wyrażeń regularnych. Gramatyka bezkontekstowa jest w stanie wyrazić konkatenację, powtórzenie oraz wybór tak samo jak wyrażenia regularne. W ten sposób możliwe jest użycie regexów do konkatenacji np. łączenia cyfr w liczbę lub łączenia znaków w słowo (tak jak to dotychczas było robione, zostawiamy zadanie sklejania stringów dla regexów). Wykorzystując wyrażenia regularne ułatwiamy sobie zapis zasad gramatyki (prosty przykład poniżej):
REGEX:
digit = 0|1|2|3|4|5|6|7|8|9
number = digit digit*
BNF:
digit -> 0|1|2|3|4|5|6|7|8|9
number -> number digit | digit
Gramatyka, którą możemy wyrazić za pomocą wyrażen regularnych nazywana jest gramatyką regularną (regular grammar) (typem 3 według hierarchi Chomsky’ego). Co za tym idzie parsowanie takiej gramatyki może zostać przeprowadzone przez sam skaner gdyż użycie parsera nie było by konieczne. Mimo wszystko brak parsera to zły pomysł, rozsądniejszym byłaby implementacja parsera chociażby w celu odróżnienia procesu aktualnie przeprowadzanego przez kompilator. Sytuacja zmienia się wtedy gdy język posiada kontekst, który w wiekszości języków programowania występuje. Gramatyka bezkontekstowa, co ona tak naprawdę znaczy? Symbole nieterminalne reprezentują "zasady pozbawione kontekstu" (zaraz wyjaśnię), z których wynika, że token T_Token może zostać zamieniony na symbol nieterminalny wszędzie tam gdzie występuje on w produkcji. Z drugiej strony moglibyśmy zdefiniować produkcję, która byłaby wrażliwa na kontekst (context-sensitive grammar rule). Taki rodzaj produkcji jest dużo bardziej skomplikowany i nie możliwy obecnie do przeprowadzenia przez parser. Poniżej przykład gramatyki wrażliwej na kontekst:
{
...
int x = 5;
...
...x...
...
}
Chodzi o sytuację, w której parser zdaję sobie sprawę z tego, że x to zmienna typu int zadeklarowana gdzieś wyżej. Gdybyśmy chcieli za pomocą notacji BNF stworzyć parser zależny od kontekstu musielibyśmy w jakiś sposób załączać np. nazwy zmiennej do zasad tak aby były one rozróżnialne. Po drugie musielibyśmy znać długość nazwy takiej zmiennej, która w wielu językach nie jest zdefiniowana, przez co potencjalnie liczba możliwych identyfikatorów jest nieskończona (nieskończona liczba zasad nie brzmi ciekawie). Nawet jeśli maksymalna długość identyfikatora wynosiłaby dwa, daje nam to setki nowych zasad gramatycznych. Zakres możliwości parsera jest ograniczony stąd też parser nie powinien przejmować się tego typu problemami. Ta część kompilacji przeprowadzana jest w analizie semantycznej, w której parser uprzednio zdefiniował, że istnieje identyfikator x (potencjalnie jakiejś zmiennej), zadeklarowana w tym danym miejscu. Gramatyka języka, która jest poza możliwościami parsera jednak wciąż możliwa do sprawdzenia przez kompilator nazywana jest semantyką statyczną języka (static semantics of the language) (w skład semantyki statycznej wchodzi statyczne sprawdzanie typów). Wspomniana gramatyka nazywana jest gramatyką kontekstową (context grammar) (typem 1 według hierarchi Chomsky’ego). Istnieje również typ 0 tzw. gramatyka rekurencyjnie przeliczalna (według polskiego tłumaczenia) (unrestricted grammar) równoważna automatowi Turinga, którą nie będę tutaj opisywał. Warto wspomnieć o osobie takiej jak Noam Chomsky, który opracował każdy z wymienionych typów gramatyki. Każda z tych gramatyk opisuję również jaki poziom mocy obliczeniowej potrzebny jest do jej opisu. Gramatyka regularna równoważna jest automatowi skończonemu, natomiast gramatyka bezkontekstowa równoważna jest automatowi ze stosem (pushdown automaton).
Analiza zstępująca (top-down) zaczyna się niemalże bez informacji. Symbol od którego zaczynamy (symbol początkowy), pasuje do każdej z produkcji. Skąd zatem wiemy, który zestaw symboli to ten którego szukamy? Nie wiemy... Jedynie co możemy zrobić to zgadywać, a w przypadku pomyłki wrócić się po węzłach. Skoro musimy zgadywać to w jaki sposób? Spróbuję teraz omówić dwa podstawowe algorytmy z nawrotami (backtracking). Zacznijmy od potraktowania naszego wejścia składającego się z tokenów jako zdanie składające z symboli terminalnych i nieterminalnych oraz proces parsowania jako przeszukiwanie po węzłach. Węzłem będzie symbol dowolny, natomiast przejście z węzła na węzeł możliwe będzie wtedy gdy napotkamy symbol istnieje w produkcji:

Zacznijmy od pierwszego, rzadziej używanego algorytmu Breadth-First Search lub BFS. Algorytm polega na przeszukiwaniu wszerz zaczynając od symbolu najbardziej na lewo lub prawo. Algorytm wymaga zapamiętywania wszystkich węzłów w danej odległości od korzenia. Standardowe przejście po grafie wygląda następująco:

Od razu wspomnę, że próba rozwijania symbolu może trwać naprawdę długo. Dlaczego? Załóżmy, że nasz algorytm rozwija zawsze pierwszy z lewej symbol znajdujący się w produkcji. W momencie gdy w produkcji pierwszym symbolem z lewej jest taki sam symbol jaki znajduję się "przed strzałką" potencjalnie wpadamy w bardzo długi proces szukania rozwiązania dla danej produkcji (w BFS nie ma ryzyka nieskończonej pętli jednak proces szukania rozwiązania może trwać naprawdę długo). Poniższa animacja ilustruje powyższy schemat przejść po drzewie tj. pierwszy rozwijany jest symbol najbardziej na lewo:

Jak można łatwo zauważyć szukanie klucza może potrwać naprawdę długo, dodatkowo szukanie zajmuje mnóstwo pamięci. Najbardziej nieprzydatną rzeczą okazuję się rozwijanie symbolu nieterminalnego, który potencjalnie zawiera inne symbole nieterminalne z niepasującym kluczem (wspomniane ryzyko rekurencji). Co można by było ulepszyć? Wyobraźmy sobie, że szukamy rozwiązania dla λ = int + int. Zakładamy również, że posiadamy zasadę mówiącą, że κ = aB (κ - symbol dowolny, a - symbol terminalny, B - symbol nieterminalny), w przypadku gdy a nie jest tokenem int nie ma sensu dalej rozwijać symbolu nieterminalnego B. Unikając niepotrzebnego rozwijania (branching factor) symboli nieterminalnych znacznie zyskujemy na czasie. Oczywiście gdy nasz ciąg symboli składa się z wielu symboli nieterminalnych to rozwijanie wciąż może zając sporo czasu. Poniżej przedstawiam zestawy symboli po których będziemy się poruszać (zasady gramatyki):

Animacja przedstawiająca poprawiony algorytm (przeszukujemy zaczynając od symbolu najbardziej na lewo), szukane zdanie to int + int:

Teraz wspomniany problem gdy pierwszym symbolem z lewej jest symbol nieterminalny (szukanie klucza rośnie wykładniczo), najpierw nasze zasady:

Szukane zdanie to caaaaaaaaaa, animacja przedstawiająca problem:

Drugim algorytmem, który postaram się omówić jest Deep-First Search lub DFS. Przeszukiwanie wgłąb polega na rozpatrywaniu jednej gałęzi i przechodzenia na kolejny węzęł w przypadku pasujących symboli, w przypadku niepasujących symboli wracamy się z powrotem po grafie. Algorytm w każdym momencie wymaga zapamiętania ścieżki od korzenia do bieżącego węzła. Schemat przejść po drzewie wygląda następująco (zaczynając od symbolu najbardziej na lewo):

Kilka zalet w stosunku do BFS:
- mniejsze zużycie pamięci (rozpatrywana jest jedna gałąź w danym momencie, nie trzymamy wskaźników na węzły znajdujące się w innych gałęziach a jedynie wskaźniki na dzieci)
- dla dobrze napisanej gramatyki wysoka wydajność w stosunku do BFS
- łatwy w implementacji
Animacja przedstawiająca szukanie rozwiązania dla int + int zaczynając od symbolu najbardziej na lewo:

Problemy z przeszukiwaniem wgłąb podczas szukania rozwiązania dla c. Zaczynając od symbolu najbardziej na lewo wpadamy w nieskończoną rekurencję:

No dobrze ale jak temu zaradzić? Przecież musi istnieć jakiś sposób dostania się do c (parsery zstępujące LL równiez podatne są na tego typu problemy). Postaram się omówić jak usunąć rekurencję lewostronną (left recursion removal) bezpośrednią (immediate) oraz pośrednią (indirect) (zwykle technika usuwania rekurencji powiązana jest z usunięciem wspólnych symboli (left factoring)). Zacznijmy od rekurencji lewostronnej bezpośredniej (najprostszy przykład z jednym symbolem rekurencyjnym):

Teraz trochę trudniejszy przykład, rekurencja lewostronna bezpośrednia z więcej niz jednym symbolem rekurencyjnym:
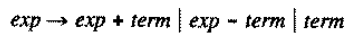
Powyższe grafiki obrazują bezpośrednią rekurencję lewostronną ponieważ symbol rekurencyjny znajduje się bezpośrednio w omawianej produkcji. Bardziej złożonym przypadkiem jest rekurencja lewostronnie pośrednia:

Takie produkcje są jednak rzadkością wśród języków programowania. Zacznijmy od rekurencji bezpośredniej, występuje ona w formie:

w której α i β składają się z symboli nieterminalnych i symboli terminalnych nie zaczynających się na A. Do usunięcia rekurencji niezbędne jest dopisanie dodatkowej zasady gramatycznej. Pierwsza generująca β oraz druga generująca powtórzenia α używając rekurencji prawostronnej. Wygląda to w następujący sposób (przypominam, że ε oznacza pustego stringa):

Stąd rozwiązaniem dla
jest

Również rozwiązaniem dla
jest

Teraz coś trudniejszego, gramatyka, której prawdopodobnie większość z nas nie zobaczy:

