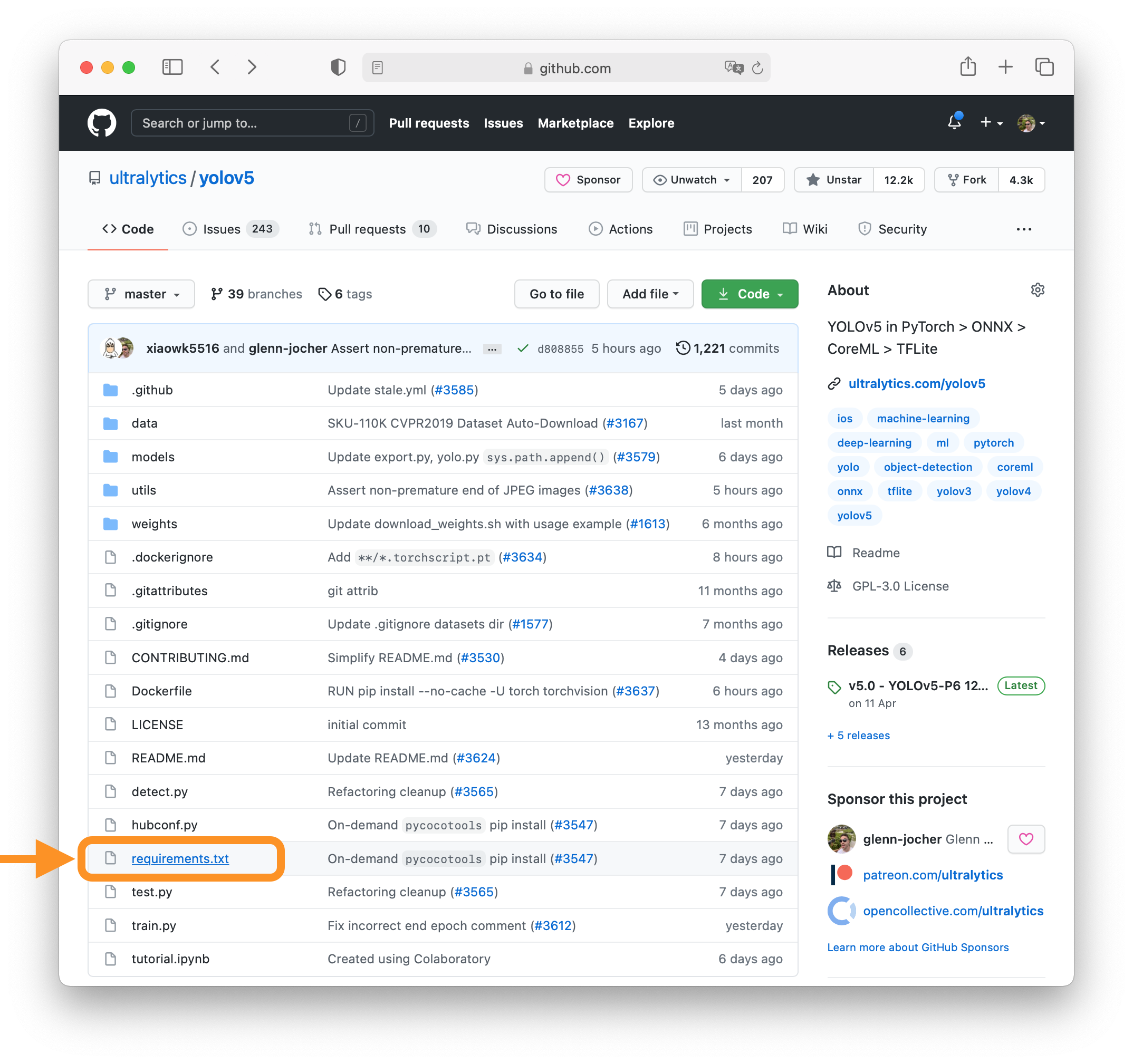
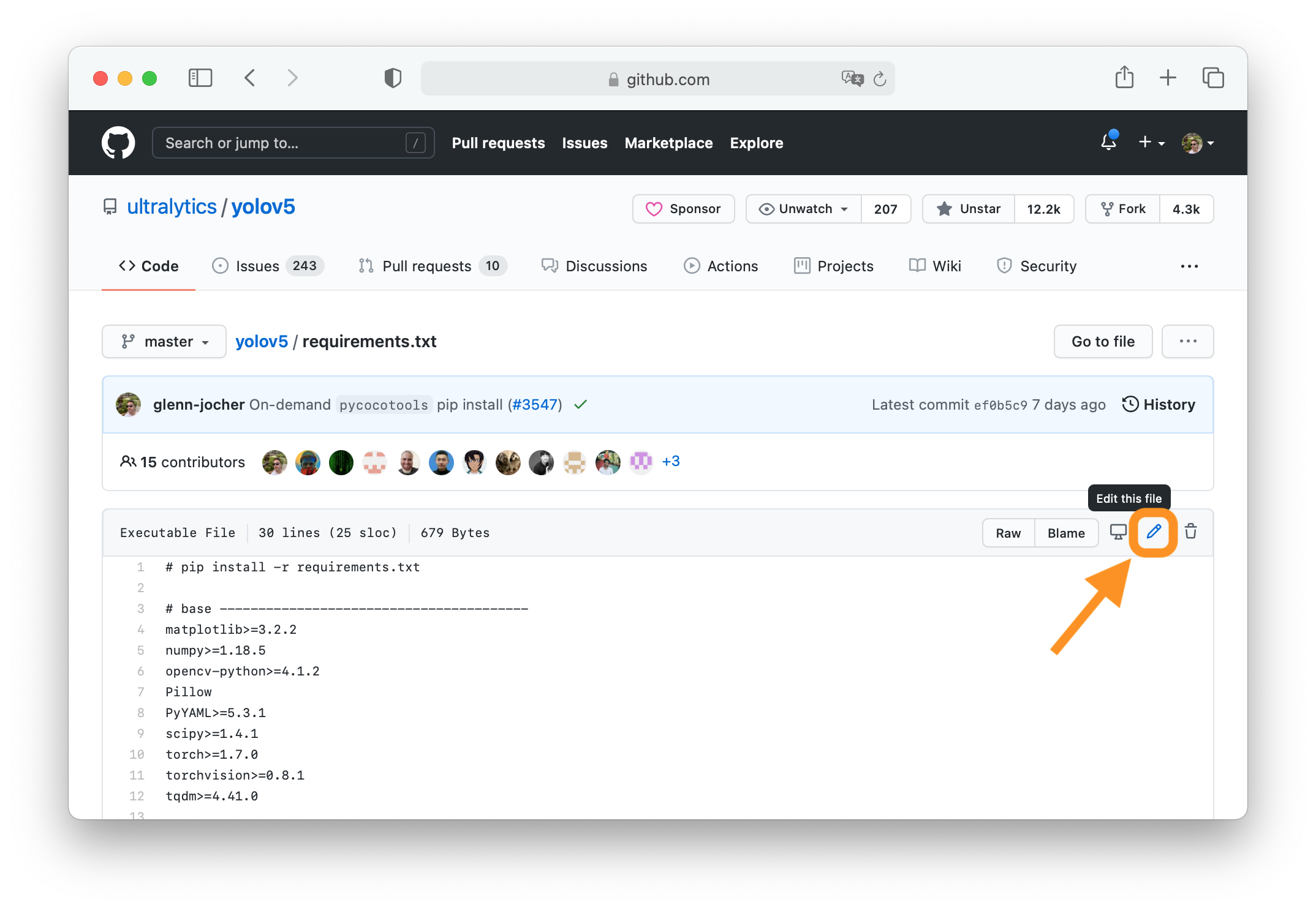
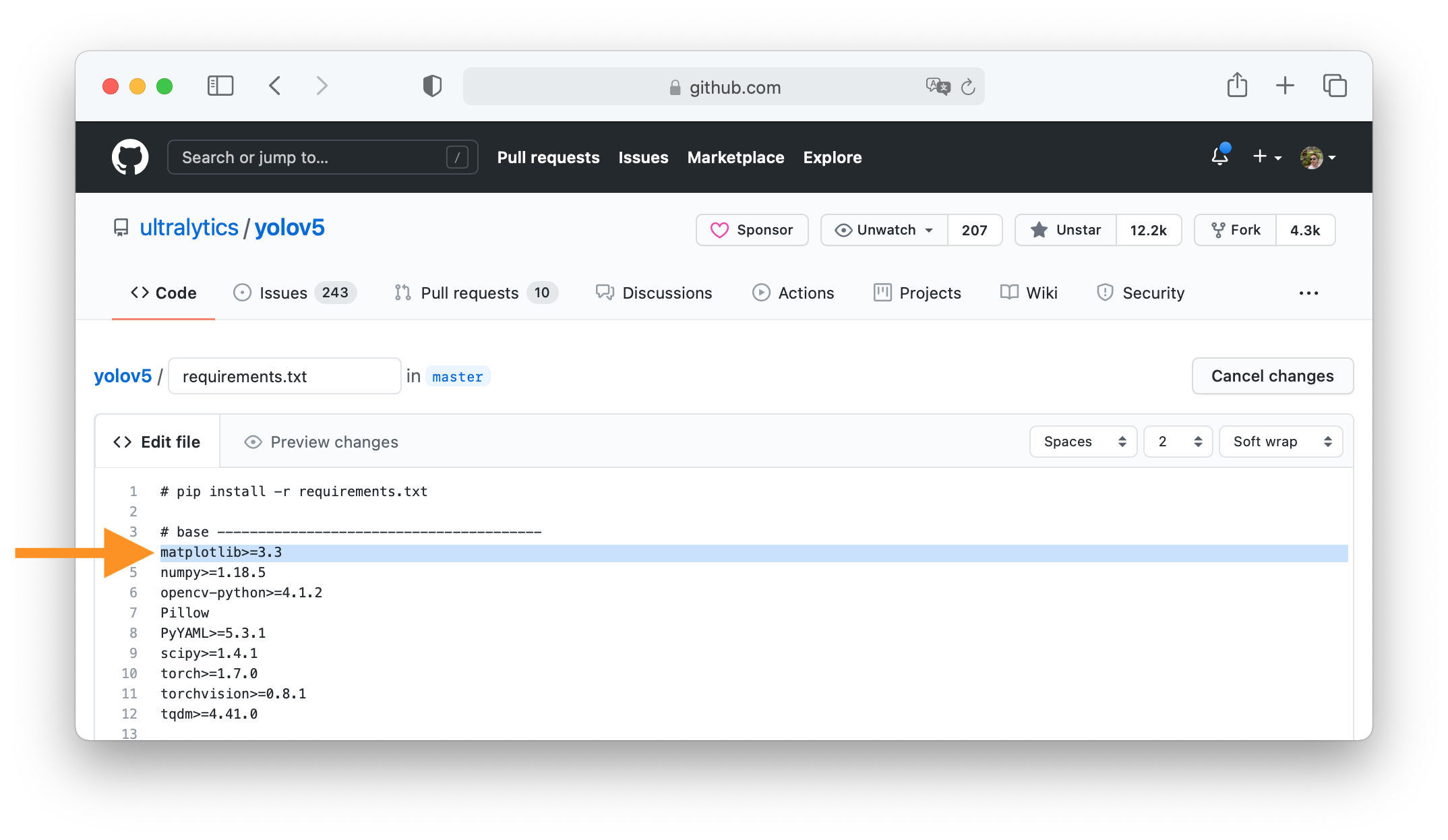
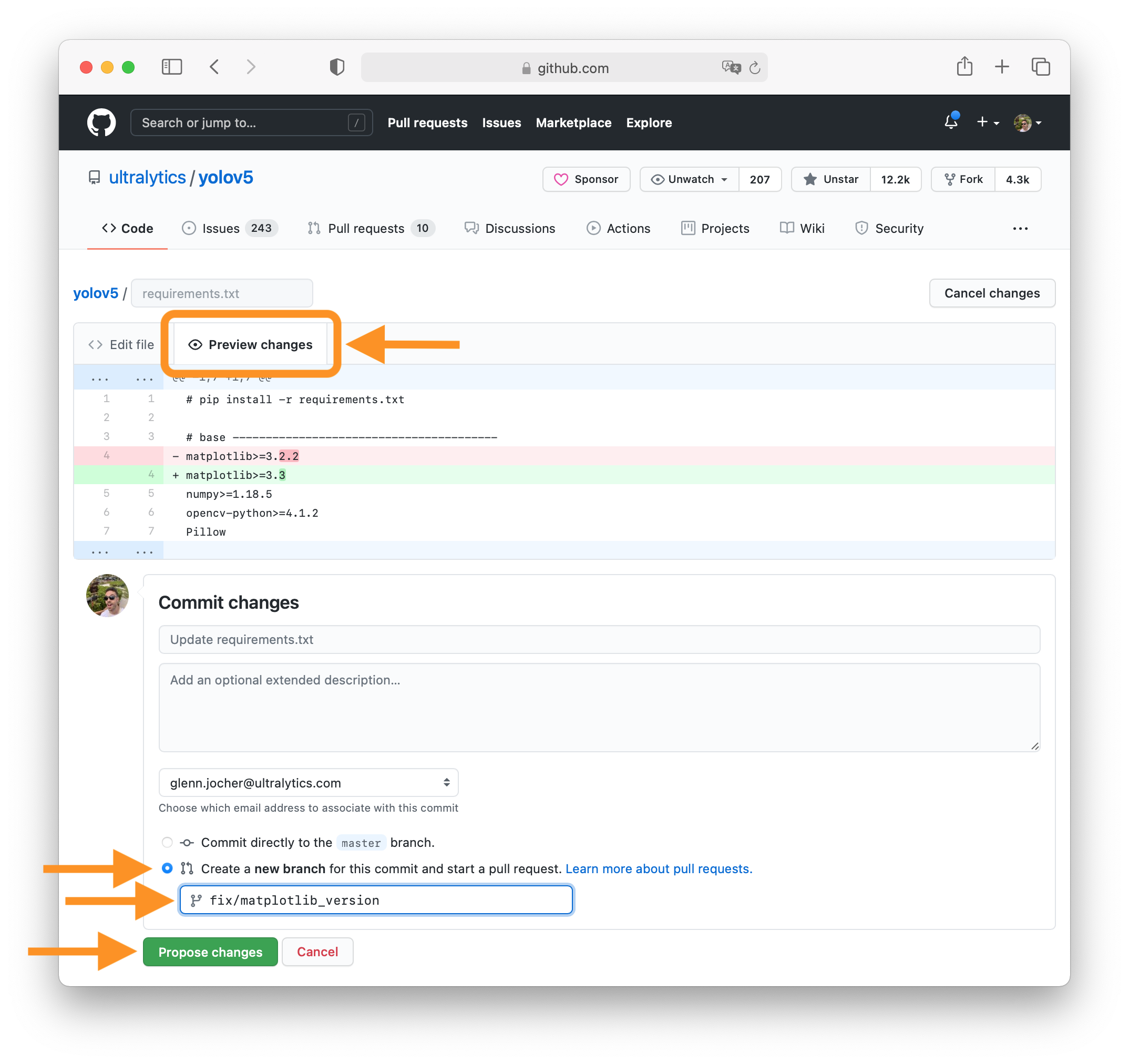
+
+  +
+
 +
+  +
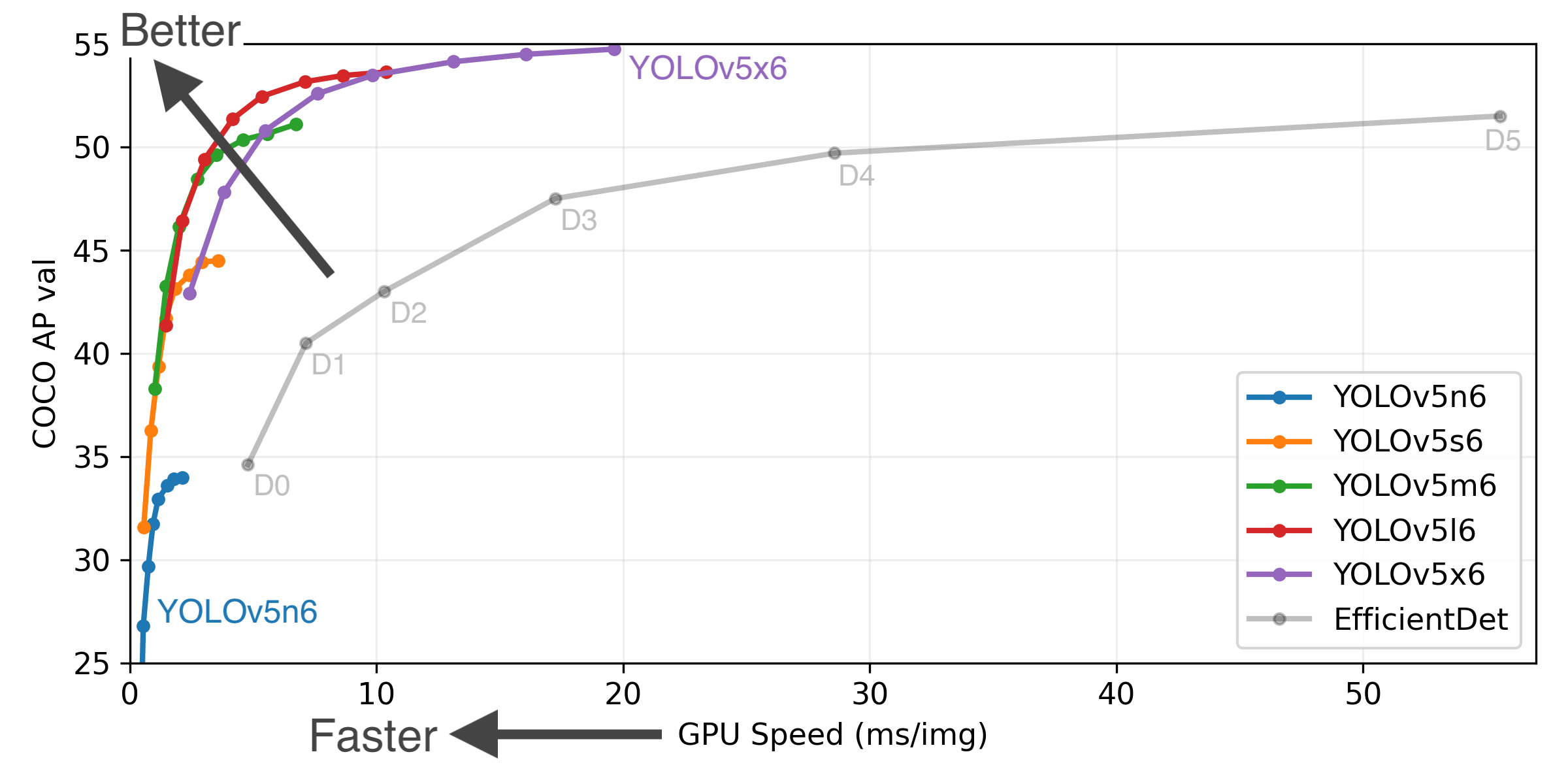
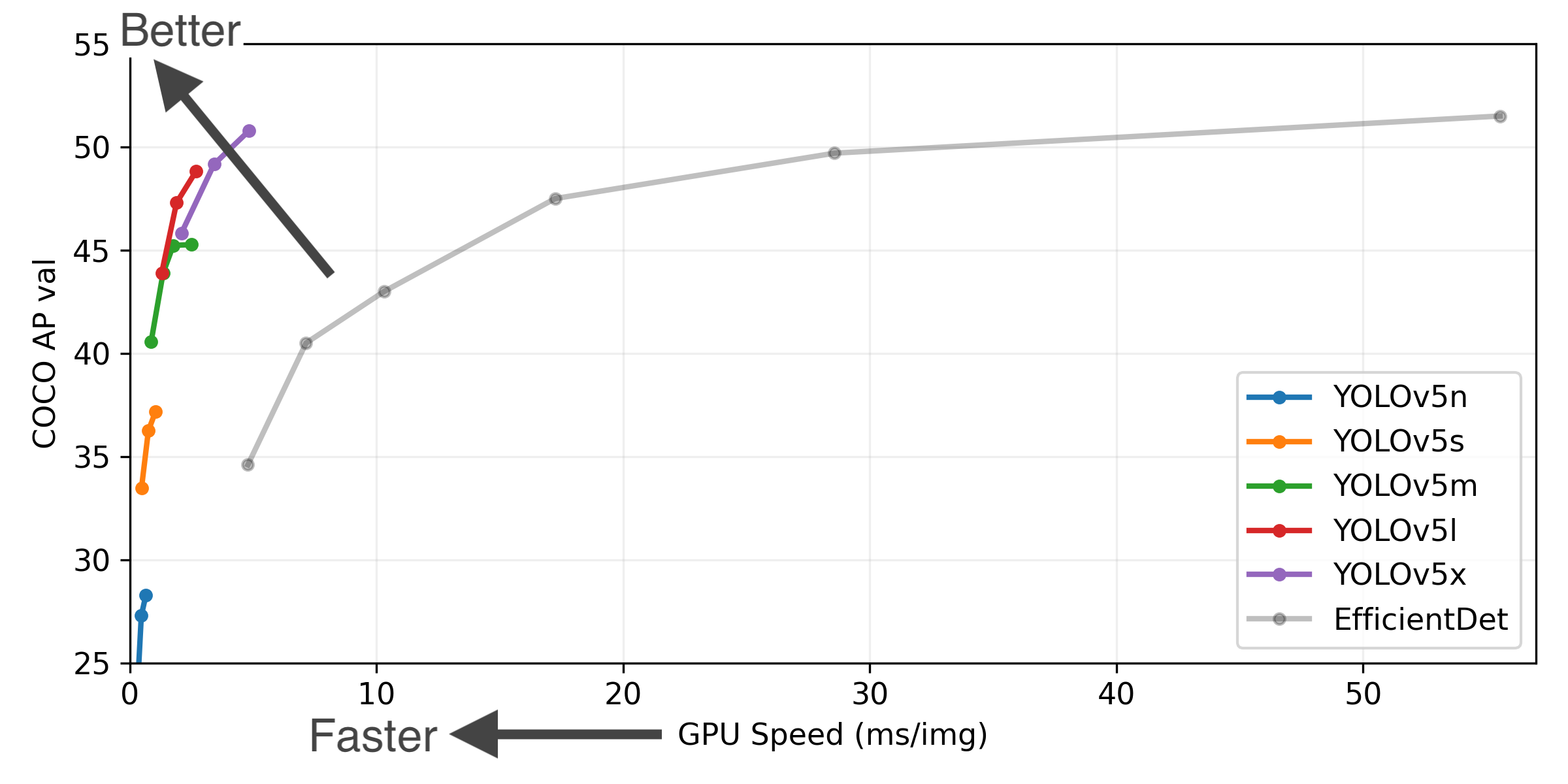
+ +YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics + open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development. +
+ + + + +
+
+
+
 +
+
+##
+
+
+##  \n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3809e5a9-dd41-4577-fe62-5531abf7cca2"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "import torch\n",
+ "from yolov5 import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "Setup complete ✅\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " path/*.jpg # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "8f7e6588-215d-4ebd-93af-88b871e770a7"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model Summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.007s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.007s)\n",
+ "Speed: 0.5ms pre-process, 6.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ "
\n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3809e5a9-dd41-4577-fe62-5531abf7cca2"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "import torch\n",
+ "from yolov5 import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "Setup complete ✅\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " path/*.jpg # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "8f7e6588-215d-4ebd-93af-88b871e770a7"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model Summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.007s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.007s)\n",
+ "Speed: 0.5ms pre-process, 6.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 48,
+ "referenced_widgets": [
+ "eb95db7cae194218b3fcefb439b6352f",
+ "769ecde6f2e64bacb596ce972f8d3d2d",
+ "384a001876054c93b0af45cd1e960bfe",
+ "dded0aeae74440f7ba2ffa0beb8dd612",
+ "5296d28be75740b2892ae421bbec3657",
+ "9f09facb2a6c4a7096810d327c8b551c",
+ "25621cff5d16448cb7260e839fd0f543",
+ "0ce7164fc0c74bb9a2b5c7037375a727",
+ "c4c4593c10904cb5b8a5724d60c7e181",
+ "473371611126476c88d5d42ec7031ed6",
+ "65efdfd0d26c46e79c8c5ff3b77126cc"
+ ]
+ },
+ "outputId": "bcf9a448-1f9b-4a41-ad49-12f181faf05a"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eb95db7cae194218b3fcefb439b6352f",
+ "version_minor": 0,
+ "version_major": 2
+ },
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 48,
+ "referenced_widgets": [
+ "eb95db7cae194218b3fcefb439b6352f",
+ "769ecde6f2e64bacb596ce972f8d3d2d",
+ "384a001876054c93b0af45cd1e960bfe",
+ "dded0aeae74440f7ba2ffa0beb8dd612",
+ "5296d28be75740b2892ae421bbec3657",
+ "9f09facb2a6c4a7096810d327c8b551c",
+ "25621cff5d16448cb7260e839fd0f543",
+ "0ce7164fc0c74bb9a2b5c7037375a727",
+ "c4c4593c10904cb5b8a5724d60c7e181",
+ "473371611126476c88d5d42ec7031ed6",
+ "65efdfd0d26c46e79c8c5ff3b77126cc"
+ ]
+ },
+ "outputId": "bcf9a448-1f9b-4a41-ad49-12f181faf05a"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eb95db7cae194218b3fcefb439b6352f",
+ "version_minor": 0,
+ "version_major": 2
+ },
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00 \n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "All results are logged by default to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc. View train and val jpgs to see mosaics, labels, predictions and augmentation effects. Note an Ultralytics **Mosaic Dataloader** is used for training (shown below), which combines 4 images into 1 mosaic during training.\n",
+ "\n",
+ ">
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "All results are logged by default to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc. View train and val jpgs to see mosaics, labels, predictions and augmentation effects. Note an Ultralytics **Mosaic Dataloader** is used for training (shown below), which combines 4 images into 1 mosaic during training.\n",
+ "\n",
+ ">  \n",
+ "`train_batch0.jpg` shows train batch 0 mosaics and labels\n",
+ "\n",
+ ">
\n",
+ "`train_batch0.jpg` shows train batch 0 mosaics and labels\n",
+ "\n",
+ ">  \n",
+ "`test_batch0_labels.jpg` shows val batch 0 labels\n",
+ "\n",
+ ">
\n",
+ "`test_batch0_labels.jpg` shows val batch 0 labels\n",
+ "\n",
+ ">  \n",
+ "`test_batch0_pred.jpg` shows val batch 0 _predictions_\n",
+ "\n",
+ "Training results are automatically logged to [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) as `results.csv`, which is plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n",
+ "\n",
+ "```python\n",
+ "from utils.plots import plot_results \n",
+ "plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "`test_batch0_pred.jpg` shows val batch 0 _predictions_\n",
+ "\n",
+ "Training results are automatically logged to [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) as `results.csv`, which is plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n",
+ "\n",
+ "```python\n",
+ "from utils.plots import plot_results \n",
+ "plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n",
+ "```\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:  \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
\n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Optional extras below. Unit tests validate repo functionality and should be run on any PRs submitted.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --task speed # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# PyTorch Hub\n",
+ "import torch\n",
+ "\n",
+ "# Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n",
+ "\n",
+ "# Images\n",
+ "dir = 'https://ultralytics.com/images/'\n",
+ "imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images\n",
+ "\n",
+ "# Inference\n",
+ "results = model(imgs)\n",
+ "results.print() # or .show(), .save()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# CI Checks\n",
+ "%%shell\n",
+ "export PYTHONPATH=\"$PWD\" # to run *.py. files in subdirectories\n",
+ "rm -rf runs # remove runs/\n",
+ "for m in yolov5n; do # models\n",
+ " python train.py --img 64 --batch 32 --weights $m.pt --epochs 1 --device 0 # train pretrained\n",
+ " python train.py --img 64 --batch 32 --weights '' --cfg $m.yaml --epochs 1 --device 0 # train scratch\n",
+ " for d in 0 cpu; do # devices\n",
+ " python val.py --weights $m.pt --device $d # val official\n",
+ " python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom\n",
+ " python detect.py --weights $m.pt --device $d # detect official\n",
+ " python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom\n",
+ " done\n",
+ " python hubconf.py # hub\n",
+ " python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ " python models/tf.py --weights $m.pt # build TensorFlow model\n",
+ " python export.py --img 64 --batch 1 --weights $m.pt --include torchscript onnx # export\n",
+ "done"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RVRSOhEvUdb5"
+ },
+ "source": [
+ "# Evolve\n",
+ "!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve\n",
+ "!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "VTRwsvA9u7ln"
+ },
+ "source": [
+ "# TensorRT \n",
+ "# https://developer.nvidia.com/nvidia-tensorrt-download\n",
+ "!lsb_release -a # check system\n",
+ "%ls /usr/local | grep cuda # check CUDA\n",
+ "!wget https://ultralytics.com/assets/TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # download\n",
+ "![ -d /content/TensorRT-8.2.0.6/ ] || tar -C /content/ -zxf ./TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # unzip\n",
+ "%pip list | grep tensorrt || pip install /content/TensorRT-8.2.0.6/python/tensorrt-8.2.0.6-cp37-none-linux_x86_64.whl # install\n",
+ "%env LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:/content/cuda-11.1/lib64:/content/TensorRT-8.2.0.6/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 # add to path\n",
+ "\n",
+ "!python export.py --weights yolov5s.pt --include engine --imgsz 640 640 --device 0\n",
+ "!python detect.py --weights yolov5s.engine --imgsz 640 640 --device 0"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/utils/.idea/.gitignore b/utils/.idea/.gitignore
new file mode 100644
index 0000000..26d3352
--- /dev/null
+++ b/utils/.idea/.gitignore
@@ -0,0 +1,3 @@
+# Default ignored files
+/shelf/
+/workspace.xml
diff --git a/utils/.idea/inspectionProfiles/Project_Default.xml b/utils/.idea/inspectionProfiles/Project_Default.xml
new file mode 100644
index 0000000..6fc75ed
--- /dev/null
+++ b/utils/.idea/inspectionProfiles/Project_Default.xml
@@ -0,0 +1,44 @@
+
+
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Optional extras below. Unit tests validate repo functionality and should be run on any PRs submitted.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --task speed # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# PyTorch Hub\n",
+ "import torch\n",
+ "\n",
+ "# Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n",
+ "\n",
+ "# Images\n",
+ "dir = 'https://ultralytics.com/images/'\n",
+ "imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images\n",
+ "\n",
+ "# Inference\n",
+ "results = model(imgs)\n",
+ "results.print() # or .show(), .save()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# CI Checks\n",
+ "%%shell\n",
+ "export PYTHONPATH=\"$PWD\" # to run *.py. files in subdirectories\n",
+ "rm -rf runs # remove runs/\n",
+ "for m in yolov5n; do # models\n",
+ " python train.py --img 64 --batch 32 --weights $m.pt --epochs 1 --device 0 # train pretrained\n",
+ " python train.py --img 64 --batch 32 --weights '' --cfg $m.yaml --epochs 1 --device 0 # train scratch\n",
+ " for d in 0 cpu; do # devices\n",
+ " python val.py --weights $m.pt --device $d # val official\n",
+ " python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom\n",
+ " python detect.py --weights $m.pt --device $d # detect official\n",
+ " python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom\n",
+ " done\n",
+ " python hubconf.py # hub\n",
+ " python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ " python models/tf.py --weights $m.pt # build TensorFlow model\n",
+ " python export.py --img 64 --batch 1 --weights $m.pt --include torchscript onnx # export\n",
+ "done"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RVRSOhEvUdb5"
+ },
+ "source": [
+ "# Evolve\n",
+ "!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve\n",
+ "!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "VTRwsvA9u7ln"
+ },
+ "source": [
+ "# TensorRT \n",
+ "# https://developer.nvidia.com/nvidia-tensorrt-download\n",
