他の言語で読む: English.

このコードパターンでは、Watson Discovery Serviceのデータを照会して操作するWebアプリケーションの実例を紹介します。 このWebアプリケーションには、独自のWatson Discovery Serviceアプリケーションを開発するための出発点として使用できる複数のUIコンポーネントが含まれています。
Watson Discovery Service を利用する最大の利点は、コグニティブ・エンリッチを適用してデータから洞察を引き出す、その強力なアナリティクス・エンジンにあります。このコード・パターンのアプリでは、Watson Discovery Service アナリティクス・エンジンのエンリッチ機能を、フィルター、リスト、グラフを使用して提示する例を説明します。データには主に以下のエンリッチが適用されます。
- エンティティー: 人、企業、組織、都市など
- カテゴリー: 深さ最大 5 レベルのカテゴリー階層にデータを分類
- 概念: 必ずしもデータ内で参照されていない一般概念を識別
- キーワード: データのインデックスや検索で通常使用される重要なトピック
- 感情: 各ドキュメントの全体的な感情 (肯定的または否定的)
このコードパターンでは、テキサス州オースティンにあるAirbnb宿泊施設のレビューを含むデータを使用します。
このコード・パターンをひと通り完了すると、以下の方法がわかるようになります。
- Watson Discovery Service にデータをロードしてエンリッチする
- Watson Discovery Service 内でデータのクエリーを実行し、データを処理する
- Watson Discovery Service によってエンリッチされたデータを示す UI コンポーネントを作成する
- よく使われている JavaScript テクノロジーを使用して、Watson Discovery Service のデータとエンリッチを備えた完全な Web アプリを構築する

- Airbnb レビューの JSON ファイルを Discovery コレクションに追加します。
- アプリの UI を使用してバックエンド・サーバーとやり取りします。フロントエンドのアプリ UI が React を使用して検索結果をレンダリングします。この UI は、バックエンドで使用したすべてのビューを再利用してサーバー・サイドのレンダリングを行うことができます。フロントエンドは semantic-ui-react コンポーネントを使用していて、レスポンシブなものとなっています。
- Discovery が入力を処理してバックエンド・サーバーにルーティングします。バックエンド・サーバーの役目は、ブラウザーに表示するビューをレンダリングすることです。バックエンド・サーバーは Express を使用して作成されており、React で作成されたビューを、express-react-views エンジンを使用してレンダリングします。
- バックエンド・サーバーがユーザー・リクエストを Watson Discovery Service に送信します。バックエンド・サーバーはプロキシー・サーバーとして機能し、フロントエンドからのクエリーを Watson Discovery Service API に転送する一方で、機密性の高い API キーをユーザーから隠します。
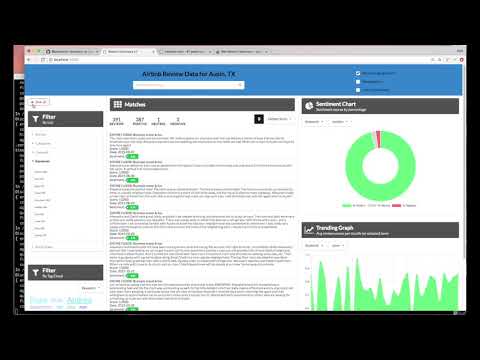
ここでは、メインのUI画面の概略を示し、その後に各UIコンポーネントとそれに関連するアクションを説明します。

- 検索フィールドと検索パラメータ: 検索条件に基づいて結果を返します。 検索パラメータは、ユーザーが値を入力する方法、表示方法、一致数を制限するために使用されます。
- リストフィルタ: 検索結果に適用されるフィルタの複数のドロップダウンリスト。 各ドロップダウンリストには、結果に関連するエンティティ、カテゴリ、概念、およびキーワードが含まれています。 ドロップダウンフィルター項目ごとに、一致数も表示されます。 ユーザーがフィルタ項目を選択すると、新しい検索が実行され、検索結果パネル(#3)が更新されます。 選択したフィルタ項目は、タグクラウド(#4)に表示される内容にも影響します。
- 検索結果とページ区切りメニュー: 結果項目のページ(ページあたり5個など)と、結果項目のページをスクロールできるペー区切りメニューが表示されます。 ドロップダウンメニューもあり、ユーザーは日付、スコア、および感情値に基づいてエントリを並べ替えることができます。
- タグクラウド・フィルタ:リストフィルタ (#2) に似ていますが、異なる形式です。一セットのフィルタ項目(エンティティ、カテゴリ、概念またはキーワードのいずれか)を一度に表示できます。 ユーザーは、クラウド内の項目を選択/選択解除してフィルターをオン/オフすることができます。 両方のフィルタ表示(#2と#4)で適用されたフィルタは常に同期します。
- トレンドチャート: 特定のエンティティ、カテゴリ、コンセプト、またはキーワードに対する感情傾向を時間の経過とともに示すグラフ。データには現在の検索結果が反映されます。
- 感情チャート: 選択したエンティティ、カテゴリ、コンセプトまたはキーワードの中立的、否定的なレビューの合計割合を示すドーナツチャート。データには現在の検索結果が反映されます。
注: プロジェクト構造については、 DEVELOPING.md を参照してください。
- Watson Discovery: 大量のデータを検索するとともに、データからパターンや傾向を読み取り、適切な意思決定を支援します。
- Node.js: サーバー側のJavaScriptコードを実行するためのオープンソースのJavaScriptランタイム環境。
- React: ユーザーインターフェイスを構築するためのJavaScriptライブラリ。
- Express: APIとWebサーバーを作成するための一般的で最小限のWebフレームワーク。
- Semantic UI React: セマンティックUIコンポーネントためのReact実装。
- Chart.js: チャート用のJavaScriptパッケージ。
- Jest: JavaScript用のテストフレームワーク。
Deploy to IBM Cloud ボタンを使用するか、サービスを作成してローカルで実行してください。