Po dokonaniu usunięcia rekurencji lewostronnej:

Usuwanie rekurencji lewostronnych nie zmienia języka, który rozpoznajemy, zmieniana jest gramatyka, a co za tym idzie struktura drzewa. W rzeczywistości usuwanie symboli rekurencyjnych utrudnia nam jako projektantom gramatyki przejrzystość produkcji (parser staje się bardziej skomplikowany).
| Przeszukiwanie wszerz | Przeszukiwanie wgłąb |
|---|---|
| Działa dla każdej gramatyki | Działa dla gramatyki pozbawionej lewostronnej rekurencji (graf musi być skończony) |
| Złożoność pamięciowa w najgorszym wypadku - wykładnicza | Złożoność pamięciowa w najgorszym wypadku - liniowa |
| Czas wyszukiwania w najgorszym wypadku wykładniczy | Czas wyszukiwania w najgorszym wypadku wykładniczy |
Poprzednie algorytmy zajmowały się wyszukiwaniem próbując dopasować dany token do produkcji, w przypadku błędu wracały się po uprzednio utworzonej ścieżce. Istnieje również inna kategoria algorytmów parsujących, są to tzw. parsery przewidujące (predictive parsers). Parsery przewidujące są znacznie szybsze jednak w tym przypadku mniej potężne od BFS (który zadziała dla każdej gramatyki) i DFS (którego gramatyka jest kompletna gdy graf jest skończony). Dodatkowo, często wspierane tablicą wypełnioną przejściami (o których za chwilę wspomnę) z poszczególnych węzłów na kolejny zyskują jeszcze większą wydajność. Niestety ten rodzaj parsowania nie jest w stanie wyszukać rozwiązania dla każdej gramatyki. Zaczynając od pierwszego symbolu w jaki sposób jesteśmy w stanie stwierdzić, którą produkcje przyjąć? Podczas podejmowania decyzji parser sprawdza aktualny oraz następny token (lookahead token) (LL(n), L - parsujemy od lewej do prawej (proszę sie nie zdziwić, ale niektóre starsze parsery parsowały od prawej do lewej), L - derywacja lewostronna (proces rozwijania symboli), n - liczba dodatkowo sprawdzanych tokenów z wyprzedzeniem) w celu podjęcia decyzji. Warto zauważyć, że gdy zwiększamy liczbę dodatkowo sprawdzanych tokenów jesteśmy w stanie szukać rozwiązań dla bardziej złożonych gramatyk z drugiej strony im większa liczba sprawdzanych tokenów tym nasz parser staje się bardziej skompilowany. Poniżej przykład, w którym parser mając do dyspozycji jeden lookahead token wyszukuje rozwiązania dla int + (int + int)

Parser zstępujący bazuje na stosie, rozpoczyna parsowanie w momencie dodania symbolu startowego natomiast akceptuje wejście momencie dopasowania tokenów do istniejącej produkcji (w momencie gdy stos jest pusty). Parsowanie odbywa się poprzez zamianę symbolu nieterminalnego (znajdującego się na górze stosu) z jedną z wybranych produkcji (generate) tym samym pobierając kolejny token z wejścia. Następnym etapem jest porównanie symbolu terminalnego z tokenem na wejściu (match), pasujący token zostaje zastąpiony kolejnym tokenem pobranym z wejścia natomiast symbol terminalny zostaje zdjęty z stosu. W momencie gdy symbol terminalny oraz token na wejściu nie są sobie równoważne zwracany jest błąd analizy składniowej. Poniżej przedstawiam przykład działania algorytmu dla gramatyki:
S -> ( S ) S | ε
Po lewej stronie przedstawiony został stos (element na samej górze znajduje się po prawej stronie) oraz wejście składające się z tokenów. Inicjując stos zaznaczmy gdzie się on kończy za pomocą znaku $ (tym samym będziemy w stanie wykrywać błędy, o których za chwilę wspomnę). Warto zauważyć, że podczas generacji symbole wstawiane są w odwrotnej kolejności, w której występują w produkcji:
$ S ( ) $ // Symbol S zostaje zastąpiony z ( S ) S, symbole wrzucamy w odwrotnej kolejności
$ S ) S ( ( ) $ // Symbol ( zostaje dopasowany z tokenem (, symbol zostaje zrzucony z stosu, pobierany jest kolejny token
$ S ) S ) $ // Symbol S zostaje zastąpiony pustym stringiem ε
$ S ) ) $ // Symbol ) zostaje dopasowany z tokenem ), symbol zostaje zrzucony z stosu, pobierany jest kolejny token
$ S $ // Symbol S zostaje zastąpiony pustym stringiem ε
$ $ // Akceptacja stringa
Metoda ta pokazuje nam pewną zależność. Jeśli na górze stosu znajduje się symbol nieterminalny zobowiązani jesteśmy do rozwinięcia jednej z produkcji na podstawie aktualnie rozpatrywanego tokenu oraz jednego tokenu wprzód. Sytuacja wygląda inaczej gdy na górze stosu znajdziemy symbol terminalny, oprócz tego, że nie musimy podejmować decyzji związanej z uprzednim wybraniem i rozwinięciem produkcji to nie musimy również brać pod uwagę następnego tokenu. Decyzje podejmowane przez LL(1) wyrażane są za pomocą uprzednio utworzonych tablic (parsing table).
Podczas parsowania LL(1) wszystkie nasze decyzje dotyczące rozwijania symboli nieterminalnych są niejako wymuszone poprzez rozpatrywanie następnego tokenu. W nastęnym nagłówku postaram się nieco przybliżyć zastosowanie tablic umożliwiających szybsze wyszukiwanie rozwiązania oraz detekcje błędów gramatycznych. Zakładamy, że tablica jest na początku pusta. Po konstrukcji tablicy jakakolwiek pusta komórka stwarza potencjalny błąd podczas parsowania. Na poniższych ilustracjach przedstawiono kolejno: opis naszej gramatyki oraz tablicę przejść, pierwsza z lewej kolumna to symbole nieterminalne, pierwszy z góry wiersz to symbole terminalne.

Tak utworzoną tablicę parser woła w sposób: M[N, T] gdzie M to tablica (moves), N to symbol nieterminalny (na górze stosu) oraz T symbol terminalny (występujący na wejściu). Podczas parsowania zdania (int + (int * int)) zaznaczmy gdzie się ono kończy znakiem $, od teraz nasze zdanie to (int + (int * int))$. Poniżej ilustracja procesu parsowania tablicą przejść (zwróćcie uwagę, że tym razem stos został inaczej przedstawiony, element na samej górze znajduję się po lewej stronie).

Wykrywanie błędów gdy posiadamy znak kończący zdanie oraz tablice przejść:

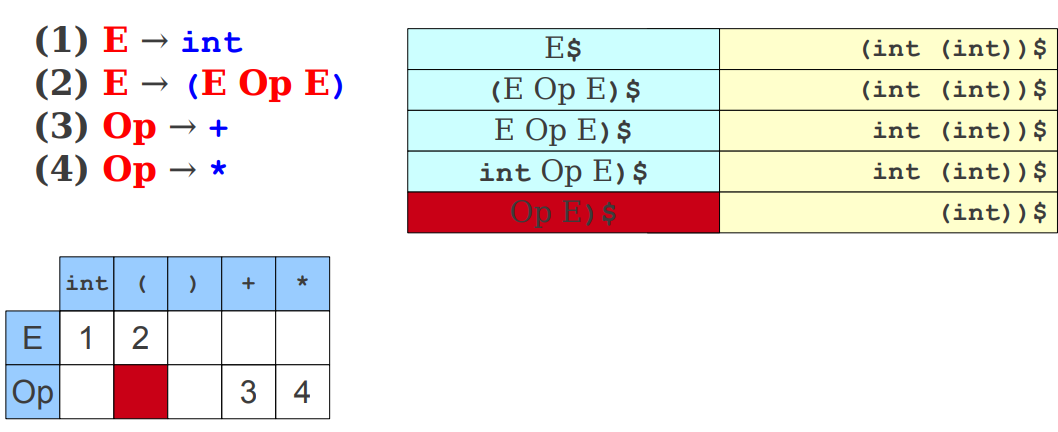
Spróbujmy podsumować algorytm działania parsera LL(1):
- Zaczynając od symbolu dowolnego S oraz tablicy przejść T inicjujemy stos $S
- Powtarzamy dopóki stos nie jest pusty:
- Pobierz aktualnie rozpatrywany token
t - Jeśli na samym wierzchu znajduję się symbol terminalny
r- Gdy
r != tzwróć błąd - W przeciwnym wypadku pobierz token
toraz usuńrze stosu
- Gdy
- Jeśli na samym wierzchu znajduje się symbol nieterminalny
A- Jeśli
T[A, t]jest niezdefiniowane, zwróć błąd - W przeciwnym wypadku zamień pierwszy element stosu na
T[A, t]
- Jeśli
- Pobierz aktualnie rozpatrywany token
Gramatyka LL(1) istnieje wtedy gdy utworzona tablica, posiada maksymalnie jedną możliwą produkcję w każdej komórce, oznacza to, że gramatyka nie może być niejednoznaczna, nie może istnieć sytuacja, w której dla danego symbolu nieterminalnego i tokenu istnieją dwie możliwe opcje do wybrania. Podczas gdy wymagamy aby ta zasada obowiązywała możliwe jest zaimplementowanie wyjątków. Jednym z przykładów może być (wspomniany wcześniej) dangling else problem:


Komórka M[else-part, else] zawiera dwie produkcje. Podczas budowania tablicy przejść moglibyśmy przyjąć zasadę, wybierania produkcji, w której następny token jest równy tokenowi na wejściu, zasada nosi nazwę most closely nested disambiguating rule.
Tablica przejść parsera LL(1) tworzona jest na podstawie zbiorów First i Follow. Podczas parsowania chcielibyśmy wiedzieć czy dany symbol nieterminalny może zostać rozwinięty do symbolu terminalnego występującego na wejściu, aby to zrobić niezbędna jest tablica First, która reprezentuje wszystkie możliwe symbole terminalne, które mogą wystąpić jako pierwsze przy rozwijaniu symbolu nieterminalnego. Z drugiej strony chcielibyśmy wiedzieć czego ewentualnie spodziewać się po rozwinieciu nieterminala, w tym celu użyjemy tablicy Follow, która reprezentuje wszystkie dozwolone symbole terminalne, które mogą wystąpić po rozwinięciu symbolu nieterminalnego. Przykład poniżej przedstawia utworzone tablice:

