
![]()



- What is Apache Pinot?
- Features
- When should I use Pinot?
- Building Pinot
- Deploying Pinot to Kubernetes
- Join the Community
- Documentation
- License
Apache Pinot is a real-time distributed OLAP datastore, built to deliver scalable real-time analytics with low latency. It can ingest from batch data sources (such as Hadoop HDFS, Amazon S3, Azure ADLS, Google Cloud Storage) as well as stream data sources (such as Apache Kafka).
Pinot was built by engineers at LinkedIn and Uber and is designed to scale up and out with no upper bound. Performance always remains constant based on the size of your cluster and an expected query per second (QPS) threshold.
For getting started guides, deployment recipes, tutorials, and more, please visit our project documentation at https://docs.pinot.apache.org.

Pinot was originally built at LinkedIn to power rich interactive real-time analytic applications such as Who Viewed Profile, Company Analytics, Talent Insights, and many more. UberEats Restaurant Manager is another example of a customer facing Analytics App. At LinkedIn, Pinot powers 50+ user-facing products, ingesting millions of events per second and serving 100k+ queries per second at millisecond latency.
-
Fast Queries: Filter and aggregate petabyte data sets with P90 latencies in the tens of milliseconds—fast enough to return live results interactively in the UI.
-
High Concurrency: With user-facing applications querying Pinot directly, it can serve hundreds of thousands of concurrent queries per second.
-
SQL Query Interface: The highly standard SQL query interface is accessible through a built-in query editor and a REST API.
-
Versatile Joins: Perform arbitrary fact/dimension and fact/fact joins on petabyte data sets.
-
Column-oriented: a column-oriented database with various compression schemes such as Run Length, Fixed Bit Length.
-
Pluggable indexing: pluggable indexing technologies including timestamp, inverted, StarTree, Bloom filter, range, text, JSON, and geospatial options.
-
Stream and batch ingest: Ingest from Apache Kafka, Apache Pulsar, and AWS Kinesis in real time. Batch ingest from Hadoop, Spark, AWS S3, and more. Combine batch and streaming sources into a single table for querying.
-
Upsert during real-time ingestion: update the data at-scale with consistency
-
Built-in Multitenancy: Manage and secure data in isolated logical namespaces for cloud-friendly resource management.
-
Built for Scale: Pinot is horizontally scalable and fault-tolerant, adaptable to workloads across the storage and throughput spectrum.
-
Cloud-native on Kubernetes: Helm chart provides a horizontally scalable and fault-tolerant clustered deployment that is easy to manage using Kubernetes.
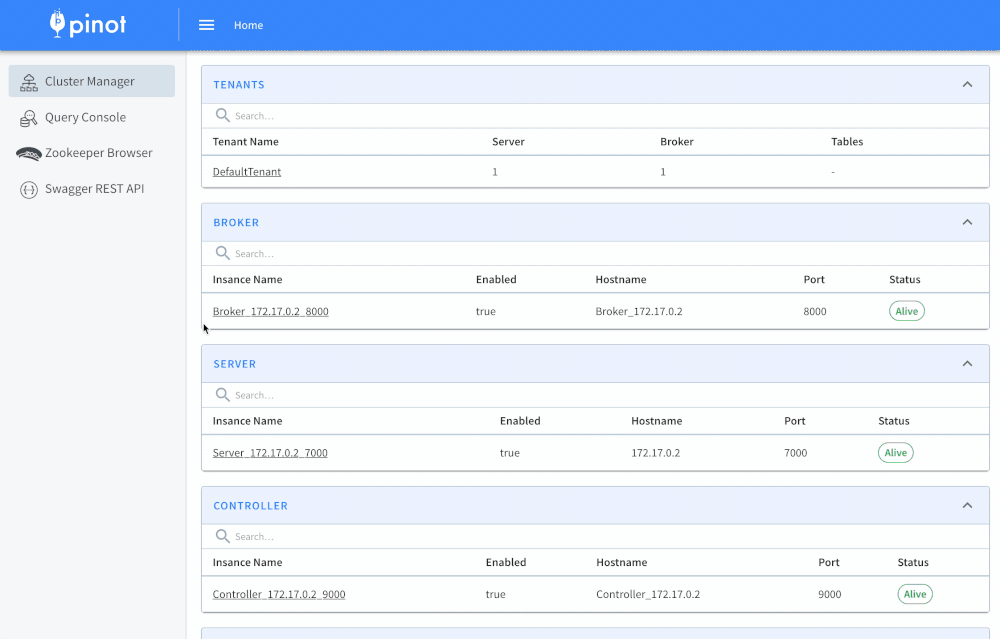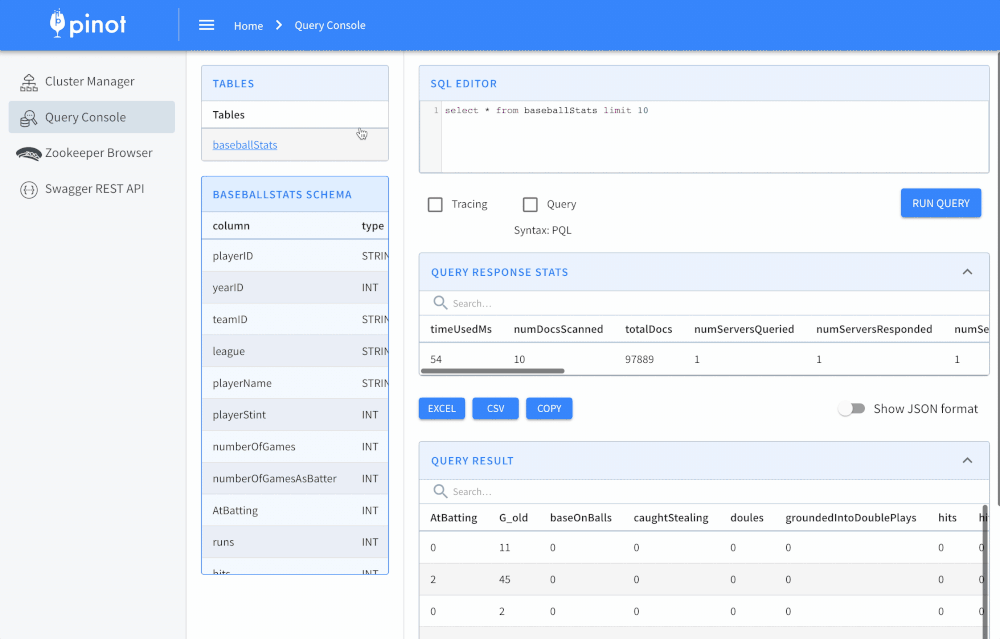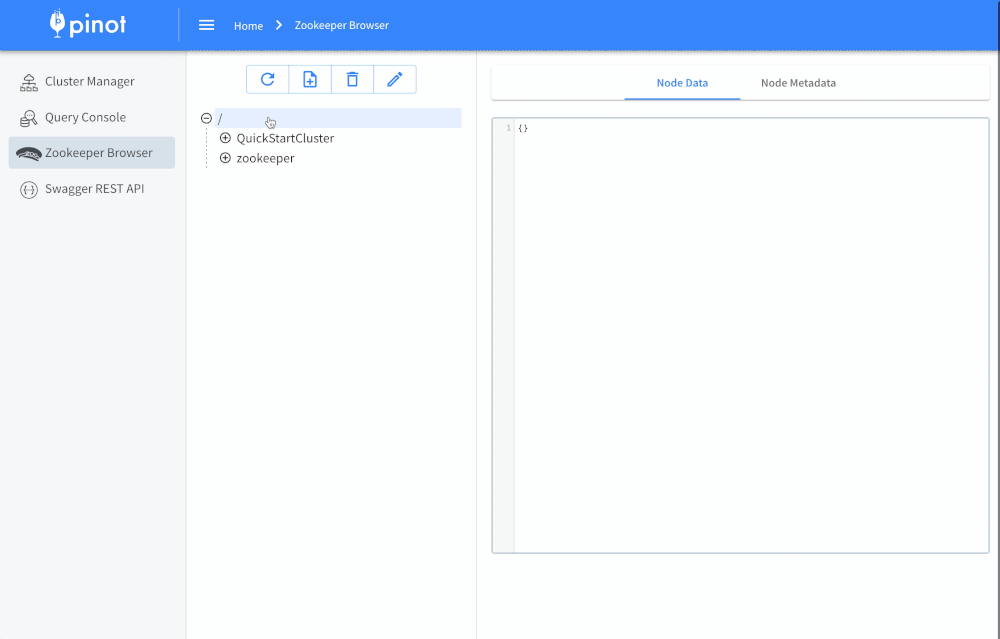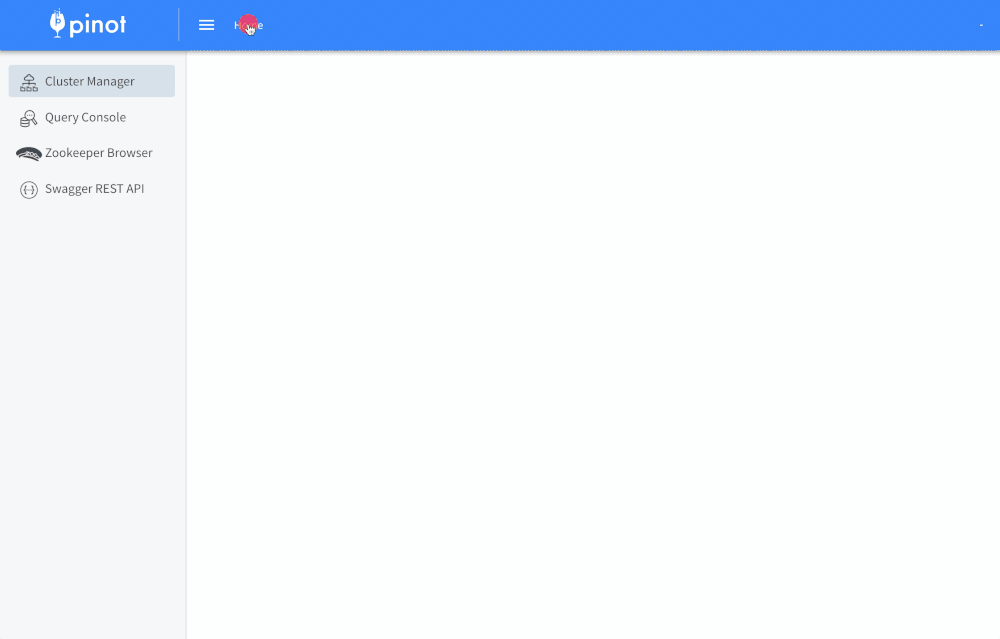
Pinot is designed to execute real-time OLAP queries with low latency on massive amounts of data and events. In addition to real-time stream ingestion, Pinot also supports batch use cases with the same low latency guarantees. It is suited in contexts where fast analytics, such as aggregations, are needed on immutable data, possibly, with real-time data ingestion. Pinot works very well for querying time series data with lots of dimensions and metrics.
Example query:
SELECT sum(clicks), sum(impressions) FROM AdAnalyticsTable
WHERE
((daysSinceEpoch >= 17849 AND daysSinceEpoch <= 17856)) AND
accountId IN (123456789)
GROUP BY
daysSinceEpoch TOP 100Want to contribute to apache/pinot? 👋🍷
Want to join the ranks of open source committers to Apache Pinot? Then check out the Contribution Guide for how you can get involved in the code.
If you have a bug or an idea for a new feature, browse the open issues to see what we’re already working on before opening a new one.
We also tagged some beginner issues new contributors can tackle.
# Clone a repo
$ git clone https://github.com/apache/pinot.git
$ cd pinot
# Build Pinot
# -Pbin-dist is required to build the binary distribution
# -Pbuild-shaded-jar is required to build the shaded jar, which is necessary for some features like spark connectors
$ mvn clean install -DskipTests -Pbin-dist -Pbuild-shaded-jar
# Run the Quick Demo
$ cd build/
$ bin/quick-start-batch.sh
For UI development setup refer this doc.
Normal Pinot builds are done using the mvn clean install command.
However this command can take a long time to run.
For faster builds it is recommended to use mvn verify -Ppinot-fastdev, which disables some plugins that are not actually needed for development.
More detailed instructions can be found at Quick Demo section in the documentation.
Please refer to Running Pinot on Kubernetes in our project documentation. Pinot also provides Kubernetes integrations with the interactive query engine, Trino Presto, and the data visualization tool, Apache Superset.
- Ask questions on Apache Pinot Slack
- Please join Apache Pinot mailing lists
dev-subscribe@pinot.apache.org (subscribe to pinot-dev mailing list)
dev@pinot.apache.org (posting to pinot-dev mailing list)
users-subscribe@pinot.apache.org (subscribe to pinot-user mailing list)
users@pinot.apache.org (posting to pinot-user mailing list) - Apache Pinot Meetup Group: https://www.meetup.com/apache-pinot/
Check out Pinot documentation for a complete description of Pinot's features.
Apache Pinot is under Apache License, Version 2.0