-
上の
Deploy to IBM Cloudボタンを押し、Deployをクリックします。 -
ツールチェーンでは、
配信パイプライン(Delivery Pipeline)をクリックして、アプリケーションをデプロイします。 いったんデプロイされると、アプリを表示(View App)をクリックすることでアプリを表示できます。

- 作成および設定されたアプリケーションとサービスを確認するには、IBM Cloudダッシュボードを使用します。アプリケーション名は、固有の接尾辞を持つ
watson-discovery-uiです。以下のサービスが作成され、wdui-接頭辞によって簡単に見つけることができます。- wdui-discovery-service
注: これらの手順は
Deploy to IBM Cloudボタンを使用する代わりに、ローカルで実行する場合にのみ必要です
$ git clone https://github.com/IBM/watson-discovery-ui
以下のサービスを作成する:
Watson Discovery ツールを起動します。 新しい data collection を作成し、ユニークな名前を付けます。

新しいコレクションのデータパネルの Configuration の下にある Switch ボタンをクリックして、データをエンリッチメントするためキーワードを抽出する新しい設定ファイルを作成します。この設定ファイルにユニークな名前を付けます。

注: これを行わないと、アプリに
keywordsが表示されなくなります。
新しいコレクションのデータパネルの Add data to this collection の下の Drag and drop your documents here or browse from computer を使用して、data/airbnb/ から抽出したjsonファイルを読み込ませます。

次のステップで
.envファイルに environment_id と collection_id を保存します。
cp env.sample .env
.envファイルを編集して必要な設定をします。
# Replace the credentials here with your own.
# Rename this file to .env before starting the app.
# Watson Discovery
DISCOVERY_USERNAME=<add_discovery_username>
DISCOVERY_PASSWORD=<add_discovery_password>
DISCOVERY_ENVIRONMENT_ID=<add_discovery_environment>
DISCOVERY_COLLECTION_ID=<add_discovery_collection>
# Run locally on a non-default port (default is 3000)
# PORT=3000
- Node.js ランタイムと NPM をインストールします。
- アプリを起動するため
npm installとnpm startを実行します。 - ブラウザに
localhost:3000を指定してUIにアクセスしてください。
注: 必要に応じてサーバーホストはapp.js内で変更でき、
PORTは.envファイルで設定することができます。

-
Error: Environment {GUID} is still not active, retry once status is active
これは、最初の実行時に起こりがちです。Discovery環境が完全に作成される前にアプリが開始しようとしました。1〜2分の時間をおいてください。その後で再起動時すれば動作します。
Deploy to IBM Cloudを使用した場合、再起動は自動的に行われます。 -
Error: Only one free environment is allowed per organization
無料トライアルで作業する場合、小さな無料のディスカバリー環境が作成されます。既にDiscovery環境を使用している場合、その実行は失敗するでしょう。 Discoveryを使用していない場合は、古いサービスをどれか削除してください。それ以外の場合は .envファイルの DISCOVERY_ENVIRONMENT_ID 値を使用して、使用する環境のIDをアプリに通知します。この環境では、デフォルト構成を使用してコレクションが作成されます。
-
Error when loading files into Discovery
2000のドキュメントファイルをDiscoveryにすべて一度に読み込むと、「ビジー」エラーが発生することがあります。この場合には、何度かに分けてファイルを読み込んでください。
-
No keywords appear in the app
これは、データ収集に適切な構成ファイルが割り当てられていないことが原因です。 上記の Step 3 を参照してください。
- Demo on Youtube: ビデオを観る。
- Watson Node.js SDK: Watson Node SDKをダウンロードする。
- Artificial Intelligence コードパターン: このコードパターンを気に入りましたか? AI Code コードパターン から関連パターンを参照してください。
- AI and Data コードパターン・プレイリスト: コードパターンに関係するビデオ全ての プレイリスト です。
- With Watson: With Watson プログラム は、自社のアプリケーションに Watson テクノロジーを有効的に組み込んでいる開発者や企業に、ブランディング、マーケティング、テクニカルに関するリソースを提供するプログラムです。