Proszę zauważyć, że zbiór First nie służy tylko i wyłącznie do szukania terminali. Podczas szukania First dla symbolu nieterminalnego dowiadujemy się również tego czy symbol jest w stanie rozwinąć się do pustego stringa ε (jeśli tak to symbol ten może zostać pominięty).
Symbol nieterminalny, który może przyjmować postać pustego stringa określany jest jako nullable. Szukanie terminali dla zbioru First jest stosunkowo proste. Weźmy jako przykład poniższą gramatykę:
exp -> exp addop term | term
addop -> + | -
term -> term mulop factor | factor
mulop -> *
factor -> ( exp ) | number
Każdą z produkcji należy odpowiednio rozpisać:
(1) exp -> exp addop term
(2) exp -> term
(3) addop -> +
(4) addop -> -
(5) term -> term mulop factor
(6) term -> factor
(7) mulop -> *
(8) factor -> ( exp )
(9) factor -> number
W tym przypadku żadna z produkcji nie jest w stanie zwrócić ε, dlatego rekurencje lewostronne (1) oraz (5) nic nie wnoszą (ich usunięcie nie zmieni zbiorów First). Zbiór zwiększamy wyszukując terminali w każdym z możliwych opcji od (1) do (9). Produkcja (1) nie powoduje zmian. Produkcja (2) dodaje zbiór First(term) do zbioru First(exp), ponieważ First(term) nie zostało jeszcze wyliczone to pomijamy tą produkcję. Produkcje (3) i (4) tworzą zbiór First(addop) = { +, - }. Produkcji (5) oraz (6) nie jesteśmy jeszcze w stanie wyliczyć. Produkcja (7) uzupełnia First(mulop) = { * }. Produkcje (8) oraz (9) tworzą zbiór First(factor) = { (, number }. Na tym etapie algorytm wraca się do produkcji (1) (ponieważ wystąpiły zmiany w zbiorach) i sprawdza czy jest w stanie ją wyliczyć, jeśli nie to znów idzie dalej. W iteracji drugiej jesteśmy w stanie wyliczyć First(term) = { (, number } dla produkcji (5) i (6), ponieważ znamy First(factor). W iteracji trzeciej jesteśmy w stanie wyliczyć zbiór First(exp) = { (, number } dla produkcji (1) i (2), ponieważ znamy First(term). W iteracji czwartej zbiory nie zmieniły się co skutkuje przerwaniem procesu, tym samym posiadamy już uzupełnione zbiory dla wyżej wymionych produkcji. Utworzone zbiory First:
First(exp) = { (, number }
First(term) = { (, number }
First(factor) = { (, number }
First(addop) = { +, - }
First(mulop) = { * }
Tworzenie zbioru Follow jest nieco bardziej skomplikowane jednak i z tym damy sobie radę. Do utworzenia zbioru Follow niezbędny jest zbiór First. Zasada wygląda następująco, zbiór Follow pierwszego symbolu inicjujemy $, będąc w danej produkcji, w której znajdują się nieterminale np. A -> B C D do zbioru Follow(B) dodajemy symbole ze zbioru First(C), ponieważ symbole terminalne, które mogą wystąpić na początku nieterminala C są symbolami, które mogą wystąpić po nieterminalu B, również i do zbioru Follow(C) dodawane są symbole ze zbioru First(D). Na końcu należy pamiętać, że symbole terminalne zbioru Follow(A) dodajemy do nieterminali kończących produkcję A. Innymi słowy symbole ze zbioru Follow(A) dodajemy do zbioru Follow(D). Należy pamiętać, że symbol ε nigdy nie wystąpi w zbiorze Follow. Znając zasady rozpoczynamy tworzenie zbioru Follow.
Produkcje (3), (4), (7) oraz (9) nie zawierają nieterminali, dlatego je pomijamy. Zbiór Follow(exp) inicjujemy $. W produkcji (1) do Follow(exp) dodajemy First(addop), do Follow(addop) dodajemy First(term) oraz do Follow(term) dodajemy Follow(exp). W produkcji (2) znowu dodajemy Follow(exp) do Follow(term) czyli symbole Follow(term) pozostają bez zmian. W produkcji (5) do Follow(term) dodajemy First(mulop), do Follow(mulop) dodajemy First(factor) oraz do Follow(factor) dodajemy Follow(term). W produkcji (6) znowu dodajemy Follow(term) do Follow(factor) czyli symbole Follow(factor) pozostają bez zmian. Na końcu w produkcji (8) do Follow(exp) dodajemy First()), dokonane zostały zmiany co oznacza, że pętla zostanie powtórzona. W drugiej iteracji w produkcji (1) do Follow(term) dodajemy First()), ponieważ Follow(exp) został zmieniony. W produkcji (5) do Follow(factor) dodajemy First()), ponieważ Follow(term) został zmieniony w produkcji (1). W iteracji trzeciej żaden ze zbiorów nie zmienił się, co oznacza przerwanie procesu. Dla tak utworzonych zbiorów First i Follow jesteśmy w stanie stworzyć tablicę przejść dla parsera LL(1). Utworzone zbiory Follow:
Follow(exp) = { $, +, -, ) }
Follow(addop) = { (, number }
Follow(term) = { $, +, -, *, ) }
Follow(mulop) = { (, number }
Follow(factor) = { $, +, -, *, ) }
Tak utworzone zbiory First i Follow wykorzystujemy do budowy tablicy przejść, w której każdą komórkę uzupełniamy First(N), gdzie N to dany symbol nieterminalny, w przypadku gdy symbol ten może zostać rozwinięty do ε wykorzystujemy Follow(N). Niewątpliwie ostatnim podpunktem w analizie zstępującej jest odzyskiwanie informacji o błędach składniowych (error recovery) wygenerowanych przez parsera. Podstawowym zadaniem parsera jest sprawdzenie czy nasz kod jest składniowo poprawny. Parser wykonujący tylko to zadanie określany jest jako recognizer, ponieważ jedyne co musi zrobić to zwrócić błąd analizy składniowej w przypadku wadliwej struktury (brak mechanizmu budowy drzewa). Jednym z standardowych metod odzyskiwania informacji o błędach jest tzw. metoda panic mode. Podczas błędu składniowego parser przestaje tworzyć drzewo składniowe do momentu natrafienia na token "separujący" np. ;. Jest to jedna z naprostszych metod odzyskiwania informacji o błędach składniowych, która likwiduje problem zapętlenia błędów.
Na tym etapie zakończę analizę zstępującą. Omówiony parser LL(1) to parser wspomagany tablicą (table-driven LL(1)), jednak istnieje równie szybkie podejście algorytmiczne tego parsera. Tak zwany recursive-descent LL(1) to parser, w którym każdy symbol nieterminalny zdefiniowany jest jako osobna funkcja, znając aktualnie rozpatrywany token wołana jest ta odpowiednia.
Analiza wstępująca (bottom-up) jest metodyką dużo bardziej skomplikowaną, która znacząco przewyższa analizę zstępującą pod względem trudności gramatyki zdolnej do sparsowania. Ze względu na znaczącą przewagę ten typ analizy jest niejako częściej implementowany w współczesnych parserach. Dla przykładu w analizie wstępującej nie mamy problemu z rekurencją lewostronną występującą w produkcji. Pomimo możliwości użycia algorytmów BFS i DFS w tworzeniu parsera jak i samego LL(1), analiza zstępująca jest raczej rzadko spotykana. Raczej nikt nie zakłada przebudowy parsera, ponieważ w nowszym standardzie języka występuje nowa, zbyt skomplikowana semantyka, w której parser LL(1) sobie nie radzi (oczekujemy potężnego narzędzia, którego gramatykę będziemy w stanie poszerzać). Często mówiąc o analizie wstępującej mamy na myśli parser LR(1) (L - parsujemy od lewej do prawej, R - derywacja prawostronna, 1 - ilość rozpatrywanych tokenów wprzód). Ze względu na siłę parserów wstępujących wyróżniamy również LR(0), w których nie posiadamy podglądu, ponieważ token pobrany z wejścia wrzucany jest na stos gdzie rozpoczyna się proces przesunięcia lub redukcji. Niewielką przewagą względem LR(0) wykazuje się parser SLR(1) (S oznaczający Simple LR(1)). Istnieje również parser LALR(1) (LookAhead LR(1)) nieznacznie silniejszy od SLR(1) natomiast mniej złożony od LR(1). Podczas analizy zstępującej najpierw rozpatrywany był symbol początkowy, to od niego parser zaczynał rozwijać kolejne symbole nieterminalne. W przypadku analizy wstępującej parser redukuje tokeny konwertując je na symbole nieterminalne tak aby z czasem dojść do symbolu początkowego (osobiście uważam, że takie rozwiązanie jest bardziej logiczne). Oto jak wygląda parsowanie analizą wstępującą:


Jako ciekawostkę chciałbym dodać, że kompilatory GCC i LLVM-Clang to ręcznie napisane parsery zstępujące (w przeszłości GCC używał Yacc'a do generacji parsera, gdzie Yacc bazuje na analizie wstępującej). Proszę się nie zdziwić, ale wiele z obecnie dzisiejszych kompilatorów powstało kilkanaście, a może nawet kilkadziesiąt lat temu. Programiści budujący kompilator pisali kod mając inne podejście względem analizy składniowej niż jak to ma miejsce teraz, gdzie znane nam obecnie algorytmy parsujące nie były tak popularne. Wszystkie metody pozwalające zbudować parser wstępujący są zbyt trudne dla kogoś kto chciałby go ręcznie napisać. Niemniej jednak ważne jest, aby zrozumieć jak działa analiza wstępująca, jeśli w przyszłości chcielibyśmy szybciej wykrywać potencjalne problemy związane z składnią BNF używając gotowych generatorów takich jak Bison.
Parser wstępujący korzysta ze stosu podobnie jak nierekurencyjny parser zstępujący. Stos zawiera w sobie zarówno tokeny jak i nieterminale. Na początku nasz stos jest pusty, gdzie po poprawnym sparsowaniu zawierać będzie jedynie symbol początkowy. Parser posiada trzy możliwe akcje do wykonania, są to m. in. "zaakceptuj", "przesuń" i "zredukuj" (w literaturze ze względu na wspomniane czynności LR(1) określany jest jako shift-reduce parser). Wyróżniającą się cechą parserów wstępujących jest koniecznośc rozszerzenia gramatyki poprzez dodanie nowego symbolu początkowego. Dla przykładu dla poniższej gramatyki:
S -> ( S ) S | ε
Zobowiązani jesteśmy do rozszerzania jej do postaci (dlaczego tak się dzieje zostanie omówione nieco później):
S' -> S
S -> ( S ) S | ε
Kolejnym nowym określeniem jest right sentential form oznaczające możliwe pośrednie zdanie występujące podczas derywacji prawostronnej. Dla przykładu w poniższej gramatyce:
E' -> E
E -> E + n | n
Wyróżniamy następujące RSF: E, E + n, n + n, są to tzw. przejścia możliwe do wykonania dla derywacji prawostronnej. Parser wrzuca symbole z wejścia na stos do momentu, w którym może wykonać redukcję na RSF. Podczas parsowania metodą wstępującą zadaniem parsera jest znalezienie jak największej uzupełnionej grupy symboli gotowej do redukcji (gotowej do zamiany na symbol nieterminalny) określane przez literature jako uchwyt (handle). Tak jak wspomniałem w tym przypadku parser nie potrzebuje tokenu podglądowego, ponieważ symbole z wejścia mogą być wrzucane na stos tak długo, aż podjęta zostanie odpowiednia akcja. Podczas analizy wstępującej zajmować się będziemy wyszukiwaniem uchwytów w sposób kierunkowy (skanując od lewej do prawej) patrząc o jeden token do przodu (istnieje również grupa parserów wstępujących bezkierunkowych). Spójrzcie proszę na poniższy przykład, jak znaleziony został uchwyt dla zdania int + int * int:

Jak widać powyższy uchwyt jest błędny. Nie wystarczy, aby uchwyt pasował do prawej strony produkcji. Drugi int został błędnie zinterpretowany jako int => T => F, oczekiwaliśmy redukcji w formie int => T => F * T.
Nasze zdanie dzielimy na dwie części. Lewa strona to nasza strefa robocza, w której znajdować się będą potencjalne uchwyty. Prawą stronę potraktujemy jako wejście, które nie zostało jeszcze przeczytane (składa się tylko i wyłącznie z symboli terminalnych). Stopniowo będziemy zajmować się przesuwaniem symboli teminalnych z prawej strony na strefę roboczą po lewej stronie. Rozpatrzmy zdanie int + int * int + int:

Skoro redukcja przeprowadzana jest po prawej stronie strefy roboczej, nigdy nie przesuniemy symbolu z lewej do prawej. Lewą stronę traktujemy jako wspomniany stos do którego wrzucamy symbole terminalne z prawej strony. Jak można łatwo zauważyć uchwyty znajdują się zawsze na górze stosu.
Podczas parsowania metodą przesuń/zredukuj za każdym razem zobowiązani jesteśmy zdecydować jaką akcję chcemy podjąć. Czy zredukować symbol? Czy być może pobrać więcej symboli z prawej strony? Skąd wiemy co należy wykonać? Wiemy, że uchwyt pojawi się zawsze na końcu zdania strefy roboczej, gdybyśmy w jakiś sposób znaleźli wzór na rozpoznawanie uchwytów będziemy wiedzieć kiedy wykonać redukcję, a kiedy przesunięcie. Ponownie rozpatrzmy zdanie int + int * int + int tym razem z innej perspektywy:

Śledząc naszą pozycję wyglądałoby to w następujący sposób:

W dowolnym momencie generacja zawartości po lewej stronie może zostać opisana w następujący sposób:
- Zaczynając od symbolu startowego S śledź produkcje, które nie są jeszcze kompletne (produkcje, które nie zostały jeszcze zredukowane do końca) oraz to gdzie w danej produkcji się znajdujemy (na powyższej animacji zaznaczone jest to znakiem kropki ·)
- Dla każdej produkcji, w kolejności, zredukuj kolejne symbole do punktu, w którym się znajdujemy. Inaczej mówiąc redukuj na bieżąco to co znajduje się po naszej lewej stronie ·
Posiadając algorytm do generacji lewej strony czy jesteśmy w stanie zbudować mechanizm do jej rozpoznawania? W każdym momencie parsowania śledzimy, w której produkcji się znajdujemy oraz jak daleko jesteśmy w tej produkcji. W każdym momencie próbujemy dopasować symbol po prawej stronie jako nowego kandydata na symbol po lewej stronie lub jeśli jest to symbol terminalny próbujemy zgadnąć, której produkcji użyć. Istnieje skończona liczba produkcji, w której istnieje skończona liczba pozycji w jakiej możemy się znaleźć. W każdym momencie zobowiązani jesteśmy śledzić gdzie się znajdujemy tylko w jednej produkcji. Dlaczego się nad tym zastanawiać? Do tego typu zadań świetnie nadają się automaty skończone. Podczas działania automatu gdy kiedykolwiek znajdziemy się w produkcji w takim miejscu gdzie · znajduję się na końcu  to prawdopodobnie będzie to uchwyt (swoją drogą tego typu mechanizm wbudowany jest generatorze bison).
to prawdopodobnie będzie to uchwyt (swoją drogą tego typu mechanizm wbudowany jest generatorze bison).
Elementem LR(0) (lub po prostu elementem) nazywamy jedną z możliwych wyborów w produkcji z zaznaczeniem pozycji, w której się znajdujemy (w poprzednim przykładzie oznaczona jako znak kropki ·). Rozważmy poprzednią gramatykę:
S' -> S
S -> ( S ) S | ε
Gramatyka ta posiada trzy możliwe wybory:
S' -> S
S -> ( S ) S
S -> ε
Tak rozpisana gramatyka posiada dokładnie osiem elementów:
S' ->·S
S' -> S·
S ->·( S ) S
S -> (·S ) S
S -> ( S·) S
S -> ( S )·S
S -> ( S ) S·
S -> ·
Pomysł polega na potraktowaniu każdego z elementów jako rejestratora pozycji w danej części produkcji. Dla przykładu znajdując się w elemencie S -> ( S·) S wiemy, że symbole ( S zostały pobrane z wejścia i umieszczone na stosie. Znajdując się w S' -> ·S prawdopodobnie oczekujemy S jako następnego symbolu na wejściu, a będąc w S -> ( S ) S· wiemy, że symbole ( S ) S znajdują się na górze stosu i prawdopodobnie mogą zostać potraktowane jako nowy uchwyt. Mając informacje o pozycji każdy z elementów może zostać użyty jako stan w automacie skończonym odpowiedzialnym jedynie za utrzymanie informacji o obecnym stanie stosu. Przejście z jednego stanu do drugiego będzie możliwe wtedy gdy pobrany w wejścia token jest równy terminalowi na przejściu. Z drugiej strony istnieje sytuacja, w której na przejściu może znajdować się symbol nieterminalny np. po dokonaniu redukcji grupa terminali zamieniana jest na symbol nieterminalny, który wciąż należy zredukować (który wciąż nie jest symbolem początkowym).
Do tej pory omówione zostały stany oraz tranzycje. Pozostała kwestia dotyczy stanu początkowego oraz stanu akceptacji. Z uwagi na ryzyko zapętlenia spowodowane występowaniem produkcji rekurencyjnych zobowiązani jesteśmy do rozszerzenia gramatyki poprzez wspomniane dodatkowe wstawienie symbolu początkowego (nowy symbol oznaczamy za pomocą '). No dobrze, ale skąd wiemy, który z stanów jest stanem akceptacji? Odpowiedź jest prosta. Pamiętajmy, że nasz automat służy wyłącznie do utrzymania informacji na temat tego gdzie się aktualnie znajdujemy, a nie do rozpoznawania symboli (to parser podejmuje decyzje o zaakceptowaniu i ostatecznej redukcji), stąd stan akceptacji nie istnieje. W istocie nasz automat powinien dać sygnał o tym, że np. podany token jest niemożliwy do zaakceptowania (brak tranzycji z aktualnego stanu) jednak nie jest to bezpośrednio związane z stanem akceptacji. Automat skończony LR(0) to automat DFA (budując NFA LR(0) jesteśmy w stanie zbudować DFA LR(0)). Rozpatrzmy poniższą gramatykę:
E' -> E
E -> E + n | n
Jej elementami są kolejno:
E' ->·E
E' -> E·
E ->·E + n
E -> E·+ n
E -> E +·n
E -> E + n·
E ->·n
E -> n·
Automat NFA powstały z powyższych elementów to:
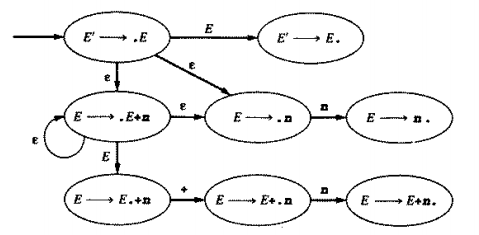
Zwróćcie uwagę, że dla powstałego NFA element E -> ·E + n posiada ε tranzycję do samego siebie (powodem jest produkcja rekurencyjna). Powstały automat DFA to:

Nasz automat wskaże nam miejsca, w których potencjalnie znajduję się uchwyt. Parser LR(0) potrzebuje informacji na temat tego w jakim stanie się znajdujemy, co za tym idzie, każdemu z stanów przypisujemy numer. Podczas wrzucania symboli na stos wrzucamy również odpowiedni numer stanu (właściwie jedynie co nas interesuje to właśnie numer stanu, w którym aktualnie się znajdujemy, stos składający się z symboli nas nie interesuje, ponieważ nie daje on żadnych informacji). Algorytm parsera LR(0) wybiera akcję na podstawie aktualnego stanu automatu DFA tj. aktualnego stanu na stosie. Algorytm przebiega w następujący sposób:
- Jeśli stan s zawiera jakikolwiek element w formie
A -> α·XβgdzieXjest symbolem terminalnym wtedy wrzuć token z wejścia na stos. Jeśli jakikolwiek z elementów zawierającychXjest równe tokenowi wrzuconemu na stos, wrzucany jest numer stanu zawierający ten element. Jeśli każdy z elementów zawierającychXnie jest równe tokenowi zwracany jest błąd. - Jeśli stan s zawiera kompletny element w formie
A -> γ·wykonaj redukcję. RedukcjaS' -> S·równoznaczna jest z akceptacją zdania jeśli na wejściu nie pozostało żadnych tokenów, w przeciwnym wypadku zwróć błąd. Podczas wykonywania redukcji zrzuć z stosu numery stanów do momentuA -> ·γ(do momentu, w którym parsowanieγsię rozpoczęło).
Gramatyka LR(0) istnieje wtedy gdy powyższe reguły nie są dwuznaczne. Możliwe do wystąpienia konflikty to:
- Konflikt przesunięcie/redukcja - konflikt, w którym nie jesteśmy w stanie stwierdzić czy należy pobrać więcej symboli z wejścia czy zredukować aktualnie pobrane symbole.
- Konflikt redukcja/redukcja - konflikt, w którym nie jesteśmy w stanie stwierdzić, którą redukcje przeprowadzić.
Niestety parser LR(0) nie jest w stanie poprawnie przeparsować poprzedniej gramatyki E' -> E z powodu istniejących konfliktów. Nic dziwnego, ponieważ parser LR(0) nie jest w stanie sparsować większości "prawdziwych" gramatyk, jest on natomiast używany jako podstawa do zbudowania parsera SLR(1). Aby zobaczyć jak algorytm parsera LR(0) działa w praktyce, rozpatrzmy poniższą gramatykę:
A' -> A
A -> ( A ) | a
Zdanie, które weźniemy pod uwagę to:
((a))
Wygenerowany automat skończony:

Parsowanie rozpoczynamy w stanie 0 (stan ten wrzucany jest na stos). Będąc w stanie 0 przesuwamy symbol ( z wejścia i wrzucamy go na stos. Automat wskazuje na tranzycję z stanu 0 do stanu 3 w przypadku wystąpienia (, stan 3 wrzucamy na stos. Stan 3 podpowiada nam, aby pobrać więcej symboli, stąd ( pobieramy z wejścia i wrzucamy go na stos. Automat wskazuje na tranzycję z stanu 3 do stanu 3 w związku z tym stan 3 wrzucany jest na stos. Ponownie będąc w stanie 3 pobierany jest symbol a, który wrzucamy na stos. Wykonywane jest przejście z stanu 3 do stanu drugiego co skutkuje wrzuceniem stanu 2 na stos. W stanie 2 wykonywana jest redukcja A -> a przez co stan 2 oraz symbol a zrzucane są z stosu. Symbol A umieszczany jest na stosie. Przejście z stanu 3 do stanu 4 skutkuje wrzuceniem stanu 4 na stos. W stanie 4 pobieramy symbol ) i umieszczamy go na stosie, równocześnie wykonywane jest przejście z stanu 4 do stanu 5 przez co stan 5 ląduje na stosie. W stanie 5 wykonujemy redukcję A -> ( A ) tym samym zrzucając stany 5, 4, 3 oraz symbole ), A, (. Symbol A umieszczany jest na stosie co powoduje przejście z stanu 3 do stanu 4 (stan 4 wrzucany jest na stos). W stanie 4 pobieramy symbol ) z wejścia i wrzucamy go na stos, przechodzimy do stanu 5 i również wrzucamy go na stos. Ponownie wykonujemy redukcje, która zrzuca stany 5, 4, 3 oraz symbole ), A, ( z stosu. Znajdując się w stanie 0 symbol A wrzucany jest na stos, przechodzimy do stanu 1. Będąc w stanie 1 akceptujemy zdanie ze względu na brak dodatkowych tokenów na wejściu. Proces parsowania można przedstawić następująco:
Stos Wejscie Akcja
$ 0 ((a))$ Przesuń
$ 0 ( 3 (a))$ Przesuń
$ 0 ( 3 ( 3 a))$ Przesuń
$ 0 ( 3 ( 3 a 2 ))$ Zredukuj A -> a
$ 0 ( 3 ( 3 A 4 ))$ Przesuń
$ 0 ( 3 ( 3 A 4 ) 5 )$ Zredukuj A -> ( A )
$ 0 ( 3 A 4 )$ Przesuń
$ 0 ( 3 A 4 ) 5 $ Zredukuj A -> ( A )
$ 0 A 1 $ Zaakceptuj
Parsery LR(0) zwykle reprezentowane są za pomocą tabeli action i tabeli goto. Tabela akcji przypisuje każdemu stanowi określoną akcję tj. przesunięcie lub redukcję. Tabela goto to nic innego jak tranzycja z jednego stanu do drugiego. Tabela tworzona jest na podstawie DFA oraz symboli terminalnych występujących w gramatyce. Dla powyższej gramatyki tabela wygląda następująco:
| Stan | Akcja | Zasada | ( |
a |
) |
Goto |
|---|---|---|---|---|---|---|
| 0 | Przesuń | 3 | 2 | 1 | ||
| 1 | Zredukuj | A' -> A | ||||
| 2 | Zredukuj | A -> a | ||||
| 3 | Przesuń | 3 | 2 | 4 | ||
| 4 | Przesuń | 5 | ||||
| 5 | Zredukuj | A -> ( A ) |
Warto zaznaczyć, że każde puste miejsce w tabeli oznacza potencjalne zwrócenie błądu podczas parsowania. Inny przykład wygenerowanej tablicy oraz automatu skończonego:


Simple LR(1) lub SLR(1) używa automatu skończonego oraz elementów LR(0). Różnicą w stosunku do LR(0) jest rozpatrywanie dodatkowego tokenu z wejścia, które znacząco zwiększa zakres możliwych do rozpatrzenia gramatyk. Decyzja dotycząca wrzucenia tokenu na stos podejmowana jest na podstawie podglądu. Dodatkowo parser SLR(1) posługuje się zbiorem Follow w celu sprawdzenia czy dany symbol nieterminalny może zostać zredukowany. Jak się okazuje te dwie proste czynności są wystarczająco skuteczne dla prawie każdej możliwej konstrukcji języka. Algorytm przedstawia się w następujący sposób:
- Jeśli stan s zawiera element w formie
A -> α·Xβ, gdzieXjest symbolem terminalnym oraz gdy token z wejścia równy jest terminalowiX, token oraz numer stanu zawierający ten element wrzucany jest na stos. - Jeśli stan s zawiera kompletny element w formie
A -> γ·oraz gdy token na wejściu znajduje się w zbiorze Follow(A) wykonaj redukcję. RedukcjaS' -> S·równoznaczna jest z akceptacją zdania jeśli na wejściu pozostał symbol$, w przeciwnym wypadku nowy stan wyliczany jest następująco. Usuń symbolγoraz odpowiadające mu stany na stosie. Wróć do stanu, w którym konstrukcjaγsię rozpoczęła, stan ten musi zawierać element w formieA -> α·Aβ. Wrzuć symbolAoraz stan zawierający elementB -> αA·βna stos. - Jeśli żadne z dwóch powyższych przypadków nie mogą zostać wykonane zgłaszany jest błąd analizy składniowej.
Gramatyka SLR(1) istnieje wtedy gdy powyższe reguły nie są dwuznaczne. Konflikty SLR(1) to kolejno:
- Konflikt przesunięcie/redukcja - Element
A -> α·Xβ, gdzieXto terminal, gdy nie istnieje kompletny element w formieB -> γ·w stanie s zXw zbiorze Follow(B). - Konflikt redukcja/redukcja - Dwa kompletne elementy
A -> αorazB -> βw stanie s dają zbiór pusty dla Follow(A) ∩ Follow(B).
Konfilkty SLR(1) podobne są do konfliktów występujących w LL(1) z jedną małą różnicą. Parsując metodą SLR(1) decyzja o wyborze produkcji może zostać opóźniona sprawdzając tym samym większą ilość wyborów. Tablica SLR(1) może zostać skonstruowana w sposób podobny do LR(0). Jako, że stan w parserze SLR(1) może reprezentować zarówno przesunięcie jak i redukcję (bazując na tokenie podglądowym), każdy z tokenów posiada etykietę s - (shift) przesuń lub r - (reduce) zredukuj, tym samym kolumna "akcji" jest już zbędna. Zbiory Follow zawierają symbol $, dlatego też istnienie dodatkowej kolumny dla $ jest kluczowe. Jako przykład weźme poprzednią gramatykę:
E' -> E
E -> E + n | n
Gramatyka ta nie jest gramatyką LR(0) lecz gramatyką SLR(1). Utworzone zbiory Follow:
Follow(E') = { $ }
Follow(E) = { $, +}
Utworzona tablica SLR(1):
| Stan | n |
+ |
$ |
E |
|---|---|---|---|---|
| 0 | s2 | 1 | ||
| 1 | s3 | zaakceptuj | ||
| 2 | r (E -> n) |
r (E -> n) |
||
| 3 | s4 | |||
| 4 | r (E -> E + n) |
r (E -> E + n) |
W stanie 1 gdy na wejściu znajduję się token + wskazujemy na przesunięcie oraz następny stan 3. W stanie 2 gdy na wejściu znajduje się token + wskazujemy na redukcję E -> n. W stanie 1 dla $ wskazujemy na zaakceptowanie zdania (zastępuje to redukcję E' -> E). Dla powyższej tablicy spróbujemy przeprasować zdanie n + n + n. Parsowanie rozpoczynamy w stanie 0, dla tokenu n wrzucamy symbol z wejścia oraz stan 2 na stos. W stanie 2 dla tokenu + wykonywana jest redukcja E -> n w tym przypadku zarówno symbol n jak i stan 2 zrzucane są z stosu, tym samym symbol E wrzucany jest na stos. W stanie 0 mając symbol E na górze stosu wrzucamy stan 1 na stos. W stanie 1 mając token + na wejściu wrzucamy stan 3 oraz symbol na stos. W stanie 3 mając na wejściu token n tablica wskazuje na wrzucenie tokenu jak i stanu 4 na stos. Stan 4 wskazuje na redukcję ze względu na występujący znak końca zdania $, przeprowadzania jest redukcja E -> E + n co skutkuje zrzuceniem stanów oraz symboli ze stosu oraz wrzuceniem symbolu E na stos. Ponownie znajdujemy się w stanie 0, w którym dla E wrzucamy stan 1 na stos. W stanie 1 akceptujemy zdanie ze względu na znak końca zdania. Proces parsowania można przedstawić następująco:
Stos Wejscie Akcja
$ 0 n + n + n $ Przesuń 2
$ 0 n 2 + n + n $ Zredukuj E -> n
$ 0 E 1 + n + n $ Przesuń 3
$ 0 E 1 + 3 n + n $ Przesuń 4
$ 0 E 1 + 3 n 4 + n $ Zredukuj E -> E + n
$ 0 E 1 + n $ Przesuń 3
$ 0 E 1 + 3 n $ Przesuń 4
$ 0 E 1 + 3 n 4 $ Zredukuj E -> E + n
$ 0 E 1 $ Zaakceptuj
Podobnie jak w przypadku LL(1) w celu zniwelowania niejednoznaczności posłużyć się możemy zasadą (most closely nested rule), w której parser dla konfliktu przesunięcie/redukcja wybierze zawsze przesunięcie względem redukcji (konflikt przesunięcie/redukcja nie zostanie rozpatrzony w tym artykule). Konflikt redukcja/redukcja jest nieco bardziej skomplikowany i zazwyczaj odsłania on błędy w projektowaniu gramatyki (nie jest to jednak reguła, której należy się trzymać). Jako przykład konfliktu redukcja/redukcja weźmiemy następującą gramatykę (uproszczona gramatyka zaczerpnięta z Pascala):
stmt -> call-stmt | assign-stmt
call-stmt -> identifier
assign-stmt -> var := exp
var -> var [ exp ] | identifier
exp -> var | number
Powyższa gramatyka "modeluje" wyrażenia, którymi mogą być wywołania procedur bez parametrów lub przypisanie wyrażeń do zmiennych. Struktura zarówno wywołania procedury jak i przypisania do zmiennej rozpoczyna się od identyfikatora. Do momentu, w którym parser nie napotkał symbolu końca zdania $ lub symbolu przypisania := nie jest w stanie rozróżnić czy wyrażenie jest wywołaniem procedury lub przypisaniem do zmiennej. Gramatykę nieco uprościmy w celu łatwiejszego zobrazowania problemu (pomijamy niektóre z wyborów produkcji):
S -> id | V := E
V -> id
E -> V | n
Rozważmy poszczególne elementy SLR(1):
S' -> ·S
S -> ·id
S -> ·V := E
V -> ·id
Dla symbolu początkowego wykonywane jest przesunięcie w przypadku wystąpienia identyfikatora (id) na wejściu dla elementów:
S -> id·
V -> id·
Teraz dla zbiorów Follow(S) = { $ } oraz Follow(V) = { :=, $ } wykonywana jest redukcja dla symbolu $, problem w tym, że parser nie wie, który z elementów to ten właściwy. W literaturze problem konfliktu redukcja/redukcja SLR(1) określany jest jako "fałszywy". Z naszego punktu widzenia redukcja dla symbolu V w przypadku wystąpienia symbolu $ nie powinna nigdy wystąpić, ponieważ wyrażenie przypisania do zmiennej oczekuje operatora := jako następny symbol.
Tak jak w przypadku innych algorytmów parsujących, ilość rozpatrywanych tokenów parsera SLR(1) może zostać zwiększona do SLR(k). Zakres obszaru w jakim działa parser SLR(k) znacząco przewyższa SLR(1) w momencie gdy k > 1 co za tym idzie tablica parsera SLR(k) rośnie wykładniczo. Zazwyczaj typowe problemy na które natrafiamy przy użyciu SLR(1) rozwiązywane są za pomocą silniejszego parsera LALR(1).
W tej sekcji omówiona zostanie metoda parsowania LR(1), która znacząco przewyższa metodykę SLR(1) rozwiązując tym samym problem niejednoznaczności w poprzednim przykładzie. W rzeczywistości metodyka LR(1) uważana jest za zbyt złożoną gdzie w większości przypadków użycie LALR(1), który korzysta w większej mierze z funkcjonalności LR(1) (zachowując tym samym prostotę SLR(1)) wystarcza. W celu lepszego zrozumienia metodyki LALR(1) należy najpierw poznać działanie LR(1).
Problemem w parsowaniu metodą SLR(1) jest aplikowanie tokenu podglądowego po skonstruowaniu DFA, które ignoruje tokeny podglądowe. Przewaga LR(1) polega na wbudowaniu tokenów podglądowych w każdy z elementów występujących w automacie. Elementy te określane są jako LR(1) items gdzie każdy z nich to para składająca się z elementu LR(0) oraz tokenu podglądowego. Każdy element opisywany jest w kwadratowych nawiasach jako [A -> α·β, a], gdzie A -> α·β to element LR(0), a a to podgląd.
W celu uzupełnienia definicji automatu LR(1) potrzebujemy zdefiniować tranzycje między stanami. Tranzycje pomiędzy elementami LR(1) podobne są do tych występujących pomiędzy elementami LR(0), jedyną różnicą w tym przypadku jest śledzenie tokenu podglądowego. Tak jak w przypadku elementów LR(0) istnieje możliwość wystąpienia ε tranzycji stąd kluczowym jest zbudowanie automatu LR(1) z elementami, które zabezpieczają nas przed przejściem do innego stanu w przypadku wystąpienia ε. Główna różnica pomiędzy automatem LR(0) i automatem LR(1) pojawia się w definicji dla tranzycji ε. Spróbujmy najpierw zdefiniować element bez tranzycji ε: mając element [A -> α·Xγ, a], gdzie X to symbol dowolny wtedy istnieje tranzycja do elementu [A -> αX·γ, a] (do elementu, który posiada dokładnie taki sam podgląd). Elementy te nie sprawiają, że nowe tokeny podglądowe są brane pod uwagę. Tylko elementy z ε "dodają" nowe podglądy. Definicja elementów z ε tranzycją wygląda następująco: mając element [A -> α·Bγ, a], gdzie B to symbol nieterminalny ε tranzycja istnieje tylko dla elementów [B -> ·β, b] dla każdej produkcji B -> β oraz dla każdego tokenu b znajdującego się w zbiorze First(γa). ε tranzycja jest nieco bardziej skomplikowana dlatego teraz spróbujemy ją sobie lepiej wyjaśnić.
Zauważnie jak ε tranzycje śledzą kontekst, w którym struktura B musi być rozpoznana. W rzeczywistości element [A -> α·Bγ, a] mówi nam, że na ten moment podczas parsowania będziemy chcieli rozpoznać B, natomiast tylko wtedy gdy po symbolu B występuje string zawierający się w γa, również taki string musi zaczynać się terminalem znajdującym się w zbiorze First(γa). Jako, że string γ występuje po B w produkcji A -> αBγ, b, jeśli a znajduje się w zbiorze Follow(A) to zbiór First(γa) zawiera się w zbiorze Follow(B), wtedy b znajdujące się w elementach [B -> ·β, b] zawsze będą występować w zbiorze Follow(B). Przewaga względem SLR(1) polega na tym, że zbiór First(γa) może okazać się właściwym podzbiorem zbioru Follow(B) (parser SLR(1) niejako zaciąga tokeny podglądowe b z całego zbioru Follow). Zwróćcie uwagę, że a występuje jako token podglądowy b tylko wtedy gdy γ wyprowadza pustego stringa (w większości przypadków taka sytuacja zachodzi gdy γ okazuje się być ε, stąd specjalny przypadek dla ε tranzycji dla [A -> α·B, a] do [B -> ·β, a]).
Rozważmy poniższą gramatykę:
A -> (A) | a
Budowę automatu LR(1) rozpoczynamy od rozszerzenia naszej gramatyki poprzez dodanie elementu [A' -> .A, $], ε-closure tego elementu to stan początkowy automatu. Z uwagi na fakt, że po symbolu A nie występują żadne symbole w tym elemencie (nawiązując do poprzedniej terminologi string γ jest pusty). W elemencie tym występują dwie ε tranzycje: [A ->·( A ), $] oraz [A ->·a, $] (First(γ$) = $), stan 0 składa się z następujących elementów:
Stan 0:
[A'->·A, $]
[A ->·( A ), $]
[A ->·a, $]
Z tego stanu istnieje tranzycja przy wystąpieniu A do stanu zawierającego [A' -> A·, $], ponieważ stan ten zawiera elementy kompletne z tego stanu nie wychodzą żadne tranzycje, stan ten będzie stanem akceptacji i oznaczymy go jako stan 1:
Stan 1:
[A' -> A·, $]
Znów będąc w stanie 0 istnieje tranzycja przy wystąpieniu ( do stanu zawierającego element domykający (ε-closure) [A -> (·A ), $], ponieważ istnieją ε tranzycje dla tego elementu, rozwiązanie nie jest proste. ε tranzycje tego elementu to [A ->·( A ), )] i [A ->·a, )]. Dzieje się tak ponieważ w elemencie [A ->·( A ), $], A jest rozpoznawane jako prawastrona w kotekście nawiasów. Innymi słowy zbiór Follow prawejstrony A to First()$) = { ) } (utworzone zostały nowe tokeny podglądowe).
Stan 2:
[A -> (·A ), $]
[A ->·( A ), )]
[A ->·a, )]
Ponownie wracając do stanu 0, pozostała ostatnia tranzycja do stanu zawierającego element [A ->·a, $], ponieważ element ten jest kompletny, stan ten będzie składał się z jednego elementu:
Stan 3:
[A -> a·, $]
Teraz wracamy do stanu 2. Z tego stanu istnieje tranzycja przy wystąpieniu A do elementu domykającego [A -> ( A·), $]. Stan ten zawiera jeden element:
Stan 4:
[A -> ( A·), $]
Istnieje również tranzycja przy wystąpieniu ( do elementu domykającego [A -> (·A ), )]. Również generujemy dwa pozostałe elementy domykające w myśl tej samej zasady wymienionej w stanie 2.
Stan 5:
[A -> (·A ), )]
[A ->·( A ), )]
[A ->·a, )]
Zauważcie, że elementy te są dokładnie take same jak w stanie 2 poza tokenem podglądowym w elemencie pierwszym. Ostatnia już tranzycja dla stanu 2 przy wystąpieniu a do stanu 6 to:
Stan 6:
[A -> a·, )]
Ponownie zauważcie, że stan 6 posiada dokładnie taki sam element co stan 3 poza tokenem podglądowym. Następnym stanem posiadającym tranzycje jest stan 4, który posiada tranzycje przy wystąpieniu tokenu ) do stanu 7:
Stan 7:
[A -> ( A )·, $]
Wracając do stanu 5 istnieje tranzycja przy wystąpieniu tokenu ( do stanu 5 (do samego siebie) oraz tranzycja dla A do stanu 8:
Stan 8:
[A -> ( A·), )]
oraz tranzycja do istniejącego już stanu 6 dla a. Wreszcie tranzycja dla ) z stanu 8 do stanu 9:
Stan 9:
[A -> ( A )·, )]
DFA tych elementów posiada 10 stanów. Automat ten jest conajmniej dwa razy większy od automatu LR(0) zbudowanego dla tej samej gramatyki.

Zbudowana tablica przejśc parsera LR(1) (zbudowana analogicznie jak dla parsera SLR(1)):
| Stan | ( |
a |
) |
$ |
A |
|---|---|---|---|---|---|
| 0 | s2 | s3 | 1 | ||
| 1 | zaakceptuj | ||||
| 2 | s5 | s6 | 4 | ||
| 3 | r2 | ||||
| 4 | s7 | ||||
| 5 | s5 | s6 | 8 | ||
| 6 | r2 | ||||
| 7 | r1 | ||||
| 8 | s9 | ||||
| 9 | r1 |
Zanim rozważymy kolejny przykład, zdefiniujemy algorytm parsera LR(1) poprzez zmodyfikowanie algorytmu SLR(1) zamieniając zbiory Follow na tokeny podglądowe. Algorytm przedstawia się w następujący sposób, niech s będzie aktualnym stanem:
- Jeśli stan s zawiera jakikolwiek element w formie
[A -> α·Xβ, a]gdzieXjest symbolem terminalnym orazXjest następnym tokenem na wejściu to wykonane zostanie przesunięcie obecnego tokenu na stos, następnym stanem wrzuconym na stos będzie stan zawierający element[A -> αX·β, a]. - Jeśli stan s zawiera kompletny element
[A -> α·, a], a następnym na wejściu jestato wykonana zostanie redukcjaA -> α. RedukcjaS' -> Srównoznaczna jest z zaakceptowaniem stringa gdy następnym tokenem na wejściu jest$. W pozostałych przypadkach nowy stan dodawany jes następująco. Usuń stringαoraz wszystkie związane z nim stany wrzucone na stos, jednocześnie wróć do stanu, w którym konstrukcjaαsię zaczęła. Stan ten musi zawierać element w formie[B -> α·Aβ, b]. WrzućAna stos oraz stan zawierający element[B -> αA·β, b]. - Jeśli żadne z dwóch powyższych przypadków nie mogą zostać wykonane zgłaszany jest błąd analizy składniowej.
O gramatyce LR(1) mówimy wtedy gdy podczas wykonywania operacji nie występują żadne z poniższych konfliktów:
- Dla każdego elementu
[A -> αX·β, a]gdzieXto terminal, nie ma żadnego elementu w stanie s w formie[B -> γ., X], w przeciwnym wypadku otrzymamy konflikt przesunięcie-redukcja. - Nie ma dwóch elementów w stanie s w formie
[A -> α·, a]oraz[B -> β·, a], w przeciwnym wypadku otrzymamy konflikt redukcja-redukcja.
Rozważmy gramatykę LR(1) (gramatykę gdzie parser SLR(1) sobie nie radził):
S -> id | V := E
V -> id
E -> V | n
Poniżej przedstawiam zbudowany automat dla powyższej gramatyki. Należy zwrócić uwagę na stan 2 gdzie dla parsera SLR(1) występował konflikt. Elementy LR(1) wyraźnie rozróżniają dwie redukcje poprzez zastosowane tokeny podglądowe. Redukcje to S -> id dla $ oraz V -> id dla :=.

LALR(1) bazuje na obserwacji, że w wielu przypadkach rozmiar stanów automatu LR(1) spowodowany jest powtarzającymi się elementami LR(0) różniącymi się jedynie tokenem podglądowym w poszczególnych stanach. Algorytm parsowania LALR(1) identyfikuje wszystkie stany z powtarzającymi się elementami LR(0), które później deklarowane są jako jeden stan z połączonymi tokenami podglądowymi w zestaw podglądów. W przypadku elementów kompletnych zestawy tokenów poglądowych są zazwyczaj mniejsze od zbiorów Follow, stąd parsowanie metodą LALR(1) zachowuje część metodyki LR(1) jak i SLR(1) (zachowując tym samym mniejszy rozmiar od elementów automatu LR(0)). Pierwsza zasada LALR(1) mówi nam o tym, że rdzeniem (core) stanu DFA LR(1) nazywamy zbiór elementów LR(0) oraz wszystkich odpowiadające im tokeny podglądowe. Druga zasada LALR(1) definiuje możliwe tranzycje z poszczególnych stanów; mając dwa stany s1 i s2 automatu LR(1), które posiadają taki sam rdzeń jeśli istnieje tranzycja z stanu s1 do t1 dla symbolu X to i również istnieje tranzycja z stanu s2 do t2 dla symbolu X pod warunkiem, że stany t1 i t2 posiadają ten sam rdzeń. Zgodnie z tymi zasadami budowany jest automat LALR(1). W literaturze poszczególne tokeny podglądowe jako druga część elementu LALR(1) rozdzielane są znakiem / np. [A -> α·β, a/b/c] gdzie a, b i c to tokeny podglądowe.
Rozważcie poprzednią gramatykę:
A -> (A) | a
Parser LALR(1) identyfikuje stany LR(1) następnie łączy je co skutkuje zmniejszeniem rozmiaru automatu do postaci:
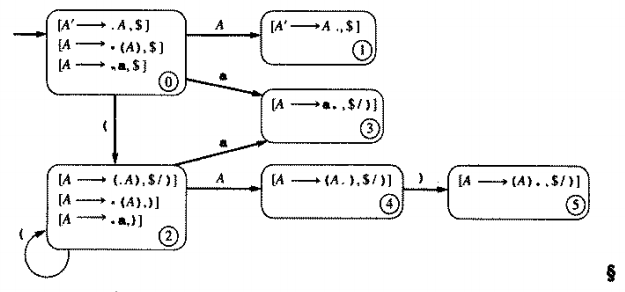
Algorytm parsowania LALR(1) jest identyczny co do algorytmu parsowania LR(1). O gramatyce LALR(1) mówimy wtedy gdy nie występują konflikty. Co ciekawe możliwe jest otrzymanie konfliktów dla LALR(1) gdy nie występują one dla LR(1) (w praktyce rzadko się to zdarza). Jeśli gramatyka jest gramatyką LALR(1) to jest i również gramatyką LR(1). Jeśli gramatyka jest gramatyką LR(1) to pewnym jest, że ta sama gramatyka nie niesie za sobą konfliktów przesunięcie-redukcja dla LALR(1), możliwe natomiast jest otrzymanie konfliktów redukcja-redukcja. Niemniej jednak jeśli gramatyka jest gramatyką SLR(1) to jest i również gramatyką LALR(1), który działa prawie tak dobrze jak LR(1). Jedną z wad algorytmu LALR(1) względem LR(1) jest późne zgłaszanie błędu spowodowane "fałszywą" redukcją podczas parsowania. Dla przykładu parsując zdanie (dla poprzedniej gramatyki) a) parser LALR(1) najpierw wykona redukcję A -> a zanim zadeklaruje błąd podczas gdy parser LR(1) natychmiast zgłosi błąd po przesunięciu a (wrzuceniu a na stos) w literaturze takie zachowanie określane jest jako spurious error.
Łącząc stany LR(1) w celu zbudowania automatu LALR(1) pozbywamy się problemu dużych tablic, niestety wciąż elementy LR(1) muszą zostać utworzone jeśli naszym celem są elementy LALR(1). Istnieje jeszcze inny sposób na wyliczenie elementów LALR(1) korzystając jedynie z elementów LR(0) za pomocą procesu nazywanego propagating lookaheads. Na koniec warto wspomnieć, że generator parserów Yacc bazuje na algorytmie LALR(1).
Na koniec chciałbym przedstawić generator parserów o nazwie Bison, poniżej znajduje się lista świetnych tutoriali odnośnie tego generatora:
Flex and Bison - Aquamentus
Flex and Bison in C++ - Jonathan Beard
Using Flex and Bison - Mactech
Podczas analizy semantycznej na podstawie utworzonej struktury drzewa następuję sprawdzanie poprawności typów, instrukcji i programu jako całości (analiza ta sprawdza czy program ma jakikolwiek sens). Ilość zadań i poziom skomplikowania zależy w głównej mierze od specyfikacji języka. Przykład na jakim etapie się znajdujemy (Java):
class MyClass implements MyInterface { // Niezadeklarowany interfejs.
string myInteger;
void doSomething() {
int[] x = new string; // Niepoprawny typ.
x[5] = myInteger * y; // Brak mozliwosci mnozenia stringow. Nie zadeklarowana zmienna.
}
void doSomething() { // Brak mozliwosci duplikacji tej samej funkcji.
}
int fibonacci(int n) {
return doSomething() + fibonacci(n - 1); // Nie mozna dodawac typu void.
}
}
// Brak funkcji main.Na etapie analizy semantycznej kompilator ma za zadanie zweryfikować przypadki, które nie zostały wychwycone w poprzednich etapach:
- Deklaracja zmiennych przed ich użyciem
- Poprawny typ wyrażeń
- Klasy dziedziczą po zadeklarowanych klasach bazowych
- ...
Po analizie semantycznej wiemy już, że kod napisany przez użytkownika jest poprawny. Idealny kompilator powinien zaakceptować jak najwięcej poprawnych programów jednocześnie jak najmniej niepoprawnych programów (C++):
int main() {
std::string x;
if (false) {
x = 137; // Niewykonywalna czesc kodu.
}
return 0;
}int fibonacci(int n) {
if (n <= 1)
return 0; // Niepoprawna wartosc zwracana. Powinno byc n
// Brak mozliwosci zgloszenia bledu przez kompilator.
return fibonacci(n - 1) + fibonacci(n - 2);
}
int main() {
std::cout << fibonacci(40);
return 0;
}Jest jeszcze jedna ważna rzecz - czas wykonania powinien być możliwie jak najkrótszy (to właśnie analiza semantyczna trwa najczęściej najdłużej). Podczas analizy semantycznej zebrane zostają informacje potrzebne do utworzenia reprezentacji pośredniej takie jak znaczenie identyfikatorów i liczba zmiennych w danym zasięgu widoczności. Tak jak w przypadku skanera potrzebny był parser chociażby z powodu pumping lemma czy Ogden's lemma tak samo analiza składniowa ze względu na swoje ograniczenia wymusza istnienie analizy semantycznej. W implementacji analizatora wyróżniamy dwie główne metodyki, pierwsza określana jest jako attribute grammars druga natomiast jako recursive AST walk. W tej części artykułu wykorzystamy metodę rekurencyjnego przechodzenia po AST bazującą na funkcjach wirtualnych.
Zasięg widoczności określa zakres w jakim dany identyfikator jest widoczny. Skąd wiemy do jakiego obiektu odnosi się poszczególny identyfikator? Jak przechowujemy informacje na temat poszczególnego identyfikatora? Identyfikatory o tej samej nazwie mogą odnosić się do kompletnie innych obiektów. Przykłady kodów kompilowalnych (Java, C++):
public class A {
char A;
A A(A A) {
A.A = 'A';
return A((A)A);
}
}int Awful() {
int x = 137;
{
std::string x = "Scope!"
if (float x = 0)
double x = x;
}
if (x == 137)
std::cout << "Y";
}Podczas analizy semantycznej każda nowa deklaracja identyfikatora dodawana jest do tzw. tablicy symboli (symbol table), ta zdefiniowana jest jako pusta, w momencie przeskoczenia do nowego zakresu dodawany jest stos reprezentujący zakres. W przypadku gdy na danym poziomie zasięgu znaleziony zostanie duplikat identyfikatora ogłaszany jest błąd analizy semantycznej. Zauważmy, że tego typu błąd nie występuje gdy ta sama nazwa identyfikatora (również tego samego typu) znajduje się o n poziomów wyżej. Nasza tablica reprezentowana jest za pomocą stosu z wskaźnikiem na rodzica (spaghetti stack) tym samym identyfikator szukany jest najpierw w zakresie, w którym się znajduje, nie znaleziony symbol szukany jest o poziom wyżej, a w przypadku braku symbolu ogłoszany jest błąd analizy semantycznej (brak potrzeby implementacji wskaźnika na dziecko).

Taki typ struktury definiuje cztery główne operacje: dodaj/usuń zakres (push/pop scope), dodaj/znajdź symbol (insert/lookup symbol). Przykładowa implementacja to najzwyklejsze zdefiniowanie klasy reprezentującej zakres po której dziedziczą klasy funkcji, instrukcji warunkowych, klasy, pętle itd.
class Scope {...};
class FunctionCall : public Scope {...};
class IfStatement : public Scope {...};
class ClassDefiniton : public Scope {...};
class ForLoopStatement : public Scope {...};
...Każda z powyższych klas rozszerza klasę bazową Scope, podczas analizy wołane są jej odpowiedniki (spora część analizy opiera się na tego typu rozwiązaniu). Inne spojrzenie na tablicę symboli

W sytuacji, w której dana klasa posiada rodzica (dziedziczy po innej klasie) przechowany zostaje wskaźnik na stos zakresu klasy bazowej (symbol szukany jest również w klasie bazowej):


Z uwagi na fakt, iż parsery LL(1) i LR(1) znają swój następny token skanowanie oraz parsowanie może odbywać się w tym samym czasie podczas jednego etapu. Niektóre kompilatory przeprowadzają skanowanie, parsowanie, analizę semantyczą i generację kodu jednoetapowo. Taki typ kompilatora określany jest jako single-pass compiler (niektóre starsze kompilatory Pascala działały w ten sposób, języki takie jak C i C++ zaprojektowane są w sposób ułatwiający implementację kompilatora jednoetapowego). Obecnie najczęściej możemy spotkać kompilatory przeprowadzające analizy wielokrotnie ze zwględu na zbyt skomplikowaną semantykę, kompilatory te określane są jako multi-pass compiler. Ciekawą zaletą kompilatorów wieloetapowych jest to, że zebrane informacje z poprzednich przejść mogą zostać wykorzystane poźniej. Jednym z rozwiązań może być implementacja tablicy symboli jako struktury, w której każdy zakres reprezentowany jest przez tablicę mieszającą (hash table). W tablicy mieszającej interesują nas tak naprawdę trzy rzeczy, wielkość tablicy, metoda niwelująca kolizje (collision resolution) oraz algorytm hashujący. Kolizji pozbywamy się implementując każdy kubełek jako liste jednokierunkową (lub drzewo binarne). Algorytm hashujacy to kwestia indywidualna, jednym z rozwiązań może być algorytm SHA-1. Jeśli chodzi o wielkość tablicy to sprawa jest nieco bardziej skompilowana. Pomijając fakt, że poprzednie problemy mogą w ogóle nie być brane pod uwagę zakładając, że używamy rozwiązań zaimplementowanych już w wielu językach to sama wielkość tablicy nie jest nam znana. Zbyt duża tablica niepotrzebnie zabiera miejsce w pamięci natomiast zbyt mała spowoduje dużą ilość kolizji. W momencie, w którym nasz kompilator jest wieloetapowy możemy założyć, że każda deklaracja identyfikatora to potencjalny nowy symbol w tablicy, implementując swego rodzaju licznik możemy w mniejszym lub większym stopniu oszacować wielkość tablicy.
Zakres statyczny (static/lexical scoping) definiuje związek między strukturą kodu źródłowego, a symbolami, których adresy wyliczane są podczas kompilacji. Wszystkie dotychczas omawiane przykłady korzystały z tablicy symboli wyliczanej na kompilacji. W takim przypadku to struktura kodu definuje widoczność symboli. Poniżej przykład kodu napisanego w języku C:
#include <stdio.h>
int x = 10;
int f() { return x; }
int g() { int x = 20; return f(); }
int main()
{
printf("%Wynik: d\n", g()); // Wynik: 10
return 0;
}Znanymi językami programowania korzystającymi z statycznych zakresów są np. Java i C++.
Zakres dynamiczny (dynamic scoping) nie definiuje bezpośrednio związku między strukturą kodu źródłowego, a symbolem, to aktualny stan stosu programu ustala do którego symbolu się odnosimy. Jest to niezwykle nietypowe podejście występujące w językach takich jak Perl czy Lisp. Zasięg widoczności, rozwiązywany podczas pracy programu jest stosunkowo wolniejszy, dzieje się tak z powodu "niezakodowanych" adresów zmiennych. W dużym uproszczeniu podczas pracy programu będąc w danej funkcji program najpierw sprawdza czy szukana zmienna znajduje się w obrębie tego samego zakresu jeśli nie to szuka dalej tym razem w funkcji z której została zawołana. Poniżej przykład kodu napisanego w języku Pseudo-C:
#include <stdio.h>
int x = 10;
int f() { return x; }
int g() { int x = 20; return f(); }
int main()
{
printf("%Wynik: d\n", g()); // Wynik: 20
return 0;
}Animacja przedstawiająca wartości wrzucane do tablicy symboli podczas pracy programu:

Systemem typów (type system) nazywamy zbiór wszystkich możliwych wyrażeń w zależności od rodzajów wartości, jakie one generują. Każdej obliczonej wartości przypisywany jest pewien typ, który jednoznacznie definiuje, jakie operacje można na nim wykonać. Zadaniem kompilatora jest zgłaszanie błędów o niezgodności typu wtedy gdy przeprowadzane operacje są niezdefiniowane (np. brakujący operator przypisania). Sprawdzanie poprawności typów podczas kompilacji określane jest jako static type checking (kompilacja nie powiedzie się w przypadku błędów) występujące np. w języku Go. Istnieją również języki, w których operacje na typach sprawdzane są podczas działania programu (dynamic type checking) (sprawdzanie jest zazwyczaj wolniejsze lecz bardziej precyzyjne), popularnym językiem korzystającym z tego typu rozwiązania jest Python. Sytem typów dzieli języki programowania na silnie typowane (strongly typed): Java, Python, JavaScript, Haskell i słabo typowane (weakly/loosely typed): C, C++. Języki silnie typowane nie pozwalają programiście na jakiekolwiek błędy związane z typami podczas gdy języki słabo typowane są zazwyczaj szybsze (niejawne konwersje) i mniej dokładne (nie każdy błąd zostaje wykryty na kompilacji). Podczas tego artykułu postaramy przyjrzeć się typowaniu słabemu oraz statycznemu sprawdzaniu poprawności typów.
Podczas analizy semantycznej kompilator ma za zadanie wydedukować jakiego typu jest każde napotkane wyrażenie. Wyrażeniem nazywamy każdy obiekt, który może przyjąć typ:
int x = function(); // Wartosc zwracana przez funkcje
const char* str = "string"; // Wartosci stalych
int y = x * 5; // Wartosci z wynikow dzialan arytmetycznych
int z = y; // Wartosci zmiennych
...Następnym (równoległym) zadaniem jest sprawdzenie poprawności wyrażeń w kontekście. Dla przykładu 1.0 + 4.0 jest wyrażeniem poprawnym jednak niepoprawnym względem instrukcji if, który oczekuje typu boolean (lub innego typu w zależności od semantyki języka):
if (1.0 + 4.0) {
/* ... */
}Jak wywnioskować jakiego typu jest wyrażenie? Przykład:

Jeśli stała 137 jest typem całkowitym to oczekujemy tego samego typu również i po prawej stronie dodawania 42 (lub typu, w którym dozwolone jest dodanie liczby całkowitej). Analizę semantyczną traktujemy jako jeden wielki if, w momencie gdy występuje zgodność typów łączymy wyrażenia w całość. System typów rozumiany jest również jako zbiór możliwych operacji na typach.
Jeśli x to identyfikator odwołujący się do obiektu typu t to x jest typu t (int x;). Jeśli e to liczba stała to e jest typu int. Jeśli argumentami wyrażenia x + y jest x typu int oraz y typu int to wyrażenie przyjmuje typ int itd. W przypadku gdy w wyrażeniu znajduje się stała i identyfikator nie należy zakładać, że identyfikator jest tego samego typu co stała (typ zmiennej należy bezpośrednio wyciągnąć z tablicy symboli):
int function(int x)
{
{
double x;
}
if (x == 1.5) // Nie nalezy zakladac ze zmienna x jest typu double.
{ // Pomijamy fakt ze porownywanie typow double odbywa sie za pomoca przyblizen.
/* ... */
}
}
Avanced C and C++ Compiling
Compiler Construction Principles and Practice
Linkers and Loaders
Anatomy of Program in Memory
An Introduction to GCC
Beginner's Guide to Linkers
Position Independent Code and x86-64 libraries
Depth First and Breadth First Tree Walking
Version Script
Calling Conventions Demystified
The History of Calling Conventions
Name Mangling
Binary File Descriptor
Stanford CS143 About Compilation