请问这三个文件的区别?以及如何在程序中选择 #5653
Comments
|
PS:Because I am from China, it is more convenient and time-saving to ask questions by using Chinese. I don’t know if you can understand the meaning of my question. If it’s not easy for you to understand, I will continue to ask questions in English in the future. lol |
|
Your tutorial, I feel that the writing is more general and broad, some detailed questions about the meaning of the parameters/files and how to configure them, where should I look for answers? Are there related issues that you sorted out or summarized?Thanks |
|
@Wanghe1997 hyp files are specified during training here, i.e. Line 445 in c2523be
|
Thank u. |
|
@Wanghe1997 batch size should be set as large as possible to fully utilize your GPU. AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck and let us know if you have any other questions! |
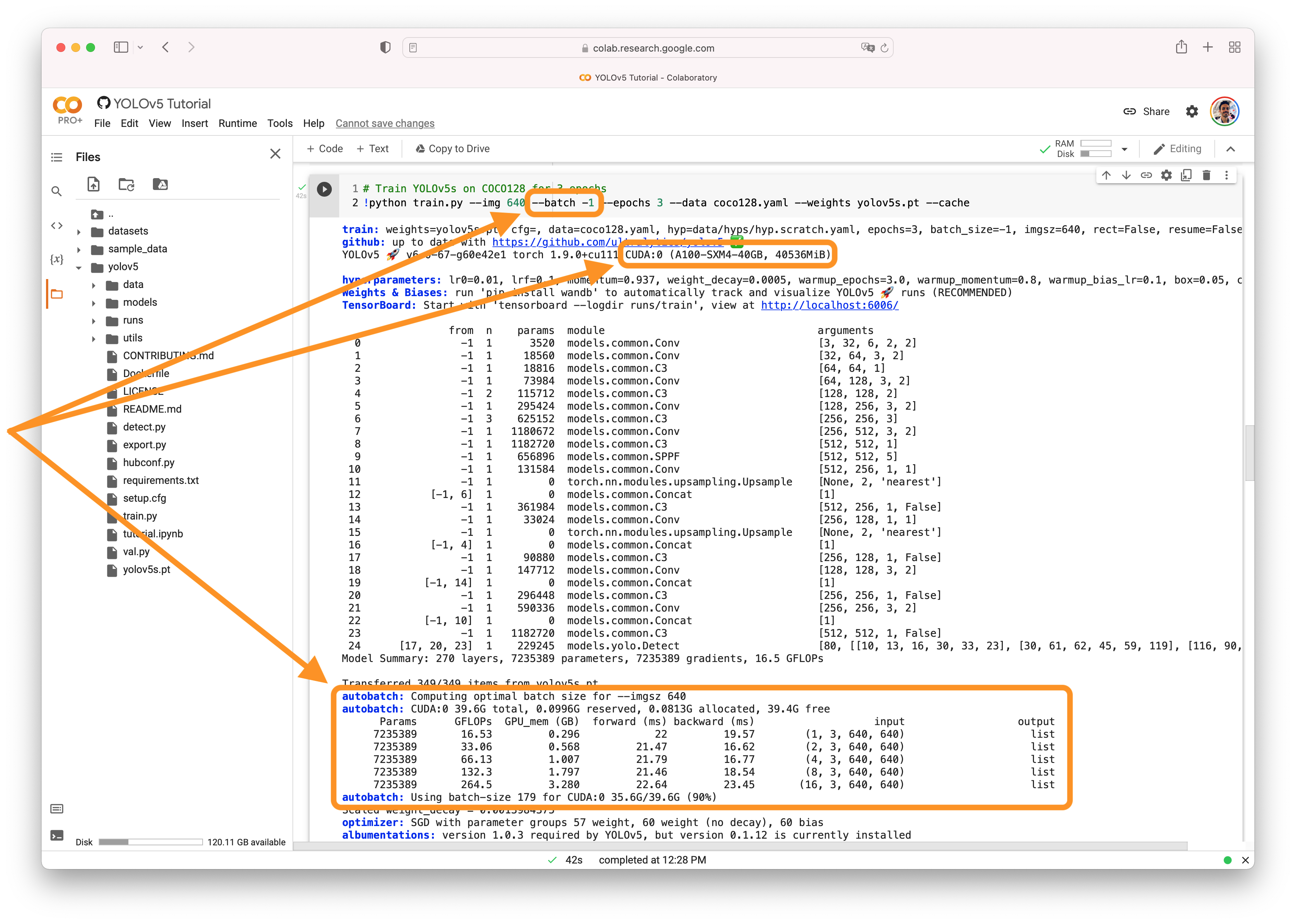
|
|
@Wanghe1997 yes |
So just set batch-size to 1 in train.py, will the program automatically execute AutoBatch? No need to do any configuration other than that? |
|
@Wanghe1997 no, the screenshot shows -1, not 1 |
ok,thanks |
I just tested AutoBatch with my dataset, and the best batch-size measured was 111. However, I used this value of 111 to train yolov5s, and it prompted an error: Unable to find a valid cuDNN algorithm to run convolution. I feel that the Autobatch test is not accurate! Although my graphics card is RTX3090, 24G memory, but theoretically it can't bear such a large batch-size |
|
@Wanghe1997 thank you for your feedback. As noted above: |

You're welcome. My system is windows10, it happens to be tested with RTX3090 single card. It seems that AutoBatch is not accurate yet. Or it can only be calculated for coco128, not for custom datasets? |
|
@Wanghe1997 the dataset does not matter. It's only been evaluated on Colab instances with K80, T4, P100, V100, A100, so no consumer cards yet. |
|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
Search before asking
Question
作者您好,请问hyp.scratch这4个yaml文件有什么区别?各自是在什么样的情况下使用?程序应该在哪里选择使用哪个hyp.scratch文件呢?另外,标注红色方框的这两个yaml文件又有什么区别?
Additional
像这些细节性的问题(比如this question,或者是一些超参数的含义等等诸如此类细节性的问题)我好像在你们的tutorial里找不到相关的解释,是不是有些关于程序或者参数设置的问题你们在一些issue里面给出了答案呢?有时候我有一些关于你们程序参数的设置、含义等疑问不知道从哪里能找到解答。你们是否在一些issue里面整理了一些常见的疑问,如果有的话可以分享吗?
The text was updated successfully, but these errors were encountered: