Problem on running Hyperparameter Evolution on Big Dataset #9916
Comments
|
May I ask Hyperparameter Evolution --evolve is trying to find the optimal hyperparameters? I think it should be to perform such task. |
|
👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
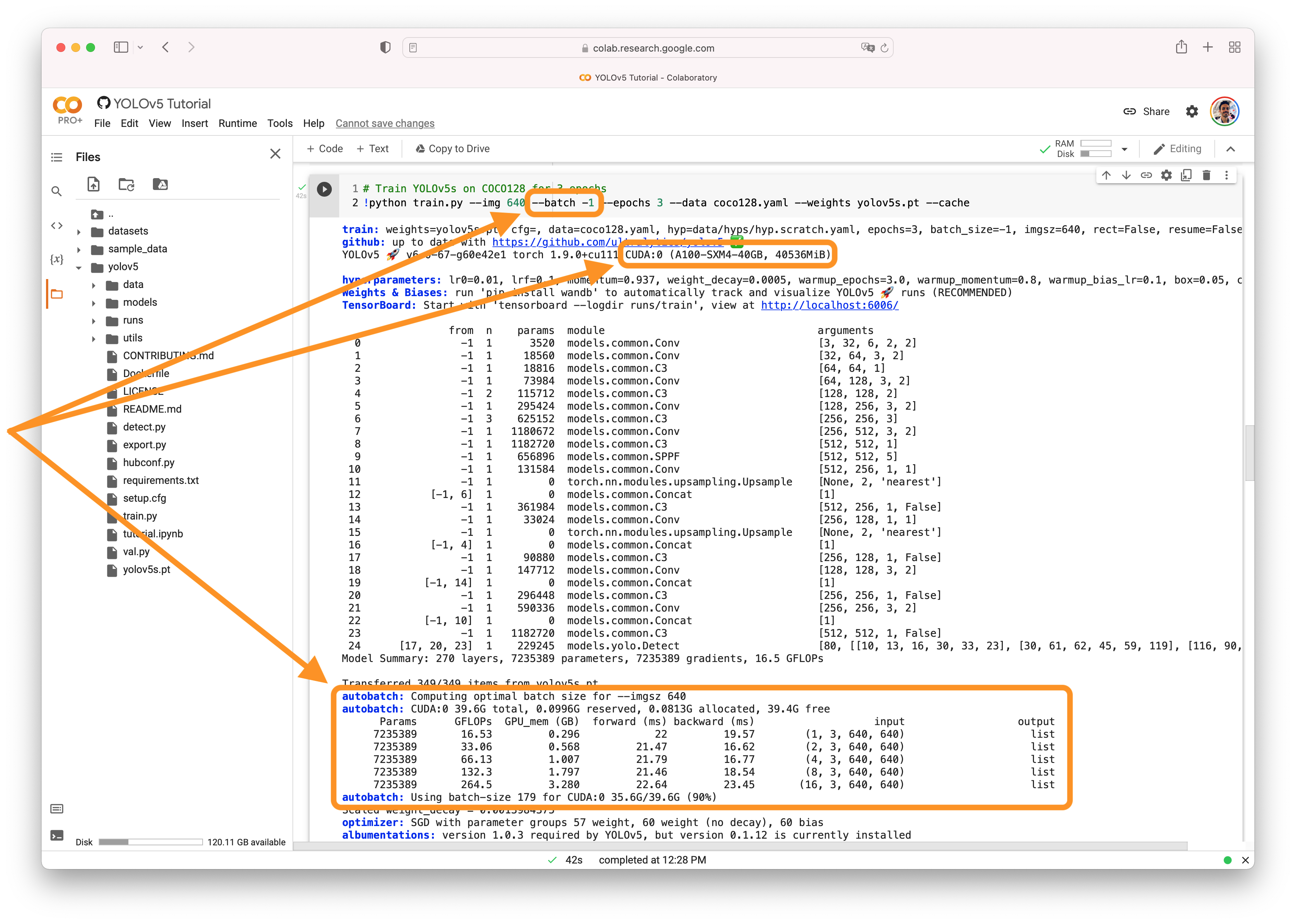
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
Search before asking
YOLOv5 Component
Evolution
Bug
Good morning,
I am trying to run Hyperparameter Evolution on a relatively big dataset (>1million images and >200GB), but I am facing issues with it.
The code I am using to run it is quite simple:
python train.py --data my_dataset.yaml --weights 'yolov5s6.pt' --cfg yolov5s.yaml --batch 32 --img 1280 --epochs 1 --evolve 25
python train.py --data my_dataset.yaml --weights 'yolov5s6.pt' --cfg yolov5s.yaml --batch 32 --img 1280 --epochs 2 --evolve 12
Some of the errors that happen:
1- Run all the epochs for a given generation, then crash during the validation.
The errors that appear are
AttributeError: 'NoneType' object has no attribute '_free_weak_ref'
Exception ignored in: <function StorageWeakRef.del at 0x2b6fee3035e0>
AttributeError: 'NoneType' object has no attribute '_free_weak_ref'
slurmstepd: error: Detected 3 oom-kill event(s) in StepId=22501303.batch cgroup. Some of your processes may have been killed by the cgroup out-of-memory handler.
However, when I was checking, the batches were occupying 22GB of 32GB of the memory.
2- Sometimes it run the generation properly but them just stop to work at the model summary screen
Environment
Also tried => Cuda 10.2, Torch 1.11, Torchvision 0.12
Both setups worked well on all the other applications, even in evolutions in smaller datasets...
Minimal Reproducible Example
No response
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: