IPEX-LLM is a low-bit LLM library on Intel XPU (Xeon/Core/Flex/Arc/PVC), featuring broadest model support, lowest latency and smallest memory footprint. It is released under Apache 2.0 License.
You can use IPEX-LLM to run any pytorch model (e.g. HuggingFace transformers models). It automatically optimizes and accelerates LLMs using low-bit optimizations, modern hardware accelerations and latest software optimizations.
Using IPEX-LLM is easy. With just 1-line of code change, you can immediately observe significant speedup 1 .
from ipex_llm import optimize_model
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained(model_path,...)
# apply ipex-llm low-bit optimization, by default uses INT4
model = optimize_model(model)
...IPEX-LLM provides a variety of low-bit optimizations (e.g., INT3/NF3/INT4/NF4/INT5/INT8), and allows you to run LLMs on low-cost PCs (CPU-only), on PCs with GPU, or on cloud.
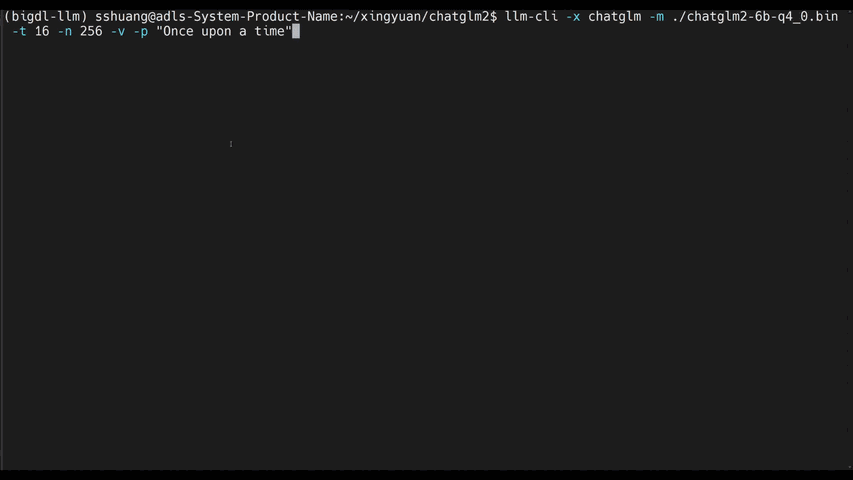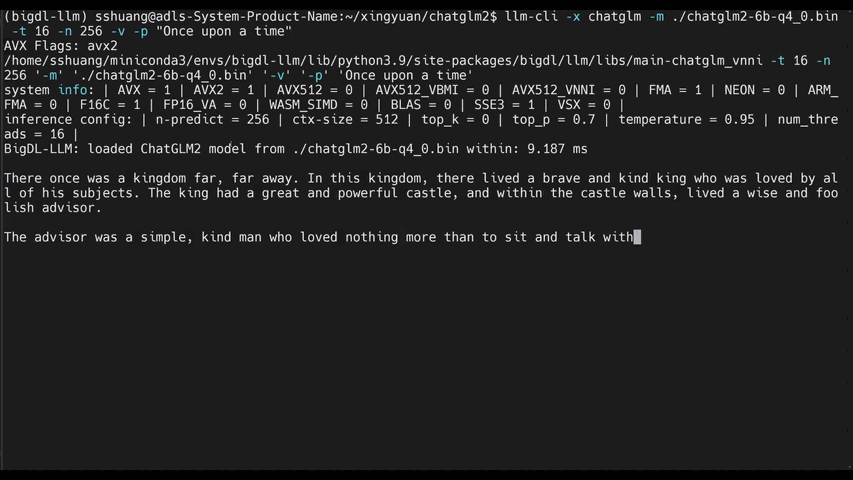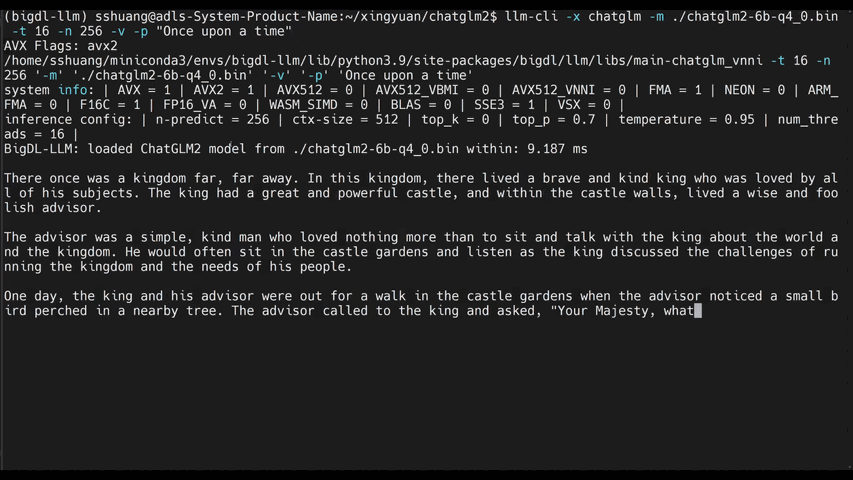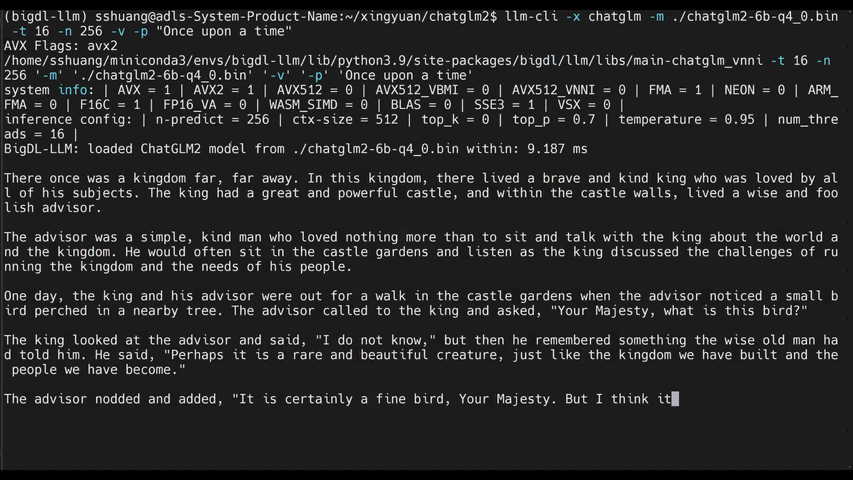
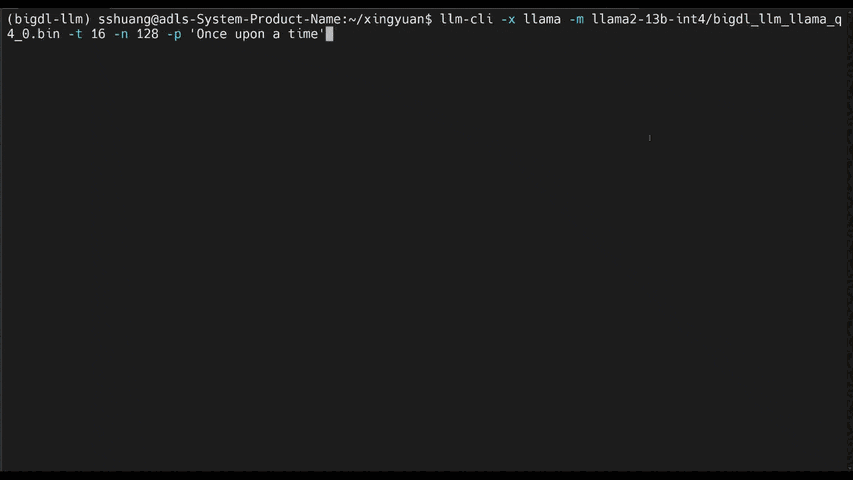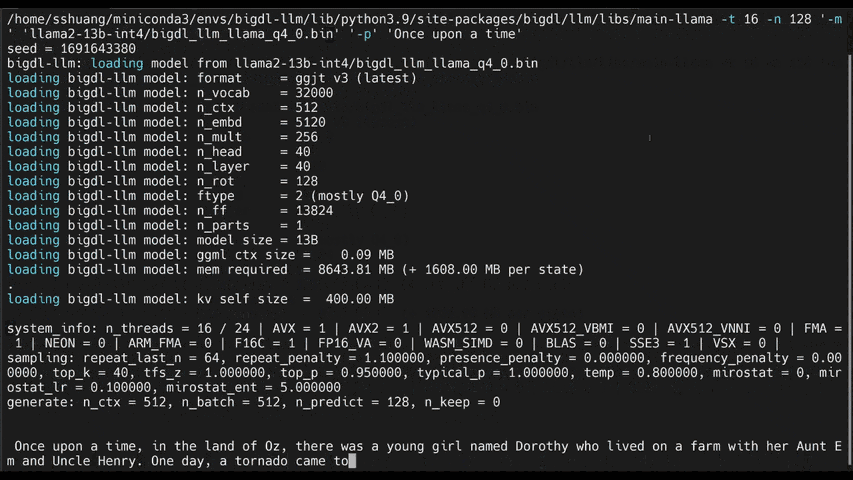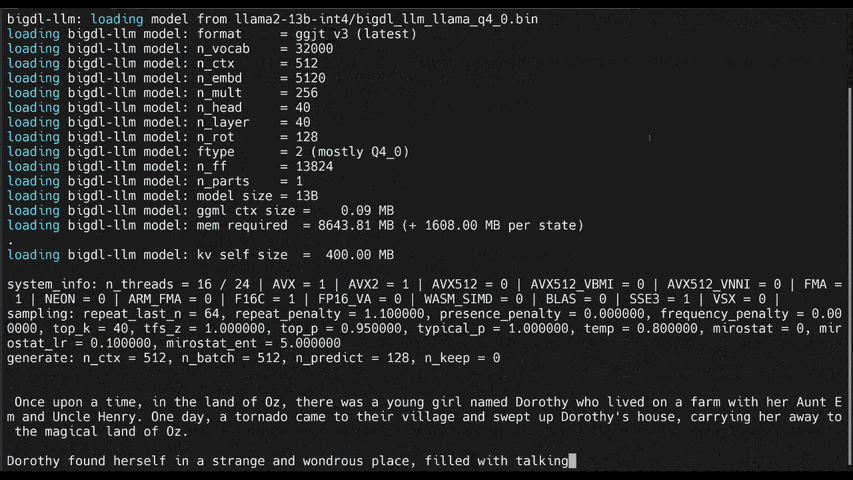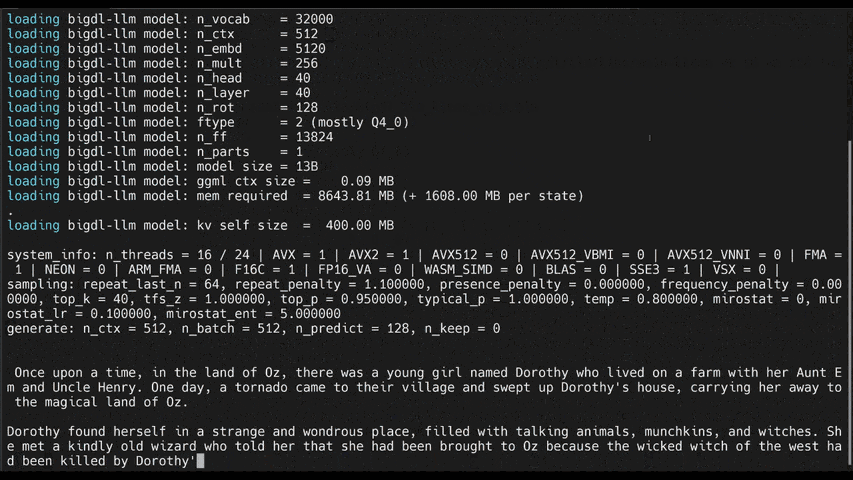
The demos below shows the experiences of running 7B and 13B model on a 16G memory laptop.
The following chapters in this tutorial will explain in more details about how to use IPEX-LLM to build LLM applications, e.g. best practices for setting up your environment, APIs, Chinese support, GPU, application development guides with case studies, etc. Most chapters provide runnable notebooks using popular open source models. Read along to learn more and run the code on your laptop.
Also, you can check out our GitHub repo for more information and latest news.
We have already verified many models on IPEX-LLM and provided ready-to-run examples, such as Llama2, Vicuna, ChatGLM, ChatGLM2, Baichuan, MOSS, Falcon, Dolly-v1, Dolly-v2, StarCoder, Mistral, RedPajama, Whisper, etc. You can find more model examples here.
Footnotes
-
Performance varies by use, configuration and other factors.
ipex-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. ↩