-- device command returns OOM, runs fine without it #5988
Comments
|
I've noticed when it runs "just fine" it acutally uses both GPUs. This should maybe be reflected in the tutorial section in The section seems not up to date anymore |
|
@GGDRriedel 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
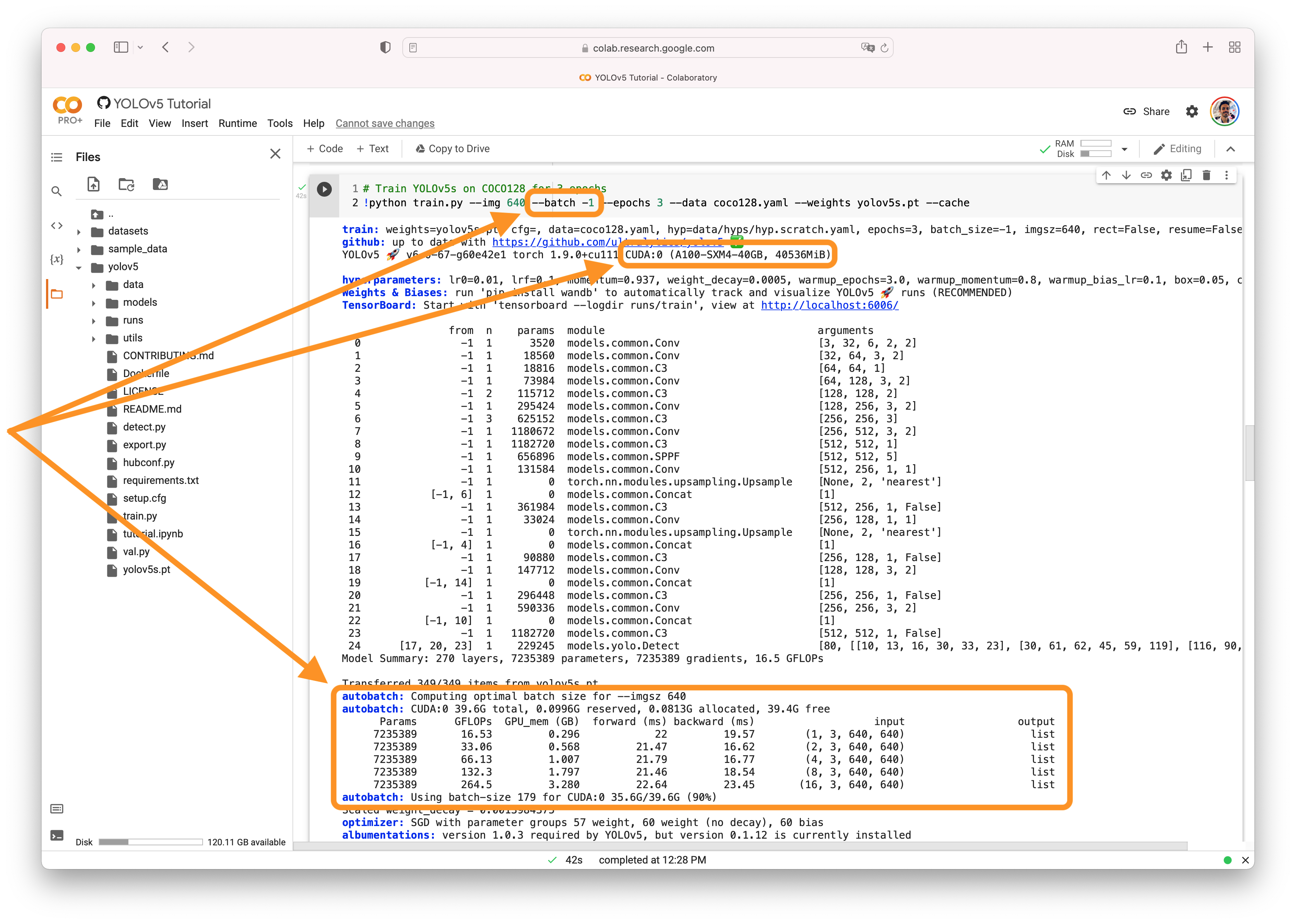
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


|
Hey Glenn, the issue isn't really the OOM itself, rather it's that the current wiki entry doesn't apply to the current library status anymore as the --evolve parameter seems to use multiple GPUs anyway |
|
@GGDRriedel device is established here, evolve status is not relevant to its definition. Line 511 in c1249a4 We are not able to reproduce any device issues. If you believe you have a reproducible issue in a common environment please raise a bug report with code to reproduce. We've created a few short guidelines below to help users provide what we need in order to get started investigating a possible problem. How to create a Minimal, Reproducible ExampleWhen asking a question, people will be better able to provide help if you provide code that they can easily understand and use to reproduce the problem. This is referred to by community members as creating a minimum reproducible example. Your code that reproduces the problem should be:
For Ultralytics to provide assistance your code should also be:
If you believe your problem meets all the above criteria, please close this issue and raise a new one using the 🐛 Bug Report template with a minimum reproducible example to help us better understand and diagnose your problem. Thank you! 😃 |
|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
Search before asking
YOLOv5 Component
Training, Evolution
Bug
RuntimeError: CUDA out of memory. Tried to allocate 126.00 MiB (GPU 0; 10.76 GiB total capacity; 9.45 GiB already allocated; 93.69 MiB free; 9.57 GiB reserved in total by PyTorch)
Environment
YOLOv5 v6.0-134-gc45f9f6 torch 1.8.1+cu102 CUDA:0 (GeForce RTX 2080 Ti, 11019MiB)
Minimal Reproducible Example
python train.py --epochs 10 --data gpr_highway.yaml --weights yolov5x6.pt --cache --evolve 10 --device 0
Gives the OOM error
python train.py --epochs 10 --data gpr_highway.yaml --weights yolov5x6.pt --cache --evolve 10
Runs just fine.
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: