Inference speed issue #9951
Comments
|
👋 Hello @bgyooPtr, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
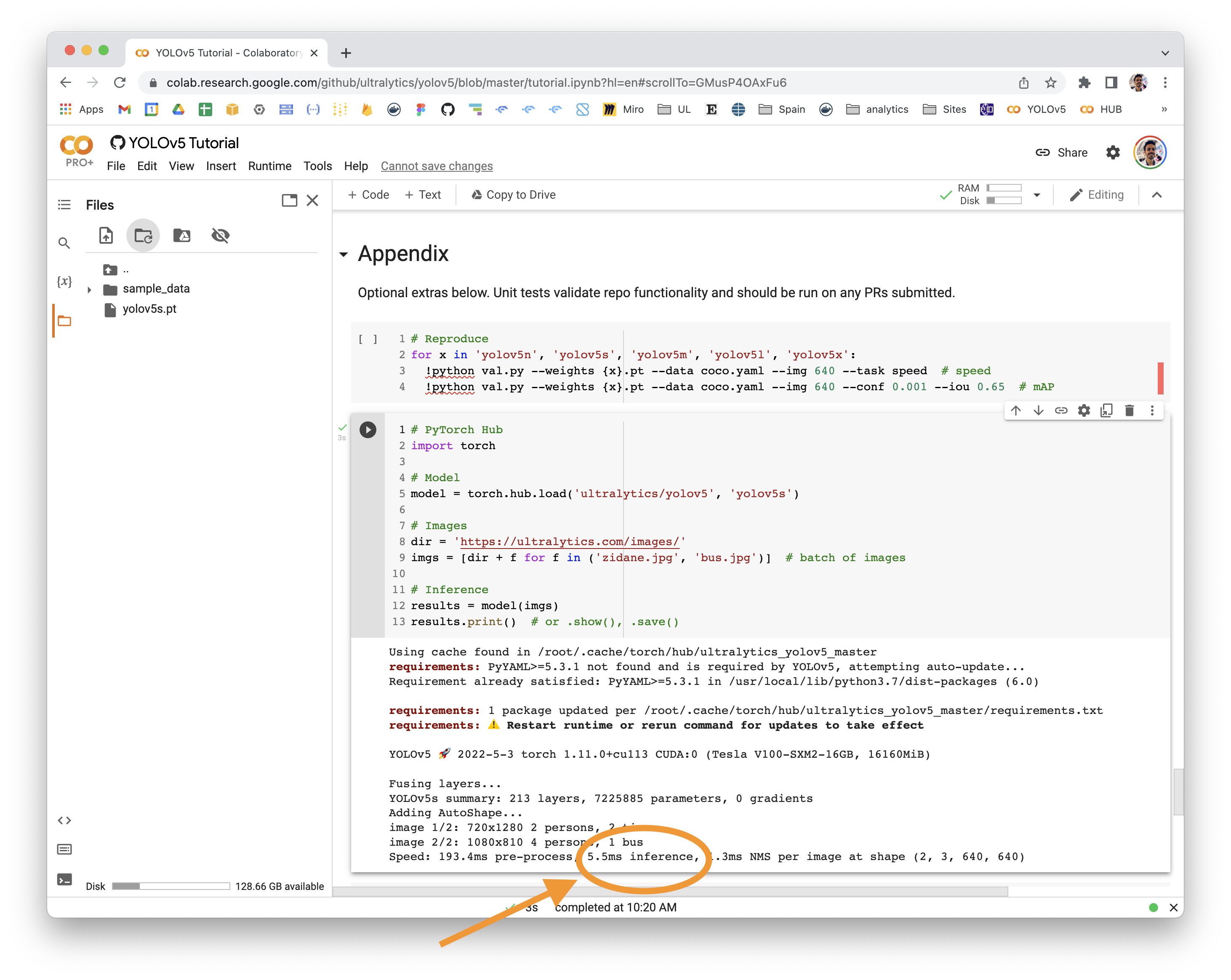
👋 Hello! Thanks for asking about inference speed issues. PyTorch Hub speeds will vary by hardware, software, model, inference settings, etc. Our default example in Colab with a V100 looks like this:
YOLOv5 🚀 can be run on CPU (i.e. detect.py inferencepython detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/
YOLOv5 PyTorch Hub inferenceimport torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
dir = 'https://ultralytics.com/images/'
imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images
# Inference
results = model(imgs)
results.print() # or .show(), .save()
# Speed: 631.5ms pre-process, 19.2ms inference, 1.6ms NMS per image at shape (2, 3, 640, 640)Increase SpeedsIf you would like to increase your inference speed some options are:
Good luck 🍀 and let us know if you have any other questions! |

|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
Search before asking
YOLOv5 Component
Detection, Integrations
Bug
When executing real-time prediction using Realsense d415, there is a big difference in speed depending on the camera fps.
The higher the camera FPS, the slower the inference speed.
Obviously, I wonder why this happens even though the function that reads data is composed of threads.
avg time: 10.963139772415161
avg time: 24.456851720809937
avg time: 35.522178649902344
Environment
Fusing layers...⚠️ --img-size [500, 500] must be multiple of max stride 32, updating to [512, 512]
Model summary: 157 layers, 1760518 parameters, 0 gradients, 4.1 GFLOPs
WARNING
Minimal Reproducible Example
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: