[Op] Layout Customization Support #90
Assignees

Labels
feature
Feature that requires significant code change
Comments
chhzh123
added a commit
that referenced
this issue
Jun 25, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Data layout is an important problem that requires organizing data into memory. Traditionally, Struct of Arrays (SOA) and Arrays of Struct (AOS) are two popular choices to map multiple arrays to memory. Considering nowadays big data and deep learning workload consisting of high-dimensional arrays, data layout is not just about the organization of multiple structures, but also about the placement of different dimensions in a tensor.
Existing libraries or compilers do have interface to support layout customization, but they are not flexible enough to support different workloads -- their specification always couple with computation and is hard to change the layout without rewriting the algorithm. Numpy uses
.transpose()to change the dimensions of an array, but it does not change the physical location of the data and only changes the strides.Intel oneDNN uses
dnnl::memory::format_tagto specify the tensor layout, but it is hard-coded in the algorithm implementation. Users cannot easily change it unless they rewrite the library function.TVM decouples the layout and provides a ConvertLayout Pass for users to pass in their desired layouts of the tensors 1, but the layouts are attached to operators, and users cannot specify the layout of arbitrary tensors (e.g. intermediate arrays inside an operation).
There are also some specific challenges for FPGA to specify data layouts. First, FPGA can support arbitrary bitwidth data types, but not only 8/16/32/64 that are supported by CPU/GPU, which brings more choices when customizing the layout. Second, the memory space of FPGA is not monolithic but can be partitioned into different memory banks. Later on, we may want to unify the
partitionprimitive and thelayoutone since partitioning an array is actually changing its layout.We can summarize the issues listed below:
conv2d_NCHW,conv2d_NHWC, andconv2d_NCHWc, which may mess up the library.NCHW, and TensorFlow usesNHWC). Previous research shows thenChw16clayout may be good for CPU 2, but it is not sure whether16is the best packing factor for GPU and FPGA.To solve the above challenges, we decouple the layout customization from computation and propose the
hcl.layoutprimitive. For the Python frontend, we support the following formats:s.layout(<tensor>, <LayoutEnum>)s.layout(<tensor>, <LayoutMap>, <Implementation>)The following example shows a binary convolution kernel written in
