目标检测的历史由来已久,本文针对目标检测做一个完整的综述,以追求时代的步伐


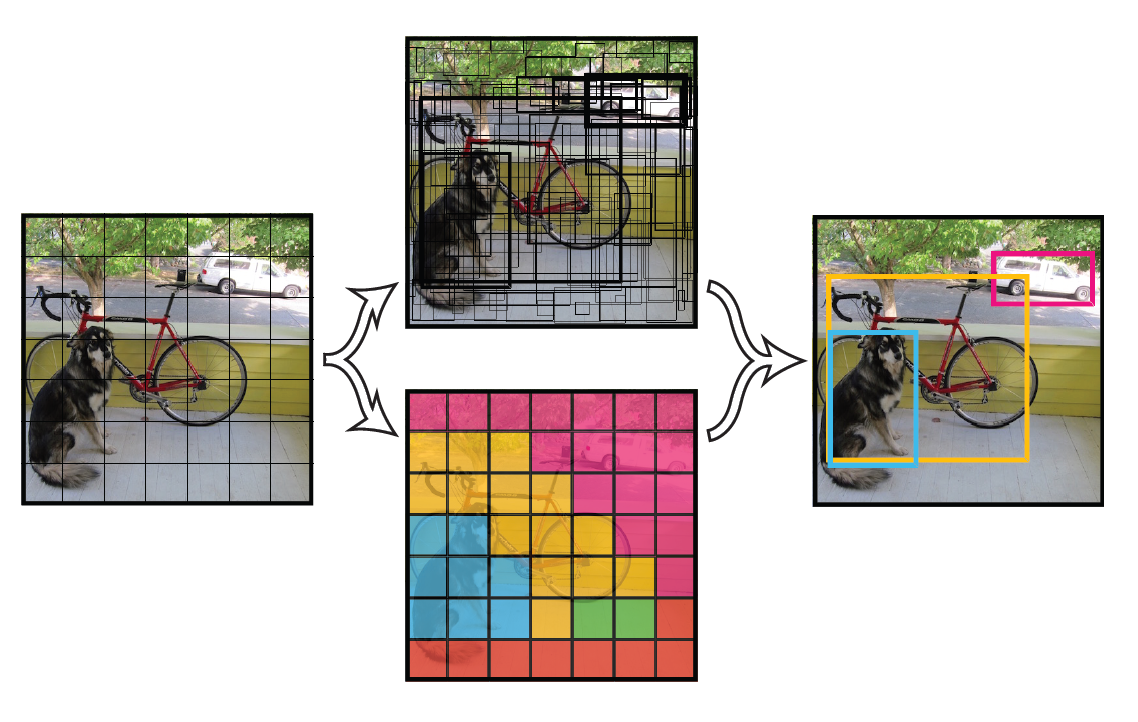
- 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:
- 其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。2个bounding box没有anchor。2个bounding box的IOU,哪个比较大(更接近对象实际的bounding box),就由哪个bounding box来负责预测该对象是否存在。
- 每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
- 举例说明: 在PASCAL VOC中,图像输入为448x448,取S=7,B=2,一共有20个类别(C=20)。则输出就是7x7x30的一个tensor。
Loss

k-means clusters
YOLOv2使用了anchor,但并非手动选取,而是通过聚类的方式学习得到。在训练集上使用k-means算法,距离衡量的方式为:目的使得大框小框的损失同等衡量。

聚类的结果发现,聚类中心的目标框和以前手动选取的不大一样,更多的是较高、较窄的目标框。聚类结果也有了更好的性能。
框回归
YOLOv2对框回归过程进行了改进,过去的框回归过程,由于对 参数没有约束,使得回归后的目标框可以位移到任意位置,这也导致YOLO的框回归中存在不稳定性。改进的做法为引入sigmid函数,对预测的
进行约束。YOLOv2在框回归时,为每一个目标框预测5个参数:
,调整的计算公式为:
![[公式]](/lengxia/paper_encode/blob/master/.%5C%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8Bimg%5Cequation.svg)
为格子的左上角坐标(行列值),
为anchor原始的宽高。
- 当
时,
,
刚好位于格子的中间。
用来控制宽高的缩放,
用来表达置信度信息。

通过使用sigmid函数,将偏移量的范围限制到 ,使得预测框的中心坐标总位于格子内部,减少了模型的不稳定性。另外,YOLOv2的分类置信度不再共享,每个anchor单独预测。即每一个anchor得到
的预测值。
多尺度训练
由于网络中只包含卷积层和池化层,YOLOv2为了增加网络的鲁棒性,在训练过程中动态调整网络的输入大小,同时相应地调整网络的结构以满足输入。因为网络下采样32倍,要求输入尺寸包含因数32。
网络结构
YOLOv2中使用了一种新的基础网络结构,基于Googlenet,名为Darknet-19。拥有19个卷积层和5个Max Pooling层,网络中使用了Batch Normalization来加快收敛。
开发了速度更快、精度更好的目标检测模型,仅需单张 1080Ti 或 2080Ti 即可训练 验证了 SOTA 的 Bag-of-Freebies(不增加推理成本的 trick) 和 Bag-of-Specials(增加推理成本的trick) 的有效性 修改了 SOTA 方法,使之更高效且更合适地单卡训练,包括 CBN、PAN、SAM 等
自适应anchor
https://zhuanlan.zhihu.com/p/161083602

- 作者观察到 PANet 的效果比 FPN ,NAS-FPN 要好,就是计算量更大;
- 作者从 PANet 出发,移除掉了只有一个输入的节点。这样做是假设只有一个输入的节点相对不太重要。这样把 PANet 简化,得到了上图 (e) Simplified PANet 的结果;
- 作者在相同 level 的输入和输出节点之间连了一条边,假设是能融合更多特征,有点 skip-connection 的意味,得到了上图 (f) 的结果;
- PANet 只有从底向上连,自顶向下两条路径,作者认为这种连法可以作为一个基础层,重复多次。这样就得到了下图的结果(看中间的 BiFPN Layer 部分)。如何确定重复几次呢,这是一个速度和精度之间的权衡,会在下面的Compound Scaling 部分介绍。

BiFPN 相对 FPN 能涨 4 个点,而且参数量反而是下降的。

step
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
advantage
- 它解决了深度卷积神经网络(CNNs)的输入必须要求固定图像尺寸(例如224*224)的限制。
- 在目标检测领域它提高了提取特征的效率,速度相比R-CNN提升24-102倍。


Fast R-CNN的主要创新点:
将最后一个卷积层的SSP Layer改为RoI Pooling Layer;
另外提出了多任务损失函数(Multi-task Loss),将边框回归直接加入到CNN网络中训练,同时包含了候选区域分类损失和位置回归损失。
ref:https://zhuanlan.zhihu.com/p/76574217


解决了“分类网络的位置不敏感性”与“检测网络的位置敏感性”之间的矛盾
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。

利用FPN构建Faster R-CNN检测器步骤
首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
然后,将处理过的图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
接着,如图5所示,构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作,最后);
接着,在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
接着,将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;
从RPN生成了候选ROI之后,分两路前进,一路为local FCN,PSRoI pooling提取局部信息;一路为Global FCN提取全局信息,最后融合在一起做判定。
focal loss
ref https://www.cnblogs.com/ManWingloeng/p/10713351.html
纵观目前主流的目标检测算法,无论SSD、Faster R-CNN、Retinanet这些的detector的设计其实都是三个步骤:
- 选择候选区域
- 提取特征
- 在muti-task loss下收敛
往往存在着三种层次的不平衡:
- sample level
- feature level
- objective level
这就对应了三个问题:
- 采样的候选区域是否具有代表性?
- 提取出的不同level的特征是怎么才能真正地充分利用?
- 目前设计的损失函数能不能引导目标检测器更好地收敛?

Balanced Feature Pyramid
feature level的不平衡表现在low/high level特征的利用上,如何利用不同分辨率的特征,分为了四步:rescaling,integrating,refining,strengthening。
-
rescaling & integrating :
假设Cl表示第l层特征,越高层分辨率越低,若有{C2,C3,C4,C5}的多层特征,C2分辨率最高,我们知道低层特诊分辨率高往往学习到的是细节特征,高层特征分辨率低学习到语义特征,把四层特征resize到中间层次的C4的size,然后后面再做简单的相加取平均操作: 就是这样简单的操作并没有引入什么计算就可以实现,最终在AP上也得到了验证是有效的。
-
refining & strengthening:
rescaling后取平均提取到的的特征还可以进一步地refine成更discriminative,作者这里用到了non-local模块,paper中使用了**Gaussian non-local attention [4]**增强integrate后的特征。

Balanced L1 Loss
可切换的空洞卷积(SAC)


DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
1、扩展可变形卷积,增强建模能力 2、提出了特征模拟方案指导网络培训:feature mimicking scheme
上面这段话是什么意思呢,通俗来讲就是,我们的可变性卷积的区域大于目标所在区域,所以这时候就会对非目标区域进行错误识别。所以自然能想到的解决方案就是加入权重项进行惩罚。(至于这个实现起来就比较简单了,直接初始化一个权重然后乘(input+offsets)就可以了)

可调节的RoIpooling也是类似的,公式如下:




Hybrid Task Cascade
Hybrid Task Cascade for Instance Segmentation
https://blog.csdn.net/u014119694/article/details/88428707
本文提出网络ExtremeNet,不再检测目标的左上角点与右下角点,而是检测目标的4个极值点(即最上点,最下点,最左点,最右点),框出目标,

backbone使用的是hourglass104网络,后面接的分别是5个4xCxHxW的heatmap以及4个对应的offsets,C代表类别,这里网络通过不同channel的heatmap预测不同的类别极值点。在预测的时候,网络分别预测了上下左右+中心,5个heatmap,并且对,上下左右的关键点同时预测了offset,因为在backbone网络下采样的过程中,会存在取整时候的精度损失,这里需要学回来,Center heatmap没有预测关键点,主要原因是center point只是用来校验使用,不需要特别高的准确性。
上下左右以及中心关键点在训练的时候采用的是focal loss,并且同样在gt周围设置了高斯的loss减少策略(这里借鉴于CornerNet,主要原因在于关键点存在一点的偏差实际上没有特别大的影响,所以gt附近的loss适当的减小一点。)


- 光学畸变: 图像的亮度、对比度、色相、饱和度和噪声
- 几何畸变: 随机缩放、剪切、翻转和旋转
- 模拟物体遮挡: 随机擦除(random erase)[100]和剪切(CutOut)[11],hide-and-seek [69] and grid mask [6]
- 多幅图像结合:
- MixUp [92]使用两个图像以不同的系数比相乘和重叠,然后使用这些重叠的比率调整标签。
- CutMix[91]是将裁剪后的图像覆盖到其他图像的矩形区域,并根据混合区域的大小调整标签。
- Mosaic[104] 混合4张训练图像的数据增强方法。
- GAN:
- style transfer GAN [15]
- Self-Adversarial Training (SAT)[104] 在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自己进行了对抗性的攻击,改变原始图像来制造图像上没有需要的对象的假象。在第二阶段,训练神经网络以正常的方式在修改后的图像上检测目标
- one-hot
- label smoothing[73]
-
样本不均衡
- focal loss[45]
- Generalized Focal Loss
- AP Loss
-
边界框回归
-
MSE
-
IoU loss [90] 考虑重叠面积
-
GIoU loss [65] 除了覆盖范围外,还包括了物体的形状和方向
![[公式]](.\目标检测img\equation (1).svg)
-
DIoU loss [99] 同时考虑了物体的中心距离
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。论文中
其中,
,
分别代表了预测框和真实框的中心点,且
代表的是计算两个中心点间的欧式距离。
代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
-
CIoU loss [99] 同时考虑了重叠区域、中心点距离和高宽比
论文考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:
其中
是权重函数,
而
用来度量长宽比的相似性,定义为
完整的 CIoU 损失函数定义:
最后,CIoU loss的梯度类似于DIoU loss,但还要考虑
的情况下,
的值通常很小,会导致梯度爆炸,因此在
实现时将替换成1。[4]
-
-
Balanced L1 Loss

- SPP [25]
- ASPP [5]
- RFB [47].
- SAC:可切换的空洞卷积
-
Squeeze-and-Excitation (SE) [29]
-
Spatial Attention Module (SAM) [85]
- Modified SAM[104]
-
Deformable Conv
-
DCN Deformable Convolutional Networks
-
-
ResNeSt
-
将低级物理特征集成为高级语义特征
- skip connection [51]
- hyper-column [22]
-
multi-scale(特征金字塔)
-
FPN
-
SFAM[98]
-
PAN
- Modified PAN[104]
-
ASFF[48]
-
BiFPN[77]

-
RFB
-


- ReLU[56]
- LReLU [54]
- PReLU [24]
- ReLU6 [28]
- (SELU) [35]
- Swish [59],
- hard-Swish [27]
- Mish [55]
-
greedy NMS [19]
-
soft NMS [1]
-
Soft-NMS的改进有两种形式,一种是线性加权的:

一种是高斯加权的:

-
Softer-NMS
提出使用 KL loss 来作为物体边框回归loss. 具体来说, 首先将bounding box的预测值和真实值分别建模成高斯分布和Dirac delta function(狄拉克函数). 然后, 训练模型, 以期降低来自于这两个分布的KL散度边框回归损失函数.


-
DIoU NMS [99]




- Batch Normalization (BN) [32]
- Cross-GPU Batch Normalization (CGBN or SyncBN) [93]
- Filter Response Normalization (FRN) [70],
- Cross-Iteration Batch Normalization (CBN) [89]
- CmBN[104]
- Residual connections
- Weighted residual connections
- Multi-input weighted residual connections(MiWRC)
- Cross stage partial connections (CSP)
- DropOut
- DropPath [36]
- Spatial DropOut [79]
- DropBlock
[1] Navaneeth Bodla, Bharat Singh, Rama Chellappa, andLarry S Davis. Soft-NMS–improving object detection withone line of code. In Proceedings of the IEEE InternationalConference on Computer Vision (ICCV), pages 5561–5569,2017. 4
[2] Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN:Delving into high quality object detection. In Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition (CVPR), pages 6154–6162, 2018. 12
[3] Jiale Cao, Yanwei Pang, Jungong Han, and Xuelong Li. Hi-erarchical shot detector. In Proceedings of the IEEE In-ternational Conference on Computer Vision (ICCV), pages9705–9714, 2019. 12
[4] Ping Chao, Chao-Yang Kao, Yu-Shan Ruan, Chien-HsiangHuang, and Youn-Long Lin. HarDNet: A low memory traf-fic network. Proceedings of the IEEE International Confer-ence on Computer Vision (ICCV), 2019. 13
[5] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,Kevin Murphy, and Alan L Yuille. DeepLab: Semantic im-age segmentation with deep convolutional nets, atrous con-volution, and fully connected CRFs. IEEE Transactionson Pattern Analysis and Machine Intelligence (TPAMI),40(4):834–848, 2017. 2, 4
[6] Pengguang Chen. GridMask data augmentation. arXivpreprint arXiv:2001.04086, 2020. 3
[7] Yukang Chen, Tong Yang, Xiangyu Zhang, Gaofeng Meng,Xinyu Xiao, and Jian Sun. DetNAS: Backbone search forobject detection. In Advances in Neural Information Pro-cessing Systems (NeurIPS), pages 6638–6648, 2019. 2
[8] Jiwoong Choi, Dayoung Chun, Hyun Kim, and Hyuk-JaeLee. Gaussian YOLOv3: An accurate and fast object de-tector using localization uncertainty for autonomous driv-ing. In Proceedings of the IEEE International Conferenceon Computer Vision (ICCV), pages 502–511, 2019. 7
[9] Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-FCN:Object detection via region-based fully convolutional net-works. In Advances in Neural Information Processing Sys-tems (NIPS), pages 379–387, 2016. 2
[10] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,and Li Fei-Fei. ImageNet: A large-scale hierarchical im-age database. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), pages248–255, 2009. 5
[11] Terrance DeVries and Graham W Taylor. Improved reg-ularization of convolutional neural networks with CutOut.arXiv preprint arXiv:1708.04552, 2017. 3
[12] Xianzhi Du, Tsung-Yi Lin, Pengchong Jin, Golnaz Ghiasi,Mingxing Tan, Yin Cui, Quoc V Le, and Xiaodan Song.SpineNet: Learning scale-permuted backbone for recog-nition and localization. arXiv preprint arXiv:1912.05027,2019. 2
[13] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qing-ming Huang, and Qi Tian. CenterNet: Keypoint triplets forobject detection. In Proceedings of the IEEE InternationalConference on Computer Vision (ICCV), pages 6569–6578,2019. 2, 12
[14] Cheng-Yang Fu, Mykhailo Shvets, and Alexander C Berg.RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free. arXiv preprintarXiv:1901.03353, 2019. 12
[15] Robert Geirhos, Patricia Rubisch, Claudio Michaelis,Matthias Bethge, Felix A Wichmann, and Wieland Brendel.ImageNet-trained cnns are biased towards texture; increas-ing shape bias improves accuracy and robustness. In Inter-national Conference on Learning Representations (ICLR),2019. 3
[16] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. DropBlock:A regularization method for convolutional networks. In Ad-vances in Neural Information Processing Systems (NIPS),pages 10727–10737, 2018. 3
[17] Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. NAS-FPN:Learning scalable feature pyramid architecture for objectdetection. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), pages 7036–7045, 2019. 2, 13
[18] Ross Girshick. Fast R-CNN. In Proceedings of the IEEE In-ternational Conference on Computer Vision (ICCV), pages1440–1448, 2015. 2
[19] Ross Girshick, Jeff Donahue, Trevor Darrell, and JitendraMalik. Rich feature hierarchies for accurate object de-tection and semantic segmentation. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recog-nition (CVPR), pages 580–587, 2014. 2, 4
[20] Jianyuan Guo, Kai Han, Yunhe Wang, Chao Zhang, Zhao-hui Yang, Han Wu, Xinghao Chen, and Chang Xu. Hit-Detector: Hierarchical trinity architecture search for objectdetection. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), 2020. 2
[21] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, ChunjingXu, and Chang Xu. GhostNet: More features from cheapoperations. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2020.5
[22] Bharath Hariharan, Pablo Arbeláez, Ross Girshick, andJitendra Malik. Hypercolumns for object segmentationand fine-grained localization. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), pages 447–456, 2015. 4
[23] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Gir-shick. Mask R-CNN. In Proceedings of the IEEE In-ternational Conference on Computer Vision (ICCV), pages2961–2969, 2017. 2
[24] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Delving deep into rectifiers: Surpassing human-level per-formance on ImageNet classification. In Proceedings ofthe IEEE International Conference on Computer Vision(ICCV), pages 1026–1034, 2015. 4
[25] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Spatial pyramid pooling in deep convolutional networks forvisual recognition. IEEE Transactions on Pattern Analy-sis and Machine Intelligence (TPAMI), 37(9):1904–1916,2015. 2, 4, 7
[26] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pat-tern Recognition (CVPR), pages 770–778, 2016. 2
[27] Andrew Howard, Mark Sandler, Grace Chu, Liang-ChiehChen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu,Ruoming Pang, Vijay Vasudevan, et al. Searching for Mo-bileNetV3. In Proceedings of the IEEE International Con-ference on Computer Vision (ICCV), 2019. 2, 4
[28] Andrew G Howard, Menglong Zhu, Bo Chen, DmitryKalenichenko, Weijun Wang, Tobias Weyand, Marco An-dreetto, and Hartwig Adam. MobileNets: Efficient con-volutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017. 2, 4
[29] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitationnetworks. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), pages 7132–7141, 2018. 4
[30] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kil-ian Q Weinberger. Densely connected convolutional net-works. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), pages 4700–4708, 2017. 2
[31] Forrest N Iandola, Song Han, Matthew W Moskewicz,Khalid Ashraf, William J Dally, and Kurt Keutzer.SqueezeNet: AlexNet-level accuracy with 50x fewer pa-rameters and¡ 0.5 MB model size.arXiv preprintarXiv:1602.07360, 2016. 2
[32] Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internal co-variate shift. arXiv preprint arXiv:1502.03167, 2015. 6
[33] Md Amirul Islam, Shujon Naha, Mrigank Rochan, NeilBruce, and Yang Wang. Label refinement network forcoarse-to-fine semantic segmentation.arXiv preprintarXiv:1703.00551, 2017. 3
[34] Seung-Wook Kim, Hyong-Keun Kook, Jee-Young Sun,Mun-Cheon Kang, and Sung-Jea Ko. Parallel feature pyra-mid network for object detection. In Proceedings of theEuropean Conference on Computer Vision (ECCV), pages234–250, 2018. 11
[35] Günter Klambauer, Thomas Unterthiner, Andreas Mayr,and Sepp Hochreiter. Self-normalizing neural networks.In Advances in Neural Information Processing Systems(NIPS), pages 971–980, 2017. 4
[36] Gustav Larsson, Michael Maire, and GregoryShakhnarovich.FractalNet: Ultra-deep neural net-works without residuals. arXiv preprint arXiv:1605.07648,2016. 6
[37] Hei Law and Jia Deng. CornerNet: Detecting objects aspaired keypoints. In Proceedings of the European Confer-ence on Computer Vision (ECCV), pages 734–750, 2018. 2,11
[38] Hei Law, Yun Teng, Olga Russakovsky, and Jia Deng.CornerNet-Lite: Efficient keypoint based object detection.arXiv preprint arXiv:1904.08900, 2019. 2
[39] Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. Be-yond bags of features: Spatial pyramid matching for recog-nizing natural scene categories. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), volume 2, pages 2169–2178. IEEE, 2006. 4
[40] Youngwan Lee and Jongyoul Park. CenterMask: Real-timeanchor-free instance segmentation. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recog-nition (CVPR), 2020. 12, 13
[41] Shuai Li, Lingxiao Yang, Jianqiang Huang, Xian-ShengHua, and Lei Zhang. Dynamic anchor feature selection forsingle-shot object detection. In Proceedings of the IEEE In-ternational Conference on Computer Vision (ICCV), pages6609–6618, 2019. 12
[42] Yanghao Li, Yuntao Chen, Naiyan Wang, and ZhaoxiangZhang. Scale-aware trident networks for object detection.In Proceedings of the IEEE International Conference onComputer Vision (ICCV), pages 6054–6063, 2019. 12
[43] Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, Yang-dong Deng, and Jian Sun. DetNet: Design backbone forobject detection. In Proceedings of the European Confer-ence on Computer Vision (ECCV), pages 334–350, 2018.2
[44] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He,Bharath Hariharan, and Serge Belongie. Feature pyramidnetworks for object detection. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), pages 2117–2125, 2017. 2
[45] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He,and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE International Conference on Com-puter Vision (ICCV), pages 2980–2988, 2017. 2, 3, 11, 13
[46] Tsung-Yi Lin, Michael Maire, Serge Belongie, JamesHays, Pietro Perona, Deva Ramanan, Piotr Dollár, andC Lawrence Zitnick. Microsoft COCO: Common objectsin context. In Proceedings of the European Conference onComputer Vision (ECCV), pages 740–755, 2014. 5
[47] Songtao Liu, Di Huang, et al. Receptive field block net foraccurate and fast object detection. In Proceedings of theEuropean Conference on Computer Vision (ECCV), pages385–400, 2018. 2, 4, 11
[48] Songtao Liu, Di Huang, and Yunhong Wang. Learning spa-tial fusion for single-shot object detection. arXiv preprintarXiv:1911.09516, 2019. 2, 4, 13
[49] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia.Path aggregation network for instance segmentation. InProceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), pages 8759–8768, 2018.1, 2, 7
[50] Wei Liu, Dragomir Anguelov, Dumitru Erhan, ChristianSzegedy, Scott Reed, Cheng-Yang Fu, and Alexander CBerg. SSD: Single shot multibox detector. In Proceedingsof the European Conference on Computer Vision (ECCV),pages 21–37, 2016. 2, 11
[51] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fullyconvolutional networks for semantic segmentation. In Pro-ceedings of the IEEE Conference on Computer Vision andPattern Recognition (CVPR), pages 3431–3440, 2015. 4
[52] Ilya Loshchilov and Frank Hutter.SGDR: Stochas-tic gradient descent with warm restarts. arXiv preprintarXiv:1608.03983, 2016. 7
[53] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and JianSun. ShuffleNetV2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Con-ference on Computer Vision (ECCV), pages 116–131, 2018.2
[54] Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rec-tifier nonlinearities improve neural network acoustic mod-els. In Proceedings of International Conference on Ma-chine Learning (ICML), volume 30, page 3, 2013. 4
[55] Diganta Misra.Mish: A self regularized non-monotonic neural activation function.arXiv preprintarXiv:1908.08681, 2019. 4
[56] Vinod Nair and Geoffrey E Hinton. Rectified linear unitsimprove restricted boltzmann machines. In Proceedingsof International Conference on Machine Learning (ICML),pages 807–814, 2010. 4
[57] Jing Nie, Rao Muhammad Anwer, Hisham Cholakkal, Fa-had Shahbaz Khan, Yanwei Pang, and Ling Shao. Enrichedfeature guided refinement network for object detection. InProceedings of the IEEE International Conference on Com-puter Vision (ICCV), pages 9537–9546, 2019. 12
[58] Jiangmiao Pang, Kai Chen, Jianping Shi, Huajun Feng,Wanli Ouyang, and Dahua Lin. Libra R-CNN: Towards bal-anced learning for object detection. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recog-nition (CVPR), pages 821–830, 2019. 2, 12
[59] Prajit Ramachandran, Barret Zoph, and Quoc V Le.Searching for activation functions.arXiv preprintarXiv:1710.05941, 2017. 4
[60] Abdullah Rashwan, Agastya Kalra, and Pascal Poupart.Matrix Nets: A new deep architecture for object detection.In Proceedings of the IEEE International Conference onComputer Vision Workshop (ICCV Workshop), pages 0–0,2019. 2
[61] Joseph Redmon, Santosh Divvala, Ross Girshick, and AliFarhadi. You only look once: Unified, real-time object de-tection. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), pages 779–788, 2016. 2
[62] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster,stronger. In Proceedings of the IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), pages 7263–7271, 2017. 2
[63] Joseph Redmon and Ali Farhadi. YOLOv3: An incrementalimprovement. arXiv preprint arXiv:1804.02767, 2018. 2,4, 7, 11
[64] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.Faster R-CNN: Towards real-time object detection with re-gion proposal networks. In Advances in Neural InformationProcessing Systems (NIPS), pages 91–99, 2015. 2
[65] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, AmirSadeghian, Ian Reid, and Silvio Savarese. Generalized in-tersection over union: A metric and a loss for boundingbox regression. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), pages658–666, 2019. 3
[66] Mark Sandler, Andrew Howard, Menglong Zhu, AndreyZhmoginov, and Liang-Chieh Chen. MobileNetV2: In-verted residuals and linear bottlenecks. In Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition (CVPR), pages 4510–4520, 2018. 2
[67] Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick.Training region-based object detectors with online hard ex-ample mining. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), pages761–769, 2016. 3
[68] Karen Simonyan and Andrew Zisserman. Very deep convo-lutional networks for large-scale image recognition. arXivpreprint arXiv:1409.1556, 2014. 2
[69] Krishna Kumar Singh, Hao Yu, Aron Sarmasi, GautamPradeep, and Yong Jae Lee. Hide-and-Seek: A data aug-mentation technique for weakly-supervised localization andbeyond. arXiv preprint arXiv:1811.02545, 2018. 3
[70] Saurabh Singh and Shankar Krishnan. Filter responsenormalization layer: Eliminating batch dependence inthe training of deep neural networks.arXiv preprintarXiv:1911.09737, 2019. 6
[71] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, IlyaSutskever, and Ruslan Salakhutdinov. DropOut: A simpleway to prevent neural networks from overfitting. The jour-nal of machine learning research, 15(1):1929–1958, 2014.3
[72] K-K Sung and Tomaso Poggio. Example-based learningfor view-based human face detection. IEEE Transactionson Pattern Analysis and Machine Intelligence (TPAMI),20(1):39–51, 1998. 3
[73] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, JonShlens, and Zbigniew Wojna. Rethinking the inception ar-chitecture for computer vision. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), pages 2818–2826, 2016. 3
[74] Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan,Mark Sandler, Andrew Howard, and Quoc V Le. MNAS-net: Platform-aware neural architecture search for mobile.In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), pages 2820–2828, 2019.2
[75] Mingxing Tan and Quoc V Le. EfficientNet: Rethinkingmodel scaling for convolutional neural networks. In Pro-ceedings of International Conference on Machine Learning(ICML), 2019. 2
[76] Mingxing Tan and Quoc V Le. MixNet: Mixed depthwiseconvolutional kernels. In Proceedings of the British Ma-chine Vision Conference (BMVC), 2019. 5
[77] Mingxing Tan, Ruoming Pang, and Quoc V Le. Efficient-Det: Scalable and efficient object detection. In Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2020. 2, 4, 13
[78] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS:Fully convolutional one-stage object detection. In Proceed-ings of the IEEE International Conference on Computer Vi-sion (ICCV), pages 9627–9636, 2019. 2
[79] Jonathan Tompson, Ross Goroshin, Arjun Jain, Yann Le-Cun, and Christoph Bregler. Efficient object localizationusing convolutional networks. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), pages 648–656, 2015. 616
[80] Li Wan, Matthew Zeiler, Sixin Zhang, Yann Le Cun, andRob Fergus. Regularization of neural networks using Drop-Connect. In Proceedings of International Conference onMachine Learning (ICML), pages 1058–1066, 2013. 3
[81] Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu,Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. CSPNet:A new backbone that can enhance learning capability ofcnn. Proceedings of the IEEE Conference on Computer Vi-sion and Pattern Recognition Workshop (CVPR Workshop),2020. 2, 7
[82] Jiaqi Wang, Kai Chen, Shuo Yang, Chen Change Loy, andDahua Lin. Region proposal by guided anchoring. In Pro-ceedings of the IEEE Conference on Computer Vision andPattern Recognition (CVPR), pages 2965–2974, 2019. 12
[83] Shaoru Wang, Yongchao Gong, Junliang Xing, LichaoHuang, Chang Huang, and Weiming Hu. RDSNet: Anew deep architecture for reciprocal object detection andinstance segmentation. arXiv preprint arXiv:1912.05070,2019. 13
[84] Tiancai Wang, Rao Muhammad Anwer, Hisham Cholakkal,Fahad Shahbaz Khan, Yanwei Pang, and Ling Shao. Learn-ing rich features at high-speed for single-shot object detec-tion. In Proceedings of the IEEE International Conferenceon Computer Vision (ICCV), pages 1971–1980, 2019. 11
[85] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and InSo Kweon. CBAM: Convolutional block attention module.In Proceedings of the European Conference on ComputerVision (ECCV), pages 3–19, 2018. 1, 2, 4
[86] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, andKaiming He. Aggregated residual transformations for deepneural networks. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), pages1492–1500, 2017. 2
[87] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and StephenLin. RepPoints: Point set representation for object detec-tion. In Proceedings of the IEEE International Conferenceon Computer Vision (ICCV), pages 9657–9666, 2019. 2, 12
[88] Lewei Yao, Hang Xu, Wei Zhang, Xiaodan Liang, andZhenguo Li. SM-NAS: Structural-to-modular neural archi-tecture search for object detection. In Proceedings of theAAAI Conference on Artificial Intelligence (AAAI), 2020.13
[89] Zhuliang Yao, Yue Cao, Shuxin Zheng, Gao Huang, andStephen Lin. Cross-iteration batch normalization. arXivpreprint arXiv:2002.05712, 2020. 1, 6
[90] Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao,and Thomas Huang. UnitBox: An advanced object detec-tion network. In Proceedings of the 24th ACM internationalconference on Multimedia, pages 516–520, 2016. 3
[91] Sangdoo Yun, Dongyoon Han, Seong Joon Oh, SanghyukChun, Junsuk Choe, and Youngjoon Yoo. CutMix: Regu-larization strategy to train strong classifiers with localizablefeatures. In Proceedings of the IEEE International Confer-ence on Computer Vision (ICCV), pages 6023–6032, 2019.3
[92] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, andDavid Lopez-Paz. MixUp: Beyond empirical risk mini-mization. arXiv preprint arXiv:1710.09412, 2017. 3
[93] Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang,Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Con-text encoding for semantic segmentation. In Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition (CVPR), pages 7151–7160, 2018. 6
[94] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, andStan Z Li. Bridging the gap between anchor-based andanchor-free detection via adaptive training sample selec-tion. In Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition (CVPR), 2020. 13
[95] Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, andStan Z Li. Single-shot refinement neural network for ob-ject detection. In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition (CVPR), pages4203–4212, 2018. 11
[96] Xiaosong Zhang, Fang Wan, Chang Liu, Rongrong Ji, andQixiang Ye. FreeAnchor: Learning to match anchors forvisual object detection. In Advances in Neural InformationProcessing Systems (NeurIPS), 2019.
[97] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun.ShuffleNet: An extremely efficient convolutional neuralnetwork for mobile devices. In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition(CVPR), pages 6848–6856, 2018. 2
[98] Qijie Zhao, Tao Sheng, Yongtao Wang, Zhi Tang, YingChen, Ling Cai, and Haibin Ling. M2det: A single-shotobject detector based on multi-level feature pyramid net-work. In Proceedings of the AAAI Conference on ArtificialIntelligence (AAAI), volume 33, pages 9259–9266, 2019. 2,4, 11
[99] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, RongguangYe, and Dongwei Ren. Distance-IoU Loss: Faster and bet-ter learning for bounding box regression. In Proceedingsof the AAAI Conference on Artificial Intelligence (AAAI),2020. 3, 4
[100] Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li,and Yi Yang. Random erasing data augmentation. arXivpreprint arXiv:1708.04896, 2017. 3
[101] Chenchen Zhu, Fangyi Chen, Zhiqiang Shen, and Mar-ios Savvides. Soft anchor-point object detection. arXivpreprint arXiv:1911.12448, 2019. 12
[102] Chenchen Zhu, Yihui He, and Marios Savvides. Feature se-lective anchor-free module for single-shot object detection.In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), pages 840–849, 2019. 11
[103] YOLOv4: Optimal Speed and Accuracy of Object Detection