How to increase performance in CBIS-DDSM? #3147
Comments
|
👋 Hello @flashcp, thank you for your interest in 🚀 YOLOv5! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://www.ultralytics.com or email Glenn Jocher at glenn.jocher@ultralytics.com. RequirementsPython 3.8 or later with all requirements.txt dependencies installed, including $ pip install -r requirements.txtEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
@flashcp please consider submitting a PR to add the CBIS-DDSM dataset to our autodownload-capable list of datasets to help us reproduce your issue and to help future users get started more easily with this dataset. Example PR is #2968. Glancing at your results your model is too small, you are not starting from pretrained weights, you are not training enough epochs, and you may want to evolve your hyperparameters. A full guide on improving training results is below.
👋 Hello! Thanks for asking about improving training results. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
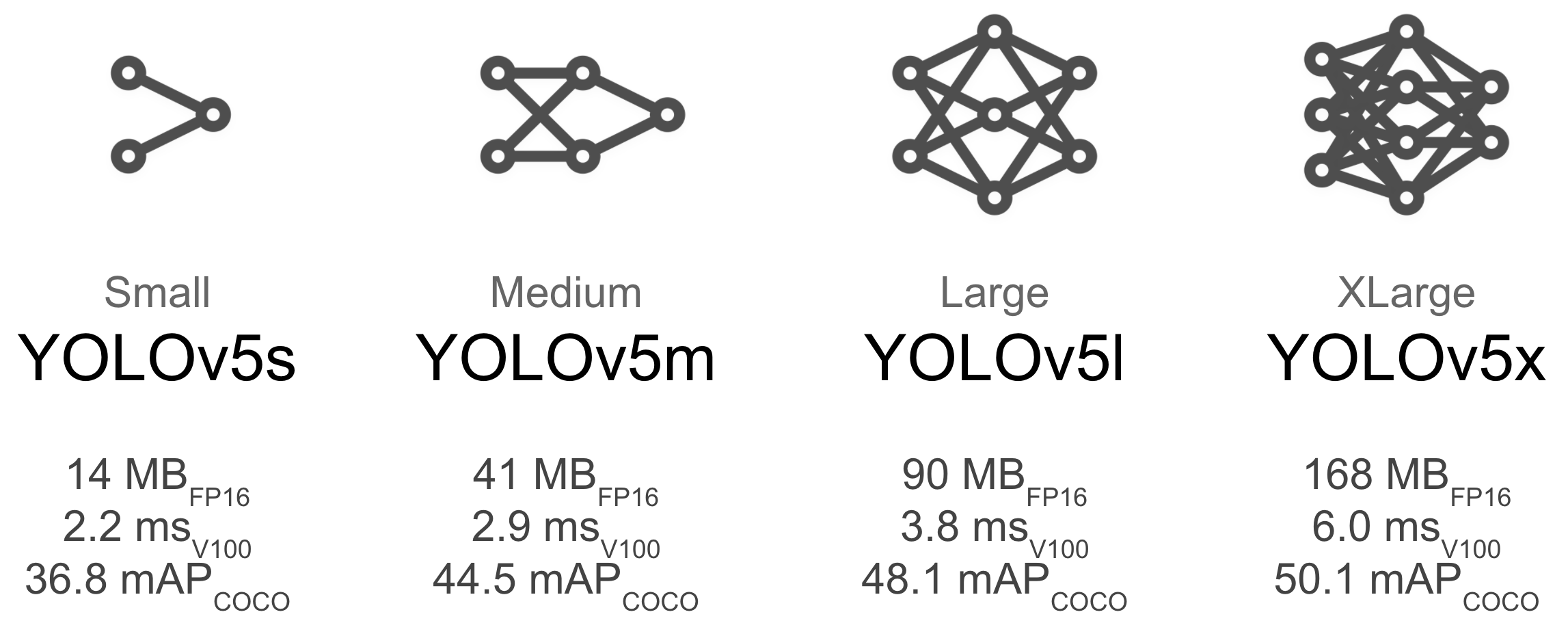
Model SelectionLarger models like YOLOv5x and YOLOv5x6 will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For mobile deployments we recommend YOLOv5s/m, for cloud deployments we recommend YOLOv5l/x. See our README table for a full comparison of all models.
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlTraining SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
Further ReadingIf you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: |

|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
|
hello,@glenn-jocher,@flashcpProblems like upstairs, I use the model is yolov5m6, excuse me ,how to solve |
|
thanks! |
|
@Chenzkun I'm sorry I don't understand your question, can you be more specific? |
I used the YOLOV5M6 to run the cbis-ddsm breast cancer data set, but after running 300,500 epochs, the results were not very good. The results were similar to the picture below. What should I do? |

|
@Chenzkun 👋 Hello! Thanks for asking about improving YOLOv5 🚀 training results. The CBIS-DDSM dataset may simply be very hard to train on, as personally I don't think I could spot the objects labelled myself. Nevertheless we have some best practices guidelines below. Most of the time good results can be obtained with no changes to the models or training settings, provided your dataset is sufficiently large and well labelled. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users first train with all default settings before considering any changes. This helps establish a performance baseline and spot areas for improvement. If you have questions about your training results we recommend you provide the maximum amount of information possible if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below. Dataset
Model SelectionLarger models like YOLOv5x and YOLOv5x6 will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For mobile deployments we recommend YOLOv5s/m, for cloud deployments we recommend YOLOv5l/x. See our README table for a full comparison of all models.
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yamlTraining SettingsBefore modifying anything, first train with default settings to establish a performance baseline. A full list of train.py settings can be found in the train.py argparser.
Further ReadingIf you'd like to know more a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: http://karpathy.github.io/2019/04/25/recipe/ Good luck 🍀 and let us know if you have any other questions! |

I used cbis-ddsm to check that each class has less than 1,500 images and fewer than 10,000 labels. How Do I meet the Yolov5 dataset requirements, thank you |
|
@Chenzkun oh the above are not hard requirements, they are best practices that you should attempt to reach to produce similar results to the COCO model results etc. |
|
hello,@glenn-jocher |

|

|
@Chenzkun batch size 2 is much smaller than recommended, this might be a reason for underperformance. I don't know what your question is regarding mosaics, these are simply 4 images mosaiced together with augmentations. |
❔Question
hello, @glenn-jocher
I would like to apply yolov5 to cbis-ddsm, but can`t get good results. How should I modify the hyper-parameter or make some adjustments on datasets?
thanks.
Additional context
datasets
The CBIS-DDSM (Curated Breast Imaging Subset of DDSM) is an updated and standardized version of the Digital Database for Screening Mammography (DDSM).
In my experiments, I just detected the masses , so there was only one category. the train datasets contains 1231 images and test datasets contains 361 images and set up the datasets structure as required by "Train Custom Data Tutorial"
TensorFlow already includes CBIS-DDSM. There are description, api and download link about CBIS-DDSM.
Modification
Because the datasets is small, I modify the warmup iterations from 1000 to 500.
nw = max(round(hyp['warmup_epochs'] * nb), 500) # number of warmup iterations, max(3 epochs, 1k iterations)In addition, the medical image unlike nature image, it not have hsv just a gray scale image. So I disable image HSV augmentation in LoadImagesAndLabels. Does this cause any errors or affect performance?
hyp and results
config:
--weights '' --hyp data/hyp.scratch.yaml --cfg yolov5s.yaml --data data/cbis_ddsm.yaml --batch-size 12 --epochs 100 --device 0 --img-size 1024hyp.yaml:








lr0: 0.01 lrf: 0.2 momentum: 0.937 weight_decay: 0.0005 warmup_epochs: 3.0 warmup_momentum: 0.8 warmup_bias_lr: 0.1 box: 0.05 cls: 0.5 cls_pw: 1.0 obj: 1.0 obj_pw: 1.0 iou_t: 0.2 anchor_t: 4.0 fl_gamma: 0.0 hsv_h: 0.015 hsv_s: 0.7 hsv_v: 0.4 degrees: 0.0 translate: 0.1 scale: 0.5 shear: 0.0 perspective: 0.0 flipud: 0.0 fliplr: 0.5 mosaic: 1.0 mixup: 0.0Thanks again for your work and look forward to you reply.
The text was updated successfully, but these errors were encountered: