About SCI
Student Code-In is a global program that helps students grow with Open Source Contribution. It is a 2 months long Open-Source initiative which provides you the best platform to improve your skills and abilities by contributing to vast variety of Open Source Projects Projects. In this, all the registered participants would get an exquisite opportunity to interact with the mentors and the Organizing Team.

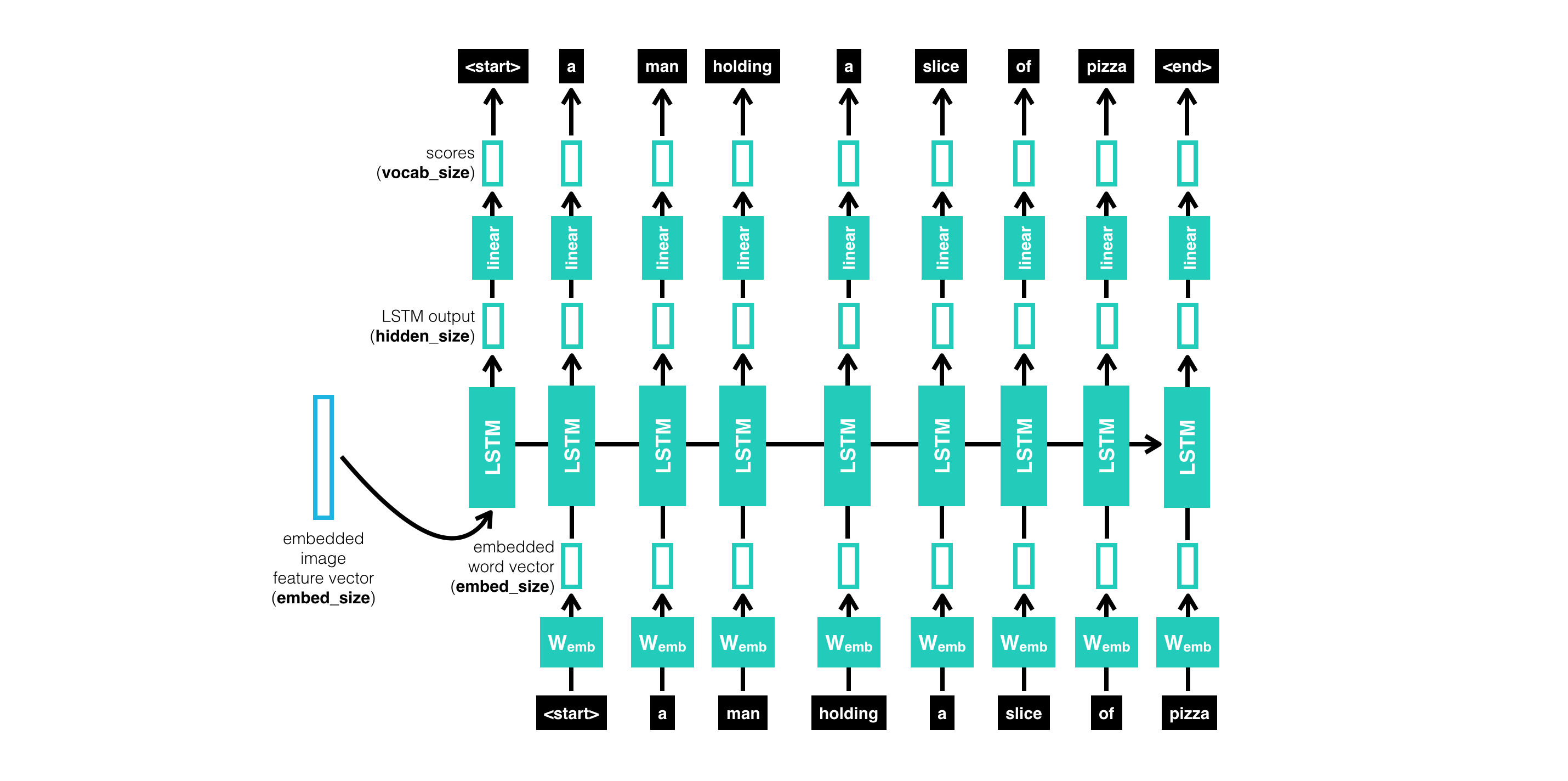
In this project, I design and train a CNN-RNN (Convolutional Neural Network - Recurrent Neural Network) model for automatically generating image captions. The network is trained on the Microsoft Common Objects in COntext (MS COCO) dataset. The image captioning model is displayed below.
 Image source
Image source
The COCO dataset is one of the largest, publicly available image datasets and it is meant to represent realistic scenes. What I mean by this is that COCO does not overly pre-process images, instead these images come in a variety of shapes with a variety of objects and environment/lighting conditions that closely represent what you might get if you compiled images from many different cameras around the world.
To explore the dataset, you can check out the dataset website
Click on the explore tab and you should see a search bar that looks like the image below. Try selecting an object by it's icon and clicking search!

You can select or deselect multiple objects by clicking on their corresponding icon. Below are some examples for what a sandwich search turned up! You can see that the initial results show colored overlays over objects like sandwiches and people and the objects come in different sizes and orientations.

COCO is a richly labeled dataset; it comes with class labels, labels for segments of an image, and a set of captions for a given image. To see the captions for an image, select the text icon that is above the image in a toolbar. Click on the other options and see what the result is.

When we actually train our model to generate captions, we'll be using these images as input and sampling one caption from a set of captions for each image to train on.



Here are some predictions from my model.







-
0_Datasets.ipynb: The purpose of this file is to initialize the COCO API and visualize the dataset. The Microsoft Common Objects in COntext (MS COCO) dataset can be accessed using the COCO API. The API has methods like "getAnnIds", "loadImgs" etc to access the images and annotations. In the 0_Datasets.ipynb file we load the instance annotations and captions annotations into memory using COCO API. Then we plot a random image from the dataset, along with its five corresponding captions. This file helps in understanding the working of the COCO API and the structure of the dataset.
-
1_Preliminaries.ipynb: The purpose of this file is to load and pre-process data from the COCO dataset and also design a CNN-RNN model for automatically generating image captions. We use the Data loader provided by pytorch to load the COCO dataset in batches. We initialize the data loader by using the "get_loader" method in data_loader.py. The "get_loader" function takes as input a number of arguments like "transform", "mode", "batch_size" etc. The getitem method in the CoCoDataset class is used to preprocess the image-caption pairs before incorporating them in a batch. For caption preprocessing we initialize an empty list and append an integer to mark the start of a caption. We use a special start and end word to mark the beginning and end of a caption. We append integers to the list that correspond to each of the tokens in the caption. Finally, we convert the list of integers to a PyTorch tensor and cast it to long type. To generate batches of training data, we begin by first sampling a caption length (where the probability that any length is drawn is proportional to the number of captions with that length in the dataset). Then, we retrieve a batch of size batch_size of image-caption pairs, where all captions have the sampled length. Once our batches are ready we import and instantiate the CNN encoder from the model.py file. The encoder uses the pre-trained ResNet-50 architecture (with the final fully-connected layer removed) to extract features from a batch of pre-processed images. The output is then flattened to a vector, before being passed through a Linear layer to transform the feature vector to have the same size as the word embedding. Then we import the RNN decoder from model.py. It outputs a PyTorch tensor with size [batch_size, captions.shape[1], vocab_size]. The output is designed such that outputs[i,j,k] contains the model's predicted score, indicating how likely the j-th token in the i-th caption in the batch is the k-th token in the vocabulary.
-
2_Training.ipynb: In this file, we train the encoder-decoder neural network for Image Generation.For this project, as aforementioned, the encoder is a CNN model whereas the decoder is a RNN model. The next few lines give you a brief introduction to whys and hows of the model.
-
Encoder: The CNN model we are using is the ResNet-152 network, which among those available from PyTorch was observed to perform the best on the ImageNet dataset and from Show, Attend and Tell: Neural Image Caption Generation with Visual Attention, section 5.2 Evaluation Procedures, one can conclude that it is always better to use recent architectures. When we work with very deep neural networks, after a certain point we find that the training error starts increasing with increasing layers. This issue is due to vanishing gradients. In order to avoid vanishing and exploding gradients in our model, we are using Residual Networks or ResNets. ResNets skip learning a few layers and instead learn an identity function, which allows it to remember the key characterstics of the data. This identity function is then passed to the next layer where the skip of the ResNets ends. This model is taken as it is with the only change being in the last fully connected layer. A batch normalization layer is added. The images undergo data augmentation before they are finally changed from 256 size to 224 in order to be feeded into the model.
-
Decoder: The decoder model used is the same one from Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. It is a LSTM model(a type of LSTM model) which produces a caption by generating one word at every timestep conditioned on a context vector, the previous hidden state and the previously generated words. This model is trained from scratch.
The optimizer used is Adam optimizer. We conclude with the training notebook here and go to the next phase.
-
-
3_Inference.ipynb: The purpose of this file is to make the predictions by loading
trained modelandvocabulary fileto get the desired result. This model generates good captions for the provided image but it can always be improved later by including hyper-parameters and using more accurate algorithms.
Make sure you read the Code of Conduct before making any contribution.
- Take a look at the Existing Issues or create your own Issues!
- Wait for the Issue to be assigned to you after which you can start working on it.
- Fork the Repo and create a Branch for any Issue that you are working upon.
- Create a Pull Request which will be promptly reviewed and suggestions would be added to improve it.
- Add Screenshots to help us know what this Script is all about.