Yolo V5 Inferencing on CPU Machine #10268
Comments
|
👋 Hello @rahul1728jha, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
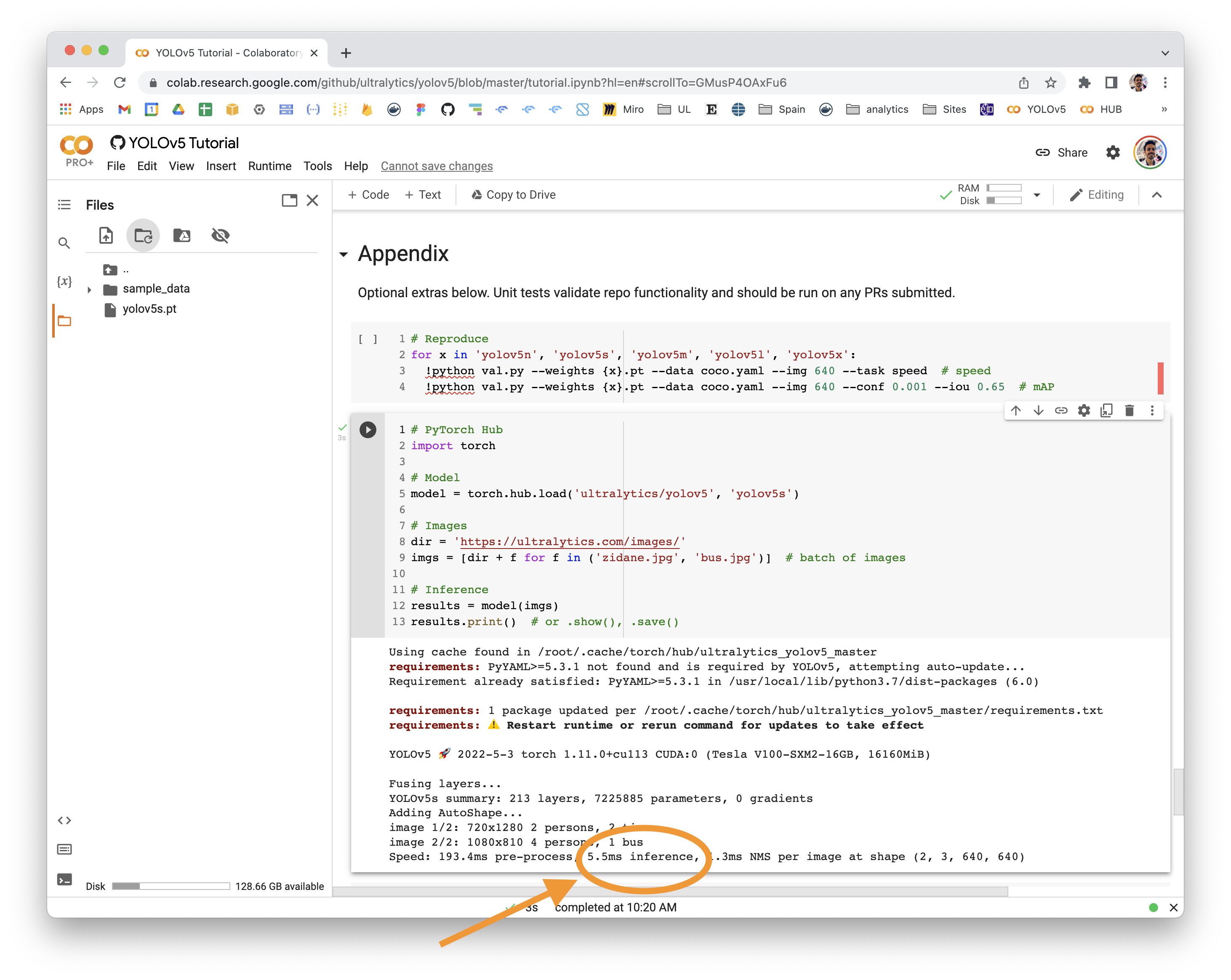
@rahul1728jha 👋 Hello! Thanks for asking about inference speed issues. I would recommend ONNX or OpenVINO for CPU inference. See https://docs.ultralytics.com/yolov5/tutorials/model_export to ONNX or OpenVINO for up to 3x CPU speedup (#6613) PyTorch Hub speeds will vary by hardware, software, model, inference settings, etc. Our default example in Colab with a V100 looks like this:
YOLOv5 🚀 can be run on CPU (i.e. detect.py inferencepython detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/
YOLOv5 PyTorch Hub inferenceimport torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Images
dir = 'https://ultralytics.com/images/'
imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images
# Inference
results = model(imgs)
results.print() # or .show(), .save()
# Speed: 631.5ms pre-process, 19.2ms inference, 1.6ms NMS per image at shape (2, 3, 640, 640)Increase SpeedsIf you would like to increase your inference speed some options are:
Good luck 🍀 and let us know if you have any other questions! |

|
I am actually surprised you even got 5fps out of my old laptop CPU lol. I dont think it is possible to run a YoloV5s model with 30fps on your CPU no. But you can perhaps squeeze out a few more FPS with the provided tools here: https://docs.ultralytics.com/yolov5/tutorials/model_export For reference, this is mine on a Ryzen 7 5800X running the benchmark: Standard (PyTorch) I get 59.95ms inference time but you can see ONNX is quite a bit faster. I believe it is 17 fps vs 24 fps. OpenVINO fails for me I believe because I have an AMD CPU but it should work on your CPU. Maybe it is faster too. The OPENCV DNN should be the fastest but I couldnt get it to run now because of wrong OpenCV version to compare. |
|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
|
Hi @glenn-jocher I understand that GPU is blazingly faster than CPU at inferencing on a batch. However, in real applications of inferencing on a live video, does the gpu still have the advantage? Since now we r processing frame by frame? For example, should I get a powerful intel NUC or a Jetson device for my robotic application if I want to do object detection and tracking in real time? |
|
@lucvt001 in real-time applications where inferencing is done on live video frames, GPUs still have a significant advantage over CPUs. While it's true that processing is done frame by frame, the parallel processing capabilities of GPUs allow for faster and more efficient object detection and tracking. If you're looking for real-time object detection and tracking in a robotic application, it is recommended to use a powerful GPU such as the one found in an Intel NUC or a Jetson device. These devices are specifically designed for high-performance computing tasks like computer vision and can provide the necessary processing power to achieve real-time performance. |
|
@glenn-jocher thank you for your advice! |
|
Hi @lucvt001 👋 When it comes to real-time video inferencing for object detection and tracking, GPUs still offer a significant advantage over CPUs. This is due to their parallel processing capabilities, which allow for faster and more efficient computation. If you're looking to perform real-time object detection and tracking in a robotic application, it is recommended to use a powerful GPU such as those found in Intel NUC or Jetson devices. These devices are specifically designed for high-performance computing tasks like computer vision and can provide the necessary processing power to achieve real-time performance. I hope this helps! Let me know if you have any more questions. |
|
thank you |
|
@shanmugamani1023 you're welcome! If you have any more questions in the future, feel free to ask. Good luck with your robotic application! 👍 |
Search before asking
Question
Hi All,
I am trying to inference using yolo v5. Below is the setup being used:
System Configuration :
Operating system : Windows
Processor Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz 1.80 GHz
Installed RAM 8.00 GB (7.86 GB usable)
System type 64-bit operating system, x64-based processor
Setup:
Input source : Real time RTSP stream from IP camera
Output : Annotated frames
Code:
sample code is like
Current metrics
Able to process 30 frames in 6 seconds i.e. getting a output @ 5FPS
Question :
My Constraint is I have to run it on a CPU.
Additional
No response
The text was updated successfully, but these errors were encountered: