YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT #6067
Comments
|
@AlexeyAB Really great work! For training, same partial weights as old tiny Yolo i.e. the first 15 layers |
|
Use this pre-trained file for trainint How to train yolov4-tiny.cfg: https://github.com/AlexeyAB/darknet#how-to-train-tiny-yolo-to-detect-your-custom-objects |
|
Hi @alexeab, Does OpenCV DNN module supports YoloV4-tiny? Thanks |
|
We are waiting for the implementation of the YOLOv4-tiny in libraries: |
OpenCV implemented it in their master branch in 6 days for Yolov4. This looks like a more trivial change required so here's hoping it will be live in a few days. |
|
@AlexeyAB v. exciting. are you planning to release a paper on it? Would love to read some details about how it works. Is it a novel backbone or one of the existing CSPs? Do you have any numbers on the performance of the backbone as a classifier? |
|
|
@AlexeyAB Can you explain why the last yolo layer uses masks starting from 1, not 0? |
|
confirmed. performance is WOW. |
|
@CSTEZCAN Hi, On GPU RTX 2070, CPU Core i7 6700K
|
|
@DoriHp Just to compare with Yolov3-tiny where were used the same masks, it seems tiny models don't detect well small objects anyway. |
|
I saw yolov3-tiny_3l.cfg with 3 yolo layers. So due to what you said, the last yolo layers has no use? |
|
To detect small objects you must also use 3-yolo-layers in yolov4-tiny. |
|
@AlexeyAB Hello Alexey! this is your "Piano Concerto No. 2 Op. 18". I have infinite respect for your work. My results as follows; nvidia-smi -pl 125 watts titan x pascal nvidia-smi -pl 250 watts titan x pascal Will be running tests on Jetson Nano, TX2 and Xavier later.. |

|
@CSTEZCAN Thanks! I think yolov4-tiny can work with 500 - 1000 FPS by using OpenCV or tkDNN/TensorRT when it will be implemented in these libraries. |
|
@AlexeyAB I have no doubt. The only weird thing I noticed is, it uses CPU relatively more during training compared to YOLOv4. The recommended system must start from Ryzen 3500 and above for an optimal performance (if you are creating such recommended setup list) :) |
Thank you so much for your time and help! |
|
Hi, @AlexeyAB , thanks for your great job. $Traceback (most recent call last): When I change "buf = np.fromfile(fp, dtype = np.float32)" to "buf = np.fromfile(fp, dtype = np.float16)" in darknet2caffe.py, this error is disappear. Is it correct? |
|
Tested on Xavier NX, with 720p video, fps was around 5 to 8. |
|
Hi, firstly, thanks for the wonderful implementation! Thanks |
You cannot. What is it that you want to do? |
Hi, thanks for the quick reply. |
what do you mean? use the weights alexeyab has provided. |
|
The issue is that I used alexeyab weights and cfg files like below... But I get the runtime error: shape [256,384,3,3] is invalid input of size 756735. How do I resolve this? |
I don't know, why don't you ask on that repo? I don't think you'll get an answer about a different repo here. |
|
I have a question a few questions that I wrote in this issue: #6548 but had not resolution. Please see below: I am in the process of detecting I calculated these custom achors: Custom anchors
I took what you said, and applied it as such to my Here is my 3 Questions: 1. The mAP barely improves. Is there something I did not implement correctly?2. Is there a reason we are detecting the largest anchors first ( >60x60) --> (>30x30) --> (<30x30) ? I read somewhere that this order does not matter.3. In the case of the
|
|
Hey @AlexeyAB !! |
SSDMobileNetv2 is lower |
|
@wwzh2015 : Can you please share this comparison? |
|
@AlexeyAB |
|
Hi, @AlexeyAB , thanks for your great job. |
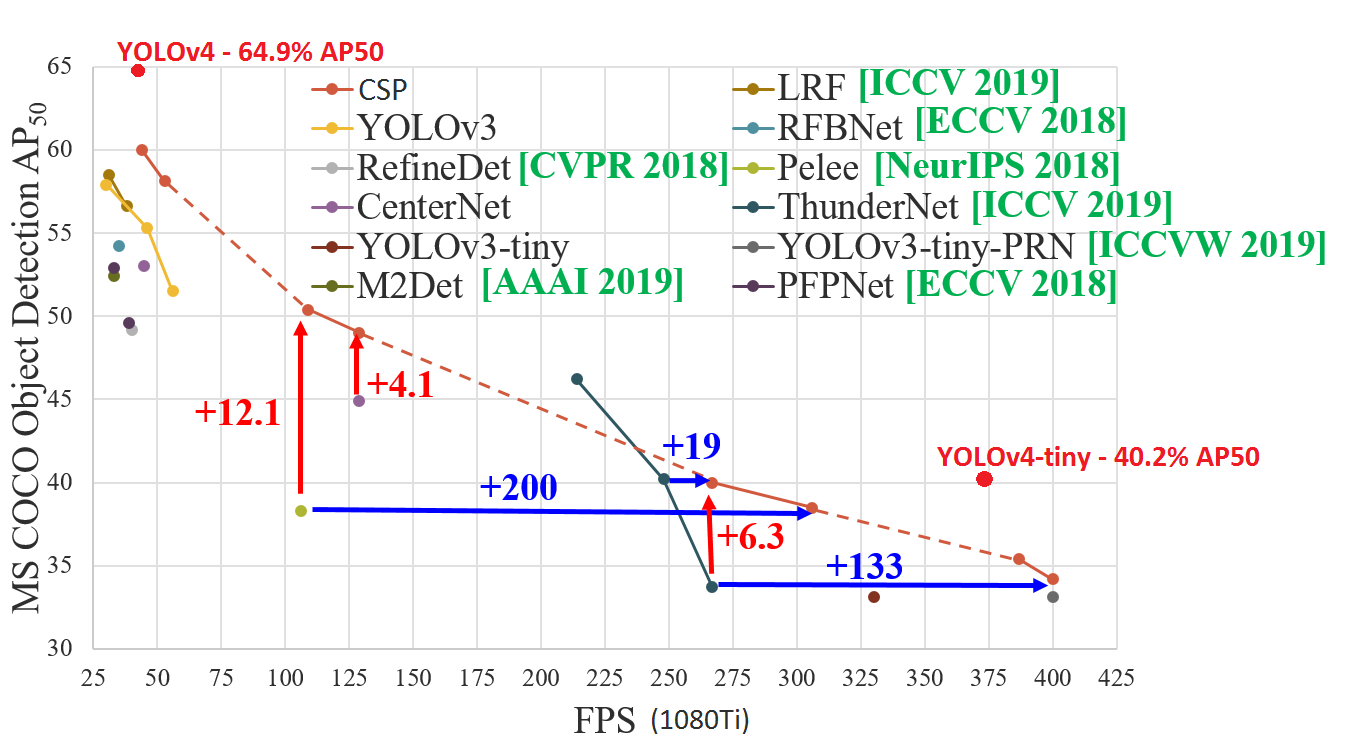
hi AlexeyAB, thanks for your great job. could you tell me which datasets the pictures is from? thanks. |



|
i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet . |
|
if you only test the generalization ability of the model ,you can get some test dataset on the overpass!
…--------------------------------
Best Regards
刘黎明
Tel:15910968546
微信: llm454650810
QQ:632846506
----- 原始邮件 -----
发件人:"Kin-Yiu, Wong" ***@***.***>
收件人:AlexeyAB/darknet ***@***.***>
抄送人:lliming2006 ***@***.***>, Comment ***@***.***>
主题:Re: [AlexeyAB/darknet] YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT (#6067)
日期:2021年06月01日 17点59分
i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet .
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or unsubscribe.
|
Okay, thanks for your reply. |
thanks! |
|
@DoriHp Can you explain why the last yolo layer uses masks starting from 1, not 0? in yolov4-tiny. did you get the answer or is it a mistake? |
|
We just follow yolov3-tiny to use masks starting from 1 for fair comparison. |
|
In that case you are not going to use the last anchor size. am I correct? |
|
yes, anchor with index 0 is not used in that case. |
did anyone explain how the backbone of yolov4-tiny works? it is easy to follow yolov4-custom.cfg but in yolov4-tiny.cfg it becomes difficult for me to understand. in the route layer there is groups parameter does this indicate group convolution? if there is group convolution don't we need shuffle parameter too? @AlexeyAB @WongKinYiu please give us a reading reference how the architecture of the backbone implemented? I have seen @AlexeyAB response here #6067 (comment) |
It means,
So in Pytorch it can be implemented as: Look at the Full structure of yolov4-tiny.cfg model This is related to the CSP paper: https://openaccess.thecvf.com/content_CVPRW_2020/html/w28/Wang_CSPNet_A_New_Backbone_That_Can_Enhance_Learning_Capability_of_CVPRW_2020_paper.html
|

|
@AlexeyAB thank you for your great illustration of the Yolov4-tiny backbone structure. |
Discussion: https://www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4/
Full structure: structure of yolov4-tiny.cfg model
YOLOv4-tiny released:
40.2%AP50,371FPS (GTX 1080 Ti) /330FPS (RTX 2070)1770 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) tkDNN/TensorRT Feature-request: YOLOv4-tiny (detector) ceccocats/tkDNN#59 (comment)
1353 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) OpenCV 4.4.0 (including: transfering CPU->GPU and GPU->CPU) (excluding: nms, pre/post-processing) YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT #6067 (comment)
39 FPS- 25ms latency - on Jetson Nano - (416x416, fp16, batch=1) tkDNN/TensorRT Feature-request: YOLOv4-tiny (detector) ceccocats/tkDNN#59 (comment)290 FPS- 3.5ms latency - on Jetson AGX - (416x416, fp16, batch=1) tkDNN/TensorRT Feature-request: YOLOv4-tiny (detector) ceccocats/tkDNN#59 (comment)42 FPS- on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) - (416x416, fp16, batch=1) OpenCV 4.4.0 (compiled with OpenVINO backend) YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT #6067 (comment)20 FPSon CPU ARM Kirin 990 - Smartphone Huawei P40 MobileNetV2-YOLOv3-Nano: Detection network designed by mobile terminal,0.5BFlops🔥🔥🔥HUAWEI P40 6ms& 3MB!!! #6091 (comment) - Tencent/NCNN library https://github.com/Tencent/ncnn120 FPSon nVidia Jetson AGX Xavier - MAX_N - Darknet framework371FPS on GPU GTX 1080 Ti - Darknet frameworkThe text was updated successfully, but these errors were encountered: