São conjuntos de passos finitos e organizados que, quando executados, realizam uma tarefa. 1, 2.
É uma tradição estatística que provê ferramentas conceituais e computacionais para descobrir padrões para o desenvolvimento e refinamento de hipóteses. 1.(Behrens, 1997)
É a capacidade do sistema em aprender padrões com dados de entrada, mesmo não sendo fornecido um retorno evidente. Tem como tarefa mais recorrente, o reconhecimento de grupos com os dados de entrada potencialmente úteis. 1.(Russel e Norvig, 2013).
O objetivo é alcançado através da aprendizagem dos dados de entrada e seus respectivos resultados fornecidos por um supervisor. Em linhas gerais, o sistema observa a amostra de dados em pares de entrada e saída e aprende uma função que faz a rota entre estes pares. 1.(Alpaydin, 2010).
O aprendizado por reforço é uma área do aprendizado de máquina que lida com a maneira como os agentes de software devem executar ações em um ambiente de modo a maximizar alguma noção de recompensa cumulativa Reinforcement learning.
Uma árvore de decisão é uma técnica de aprendizado de máquina que é representada por uma árvore que recebe como entrada um vetor de características e retorna uma decisão baseada nesses valores. A decisão fornecida pelo algoritmo é obtido através da execução de uma sequência de testes. Cada nó interno na árvore corresponde a um teste do valor de um dos atributos do vetor de entrada, e os ramos do nó são rotulados com os valores possíveis do atributo. Cada nó da folha na árvore especifica um valor a ser retornado pela Árvore, ou seja, a decisão final (Russel e Norvig, 2013).
Na imagem abaixo temos o exemplo da representação de uma ávore de decisão para decidir se um cliente deve aguardar por uma mesa no restaurante.

Abaixo temos algumas possíveis entradas para a árvore de decisão, representada acima, e seus respectivos resultados.

É um ramo estudado em estatística, psicologia, neurociência e ciência da computação que está diretamente ligado a aprendizado de máquina e inteligência artificial. É um método de programação de agentes que devem aprender a se comportar em um ambiente dinâmico através de interações de “tentativa e erro”, conhecidas também como premiações e punições, sem a necessidade de especificar como uma tarefa deve ser realizada. A abordagem que é utilizada nesse trabalho é feita usando técnicas de estatísticas e métodos de programação dinâmica, buscando estimar qual a vantagem em se tomar determinadas ações em diferentes estados do ambiente dado um objetivo. 1, 2.
Comumente conhecido como NoSQL (Not Only SQL - Não Somente SQL, tradução literal) é um termo genérico para banco de dados não-relacionais, por exemplo, Document Store (MongoDB), Graph Databases (Neo4j), etc. Uma lista desses softwares pode ser encontrada em: http://nosql-database.org/ Recomenda-se mais estudos em: 1. NoSQL databases overview e 2. Gessert et. al. 2016
O conceito de bancos de dados relacionais está na forma em que eles são implementados, que estabelece uma relação lógica entre os dados, para que a repetição de dados (redundância) seja a menor possível, economizando espaço em disco e aumentando a velocidade de consulta dos dados.
Um banco de dados relacional possui como entidade central tabelas, onde as colunas armazenam os tipos de dados e as linhas um caso específico de dados, sendo chamada de tupla ou registro. Também é importante o conceito de chave, que identifica unicamente um registro.
O modelo relacional tem sua origem em 1970 quando um matemático da IBM chamado Edgar Frank Codd publicou um artigo onde foi definido formalmente o modelo relacional. Em 1985 o mesmo matemático publicou um artigo com as 13 regras que caracterizam um modelo de dados relacional. 1
É uma característica de uma técnica estatística ou de seus resultados, pelo que o valor esperado dos resultados difere do parâmetro quantitativo subjacente verdadeiro sendo estimado. Em português, viés. 1. Bias, 2. Viés
É um termo que descreve o grande volume de dados - estruturados e não estruturados - que sobrecarrega as empresas diariamente. Pode ser usado para obter insights que levam a decisões melhores e ações estratégicas de negócio. Normalmente tem a definição separada em 3 V's:
-
Volume: A quantidade de dado importa. Com big data você deve que processar grandes quantidades de dados para obter resultados concretos, o tamanho exato varia de empresa para empresa, podendo ser terabytes ou zetabytes.
-
Velocidade: Todos os dados devem ser transmitidos em grandes velocidades e tratados em um tempo baixo. Normalmente a velocidade está diretamente ligada a memória e escrita em disco.
-
Variedade: Os dados são gerados em inúmeros formatos, desde dados estruturados (bancos de dados normais) a não estruturados (textos, e-mails, som, vídeo, fotos, tweets e etc...)
Também são considerados dois V's adicionais:
-
Veracidade: É a garantia da qualidade do dado, ou seja, garantir que as informações sejam verdadeiras para a análise.
-
Valor: Tudo o que for feito com o big data tem que gerar um valor no final, não adianta ler uma quantidade massiva de dados sem gerar algum valor no fim. 1 2 3
O coeficiente de determinação (R2) é uma estimativa da qualidade de um modelo de regressão. Usualmente R2 é interpretado como o quanto da variância de uma variável independente pode ser capturada (dado o modelo) a partir das variáveis dependentes 1. Para modelos lineares, R2 é usualmente definido como sendo o quadrado do coeficiente de correlação da amostra, sendo, neste caso, uma medida de o quanto a variável independente pode ser explicada a partir de uma combinação linear das variáveis dependentes 2.
É o tipo de tarefa de aprendizado de máquina em que as entradas são mapeadas em saídas baseadas nos pares examplos de entrada-saída. O desafio enfrentado pelo algoritmo classificador é ajustar uma função que possa separar os exemplos de entrada de forma a maximizar a quantidade de saídas corretas Supervised learning. Uma abstração seria ter como entrada um conjunto de informações a respeito do tecido da mama extraídos da mamografia. A saída neste caso poderia ser tecido normal, tumor maligno ou tumor benigno (podem existir mais categorias). O algoritmo de classificação deve inferir a cerca dos dados de forma a reconhecer o padrão de dados de entrada de forma a determinar a saída que mais se aproxime do parão identificado.
É a classificação não supervisionada de padrões (observações, itens de dados ou classes) em grupos (clusters). Intuitivamente, itens dentro de um cluster válido são mais similares uns aos outros do que itens de outros clusters (Jain et. al, 1999).
É o fator multiplicativo de um termo em uma expressão, sendo geralmente um número, e que não se confunde com as variáveis da expressão.1
É um gerenciador de pacotes, dependências e ambientes para qualquer idioma - Python, R, Ruby, Lua, Scala, Java, JavaScript, C / C ++, FORTRAN. ref
É uma organização no github contendo repositórios de receitas conda. Graças a alguns incríveis provedores de integração contínua (AppVeyor, CircleCI e TravisCI), cada repositório, também conhecido como feedstock, constrói automaticamente sua própria receita de forma limpa e repetitiva no Windows, Linux e OSX. 1
Correlação é a medida estatística que descreve a associação entre variáveis randômicas. Frequentemente, correlação é o primeiro passo para entender relacionamentos e consequentemente construir melhores modelos estatísticos. 1 Para interpretar o coeficiente é preciso saber que 1 significa que a correlação entre as variáveis é perfeita positiva e -1 significa que é perfeita negativa. Se o coeficiente for igual a 0 significa que as variáveis não dependem uma da outra.1
Em probabilidade, a covariância de duas variáveis X e Y é uma medida da variabilidade conjunta destas variáveis aleatórias. Se as variáveis tem covariância positiva tendem a mostrar um comportamento semelhante, ou seja, os menores (maiores) valores da variável X corresponde aos menores (maiores) da variável Y . Se a covariância é negativa então as variáveis tendem a mostrar um comportamento oposto, ou seja, os menores (maiores) valores da variável X corresponde aos maiores (menores) da variável Y. Assim, podemos ver que o sinal da covariância mostra a tendência na relação linear entre as variáveis. 1.
São conjuntos de dados tabulados, onde para cada individuo são denotadas diversas características. Cada coluna corresponde a uma varíavel, e cada linha é o conjunto de caracteristicas do individuo. Os valores(itens) dessa tabela são chamados dados. wiki
O processo de tradução de dados em termos leigos para influenciar uma decisão ou ação de negócios. 1 Para que o Data Storytelling seja bem-sucedido, a pessoa deve ter boas habilidades em comunicação, para que seja possível a transferência de informações sobre o que foi feito, como foi feito e por quê foi feito, apresentando motivos bem estruturados e se possível, figuras ou mapas que demonstrem toda a informação.[1] (https://paulovasconcellos.com.br/o-que-%C3%A9-data-storytelling-ac5a924dcdaf)
É definido como a raiz quadrada positiva da variância (Bussab et al, 2010). Em probabilidade, o desvio padrão ou desvio padrão populacional é uma medida de dispersão em torno da média populacional de uma variável aleatória. Em estatística, desvio padrão amostral indica uma medida de dispersão dos dados em torno de média amostral 1.
A distribuição normal é simétrica em torno da média o que implica que a média, a mediana e a moda são todas coincidentes.1
Dropout é uma técnica de regularização de redes neurais em que, a cada iteração do treinamento, uma seleção aleatória de neurônios é desligada. A quantidade de neurônios desligados é controlada por um hiper-parâmetro, sendo que, quanto mais neurônios são desligados, mais forte é a regularização. É importante que o dropout seja aplicado apenas durante o treinamento e nunca para fazer predições. (Srivastava, 2014)
Método de aprendizado que consiste em utilizar a predição de vários algoritmos de Aprendizado de Máquina e combinar seus resultados de modo à obter uma predição melhorada. Um exemplo conhecido é o Random Forest, que utiliza diversas Decision Trees para fazer sua predição. 1
Método usado para calcular a diferença entre duas distribuições probabilísticas e por isso é muito usado em problemas de classificação, pois se quer alcançar uma aproximação da distribuição das classes do referido problema, é dado por: ,
onde
é a probabilidade do exemplo ser da classe x (1 na classe correspondente e 0 nas restantes) e
é a probabilidade obtida. Faz-se o somatório do produto para cada classe x e no final teremos o erro entre a distribuição esperada e a obtida. 1 2
O erro quadrático médio ou desvio quadrático médio é uma medida do erro cometido ao estimar um observável MSE. Sejam o i-ésimo valor observado e o i-ésimo valor estimado, respectivamente, em um conjunto de N observações,
isto é, i = 1, 2, ..., N. O erro quadrático médio desse experimento é dado por
.
Diga-me com quem andas e eu te direi quem és. Esse provérbio resume bem o conceito por trás dessa abordagem de aprendizado que consiste na representação vetorial da relação entre entidades de um determinado conjunto dentro de um espaço multi-dimensional.
Um dos algoritmos mais famosos a aplicar esse conceito é o word2vec que é capaz de abstrair, através desses vetores de relações, propriedades semânticas e sintáticas das palavras. Isto pode ser exemplificado através da operação Rei - Homem + Mulher = Rainha, que demonstra que o vetor que representa o conceito de feminino pode ser adicionado a uma palavra masculina para obter sua contraparte feminina como resultado.
O Apache Hadoop é uma coleção de utilitários de software de código aberto que facilitam o uso de uma rede de vários computadores para resolver problemas envolvendo grandes quantidades de dados e cálculos. Ele fornece uma estrutura de software para armazenamento distribuído e processamento de big data usando o modelo de programação MapReduce. 1
Hipótese inicial a ser testada, que é colocada em teste de hipótese. Normalmente baseada em análises anteriores ou conhecimentos especializados em geral indica uma igualdade a ser contestada. 1 2
Trata-se de supostas respostas para um problema em questão. É importante que as proposições possam ser testadas de maneira empírica, a fim de determinar sua validade. 1
Um gráfico composto por retângulos justapostos em que a base de cada um deles corresponde ao intervalo de classe e a sua área à respectiva frequência. Um histograma é utilizado para representar a distribuição de frequências de variáveis contínuas. Os valores observáveis da variável são divididos em classes (faixas de valores) e, então, conta-se a frequência de ocorrência dos valores em cada classe. O histograma é o gráfico que relaciona as classes no eixo X e valores proporcionais à frequência no eixo Y.

Diferentes amostras podem ser retiradas de uma mesma população, e amostras diferentes podem resultar em estimativas diferentes. Isto é, um estimador é uma variável aleatória, podendo assumir valores diferentes para cada amostra. Então, ao invés de estimar o parâmetro de interesse por um único valor, é muito mais informativo estimá-lo por um intervalo de valores que considere a variação presente na amostra e que contenha o seu verdadeiro valor com determinada confiança.1
Julia é uma linguagem de propósito geral desenhada para alta-performance com características como a tipagem dinâmica, polimorfismo, e Entrada e saída asíncronos de forma nativa, permitindo computação paralela e distribuída. Uma das principais características da linguagem é a utilização de multimétodos como um paradigma. 1
O Project Jupyter é um projeto de código aberto, sem fins lucrativos, nascido do Projeto IPython em 2014, que evoluiu para dar suporte à ciência de dados interativa e computação científica em todas as linguagens de programação. Jupyter é, e sempre será, 100% de software de código aberto, livre para todos usarem e liberados sob os termos liberais da licença BSD modificada.
É um algoritmo de agrupamento (clustering) que utiliza distância euclidiana para dividir/organizar/separar os N valores de uma amostra em K subconjuntos. K é definido previamente e o algoritmo faz o trabalho de calcular a distribuição da amostra nos subconjuntos mais próximos. Os pontos de onde mede-se a distância euclidiana, que são os centros dos subconjuntos (K0,K1,K2,Kn) são definidos aleatoriamente na primeira iteração e a cada iteração posterior são movimentados afim de distribuir a amostra em subconjuntos de tamanhos iguais.

Matriz é uma estrutura de dados utilizada para armazenar dados em mais de uma dimensão. Por exemplo, com duas dimensões, temos linhas e colunas acessadas com dois índices.
É possível criar matrizes de n dimensões, que serão acessadas com n índices. Dados dois números naturais m e n não-nulos, denomina-se matriz m por n (indica-se m x n) toda tabela formada por (m • n) elementos dispostos em m linhas e n colunas. As matrizes são indicadas por letras maiúsculas do alfabeto latino e representadas utilizando-se parênteses ou colchetes. Um elemento genérico de uma matriz A é simbolizado por aij, em que i indica a linha e j a coluna a que pertence o elemento.
Numa matriz quadrada de ordem 2 destacam-se:
- diagonal principal:
a11ea22; - diagonal secundária:
a12ea21.
Numa matriz quadrada de ordem 3 destacam-se:
- diagonal principal:
a11,a22ea33; - diagonal secundária:
a13,a22ea31.
Em suma, para matrizes quadradas de ordem n:
- diagonal principal: elementos
aij, comi = j; - diagonal secundária: elementos
aij, comi+j = n+1
Matrizes especiais:
Existem matrizes que apresentam maior utilidade e possuem um nome diferenciado (especial):
- Matriz nula é toda matriz que tem todos os elementos iguais a zero. Representa-se por Om x n.
- Matriz identidade de ordem n ou matriz unidade de ordem n é toda matriz quadrada no qual os elementos de sua diagonal principal são iguais a 1 e os demais, nulos.
- Matriz oposta de A é a matriz que se obtém de A, trocando-se o sinal de cada um de seus elementos. Representa-se por -A. 1 2
A mediana de um grupo de itens é o valor do item central quando todos os itens do grupo estão ordenados de forma crescente ou decrescente. Para um grupo com 3 valores, a mediana é o valor de posição 2, quando os valores estão ordenados. Exemplo: No grupo [5, 10, 15], a mediana é o 10. Já em grupos que a quantidade de valores é par, a mediana é a média dos valores centrais. Exemplo: No grupo [5, 10, 15, 20], a mediana é a média entre 10 e 15 (os valores centrais), no caso, 12,5. (Kazmier, Leonard. 2007).
É a prática de extrair informações de uma massa de dados, a fim de determinar padrões e resultados futuros. Utiliza-se de várias técnicas como mineração de dados, modelagem estatística e machine learning para dar suporte na tomada de decisão. 1
É uma técnica utilizada para analisar dados que cria várias médias de vários intervalos de dados dentro do dataset. A média móvel é calculada da seguinte maneira: dado um tamanho k de subset, o primeiro ponto da média móvel é obtido a partir da média dos k primeiros elementos. Depois, essa "janela" é movida para frente, excluindo o primeiro valor e calculando a média com o próximo dado. Essa é uma técnica amplamente usada para suavizar curvas e descobrir tendências dentro dos dados, muito usada no setor financeiro. 1
Ver Banco de Dados Não-Relacional.
É uma instância em uma base de dados que pode ser apenas um ruído que se deseja eliminar em uma etapa de pré-processamento, ou ainda uma instância que possui um padrão nunca analisado antes, a qual possa representar um comportamento extraordinário e, portanto, passível de estudo e atenção especial. Campos 2015
É um evento que ocorre quando o modelo se encaixa bem nos dados de treinamento, mas não se generaliza para dados não vistos ou testados. Isto é, não produz boas predições para dados desconhecidos. Chaoji et. al. 2016
Em filosofia, ontologia é a teoria da "natureza do ser ou dos tipos de existências". Para Ciência da Computação, ontologias são um meio para modelar formalmente a estrutura de um sistema, ou seja, as entidades e relações relevantes que emergem da observação, e que são úteis para um determinado propósito (STAAB, Steffen; STUDER, Rudi (Ed.). Handbook on ontologies. Springer Science & Business Media, 2010).
Pandas é uma biblioteca Python open source, ela fornece ferramentas de análise de dados e estruturas de dados de alta performance e fáceis de usar. É considerada a principal e mais completa biblioteca para estes objetivos, sendo fundamental para Análise de Dados. 1
É um ecossistema de ferramentas e bibliotecas de Machine Learning, para uso em Processamento de Linguagem Natural e Visão Computacional. Escrito em Python e de código aberto, é baseado em Torch, um framework escrito em Lua. 1 2
É um algorítimo para aprendizado de máquina supervisionado para classificadores binários(funções que determinam se os dados pertencem a uma determinada classe ou não). É um tipo de classificador linear, ou seja, algoritmo de classificação que faz suas predições baseado em uma função de predição linear combinando pesos de um vetor de características. 1
Uma métrica para modelos de classificação. A precisão identifica a frequência com que um modelo estava correto ao prever a classe positiva. Isso é:
Ao contrário da expectativa, os quartis são 3 pontos que dividem um conjunto em 4 subconjuntos de iguais quantidades. eg. um conjunto que contém os números de 1 a 10, os quartis Q1, Q2 e Q3 são, respectivamente: 3, 5.5 e 8. 1
Função não-linear de ativação de neurônios numa rede neural artificial1. É definida pela função e forma:


Surgiu recentemente como uma eficiente substituição para a função Sigmóid2.
Uma métrica para modelos de classificação que responde à seguinte pergunta: de todos os possíveis rótulos positivos, quantos o modelo identificou corretamente? Isso é:
Conceitualmente, é uma técnica para analisar dados e encontrar uma formulação matemática linear e explícita que descreva de maneira aproximada o comportamento (a relação) dos dados. Na prática, é encontrar dois coeficientes (linear e angular) que minimizem o erro quadrático entre a função linear resultante e os dados. 1
São sistemas físicos que podem adquirir, armazenar e utilizar conhecimentos experimentais, que podem alcançar uma boa performance, devido à sua densa interconexão entre os nós da rede. (Lippmann, 1997 apud. Fernandes, 2003)
Método de aprendizado usado para classificação, regressão e outras aplicações, que se baseia na junção de outros algoritmos conhecidos (logistic regression, linear regression,etc). Esse modelo é obtido pela construção de árvores de decisão, que conforme vão sendo construídas, decidem quais algoritmos juntos levam ao melhor modelo. (Hastie et. al. 2008).
A regressão logística é uma técnica estatística que tem como objetivo produzir, a partir de um conjunto de observações, um modelo que permita a predição de valores tomados por uma variável categórica, frequentemente binária, a partir de uma série de variáveis explicativas contínuas e/ou binárias. Em comparação com as técnicas conhecidas em regressão, em especial a regressão linear, a regressão logística distingue-se essencialmente pelo facto de a variável resposta ser categórica. Esse algoritmo é comumente usado em problemas de classificação. 1.
Scala é uma linguagem de programação desenvolvida para expressar padrões de programação comuns de forma elegante e com tipagem segura através da integração de características de linguagens orientadas a objetos e funcional. Referência
A scikit-learn é uma biblioteca de código aberto muito popular para realizar apredizado de máquina e mineração de dados em Python. Ela inclui diversos algoritmos de classificação, regressão e agrupamento, tais como máquinas de vetores de suporte, florestas aleatórias, gradient boosting, k-means, DBSCAN e muitos outros. Além disso, a biblioteca também oferece técnicas de pré-processamento, seleção de atributos, seleção de modelos, métricas e outros utilitários. 1 2 3
Um sistema de recomendação combina técnicas de Recuperação de Informação e Aprendizagem de Máquina para selecionar itens personalizados com base nos interesses dos usuários e conforme o contexto no qual estão inseridos, é utilizado em diversas áreas como: filmes, músicas, livros, pesquisas, sites de comércios eletrônicos, etc. Através dessas técnicas, é gerado uma filtragem da informação para o usuário e assim retornando uma lista de recomendação, as filtragens mais comuns são:
- Filtragem colaborativa: considera a experiência de todos os usuários
- Filtragem baseada em conteúdo: Considera a experiência do usuário alvo
- Filtragem Híbrida: utiliza-se os dois tipos para gerar uma recomendação mais personalizada.
Veja mais nesse link.
Máquina de vetores de suporte (do inglês SVM: support vector machine) é um método de aprendizado supervisionado que, dado um conjunto de treino X, tenta encontrar um hiperplano no espaço vetorial formado pelos exemplos em X que melhor separa os subconjuntos de exemplos definidos pelas classes nesse conjunto (James et. al. 2017). De forma efetiva, o método tenta encontrar uma margem de separação para os exemplos de acordo com as classes informadas. De posse da margem, é possível predizer a classe de um novo exemplo como sendo aquela do conjunto definido pelas margens encontradas durante o treino em que o novo exemplo está inserido. O método pode ser estendido para permitir margens mais ou menos severas (hard vs. soft margin), projeções não lineares em espaços de dimensão superior (kernel trick), predições probabilísticas entre outras 1.
O TensorFlow™ é uma biblioteca de software de código aberto para computação numérica que usa gráficos de fluxo de dados. Os nodes no gráfico representam operações matemáticas, e as arestas representam as matrizes ou tensores de dados multidimensionais que se comunicam com os nodes. A arquitetura flexível permite que você implante aplicações de computação a uma ou mais CPUs ou GPUs em um computador, servidor ou dispositivo móvel usando uma única API. O TensorFlow foi desenvolvido por pesquisadores e engenheiros da Google Brain Team no departamento de pesquisas de inteligência de máquina do Google com a finalidade de realizar pesquisas sobre redes neurais profundas e aprendizado de máquina. No entanto, devido à característica abrangente do sistema, ele também pode ser aplicado a vários outros domínios. 1
É um evento que ocorre quando o seu modelo não representa de maneira eficaz o problema que foi proposto, ou seja, o modelo não se ajusta aos dados. Normalmente é possível identificar o underfitting por uma baixa variância e um alto bias. 1
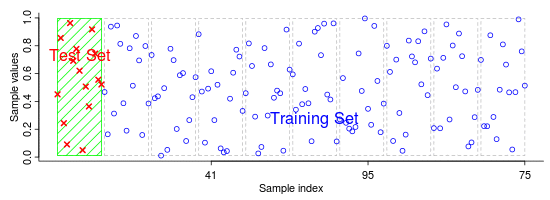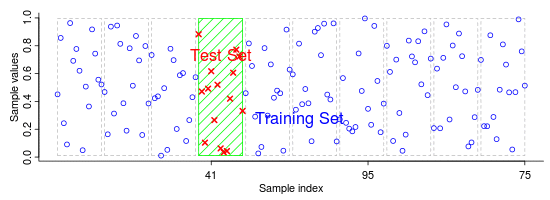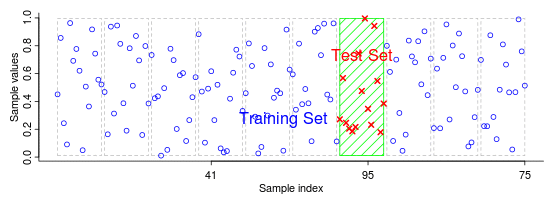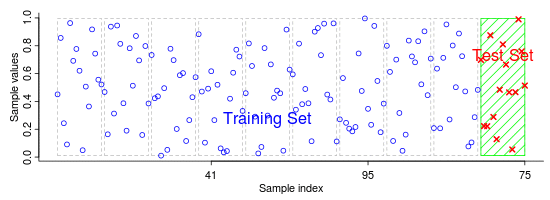
Na abordagem básica, chamada método k-fold, o conjunto de treinamento é particionado em k subconjuntos. Dentre esses k subconjuntos teremos:
- 1 subconjunto de validação
- k-1 subconjuntos de treinamento
Quando um valor específico para k é escolhido, por exemplo k = 10, teremos uma Validação cruzada 10-fold. Neste caso o processo de validação será repetido 10 vezes, onde cada uma das 10 subamostras serão usadas como dados de validação scikit learn cross-validation.
Abaixo temos uma animação exemplificando as iterações.
Em termos estatísticos, a variância determina o quão distante cada valor está do valor médio do conjunto. Quanto maior a variância, mais distante o valor está da média. Quanto menor a variância, mais próximo o valor está da média. 1
Variáveis que possuem valores não-quantitativos. Os diferentes valores de uma variável categórica são normalmente chamados níveis (levels). Se os valores dos níveis forem nomes arbitrários a variável é normal (por exemplo, cor do olho). Porém se existirem ao menos 3 níveis (notas de escola como A, B, C) a variável é ordinal.
Variável que possui valor quantitativo, ou seja, que pode ser contado. Em outras palavras, são variáveis com características mensuráveis que podem assumir apenas um número finito ou infinito contável de valores e, assim, somente fazem sentido valores inteiros. Geralmente são o resultado de contagens. Exemplos: número de filhos, número de bactérias por litro de leite. 1
Na computação um vetor (arranjo unidimensional) é uma estrutura de dados que armazena um grupo de elementos, identificados por um índice e tipicamente com elementos do mesmo tipo. 1,2
Também conhecido como erro sistemático, é a distorção sistemática entre a medida de uma variável estatística e o valor real da grandeza a ser estimada. 1
Alpaydin, Ethem. Introduction to Machine Learning. 2.ed. Massachusetts: MIT Press, 2010.
Behrens, J. T.. Principles and procedures of Exploratory Data Analysis. American Psychological Association Inc. 1997. Vol.2, No.2, 131-160
Bussab, Wilton de O., and Pedro A. Morettin. Estatística básica. 8.ed. Página 41. Saraiva, 2010.
CAMPOS, Guilherme Oliveira. Estudo, avaliação e comparação de técnicas de detecção não supervisionada de outliers. 2015. Dissertação (Mestrado em Ciências de Computação e Matemática Computacional) - Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo, São Carlos, 2015. doi:10.11606/D.55.2015.tde-04082015-084412. Acesso em: 2017-10-03.
Fernandes, Anita Maria da Rocha. Inteligência Artificial: noções gerais. 1.ed. Florianópolis: Visual Books, 2003.
Gessert, W. Wingerath, S. Friedrich, and N. Ritter. Nosql database systems:a survey and decision guidance. Computer Science - Research and Development,32(3):353–365, Jul 2017
Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome. The Elements of Statistical Learning (2nd ed.). Springer. ISBN 0-387-95284-5, 2008.
Jain, A.K.; Murty, M.N.; Flynn, P.J.; Data Clustering: A review. ACM Computing Surveys, Vol. 31, No. 3, 1999.
Kazmier, Leonard. 2007. Estatística aplicada à administração e economia. Cap. 3.4, pág. 52.
Russell, Stuart J.; Norvig, Peter. Inteligência Artificial. 3.ed. Rio de Janeiro: Elsevier, 2013.
Srivastava N., Hinton G., Krizhevsky A., Sutskever I., and Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research. 15, 1 (January 2014), 1929-1958.
Staab, Steffen, and Rudi Studer, eds. Handbook on ontologies. Springer Science & Business Media, 2010.
Vineet Chaoji, Rajeev Rastogi, and Gourav Roy. 2016. Machine learning in the real world. Proc. VLDB Endow. 9, 13 (September 2016), 1597-1600. DOI: http://dx.doi.org/10.14778/3007263.3007318
Gareth James, Daniela Witten, Trevor Hastie e Robert Tibshirani. 2017. An Introduction to Statistical Learning. Spring. disponível em link. DOI: 10.1007/978-1-4614-7138-7