+ "!lsb_release -a # check system\n",
+ "%ls /usr/local | grep cuda # check CUDA\n",
+ "!wget https://ultralytics.com/assets/TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # download\n",
+ "![ -d /content/TensorRT-8.2.0.6/ ] || tar -C /content/ -zxf ./TensorRT-8.2.0.6.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz # unzip\n",
+ "%pip list | grep tensorrt || pip install /content/TensorRT-8.2.0.6/python/tensorrt-8.2.0.6-cp37-none-linux_x86_64.whl # install\n",
+ "%env LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:/content/cuda-11.1/lib64:/content/TensorRT-8.2.0.6/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64 # add to path\n",
+ "\n",
+ "!python export.py --weights yolov5s.pt --include engine --imgsz 640 640 --device 0\n",
+ "!python detect.py --weights yolov5s.engine --imgsz 640 640 --device 0"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/utils/.idea/.gitignore b/utils/.idea/.gitignore
new file mode 100644
index 0000000..26d3352
--- /dev/null
+++ b/utils/.idea/.gitignore
@@ -0,0 +1,3 @@
+# Default ignored files
+/shelf/
+/workspace.xml
diff --git a/utils/.idea/inspectionProfiles/Project_Default.xml b/utils/.idea/inspectionProfiles/Project_Default.xml
new file mode 100644
index 0000000..6fc75ed
--- /dev/null
+++ b/utils/.idea/inspectionProfiles/Project_Default.xml
@@ -0,0 +1,44 @@
+
+ +
+
+
+
+
+ 
$ python train.py --upload_data val
+
+
+ {dataset}_wandb.yaml file which can be used to train from dataset artifact.
+ $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..
+
+ 
+ $ python train.py --data {data}_wandb.yaml
+
+
+ $ python train.py --save_period 1
+
+
+ --resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
+
+ $ python train.py --resume wandb-artifact://{run_path}
+
+
+ --upload_dataset or
+ train from _wandb.yaml file and set --save_period
+
+ $ python train.py --resume wandb-artifact://{run_path}
+
+
+  +
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/utils/loggers/wandb/__init__.py b/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc b/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000..462122a
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc b/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000..862cb6d
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc
new file mode 100644
index 0000000..5988ad1
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc
new file mode 100644
index 0000000..f58a4be
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc differ
diff --git a/utils/loggers/wandb/log_dataset.py b/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/utils/loggers/wandb/sweep.py b/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..206059b
--- /dev/null
+++ b/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent
+ hyp_dict = vars(wandb.config).get("_items")
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/utils/loggers/wandb/sweep.yaml b/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..c7790d7
--- /dev/null
+++ b/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..221d3c8
--- /dev/null
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,560 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.datasets import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = (isinstance(data_dict['train'], str) and
+ data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX))
+ is_valset_wandb_artifact = (isinstance(data_dict['val'], str) and
+ data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX))
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup trainig processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict},
+ allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data,
+ opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(data_dict.get('train'),
+ opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(data_dict.get('val'),
+ opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model', type='model', metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score
+ })
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = Path('data') / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.img_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file),
+ name='data/labels/' + label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({"position": {"middle": [xywh[0], xywh[1]], "width": xywh[2], "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append(
+ {"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch,
+ id,
+ self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class
+ )
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact, aliases=['latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/utils/loss.py b/utils/loss.py
new file mode 100644
index 0000000..45cee3e
--- /dev/null
+++ b/utils/loss.py
@@ -0,0 +1,662 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import is_parallel
+
+import torch.nn.functional as F
+
+from utils.general import box_iou, xywh2xyxy
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEtheta = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['theta_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+ BCEtheta = FocalLoss(BCEtheta, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.stride = det.stride # tensor([8., 16., 32., ...])
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ # self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.ssi = list(self.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.BCEtheta = BCEtheta
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets): # predictions, targets, model
+ """
+ Args:
+ p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
+ targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels])
+
+ Return:
+ total_loss * bs (tensor): [1]
+ torch.cat((lbox, lobj, lcls, ltheta)).detach(): [4]
+ """
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ ltheta = torch.zeros(1, device=device)
+ # tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+ tcls, tbox, indices, anchors, tgaussian_theta = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets, (n_targets, self.no)
+
+ # Regression
+ pxy = ps[:, :2].sigmoid() * 2 - 0.5
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i] # featuremap pixel
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
+
+ # Classification
+ class_index = 5 + self.nc
+ if self.nc > 1: # cls loss (only if multiple classes)
+ # t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t = torch.full_like(ps[:, 5:class_index], self.cn, device=device) # targets
+ t[range(n), tcls[i]] = self.cp
+ # lcls += self.BCEcls(ps[:, 5:], t) # BCE
+ lcls += self.BCEcls(ps[:, 5:class_index], t) # BCE
+
+ # theta Classification by Circular Smooth Label
+ t_theta = tgaussian_theta[i].type(ps.dtype) # target theta_gaussian_labels
+ ltheta += self.BCEtheta(ps[:, class_index:], t_theta)
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ ltheta *= self.hyp['theta']
+ bs = tobj.shape[0] # batch size
+
+ # return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+ return (lbox + lobj + lcls + ltheta) * bs, torch.cat((lbox, lobj, lcls, ltheta)).detach()
+
+ def build_targets(self, p, targets):
+ """
+ Args:
+ p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
+ targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels]) pixel
+
+ Return:non-normalized data
+ tcls (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
+ tbox (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 4) featuremap pixel
+ indices (list[P3_out,...]): len=self.na, tensor.size(4, n_filter2) [b, a, gj, gi]
+ anch (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 2)
+ tgaussian_theta (list[P3_out,...]): len=self.na, tensor.size(n_filter2, hyp['cls_theta'])
+ # ttheta (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
+ """
+ # Build targets for compute_loss()
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ # ttheta, tgaussian_theta = [], []
+ tgaussian_theta = []
+ # gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ feature_wh = torch.ones(2, device=targets.device) # feature_wh
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ # targets (tensor): (n_gt_all_batch, c) -> (na, n_gt_all_batch, c) -> (na, n_gt_all_batch, c+1)
+ # targets (tensor): (na, n_gt_all_batch, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index]])
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0], # tensor: (5, 2)
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ # gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain=[1, 1, w, h, w, h, 1, 1]
+ feature_wh[0:2] = torch.tensor(p[i].shape)[[3, 2]] # xyxy gain=[w_f, h_f]
+
+ # Match targets to anchors
+ # t = targets * gain # xywh featuremap pixel
+ t = targets.clone() # (na, n_gt_all_batch, c+1)
+ t[:, :, 2:6] /= self.stride[i] # xyls featuremap pixel
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # edge_ls ratio, torch.size(na, n_gt_all_batch, 2)
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare, torch.size(na, n_gt_all_batch)
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter; Tensor.size(n_filter1, c+1)
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy; (n_filter1, 2)
+ # gxi = gain[[2, 3]] - gxy # inverse
+ gxi = feature_wh[[0, 1]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m)) # (5, n_filter1)
+ t = t.repeat((5, 1, 1))[j] # (n_filter1, c+1) -> (5, n_filter1, c+1) -> (n_filter2, c+1)
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # (5, n_filter1, 2) -> (n_filter2, 2)
+ else:
+ t = targets[0] # (n_gt_all_batch, c+1)
+ offsets = 0
+
+ # Define, t (tensor): (n_filter2, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index])
+ b, c = t[:, :2].long().T # image, class; (n_filter2)
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ # theta = t[:, 6]
+ gaussian_theta_labels = t[:, 7:-1]
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, -1].long() # anchor indices 取整
+ # indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ indices.append((b, a, gj.clamp_(0, feature_wh[1] - 1), gi.clamp_(0, feature_wh[0] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ # ttheta.append(theta) # theta, θ∈[-pi/2, pi/2)
+ tgaussian_theta.append(gaussian_theta_labels)
+
+ # return tcls, tbox, indices, anch
+ return tcls, tbox, indices, anch, tgaussian_theta #, ttheta
+
+
+class ComputeLossOTA:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEtheta = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['theta_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+ BCEtheta = FocalLoss(BCEtheta, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.stride = det.stride # tensor([8., 16., 32., ...])
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ # self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.ssi = list(self.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.BCEtheta = BCEtheta
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets, imgs): # predictions, targets, model
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ ltheta = torch.zeros(1, device=device)
+ bs, as_, gjs, gis, targets, anchors, tgaussian_theta, indices = self.build_targets(p, targets, imgs)
+ pre_gen_gains = [torch.tensor(pp.shape, device=device)[[3, 2, 3, 2]] for pp in p]
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i] # image, anchor, gridy, gridx
+ b1, a1, gj1, gi1 = indices[i]
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
+ ps1 = pi[b1, a1, gj1, gi1]
+
+ # Regression
+ grid = torch.stack([gi, gj], dim=1)
+ pxy = ps[:, :2].sigmoid() * 2. - 0.5
+ # pxy = ps[:, :2].sigmoid() * 3. - 1.
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ selected_tbox = targets[i][:, 2:6] * pre_gen_gains[i]
+ selected_tbox[:, :2] -= grid
+ iou = bbox_iou(pbox.T, selected_tbox, x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
+
+ # Classification
+ selected_tcls = targets[i][:, 1].long()
+ class_index = 5 + self.nc
+ if self.nc > 1: # cls loss (only if multiple classes)
+ '''t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t[range(n), selected_tcls] = self.cp
+ lcls += self.BCEcls(ps[:, 5:], t) # BCE'''
+
+ t = torch.full_like(ps[:, 5:class_index], self.cn, device=device) # targets
+ t[range(n), selected_tcls] = self.cp
+ lcls += self.BCEcls(ps[:, 5:class_index], t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ t_theta = tgaussian_theta[i].type(ps1.dtype) # target theta_gaussian_labels
+ ltheta += self.BCEtheta(ps1[:, class_index:], t_theta)
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ ltheta *= self.hyp['theta']
+ bs = tobj.shape[0] # batch size
+
+ loss = lbox + lobj + lcls + ltheta
+ #return (lbox + lobj + lcls + ltheta) * bs, torch.cat((lbox, lobj, lcls, ltheta)).detach()
+ return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
+
+ def build_targets(self, p, targets, imgs):
+
+ # indices, anch = self.find_positive(p, targets)
+ indices, anch, tgaussian_theta = self.find_3_positive(p, targets)
+ # indices, anch = self.find_4_positive(p, targets)
+ # indices, anch = self.find_5_positive(p, targets)
+ # indices, anch = self.find_9_positive(p, targets)
+
+ matching_bs = [[] for pp in p]
+ matching_as = [[] for pp in p]
+ matching_gjs = [[] for pp in p]
+ matching_gis = [[] for pp in p]
+ matching_targets = [[] for pp in p]
+ matching_anchs = [[] for pp in p]
+
+ nl = len(p)
+
+ for batch_idx in range(p[0].shape[0]):
+
+ b_idx = targets[:, 0] == batch_idx
+ this_target = targets[b_idx]
+ if this_target.shape[0] == 0:
+ continue
+
+ txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
+ txyxy = xywh2xyxy(txywh)
+
+ pxyxys = []
+ p_cls = []
+ p_obj = []
+ from_which_layer = []
+ all_b = []
+ all_a = []
+ all_gj = []
+ all_gi = []
+ all_anch = []
+
+ for i, pi in enumerate(p):
+ b, a, gj, gi = indices[i]
+ idx = (b == batch_idx)
+ b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
+ all_b.append(b)
+ all_a.append(a)
+ all_gj.append(gj)
+ all_gi.append(gi)
+ all_anch.append(anch[i][idx])
+ from_which_layer.append(torch.ones(size=(len(b),)) * i)
+
+ fg_pred = pi[b, a, gj, gi]
+ p_obj.append(fg_pred[:, 4:5])
+ p_cls.append(fg_pred[:, 5:])
+
+ grid = torch.stack([gi, gj], dim=1)
+ pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] # / 8.
+ # pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
+ pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] # / 8.
+ pxywh = torch.cat([pxy, pwh], dim=-1)
+ pxyxy = xywh2xyxy(pxywh)
+ pxyxys.append(pxyxy)
+
+ pxyxys = torch.cat(pxyxys, dim=0)
+ if pxyxys.shape[0] == 0:
+ continue
+ p_obj = torch.cat(p_obj, dim=0)
+ p_cls = torch.cat(p_cls, dim=0)
+ from_which_layer = torch.cat(from_which_layer, dim=0)
+ all_b = torch.cat(all_b, dim=0)
+ all_a = torch.cat(all_a, dim=0)
+ all_gj = torch.cat(all_gj, dim=0)
+ all_gi = torch.cat(all_gi, dim=0)
+ all_anch = torch.cat(all_anch, dim=0)
+
+ pair_wise_iou = box_iou(txyxy, pxyxys)
+
+ pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
+
+ top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
+ dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
+
+ gt_cls_per_image = (
+ F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
+ .float()
+ .unsqueeze(1)
+ .repeat(1, pxyxys.shape[0], 181)
+ )
+
+ num_gt = this_target.shape[0]
+
+ cls_preds_ = (
+ p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
+ * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
+ )
+
+ y = cls_preds_.sqrt_()
+ pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
+ torch.log(y / (1 - y)), gt_cls_per_image, reduction="none"
+ ).sum(-1)
+ del cls_preds_
+
+ cost = (
+ pair_wise_cls_loss
+ + 3.0 * pair_wise_iou_loss
+ )
+
+ matching_matrix = torch.zeros_like(cost)
+
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
+ )
+ matching_matrix[gt_idx][pos_idx] = 1.0
+
+ del top_k, dynamic_ks
+ anchor_matching_gt = matching_matrix.sum(0)
+ if (anchor_matching_gt > 1).sum() > 0:
+ _, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
+ matching_matrix[:, anchor_matching_gt > 1] *= 0.0
+ matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
+ fg_mask_inboxes = matching_matrix.sum(0) > 0.0
+ matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
+
+ from_which_layer = from_which_layer[fg_mask_inboxes]
+ all_b = all_b[fg_mask_inboxes]
+ all_a = all_a[fg_mask_inboxes]
+ all_gj = all_gj[fg_mask_inboxes]
+ all_gi = all_gi[fg_mask_inboxes]
+ all_anch = all_anch[fg_mask_inboxes]
+
+ this_target = this_target[matched_gt_inds]
+
+ for i in range(nl):
+ layer_idx = from_which_layer == i
+ matching_bs[i].append(all_b[layer_idx])
+ matching_as[i].append(all_a[layer_idx])
+ matching_gjs[i].append(all_gj[layer_idx])
+ matching_gis[i].append(all_gi[layer_idx])
+ matching_targets[i].append(this_target[layer_idx])
+ matching_anchs[i].append(all_anch[layer_idx])
+
+ for i in range(nl):
+ if matching_targets[i] != []:
+ matching_bs[i] = torch.cat(matching_bs[i], dim=0)
+ matching_as[i] = torch.cat(matching_as[i], dim=0)
+ matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
+ matching_gis[i] = torch.cat(matching_gis[i], dim=0)
+ matching_targets[i] = torch.cat(matching_targets[i], dim=0)
+ matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
+ else:
+ matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+
+ return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs, tgaussian_theta, indices
+
+ def find_3_positive(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ '''na, nt = self.na, targets.shape[0] # number of anchors, targets
+ indices, anch = [], []
+ gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0],
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1. < g) & (gxy > 1.)).T
+ l, m = ((gxi % 1. < g) & (gxi > 1.)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ b, c = t[:, :2].long().T # image, class
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, 6].long() # anchor indices
+ indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ anch.append(anchors[a]) # anchors
+
+ return indices, anch'''
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ # ttheta, tgaussian_theta = [], []
+ tgaussian_theta = []
+ # gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ feature_wh = torch.ones(2, device=targets.device) # feature_wh
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ # targets (tensor): (n_gt_all_batch, c) -> (na, n_gt_all_batch, c) -> (na, n_gt_all_batch, c+1)
+ # targets (tensor): (na, n_gt_all_batch, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index]])
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0], # tensor: (5, 2)
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ # gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain=[1, 1, w, h, w, h, 1, 1]
+ feature_wh[0:2] = torch.tensor(p[i].shape)[[3, 2]] # xyxy gain=[w_f, h_f]
+
+ # Match targets to anchors
+ # t = targets * gain # xywh featuremap pixel
+ t = targets.clone() # (na, n_gt_all_batch, c+1)
+ t[:, :, 2:6] /= self.stride[i] # xyls featuremap pixel
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # edge_ls ratio, torch.size(na, n_gt_all_batch, 2)
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare, torch.size(na, n_gt_all_batch)
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter; Tensor.size(n_filter1, c+1)
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy; (n_filter1, 2)
+ # gxi = gain[[2, 3]] - gxy # inverse
+ gxi = feature_wh[[0, 1]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m)) # (5, n_filter1)
+ t = t.repeat((5, 1, 1))[j] # (n_filter1, c+1) -> (5, n_filter1, c+1) -> (n_filter2, c+1)
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # (5, n_filter1, 2) -> (n_filter2, 2)
+ else:
+ t = targets[0] # (n_gt_all_batch, c+1)
+ offsets = 0
+
+ # Define, t (tensor): (n_filter2, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index])
+ b, c = t[:, :2].long().T # image, class; (n_filter2)
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ # theta = t[:, 6]
+ gaussian_theta_labels = t[:, 7:-1]
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, -1].long() # anchor indices 取整
+ # indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ indices.append(
+ (b, a, gj.clamp_(0, feature_wh[1] - 1), gi.clamp_(0, feature_wh[0] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ # ttheta.append(theta) # theta, θ∈[-pi/2, pi/2)
+ tgaussian_theta.append(gaussian_theta_labels)
+
+ # return tcls, tbox, indices, anch
+ return indices, anch, tgaussian_theta # , ttheta
\ No newline at end of file
diff --git a/utils/metrics.py b/utils/metrics.py
new file mode 100644
index 0000000..c80bfa2
--- /dev/null
+++ b/utils/metrics.py
@@ -0,0 +1,344 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+
+ if n_p == 0 or n_l == 0:
+ continue
+ else:
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = {i: v for i, v in enumerate(names)} # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = f1.mean(0).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype('int32')
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(np.int16)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
+ labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
+ box2 = box2.T
+
+ # Get the coordinates of bounding boxes
+ if x1y1x2y2: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+ else: # transform from xywh to xyxy
+ b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
+ b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
+ b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
+ b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
+ (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ else:
+ return iou - rho2 / c2 # DIoU
+ else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU
+ else:
+ return iou # IoU
+
+
+def box_iou(box1, box2):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ def box_area(box):
+ # box = 4xn
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+ area1 = box_area(box1.T)
+ area2 = box_area(box2.T)
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
+ return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
+
+
+def bbox_ioa(box1, box2, eps=1E-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ box2 = box2.transpose()
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f hbb mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = py.mean(0)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
diff --git a/utils/nms_rotated/__init__.py b/utils/nms_rotated/__init__.py
new file mode 100644
index 0000000..9768d17
--- /dev/null
+++ b/utils/nms_rotated/__init__.py
@@ -0,0 +1,3 @@
+from .nms_rotated_wrapper import obb_nms, poly_nms
+
+__all__ = ['obb_nms', 'poly_nms']
diff --git a/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc b/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000..6ec2e44
Binary files /dev/null and b/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc differ
diff --git a/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc b/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc
new file mode 100644
index 0000000..ef94b65
Binary files /dev/null and b/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc differ
diff --git a/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd b/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd
new file mode 100644
index 0000000..ec6c224
Binary files /dev/null and b/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps
new file mode 100644
index 0000000..bb12204
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log
new file mode 100644
index 0000000..b0f0c7f
--- /dev/null
+++ b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log
@@ -0,0 +1,9 @@
+# ninja log v5
+2 3053 6788011957379629 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 230f582cc4ead385
+2 6945 6788011996267406 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 91ac4870d9dfe29f
+3 3474 6789732946931915 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 1256c1d3ee98246c
+1 7591 6789732988080942 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 62d6bb08f7474408
+3 3117 6789734007496664 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 230f582cc4ead385
+2 6897 6789734045285714 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 91ac4870d9dfe29f
+3 8105 6789761451993078 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj de5e56148eafc714
+1 8722 6789761458150954 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj 8782fd757258be9d
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja
new file mode 100644
index 0000000..6700a49
--- /dev/null
+++ b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja
@@ -0,0 +1,28 @@
+ninja_required_version = 1.3
+cxx = cl
+nvcc = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin\nvcc
+
+cflags = /nologo /O2 /W3 /GL /DNDEBUG /MD /MD /wd4819 /wd4251 /wd4244 /wd4267 /wd4275 /wd4018 /wd4190 /EHsc -DWITH_CUDA -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\torch\csrc\api\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\TH -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\THC "-IC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include" -ID:\anaconda3\envs\pytorch\include -ID:\anaconda3\envs\pytorch\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.29.30133\include" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\shared" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\winrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\cppwinrt"
+post_cflags = -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=nms_rotated_ext -D_GLIBCXX_USE_CXX11_ABI=0 /std:c++14
+cuda_cflags = --use-local-env -Xcompiler /MD -Xcompiler /wd4819 -Xcompiler /wd4251 -Xcompiler /wd4244 -Xcompiler /wd4267 -Xcompiler /wd4275 -Xcompiler /wd4018 -Xcompiler /wd4190 -Xcompiler /EHsc -Xcudafe --diag_suppress=base_class_has_different_dll_interface -Xcudafe --diag_suppress=field_without_dll_interface -Xcudafe --diag_suppress=dll_interface_conflict_none_assumed -Xcudafe --diag_suppress=dll_interface_conflict_dllexport_assumed -DWITH_CUDA -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\torch\csrc\api\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\TH -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\THC "-IC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include" -ID:\anaconda3\envs\pytorch\include -ID:\anaconda3\envs\pytorch\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.29.30133\include" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\shared" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\winrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\cppwinrt"
+cuda_post_cflags = -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=nms_rotated_ext -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_80,code=sm_80
+ldflags =
+
+rule compile
+ command = cl /showIncludes $cflags -c $in /Fo$out $post_cflags
+ deps = msvc
+
+rule cuda_compile
+ command = $nvcc $cuda_cflags -c $in -o $out $cuda_post_cflags
+
+
+
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_cpu.obj: compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_cpu.cpp
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_cuda.obj: cuda_compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_cuda.cu
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_ext.obj: compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_ext.cpp
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/poly_nms_cuda.obj: cuda_compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\poly_nms_cuda.cu
+
+
+
+
+
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj
new file mode 100644
index 0000000..9e1c6d5
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj
new file mode 100644
index 0000000..3980701
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp
new file mode 100644
index 0000000..b834ae3
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib
new file mode 100644
index 0000000..ff8a16a
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj
new file mode 100644
index 0000000..98c1c5f
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj
new file mode 100644
index 0000000..d9ba8f4
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj differ
diff --git a/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO b/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO
new file mode 100644
index 0000000..83acf87
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO
@@ -0,0 +1,9 @@
+Metadata-Version: 2.1
+Name: nms-rotated
+Version: 0.0.0
+Summary: UNKNOWN
+License: UNKNOWN
+Platform: UNKNOWN
+
+UNKNOWN
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt b/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt
new file mode 100644
index 0000000..8e475c6
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt
@@ -0,0 +1,10 @@
+setup.py
+nms_rotated.egg-info/PKG-INFO
+nms_rotated.egg-info/SOURCES.txt
+nms_rotated.egg-info/dependency_links.txt
+nms_rotated.egg-info/not-zip-safe
+nms_rotated.egg-info/top_level.txt
+src/nms_rotated_cpu.cpp
+src/nms_rotated_cuda.cu
+src/nms_rotated_ext.cpp
+src/poly_nms_cuda.cu
\ No newline at end of file
diff --git a/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt b/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe b/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/top_level.txt b/utils/nms_rotated/nms_rotated.egg-info/top_level.txt
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/top_level.txt
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated_ext.pyd b/utils/nms_rotated/nms_rotated_ext.pyd
new file mode 100644
index 0000000..ec6c224
Binary files /dev/null and b/utils/nms_rotated/nms_rotated_ext.pyd differ
diff --git a/utils/nms_rotated/nms_rotated_wrapper.py b/utils/nms_rotated/nms_rotated_wrapper.py
new file mode 100644
index 0000000..b2412e5
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated_wrapper.py
@@ -0,0 +1,79 @@
+import numpy as np
+import torch
+
+from . import nms_rotated_ext
+
+
+def obb_nms(dets, scores, iou_thr, device_id=None):
+ """
+ RIoU NMS - iou_thr.
+ Args:
+ dets (tensor/array): (num, [cx cy w h θ]) θ∈[-pi/2, pi/2)
+ scores (tensor/array): (num)
+ iou_thr (float): (1)
+ Returns:
+ dets (tensor): (n_nms, [cx cy w h θ])
+ inds (tensor): (n_nms), nms index of dets
+ """
+ if isinstance(dets, torch.Tensor):
+ is_numpy = False
+ dets_th = dets
+ elif isinstance(dets, np.ndarray):
+ is_numpy = True
+ device = 'cpu' if device_id is None else f'cuda:{device_id}'
+ dets_th = torch.from_numpy(dets).to(device)
+ else:
+ raise TypeError('dets must be eithr a Tensor or numpy array, '
+ f'but got {type(dets)}')
+
+ if dets_th.numel() == 0: # len(dets)
+ inds = dets_th.new_zeros(0, dtype=torch.int64)
+ else:
+ # same bug will happen when bboxes is too small
+ too_small = dets_th[:, [2, 3]].min(1)[0] < 0.001 # [n]
+ if too_small.all(): # all the bboxes is too small
+ inds = dets_th.new_zeros(0, dtype=torch.int64)
+ else:
+ ori_inds = torch.arange(dets_th.size(0)) # 0 ~ n-1
+ ori_inds = ori_inds[~too_small]
+ dets_th = dets_th[~too_small] # (n_filter, 5)
+ scores = scores[~too_small]
+
+ inds = nms_rotated_ext.nms_rotated(dets_th, scores, iou_thr)
+ inds = ori_inds[inds]
+
+ if is_numpy:
+ inds = inds.cpu().numpy()
+ return dets[inds, :], inds
+
+
+def poly_nms(dets, iou_thr, device_id=None):
+ if isinstance(dets, torch.Tensor):
+ is_numpy = False
+ dets_th = dets
+ elif isinstance(dets, np.ndarray):
+ is_numpy = True
+ device = 'cpu' if device_id is None else f'cuda:{device_id}'
+ dets_th = torch.from_numpy(dets).to(device)
+ else:
+ raise TypeError('dets must be eithr a Tensor or numpy array, '
+ f'but got {type(dets)}')
+
+ if dets_th.device == torch.device('cpu'):
+ raise NotImplementedError
+ inds = nms_rotated_ext.nms_poly(dets_th.float(), iou_thr)
+
+ if is_numpy:
+ inds = inds.cpu().numpy()
+ return dets[inds, :], inds
+
+if __name__ == '__main__':
+ rboxes_opencv = torch.tensor(([136.6, 111.6, 200, 100, -60],
+ [136.6, 111.6, 100, 200, -30],
+ [100, 100, 141.4, 141.4, -45],
+ [100, 100, 141.4, 141.4, -45]))
+ rboxes_longedge = torch.tensor(([136.6, 111.6, 200, 100, -60],
+ [136.6, 111.6, 200, 100, 120],
+ [100, 100, 141.4, 141.4, 45],
+ [100, 100, 141.4, 141.4, 135]))
+
\ No newline at end of file
diff --git a/utils/nms_rotated/setup.py b/utils/nms_rotated/setup.py
new file mode 100644
index 0000000..a3ee967
--- /dev/null
+++ b/utils/nms_rotated/setup.py
@@ -0,0 +1,54 @@
+#!/usr/bin/env python
+import os
+import subprocess
+import time
+from setuptools import find_packages, setup
+
+import torch
+from torch.utils.cpp_extension import (BuildExtension, CppExtension,
+ CUDAExtension)
+def make_cuda_ext(name, module, sources, sources_cuda=[]):
+
+ define_macros = []
+ extra_compile_args = {'cxx': []}
+
+ if torch.cuda.is_available() or os.getenv('FORCE_CUDA', '0') == '1':
+ define_macros += [('WITH_CUDA', None)]
+ extension = CUDAExtension
+ extra_compile_args['nvcc'] = [
+ '-D__CUDA_NO_HALF_OPERATORS__',
+ '-D__CUDA_NO_HALF_CONVERSIONS__',
+ '-D__CUDA_NO_HALF2_OPERATORS__',
+ ]
+ sources += sources_cuda
+ else:
+ print(f'Compiling {name} without CUDA')
+ extension = CppExtension
+ # raise EnvironmentError('CUDA is required to compile MMDetection!')
+
+ return extension(
+ name=f'{module}.{name}',
+ sources=[os.path.join(*module.split('.'), p) for p in sources],
+ define_macros=define_macros,
+ extra_compile_args=extra_compile_args)
+
+# python setup.py develop
+if __name__ == '__main__':
+ #write_version_py()
+ setup(
+ name='nms_rotated',
+ ext_modules=[
+ make_cuda_ext(
+ name='nms_rotated_ext',
+ module='',
+ sources=[
+ 'src/nms_rotated_cpu.cpp',
+ 'src/nms_rotated_ext.cpp'
+ ],
+ sources_cuda=[
+ 'src/nms_rotated_cuda.cu',
+ 'src/poly_nms_cuda.cu',
+ ]),
+ ],
+ cmdclass={'build_ext': BuildExtension},
+ zip_safe=False)
\ No newline at end of file
diff --git a/utils/nms_rotated/src/box_iou_rotated_utils.h b/utils/nms_rotated/src/box_iou_rotated_utils.h
new file mode 100644
index 0000000..c017e17
--- /dev/null
+++ b/utils/nms_rotated/src/box_iou_rotated_utils.h
@@ -0,0 +1,360 @@
+// Mortified from
+// https://github.com/facebookresearch/detectron2/tree/master/detectron2/layers/csrc/box_iou_rotated
+// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+#pragma once
+
+#include
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/utils/loggers/wandb/__init__.py b/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc b/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000..462122a
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/__init__.cpython-37.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc b/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000..862cb6d
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/__init__.cpython-39.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc
new file mode 100644
index 0000000..5988ad1
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-37.pyc differ
diff --git a/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc
new file mode 100644
index 0000000..f58a4be
Binary files /dev/null and b/utils/loggers/wandb/__pycache__/wandb_utils.cpython-39.pyc differ
diff --git a/utils/loggers/wandb/log_dataset.py b/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/utils/loggers/wandb/sweep.py b/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..206059b
--- /dev/null
+++ b/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent
+ hyp_dict = vars(wandb.config).get("_items")
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/utils/loggers/wandb/sweep.yaml b/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..c7790d7
--- /dev/null
+++ b/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..221d3c8
--- /dev/null
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,560 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.datasets import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = (isinstance(data_dict['train'], str) and
+ data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX))
+ is_valset_wandb_artifact = (isinstance(data_dict['val'], str) and
+ data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX))
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup trainig processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict},
+ allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data,
+ opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(data_dict.get('train'),
+ opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(data_dict.get('val'),
+ opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model', type='model', metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score
+ })
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = Path('data') / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.img_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file),
+ name='data/labels/' + label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({"position": {"middle": [xywh[0], xywh[1]], "width": xywh[2], "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append(
+ {"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch,
+ id,
+ self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class
+ )
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact, aliases=['latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/utils/loss.py b/utils/loss.py
new file mode 100644
index 0000000..45cee3e
--- /dev/null
+++ b/utils/loss.py
@@ -0,0 +1,662 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import is_parallel
+
+import torch.nn.functional as F
+
+from utils.general import box_iou, xywh2xyxy
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEtheta = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['theta_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+ BCEtheta = FocalLoss(BCEtheta, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.stride = det.stride # tensor([8., 16., 32., ...])
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ # self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.ssi = list(self.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.BCEtheta = BCEtheta
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets): # predictions, targets, model
+ """
+ Args:
+ p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
+ targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels])
+
+ Return:
+ total_loss * bs (tensor): [1]
+ torch.cat((lbox, lobj, lcls, ltheta)).detach(): [4]
+ """
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ ltheta = torch.zeros(1, device=device)
+ # tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+ tcls, tbox, indices, anchors, tgaussian_theta = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets, (n_targets, self.no)
+
+ # Regression
+ pxy = ps[:, :2].sigmoid() * 2 - 0.5
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i] # featuremap pixel
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
+
+ # Classification
+ class_index = 5 + self.nc
+ if self.nc > 1: # cls loss (only if multiple classes)
+ # t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t = torch.full_like(ps[:, 5:class_index], self.cn, device=device) # targets
+ t[range(n), tcls[i]] = self.cp
+ # lcls += self.BCEcls(ps[:, 5:], t) # BCE
+ lcls += self.BCEcls(ps[:, 5:class_index], t) # BCE
+
+ # theta Classification by Circular Smooth Label
+ t_theta = tgaussian_theta[i].type(ps.dtype) # target theta_gaussian_labels
+ ltheta += self.BCEtheta(ps[:, class_index:], t_theta)
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ ltheta *= self.hyp['theta']
+ bs = tobj.shape[0] # batch size
+
+ # return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+ return (lbox + lobj + lcls + ltheta) * bs, torch.cat((lbox, lobj, lcls, ltheta)).detach()
+
+ def build_targets(self, p, targets):
+ """
+ Args:
+ p (list[P3_out,...]): torch.Size(b, self.na, h_i, w_i, self.no), self.na means the number of anchors scales
+ targets (tensor): (n_gt_all_batch, [img_index clsid cx cy l s theta gaussian_θ_labels]) pixel
+
+ Return:non-normalized data
+ tcls (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
+ tbox (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 4) featuremap pixel
+ indices (list[P3_out,...]): len=self.na, tensor.size(4, n_filter2) [b, a, gj, gi]
+ anch (list[P3_out,...]): len=self.na, tensor.size(n_filter2, 2)
+ tgaussian_theta (list[P3_out,...]): len=self.na, tensor.size(n_filter2, hyp['cls_theta'])
+ # ttheta (list[P3_out,...]): len=self.na, tensor.size(n_filter2)
+ """
+ # Build targets for compute_loss()
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ # ttheta, tgaussian_theta = [], []
+ tgaussian_theta = []
+ # gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ feature_wh = torch.ones(2, device=targets.device) # feature_wh
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ # targets (tensor): (n_gt_all_batch, c) -> (na, n_gt_all_batch, c) -> (na, n_gt_all_batch, c+1)
+ # targets (tensor): (na, n_gt_all_batch, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index]])
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0], # tensor: (5, 2)
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ # gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain=[1, 1, w, h, w, h, 1, 1]
+ feature_wh[0:2] = torch.tensor(p[i].shape)[[3, 2]] # xyxy gain=[w_f, h_f]
+
+ # Match targets to anchors
+ # t = targets * gain # xywh featuremap pixel
+ t = targets.clone() # (na, n_gt_all_batch, c+1)
+ t[:, :, 2:6] /= self.stride[i] # xyls featuremap pixel
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # edge_ls ratio, torch.size(na, n_gt_all_batch, 2)
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare, torch.size(na, n_gt_all_batch)
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter; Tensor.size(n_filter1, c+1)
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy; (n_filter1, 2)
+ # gxi = gain[[2, 3]] - gxy # inverse
+ gxi = feature_wh[[0, 1]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m)) # (5, n_filter1)
+ t = t.repeat((5, 1, 1))[j] # (n_filter1, c+1) -> (5, n_filter1, c+1) -> (n_filter2, c+1)
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # (5, n_filter1, 2) -> (n_filter2, 2)
+ else:
+ t = targets[0] # (n_gt_all_batch, c+1)
+ offsets = 0
+
+ # Define, t (tensor): (n_filter2, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index])
+ b, c = t[:, :2].long().T # image, class; (n_filter2)
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ # theta = t[:, 6]
+ gaussian_theta_labels = t[:, 7:-1]
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, -1].long() # anchor indices 取整
+ # indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ indices.append((b, a, gj.clamp_(0, feature_wh[1] - 1), gi.clamp_(0, feature_wh[0] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ # ttheta.append(theta) # theta, θ∈[-pi/2, pi/2)
+ tgaussian_theta.append(gaussian_theta_labels)
+
+ # return tcls, tbox, indices, anch
+ return tcls, tbox, indices, anch, tgaussian_theta #, ttheta
+
+
+class ComputeLossOTA:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEtheta = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['theta_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+ BCEtheta = FocalLoss(BCEtheta, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.stride = det.stride # tensor([8., 16., 32., ...])
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ # self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.ssi = list(self.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.BCEtheta = BCEtheta
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets, imgs): # predictions, targets, model
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ ltheta = torch.zeros(1, device=device)
+ bs, as_, gjs, gis, targets, anchors, tgaussian_theta, indices = self.build_targets(p, targets, imgs)
+ pre_gen_gains = [torch.tensor(pp.shape, device=device)[[3, 2, 3, 2]] for pp in p]
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i] # image, anchor, gridy, gridx
+ b1, a1, gj1, gi1 = indices[i]
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
+ ps1 = pi[b1, a1, gj1, gi1]
+
+ # Regression
+ grid = torch.stack([gi, gj], dim=1)
+ pxy = ps[:, :2].sigmoid() * 2. - 0.5
+ # pxy = ps[:, :2].sigmoid() * 3. - 1.
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ selected_tbox = targets[i][:, 2:6] * pre_gen_gains[i]
+ selected_tbox[:, :2] -= grid
+ iou = bbox_iou(pbox.T, selected_tbox, x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
+
+ # Classification
+ selected_tcls = targets[i][:, 1].long()
+ class_index = 5 + self.nc
+ if self.nc > 1: # cls loss (only if multiple classes)
+ '''t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t[range(n), selected_tcls] = self.cp
+ lcls += self.BCEcls(ps[:, 5:], t) # BCE'''
+
+ t = torch.full_like(ps[:, 5:class_index], self.cn, device=device) # targets
+ t[range(n), selected_tcls] = self.cp
+ lcls += self.BCEcls(ps[:, 5:class_index], t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ t_theta = tgaussian_theta[i].type(ps1.dtype) # target theta_gaussian_labels
+ ltheta += self.BCEtheta(ps1[:, class_index:], t_theta)
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ ltheta *= self.hyp['theta']
+ bs = tobj.shape[0] # batch size
+
+ loss = lbox + lobj + lcls + ltheta
+ #return (lbox + lobj + lcls + ltheta) * bs, torch.cat((lbox, lobj, lcls, ltheta)).detach()
+ return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
+
+ def build_targets(self, p, targets, imgs):
+
+ # indices, anch = self.find_positive(p, targets)
+ indices, anch, tgaussian_theta = self.find_3_positive(p, targets)
+ # indices, anch = self.find_4_positive(p, targets)
+ # indices, anch = self.find_5_positive(p, targets)
+ # indices, anch = self.find_9_positive(p, targets)
+
+ matching_bs = [[] for pp in p]
+ matching_as = [[] for pp in p]
+ matching_gjs = [[] for pp in p]
+ matching_gis = [[] for pp in p]
+ matching_targets = [[] for pp in p]
+ matching_anchs = [[] for pp in p]
+
+ nl = len(p)
+
+ for batch_idx in range(p[0].shape[0]):
+
+ b_idx = targets[:, 0] == batch_idx
+ this_target = targets[b_idx]
+ if this_target.shape[0] == 0:
+ continue
+
+ txywh = this_target[:, 2:6] * imgs[batch_idx].shape[1]
+ txyxy = xywh2xyxy(txywh)
+
+ pxyxys = []
+ p_cls = []
+ p_obj = []
+ from_which_layer = []
+ all_b = []
+ all_a = []
+ all_gj = []
+ all_gi = []
+ all_anch = []
+
+ for i, pi in enumerate(p):
+ b, a, gj, gi = indices[i]
+ idx = (b == batch_idx)
+ b, a, gj, gi = b[idx], a[idx], gj[idx], gi[idx]
+ all_b.append(b)
+ all_a.append(a)
+ all_gj.append(gj)
+ all_gi.append(gi)
+ all_anch.append(anch[i][idx])
+ from_which_layer.append(torch.ones(size=(len(b),)) * i)
+
+ fg_pred = pi[b, a, gj, gi]
+ p_obj.append(fg_pred[:, 4:5])
+ p_cls.append(fg_pred[:, 5:])
+
+ grid = torch.stack([gi, gj], dim=1)
+ pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i] # / 8.
+ # pxy = (fg_pred[:, :2].sigmoid() * 3. - 1. + grid) * self.stride[i]
+ pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i] # / 8.
+ pxywh = torch.cat([pxy, pwh], dim=-1)
+ pxyxy = xywh2xyxy(pxywh)
+ pxyxys.append(pxyxy)
+
+ pxyxys = torch.cat(pxyxys, dim=0)
+ if pxyxys.shape[0] == 0:
+ continue
+ p_obj = torch.cat(p_obj, dim=0)
+ p_cls = torch.cat(p_cls, dim=0)
+ from_which_layer = torch.cat(from_which_layer, dim=0)
+ all_b = torch.cat(all_b, dim=0)
+ all_a = torch.cat(all_a, dim=0)
+ all_gj = torch.cat(all_gj, dim=0)
+ all_gi = torch.cat(all_gi, dim=0)
+ all_anch = torch.cat(all_anch, dim=0)
+
+ pair_wise_iou = box_iou(txyxy, pxyxys)
+
+ pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
+
+ top_k, _ = torch.topk(pair_wise_iou, min(10, pair_wise_iou.shape[1]), dim=1)
+ dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
+
+ gt_cls_per_image = (
+ F.one_hot(this_target[:, 1].to(torch.int64), self.nc)
+ .float()
+ .unsqueeze(1)
+ .repeat(1, pxyxys.shape[0], 181)
+ )
+
+ num_gt = this_target.shape[0]
+
+ cls_preds_ = (
+ p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
+ * p_obj.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_()
+ )
+
+ y = cls_preds_.sqrt_()
+ pair_wise_cls_loss = F.binary_cross_entropy_with_logits(
+ torch.log(y / (1 - y)), gt_cls_per_image, reduction="none"
+ ).sum(-1)
+ del cls_preds_
+
+ cost = (
+ pair_wise_cls_loss
+ + 3.0 * pair_wise_iou_loss
+ )
+
+ matching_matrix = torch.zeros_like(cost)
+
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False
+ )
+ matching_matrix[gt_idx][pos_idx] = 1.0
+
+ del top_k, dynamic_ks
+ anchor_matching_gt = matching_matrix.sum(0)
+ if (anchor_matching_gt > 1).sum() > 0:
+ _, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
+ matching_matrix[:, anchor_matching_gt > 1] *= 0.0
+ matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
+ fg_mask_inboxes = matching_matrix.sum(0) > 0.0
+ matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
+
+ from_which_layer = from_which_layer[fg_mask_inboxes]
+ all_b = all_b[fg_mask_inboxes]
+ all_a = all_a[fg_mask_inboxes]
+ all_gj = all_gj[fg_mask_inboxes]
+ all_gi = all_gi[fg_mask_inboxes]
+ all_anch = all_anch[fg_mask_inboxes]
+
+ this_target = this_target[matched_gt_inds]
+
+ for i in range(nl):
+ layer_idx = from_which_layer == i
+ matching_bs[i].append(all_b[layer_idx])
+ matching_as[i].append(all_a[layer_idx])
+ matching_gjs[i].append(all_gj[layer_idx])
+ matching_gis[i].append(all_gi[layer_idx])
+ matching_targets[i].append(this_target[layer_idx])
+ matching_anchs[i].append(all_anch[layer_idx])
+
+ for i in range(nl):
+ if matching_targets[i] != []:
+ matching_bs[i] = torch.cat(matching_bs[i], dim=0)
+ matching_as[i] = torch.cat(matching_as[i], dim=0)
+ matching_gjs[i] = torch.cat(matching_gjs[i], dim=0)
+ matching_gis[i] = torch.cat(matching_gis[i], dim=0)
+ matching_targets[i] = torch.cat(matching_targets[i], dim=0)
+ matching_anchs[i] = torch.cat(matching_anchs[i], dim=0)
+ else:
+ matching_bs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_as[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_gjs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_gis[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_targets[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+ matching_anchs[i] = torch.tensor([], device='cuda:0', dtype=torch.int64)
+
+ return matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs, tgaussian_theta, indices
+
+ def find_3_positive(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ '''na, nt = self.na, targets.shape[0] # number of anchors, targets
+ indices, anch = [], []
+ gain = torch.ones(7, device=targets.device).long() # normalized to gridspace gain
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0],
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1. / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1. < g) & (gxy > 1.)).T
+ l, m = ((gxi % 1. < g) & (gxi > 1.)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ b, c = t[:, :2].long().T # image, class
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, 6].long() # anchor indices
+ indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ anch.append(anchors[a]) # anchors
+
+ return indices, anch'''
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ # ttheta, tgaussian_theta = [], []
+ tgaussian_theta = []
+ # gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ feature_wh = torch.ones(2, device=targets.device) # feature_wh
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ # targets (tensor): (n_gt_all_batch, c) -> (na, n_gt_all_batch, c) -> (na, n_gt_all_batch, c+1)
+ # targets (tensor): (na, n_gt_all_batch, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index]])
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0], # tensor: (5, 2)
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ # gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain=[1, 1, w, h, w, h, 1, 1]
+ feature_wh[0:2] = torch.tensor(p[i].shape)[[3, 2]] # xyxy gain=[w_f, h_f]
+
+ # Match targets to anchors
+ # t = targets * gain # xywh featuremap pixel
+ t = targets.clone() # (na, n_gt_all_batch, c+1)
+ t[:, :, 2:6] /= self.stride[i] # xyls featuremap pixel
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # edge_ls ratio, torch.size(na, n_gt_all_batch, 2)
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare, torch.size(na, n_gt_all_batch)
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter; Tensor.size(n_filter1, c+1)
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy; (n_filter1, 2)
+ # gxi = gain[[2, 3]] - gxy # inverse
+ gxi = feature_wh[[0, 1]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m)) # (5, n_filter1)
+ t = t.repeat((5, 1, 1))[j] # (n_filter1, c+1) -> (5, n_filter1, c+1) -> (n_filter2, c+1)
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j] # (5, n_filter1, 2) -> (n_filter2, 2)
+ else:
+ t = targets[0] # (n_gt_all_batch, c+1)
+ offsets = 0
+
+ # Define, t (tensor): (n_filter2, [img_index, clsid, cx, cy, l, s, theta, gaussian_θ_labels, anchor_index])
+ b, c = t[:, :2].long().T # image, class; (n_filter2)
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ # theta = t[:, 6]
+ gaussian_theta_labels = t[:, 7:-1]
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, -1].long() # anchor indices 取整
+ # indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ indices.append(
+ (b, a, gj.clamp_(0, feature_wh[1] - 1), gi.clamp_(0, feature_wh[0] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ # ttheta.append(theta) # theta, θ∈[-pi/2, pi/2)
+ tgaussian_theta.append(gaussian_theta_labels)
+
+ # return tcls, tbox, indices, anch
+ return indices, anch, tgaussian_theta # , ttheta
\ No newline at end of file
diff --git a/utils/metrics.py b/utils/metrics.py
new file mode 100644
index 0000000..c80bfa2
--- /dev/null
+++ b/utils/metrics.py
@@ -0,0 +1,344 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+
+ if n_p == 0 or n_l == 0:
+ continue
+ else:
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = {i: v for i, v in enumerate(names)} # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = f1.mean(0).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype('int32')
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(np.int16)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
+ labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
+ box2 = box2.T
+
+ # Get the coordinates of bounding boxes
+ if x1y1x2y2: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+ else: # transform from xywh to xyxy
+ b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
+ b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
+ b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
+ b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
+ (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ else:
+ return iou - rho2 / c2 # DIoU
+ else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU
+ else:
+ return iou # IoU
+
+
+def box_iou(box1, box2):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ def box_area(box):
+ # box = 4xn
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+ area1 = box_area(box1.T)
+ area2 = box_area(box2.T)
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
+ return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
+
+
+def bbox_ioa(box1, box2, eps=1E-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ box2 = box2.transpose()
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f hbb mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = py.mean(0)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
diff --git a/utils/nms_rotated/__init__.py b/utils/nms_rotated/__init__.py
new file mode 100644
index 0000000..9768d17
--- /dev/null
+++ b/utils/nms_rotated/__init__.py
@@ -0,0 +1,3 @@
+from .nms_rotated_wrapper import obb_nms, poly_nms
+
+__all__ = ['obb_nms', 'poly_nms']
diff --git a/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc b/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000..6ec2e44
Binary files /dev/null and b/utils/nms_rotated/__pycache__/__init__.cpython-37.pyc differ
diff --git a/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc b/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc
new file mode 100644
index 0000000..ef94b65
Binary files /dev/null and b/utils/nms_rotated/__pycache__/nms_rotated_wrapper.cpython-37.pyc differ
diff --git a/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd b/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd
new file mode 100644
index 0000000..ec6c224
Binary files /dev/null and b/utils/nms_rotated/build/lib.win-amd64-3.7/nms_rotated_ext.pyd differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps
new file mode 100644
index 0000000..bb12204
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_deps differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log
new file mode 100644
index 0000000..b0f0c7f
--- /dev/null
+++ b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/.ninja_log
@@ -0,0 +1,9 @@
+# ninja log v5
+2 3053 6788011957379629 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 230f582cc4ead385
+2 6945 6788011996267406 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 91ac4870d9dfe29f
+3 3474 6789732946931915 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 1256c1d3ee98246c
+1 7591 6789732988080942 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 62d6bb08f7474408
+3 3117 6789734007496664 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj 230f582cc4ead385
+2 6897 6789734045285714 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj 91ac4870d9dfe29f
+3 8105 6789761451993078 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj de5e56148eafc714
+1 8722 6789761458150954 C:/Users/Administrator/Desktop/yolov5_obb/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj 8782fd757258be9d
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja
new file mode 100644
index 0000000..6700a49
--- /dev/null
+++ b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/build.ninja
@@ -0,0 +1,28 @@
+ninja_required_version = 1.3
+cxx = cl
+nvcc = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin\nvcc
+
+cflags = /nologo /O2 /W3 /GL /DNDEBUG /MD /MD /wd4819 /wd4251 /wd4244 /wd4267 /wd4275 /wd4018 /wd4190 /EHsc -DWITH_CUDA -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\torch\csrc\api\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\TH -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\THC "-IC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include" -ID:\anaconda3\envs\pytorch\include -ID:\anaconda3\envs\pytorch\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.29.30133\include" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\shared" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\winrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\cppwinrt"
+post_cflags = -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=nms_rotated_ext -D_GLIBCXX_USE_CXX11_ABI=0 /std:c++14
+cuda_cflags = --use-local-env -Xcompiler /MD -Xcompiler /wd4819 -Xcompiler /wd4251 -Xcompiler /wd4244 -Xcompiler /wd4267 -Xcompiler /wd4275 -Xcompiler /wd4018 -Xcompiler /wd4190 -Xcompiler /EHsc -Xcudafe --diag_suppress=base_class_has_different_dll_interface -Xcudafe --diag_suppress=field_without_dll_interface -Xcudafe --diag_suppress=dll_interface_conflict_none_assumed -Xcudafe --diag_suppress=dll_interface_conflict_dllexport_assumed -DWITH_CUDA -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\torch\csrc\api\include -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\TH -ID:\anaconda3\envs\pytorch\lib\site-packages\torch\include\THC "-IC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include" -ID:\anaconda3\envs\pytorch\include -ID:\anaconda3\envs\pytorch\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.29.30133\include" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\shared" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\um" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\winrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\cppwinrt"
+cuda_post_cflags = -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=nms_rotated_ext -D_GLIBCXX_USE_CXX11_ABI=0 -gencode=arch=compute_80,code=sm_80
+ldflags =
+
+rule compile
+ command = cl /showIncludes $cflags -c $in /Fo$out $post_cflags
+ deps = msvc
+
+rule cuda_compile
+ command = $nvcc $cuda_cflags -c $in -o $out $cuda_post_cflags
+
+
+
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_cpu.obj: compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_cpu.cpp
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_cuda.obj: cuda_compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_cuda.cu
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/nms_rotated_ext.obj: compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\nms_rotated_ext.cpp
+build C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\build\temp.win-amd64-3.7\Release\src/poly_nms_cuda.obj: cuda_compile C$:\Users\Administrator\Desktop\yolov5_obb\utils\nms_rotated\src\poly_nms_cuda.cu
+
+
+
+
+
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj
new file mode 100644
index 0000000..9e1c6d5
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cpu.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj
new file mode 100644
index 0000000..3980701
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_cuda.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp
new file mode 100644
index 0000000..b834ae3
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.exp differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib
new file mode 100644
index 0000000..ff8a16a
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.lib differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj
new file mode 100644
index 0000000..98c1c5f
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/nms_rotated_ext.obj differ
diff --git a/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj
new file mode 100644
index 0000000..d9ba8f4
Binary files /dev/null and b/utils/nms_rotated/build/temp.win-amd64-3.7/Release/src/poly_nms_cuda.obj differ
diff --git a/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO b/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO
new file mode 100644
index 0000000..83acf87
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/PKG-INFO
@@ -0,0 +1,9 @@
+Metadata-Version: 2.1
+Name: nms-rotated
+Version: 0.0.0
+Summary: UNKNOWN
+License: UNKNOWN
+Platform: UNKNOWN
+
+UNKNOWN
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt b/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt
new file mode 100644
index 0000000..8e475c6
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/SOURCES.txt
@@ -0,0 +1,10 @@
+setup.py
+nms_rotated.egg-info/PKG-INFO
+nms_rotated.egg-info/SOURCES.txt
+nms_rotated.egg-info/dependency_links.txt
+nms_rotated.egg-info/not-zip-safe
+nms_rotated.egg-info/top_level.txt
+src/nms_rotated_cpu.cpp
+src/nms_rotated_cuda.cu
+src/nms_rotated_ext.cpp
+src/poly_nms_cuda.cu
\ No newline at end of file
diff --git a/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt b/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe b/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/not-zip-safe
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated.egg-info/top_level.txt b/utils/nms_rotated/nms_rotated.egg-info/top_level.txt
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated.egg-info/top_level.txt
@@ -0,0 +1 @@
+
diff --git a/utils/nms_rotated/nms_rotated_ext.pyd b/utils/nms_rotated/nms_rotated_ext.pyd
new file mode 100644
index 0000000..ec6c224
Binary files /dev/null and b/utils/nms_rotated/nms_rotated_ext.pyd differ
diff --git a/utils/nms_rotated/nms_rotated_wrapper.py b/utils/nms_rotated/nms_rotated_wrapper.py
new file mode 100644
index 0000000..b2412e5
--- /dev/null
+++ b/utils/nms_rotated/nms_rotated_wrapper.py
@@ -0,0 +1,79 @@
+import numpy as np
+import torch
+
+from . import nms_rotated_ext
+
+
+def obb_nms(dets, scores, iou_thr, device_id=None):
+ """
+ RIoU NMS - iou_thr.
+ Args:
+ dets (tensor/array): (num, [cx cy w h θ]) θ∈[-pi/2, pi/2)
+ scores (tensor/array): (num)
+ iou_thr (float): (1)
+ Returns:
+ dets (tensor): (n_nms, [cx cy w h θ])
+ inds (tensor): (n_nms), nms index of dets
+ """
+ if isinstance(dets, torch.Tensor):
+ is_numpy = False
+ dets_th = dets
+ elif isinstance(dets, np.ndarray):
+ is_numpy = True
+ device = 'cpu' if device_id is None else f'cuda:{device_id}'
+ dets_th = torch.from_numpy(dets).to(device)
+ else:
+ raise TypeError('dets must be eithr a Tensor or numpy array, '
+ f'but got {type(dets)}')
+
+ if dets_th.numel() == 0: # len(dets)
+ inds = dets_th.new_zeros(0, dtype=torch.int64)
+ else:
+ # same bug will happen when bboxes is too small
+ too_small = dets_th[:, [2, 3]].min(1)[0] < 0.001 # [n]
+ if too_small.all(): # all the bboxes is too small
+ inds = dets_th.new_zeros(0, dtype=torch.int64)
+ else:
+ ori_inds = torch.arange(dets_th.size(0)) # 0 ~ n-1
+ ori_inds = ori_inds[~too_small]
+ dets_th = dets_th[~too_small] # (n_filter, 5)
+ scores = scores[~too_small]
+
+ inds = nms_rotated_ext.nms_rotated(dets_th, scores, iou_thr)
+ inds = ori_inds[inds]
+
+ if is_numpy:
+ inds = inds.cpu().numpy()
+ return dets[inds, :], inds
+
+
+def poly_nms(dets, iou_thr, device_id=None):
+ if isinstance(dets, torch.Tensor):
+ is_numpy = False
+ dets_th = dets
+ elif isinstance(dets, np.ndarray):
+ is_numpy = True
+ device = 'cpu' if device_id is None else f'cuda:{device_id}'
+ dets_th = torch.from_numpy(dets).to(device)
+ else:
+ raise TypeError('dets must be eithr a Tensor or numpy array, '
+ f'but got {type(dets)}')
+
+ if dets_th.device == torch.device('cpu'):
+ raise NotImplementedError
+ inds = nms_rotated_ext.nms_poly(dets_th.float(), iou_thr)
+
+ if is_numpy:
+ inds = inds.cpu().numpy()
+ return dets[inds, :], inds
+
+if __name__ == '__main__':
+ rboxes_opencv = torch.tensor(([136.6, 111.6, 200, 100, -60],
+ [136.6, 111.6, 100, 200, -30],
+ [100, 100, 141.4, 141.4, -45],
+ [100, 100, 141.4, 141.4, -45]))
+ rboxes_longedge = torch.tensor(([136.6, 111.6, 200, 100, -60],
+ [136.6, 111.6, 200, 100, 120],
+ [100, 100, 141.4, 141.4, 45],
+ [100, 100, 141.4, 141.4, 135]))
+
\ No newline at end of file
diff --git a/utils/nms_rotated/setup.py b/utils/nms_rotated/setup.py
new file mode 100644
index 0000000..a3ee967
--- /dev/null
+++ b/utils/nms_rotated/setup.py
@@ -0,0 +1,54 @@
+#!/usr/bin/env python
+import os
+import subprocess
+import time
+from setuptools import find_packages, setup
+
+import torch
+from torch.utils.cpp_extension import (BuildExtension, CppExtension,
+ CUDAExtension)
+def make_cuda_ext(name, module, sources, sources_cuda=[]):
+
+ define_macros = []
+ extra_compile_args = {'cxx': []}
+
+ if torch.cuda.is_available() or os.getenv('FORCE_CUDA', '0') == '1':
+ define_macros += [('WITH_CUDA', None)]
+ extension = CUDAExtension
+ extra_compile_args['nvcc'] = [
+ '-D__CUDA_NO_HALF_OPERATORS__',
+ '-D__CUDA_NO_HALF_CONVERSIONS__',
+ '-D__CUDA_NO_HALF2_OPERATORS__',
+ ]
+ sources += sources_cuda
+ else:
+ print(f'Compiling {name} without CUDA')
+ extension = CppExtension
+ # raise EnvironmentError('CUDA is required to compile MMDetection!')
+
+ return extension(
+ name=f'{module}.{name}',
+ sources=[os.path.join(*module.split('.'), p) for p in sources],
+ define_macros=define_macros,
+ extra_compile_args=extra_compile_args)
+
+# python setup.py develop
+if __name__ == '__main__':
+ #write_version_py()
+ setup(
+ name='nms_rotated',
+ ext_modules=[
+ make_cuda_ext(
+ name='nms_rotated_ext',
+ module='',
+ sources=[
+ 'src/nms_rotated_cpu.cpp',
+ 'src/nms_rotated_ext.cpp'
+ ],
+ sources_cuda=[
+ 'src/nms_rotated_cuda.cu',
+ 'src/poly_nms_cuda.cu',
+ ]),
+ ],
+ cmdclass={'build_ext': BuildExtension},
+ zip_safe=False)
\ No newline at end of file
diff --git a/utils/nms_rotated/src/box_iou_rotated_utils.h b/utils/nms_rotated/src/box_iou_rotated_utils.h
new file mode 100644
index 0000000..c017e17
--- /dev/null
+++ b/utils/nms_rotated/src/box_iou_rotated_utils.h
@@ -0,0 +1,360 @@
+// Mortified from
+// https://github.com/facebookresearch/detectron2/tree/master/detectron2/layers/csrc/box_iou_rotated
+// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+#pragma once
+
+#include