NCHWformat. By adding thes.layout(B, hcl.DenseLayout.NHWC)operation, we change the layout of tensorBtoNHWCas a part of our compilation pass. HereNHWCis a predefined enumeration value. Later on, we can also support sparse format using a similar notation likehcl.SparseLayout.CSR.The generated MLIR code is shown below. There is an affine map attached to the

layoutoperation, which specifies the mapping from the previous index space to the new index space. After applying this primitive, we can see the shape of tensorBand the indices both changed. Since layout only tells where to retrieve the data but not how to compute them, only changing the indices is fine and preserves the correctness. If users want to have a better locality on CPU, then they need to explicitly reorder the loops to ensure the traversal order is the same as the memory organization.The second format is to pass in a lambda function that explicitly specifies the layout. The following example shows changing the layout to
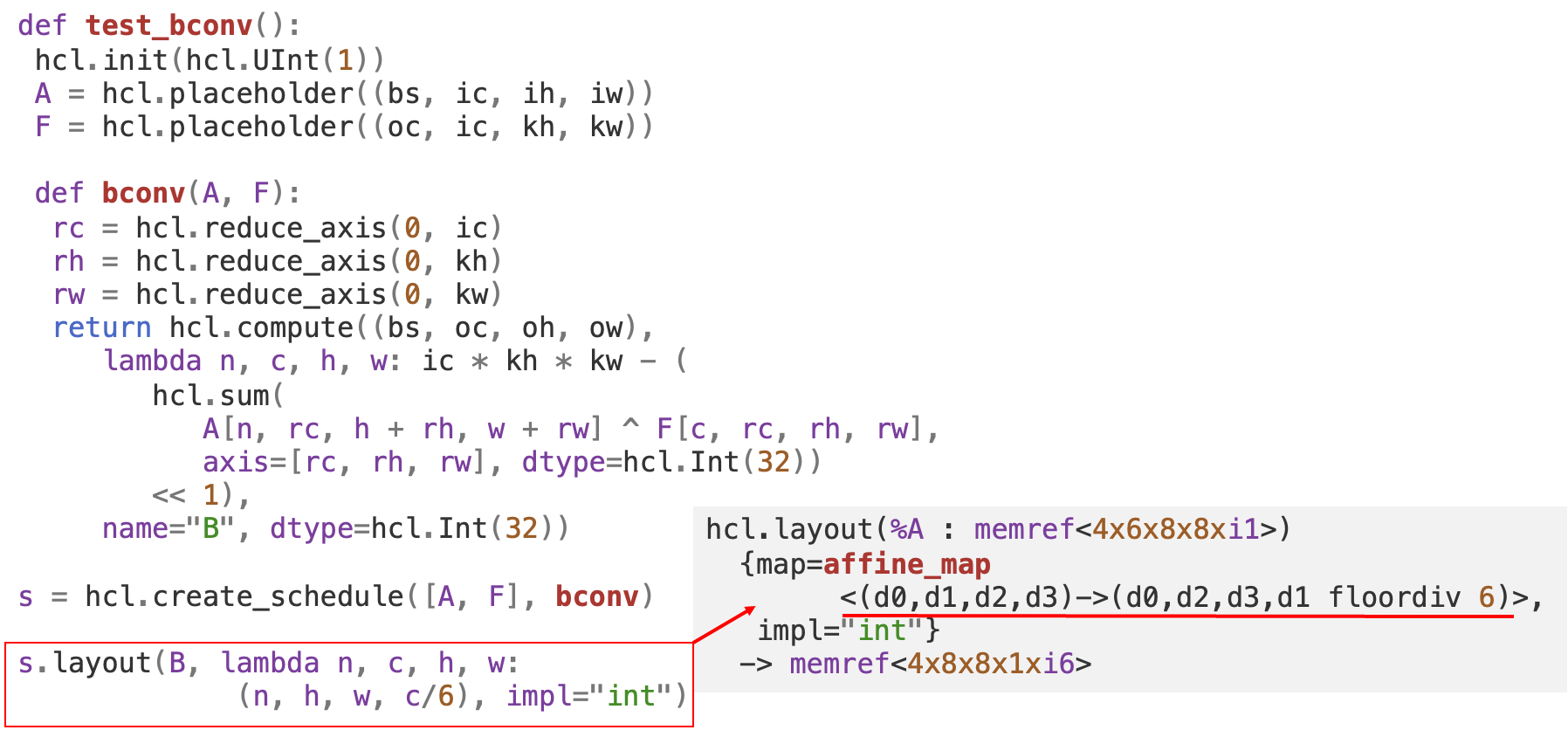
NHW(C6)with the last channel dimension packed. The data type is also changed in this case.Users can also pass in the
implparameter to specify which implementation they want to use. There are two different implementations for this packed layout. One is using thevectordialect, the other is using a large bitwidth integer. The differences are listed in the table below.memref<4x8x8x1xvector<6xi1>>Can work for floating/fixed-point and large numbers of elements
memref<4x8x8x1xi6>%a_vec = affine.load %A[%n, %h, %w, %c floordiv 6]%a = vector.extractelement %a_vec[%c mod 6] : vector<6xi1>%a_int = affine.load %A[%n, %h, %w, %c]%a = hcl.get_bit(%a_int, %c mod 6) -> i1%a_new = vector.insertelement %sum, %c_vec[%c mod 6] : vector<6xi1>affine.store %a_new, %A[%n, %h, %w, %c floordiv 6] : memref<4x8x8x1xvector<6xi1>>%a_new = hcl.set_bit(%a_int, %c mod 6)affine.store %a_new, %A[%n, %h, %w, %c] : memref<4x8x8x1xi6>Currently, we still load/store the data element by element, but in the end, we need to fully vectorize the code with vectorized computation.
Footnotes
Jared Roesch, Steven Lyubomirsky, Logan Weber, Josh Pollock, Marisa Kirisame, Tianqi Chen, Zachary Tatlock, Relay: A New IR for Machine Learning Frameworks, MAPL, 2018 ↩
Yizhi Liu, Yao Wang, Ruofei Yu, Mu Li, Vin Sharma, and Yida Wang, Optimizing CNN model inference on CPUs, ATC, 2019 ↩
The text was updated successfully, but these errors were encountered: