Manually import TensorRT converted model and display model outputs #10397
Comments
|
👋 Hello @The-Magicians-Code, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
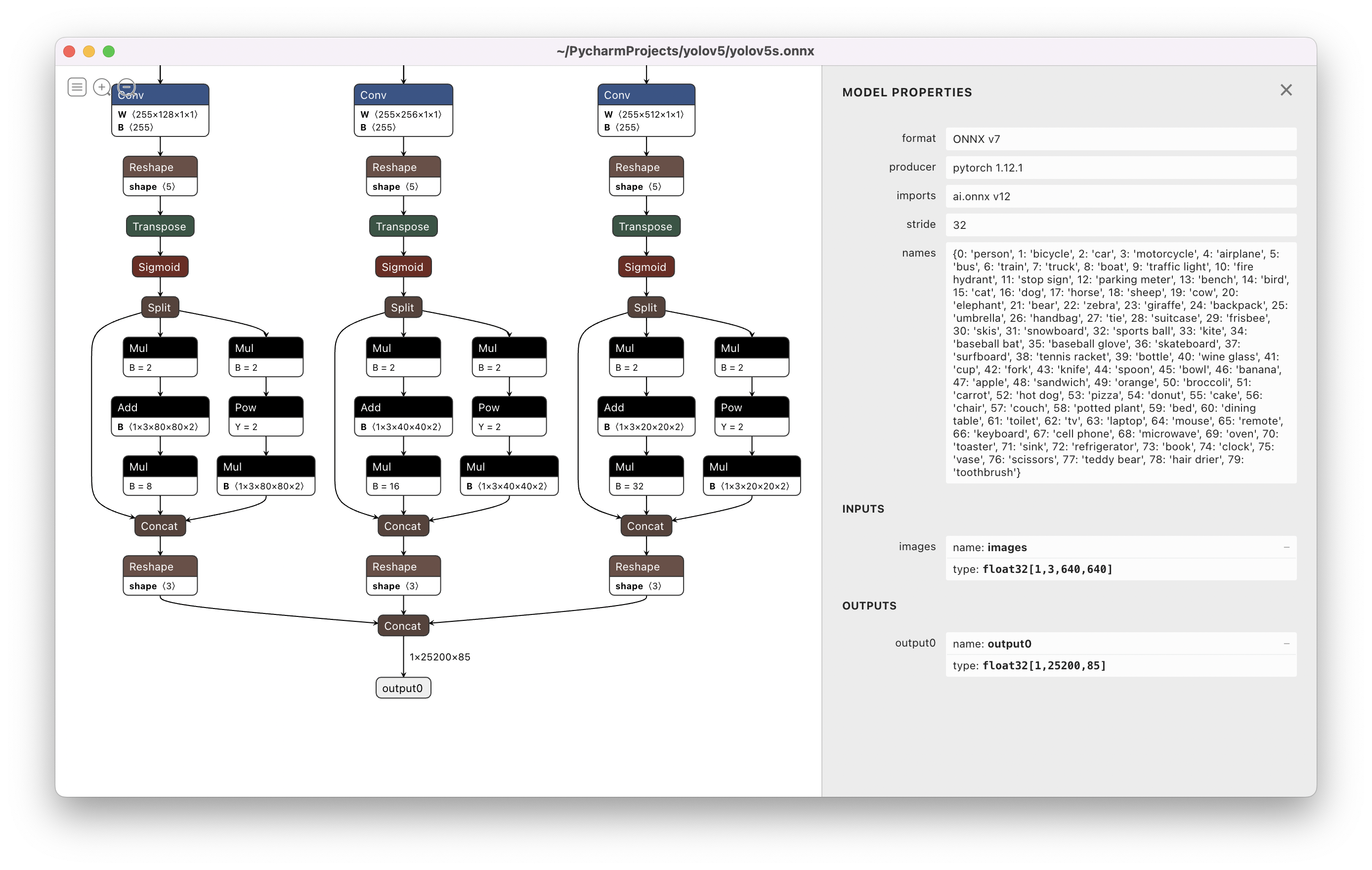
@The-Magicians-Code 👋 Hello! Thanks for asking about Export Formats. YOLOv5 🚀 offers export to almost all of the common export formats. See our TFLite, ONNX, CoreML, TensorRT Export Tutorial for full details. 85 is [xywh, objectness, classes 0-79] FormatsYOLOv5 inference is officially supported in 11 formats: 💡 ProTip: Export to ONNX or OpenVINO for up to 3x CPU speedup. See CPU Benchmarks.
BenchmarksBenchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook python benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0Colab Pro V100 GPUColab Pro CPUExport a Trained YOLOv5 ModelThis command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. python export.py --weights yolov5s.pt --include torchscript onnx💡 ProTip: Add Output: export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']
YOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 274MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
PyTorch: starting from yolov5s.pt with output shape (1, 25200, 85) (14.1 MB)
TorchScript: starting export with torch 1.12.1+cu113...
TorchScript: export success ✅ 1.7s, saved as yolov5s.torchscript (28.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success ✅ 2.3s, saved as yolov5s.onnx (28.0 MB)
Export complete (5.5s)
Results saved to /content/yolov5
Detect: python detect.py --weights yolov5s.onnx
Validate: python val.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Visualize: https://netron.app/The 3 exported models will be saved alongside the original PyTorch model:
Netron Viewer is recommended for visualizing exported models:
Exported Model Usage Examples
python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
python val.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS Only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddleUse PyTorch Hub with exported YOLOv5 models: import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt')
'yolov5s.torchscript ') # TorchScript
'yolov5s.onnx') # ONNX Runtime
'yolov5s_openvino_model') # OpenVINO
'yolov5s.engine') # TensorRT
'yolov5s.mlmodel') # CoreML (macOS Only)
'yolov5s_saved_model') # TensorFlow SavedModel
'yolov5s.pb') # TensorFlow GraphDef
'yolov5s.tflite') # TensorFlow Lite
'yolov5s_edgetpu.tflite') # TensorFlow Edge TPU
'yolov5s_paddle_model') # PaddlePaddle
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.OpenCV DNN inferenceOpenCV inference with ONNX models: python export.py --weights yolov5s.pt --include onnx
python detect.py --weights yolov5s.onnx --dnn # detect
python val.py --weights yolov5s.onnx --dnn # validateC++ InferenceYOLOv5 OpenCV DNN C++ inference on exported ONNX model examples:
YOLOv5 OpenVINO C++ inference examples:
Good luck 🍀 and let us know if you have any other questions! |
|
Thank you for the response. Current code: This is what the reference image looks like: |





|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
|
@The-Magicians-Code thanks for reaching out! It looks like you're on the right track! 😄 The outputs from the model indeed represent [xmin, ymin, xmax, ymax, confidence, object_id] as you mentioned. However, the coordinates must be properly scaled for the original image to draw correct bounding boxes. It seems the issue might be related to the scaling of the bounding box coordinates. Make sure to perform the proper scaling based on the original image dimensions and the input size used for the model inference. Also, before writing the outputs to the image, make sure to verify the coordinates by printing them and ensure they correspond to the correct regions in the image. You might also want to verify the result tensor before and after the non-maximum suppression to ensure that the bounding box coordinates and confidence values are correct. Feel free to share more details if you need further assistance! Good luck! 🚀 |
Search before asking
Question
I've managed to convert yolov5s6 640x640 model to .engine file from .onnx export, now that I've parsed it with tensorrt in python, I received the outputs shaped (1, 25500, 85), assuming the first parameter is the batch size, 85 is the number of classes, what does the middle dimension represent? How to obtain bounding box coordinates, confidence values and confidence classes from the output array by hand?
Additional
No response
The text was updated successfully, but these errors were encountered: