主要讲posix api的锁,主要 互斥锁, 自旋锁, 读写锁, 原子操作 再是在多进程的情况下面的 共享内存 还有比如说分布式锁,那个乐观锁,悲观锁,公平锁这些分布式的锁,在后面中间件讲 主要核心先把这些posix API里面这些底层的锁解释清楚,后面再讲一个自己实现一个try-catch怎么做,原理又怎么样,抛异常,捕获异常以及在finaly里面处理时这三个怎么去实现,这个异常是怎么抛的?
先思考为什么要有锁的概念,为什么要有锁呢? 因为随着在多线程,多进程这种多任务的操作系统情况下面,它避免不了多个任务在执行的时候会共享一些资源,这些资源就叫做临界资源,对于这些临界资源多个线程同时去使用的时候,那避免不了它就会出现一些意想不到的情况,a线程在执行同时b线程也在执行,会出现了一个我们根本无法预计的情况。所以对它加上一把锁为了避免副作用,异常的情况。
加锁是为了避免有副作用产生,这个副作用什么意思,就是我们避免那些我们意想不到的情况产生所以我们加锁,加锁的时候我们对这个加锁的粒度可能拿捏不稳,什么时候加多大的锁?
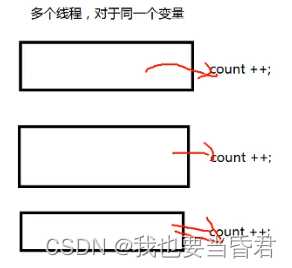
经典案例:多个线程同时对于一个变量进行count++;
pthread_create(), 第一个参数线程在创建完之后会带回一个id,那这个线程id有什么用呢?我们在另外一个线程要去终止它的时候,会使用到这个id 第二个参数是线程的属性比如堆栈大小我们是可以自己定义的 第三个参数是线程的入口, 第四个参数是传到子线程的参数, 返回值等于0是成功
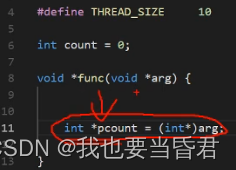
这个地方是拿地址不是拿值
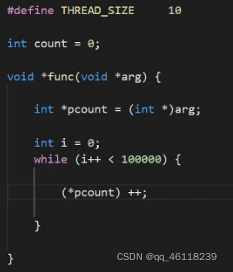

为什么做不到我们想要的东西。
count++里面到底发生了哪些事?
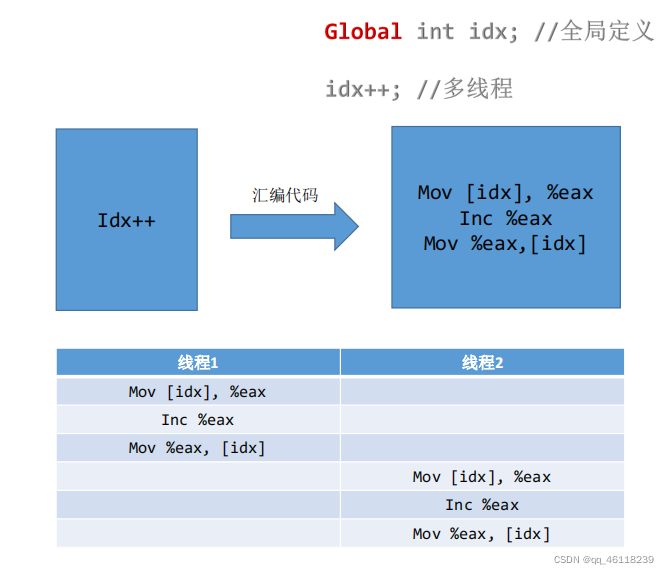
一行代码翻译成汇编却有三行代码,但是由于线程的切换它变成了另外的状态
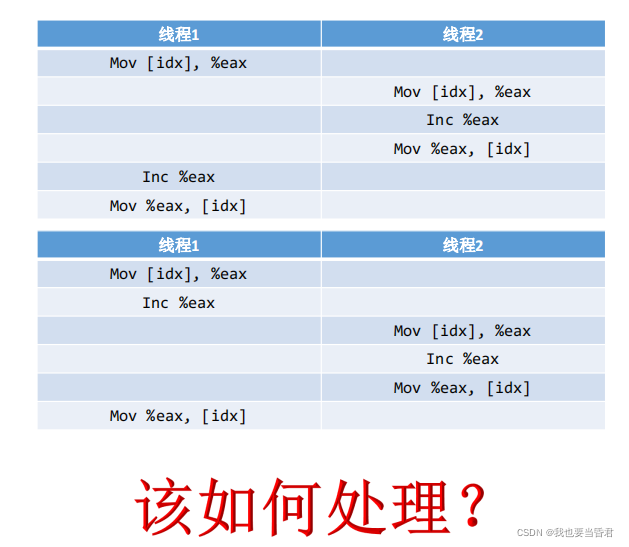
在线程2是51切换到线程1又变成了50,俩个线程执行idx++却只加了一次,所以副作用小于100万不会多于 线程切换是什么概念? CPU每一次运行每一次指令执行的时候都是与寄存器打交道
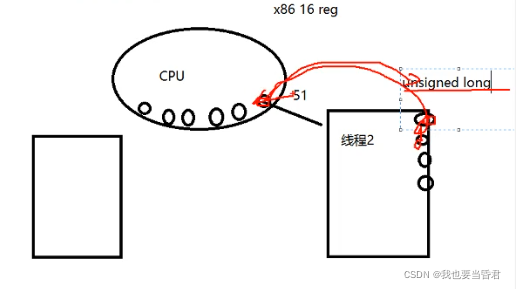
与协程切换类似也是这样做的 这个寄存器的值我们用什么来存储,用指针,用无符号long型来存储寄存器里面的值,
把这一组寄存器的值加载上去就实现了寄存器的切换, 多核怎么做呢?原理一样,每一个CPU操作系统会为它准备一个就绪队列,运行那个就加载那个,并且切出运行完的, **上下文切换会消耗那些资源?**无外乎所做的就是一个mov指令,看似只有这些消耗,还有关于文件系统虚拟内存相关的操作,单独从寄存器的更换上面是没有太多消耗的,消耗不大
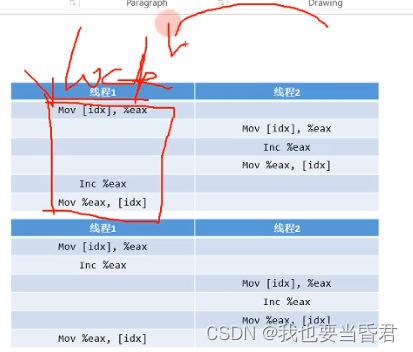
站在一个微观的角度我们怎么加锁比较好? 第一种加锁我们在整个汇编代码段把它合并成不可分割的一段 把这三条汇编指令捆绑在一起
这个mutex的本质是什么东西?
一进入这三条指令之前就给他加锁不允许另外一个线程进入,等待着这把锁释放才可以执行, 线程二发现线程一锁住了它会切换出资源执行一系列动作去休眠,进入等待状态也有表述叫阻塞状态, mutex也知道这个过程代价比较大所以提供出来了另外一个接口叫做尝试加锁

线程一以及加锁了,线程二再去时会发现已经被占,为了防止线程二休眠,就让线程二去尝试加锁一下,看它有没有被锁,如果被锁了它就不执行,不去做切换去做其它的事情,如果没有被锁它就去加锁
不断询问不断的轮训这把锁有没有被占用,trylock的好处至少线程不会被休眠,能够快速的第一反映知道锁有没有释放
trylock的过程有没有切换的发生,能不能发生切换? 这只是应用层循环的切换中间还是有可能引起线程的切换的 那么有没有锁在这个过程中间就一直在等没有引起线程切换? 这就是spin_lock,不去深究原理会发现spin_lock与lock调用接口是一模一样的

lock会引起线程切换代价比较大,spin不会就是一直敲门一直等,在使用场景上面对于时间比较长的我们会使用mutex_lock,对于时间比较短的我们会使用spin_lock,什么叫做时间长,什么叫做时间短,对于操作比较复杂的我们使用mutex,如果就是链表添加删除节点这种几行代码的我们使用spinlock,如果是对红黑树整个B树进行加锁我们采用mutex 在使用锁的时候一定要避免死锁产生,对于单核这只是纯软件的东西不会引起线程切换并不是说cpu不会切换往下执行,从锁法粒度上面lock,trylock,spin可以依次越来越小, 使用lock时可以优先使用trylock,只是trylock在写代码逻辑上面会稍微复杂一点,
线程的切换有两种情况:1.第一种时间片用完了,会进入ready就绪状态2.在等待着某种条件,比如io没有就绪或者就是在等待着某种条件,会进入wait等待的状态这两种切换是不一样的 spinlock时间片到了也不会引起切换
有注意到现在10个线程在写,一个线程在读,在一定程度上面可以考虑使用读写锁来做,读写锁逻辑比较麻烦不太建议使用,对于读多写少的场景使用读写锁是合适的,
我们会发现一行代码翻译成3条指令的过程核心的解法就是把这几条指令合在一起,不被另外的线程拆开,就在前面加锁,这是一个加锁的概念,那有没有更好的方法我们把这三条指令就变成一条指令,压根就不用加锁的方法,接下来就是原子操作与这个CAS
volatile到底有什么用? volatile最早的时候由于那些高低电平它在捕获的时候,它的数值在变,不是通过我们计算的方式,比如说这内存中间的一个值是通过一个串口也好或者是网线过来也好,它这里面的值在变,就是这个内存块里面的值在变,我们cpu操作的时候可以把这一个内存单元的值定义成volatile它是易变,这个易变的变的过程是由于外界客观资源所造成的它的数据是一直在变的,所以这个地方很难理解**到底定不定义volatile有什么区别?**核心点是对于volatile这个数据是改变的状态,我们在操作的时候有可能发生改变或者别的什么现象
如果是简单的定义成int a=5,当另外一个线程把它修改成a=6时,a的值会出现一个现象从内存中间加载到寄存器里面,那就会出现两份,内存中间有一份,寄存器里面也有一份,而cpu肯定会优先计算寄存器里面的,所以内存中的值它影响就不会很大,我们加上volatile这个值计算的时候会优先于内存计算,如果不加它会以寄存器里面的值写回内存的方式去做,易变是直接把内存里面地址的值拿过来操作,这是两者之间的本质区别
这里写汇编的volatile与我们定义的volatile不是一个意思,
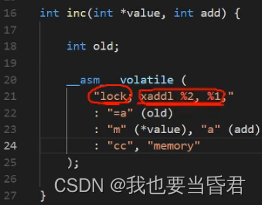
把第二个参数加上第一个参数存储到第一个参数里面, 这个lock是什么意思? 在计算机体系结构里面cpu操作内存,内存块不只一个,在cpu和内存中间有一条总线,这个lock是锁总线的意思,只允许这一条指令执行完,避免了多个CPU同时去操作这一条, 这个memory什么意思呢? 在体系结构里面,cpu-高速缓存-主内存,当然这个高速缓存中间又划分很多层
会出现一个什么现象呢?我们对于一个指令加载进来的时候,在CPU操作的时候在高速缓存和内存中间就会有一个一致性的问题
这四个MESI状态, “M”:从CPU到高速缓存 “E”:高速缓存到主存 “S”:共享 “I”:
这个屏障是干啥的就是从高速缓存写回这个主内存中间,我们memory把它锁住,能够保证它落到内存的时候不受干扰,
这个地方old返回值不大,相当于填空题,把一个值填在这里其实没有多大意义
一行代码的力度还比不上一个函数的力度吗?函数调用是没有副作用的 我们核心的点是抓住这个副作用以及产生的效果,这里面的这个代码就是单独的把三条指令变成一条指令,
汇编语法,汇编解释器

原子操作的力度比spin更小,但是原子操作有一个前提是需要指令系统里面有才能够去实现,比如说对于一个双向链表使用头插法虽然就只有几行代码,但是不能使用原子操作,因为没有同时对多个变量赋值的指令

对于类似于单例模式的这样一种结构,指令系统里面有没有可以单一的做这个事情的指令,
对于xchg这条指令如果a==b成功就返回c,否则就返回0;这就CAS的核心,所谓的无锁就是对应的原子操作, 假如问我能不能写一个线程安全的单例模式

以上的分析是从多线程的角度下面思考的,那么多进程下面又该怎么办? 对于多进程按照我们刚刚那个mutex也好或者spin lock也好,我们定义一些变量加的锁,它不在一个进程里面,它的虚拟地址空间都不一样,由一份变成两份,就是我们定义变量压根就是不行的,所以对于多进程加锁的话是需要有一块共享的资源的,也就是A进程和B进程是共享这一块资源的,我们同样也是可以用原子操作,原子操作底层接口也是汇编,
这里可以创建10个子进程,break让子进程不继续创建,usleep就是让另外一个进程先走, 我们共享一个变量,使用原子操作是可行的,我们可以共享一个变量同样我们可不可以共享一个内存池,并且对它们的分配做一个统一分配和回收 这种mmap共享的方式只在父子进程之间,如果我们打开一个fd对于一个文件去做映射的话,父子进程之间是没有关系的,

#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/mman.h>
#define THREAD_SIZE 10
int count = 0;
pthread_mutex_t mutex;
pthread_spinlock_t spinlock;
pthread_rwlock_t rwlock;
// MOV dest, src; at&t
// MOV src, dest; x86
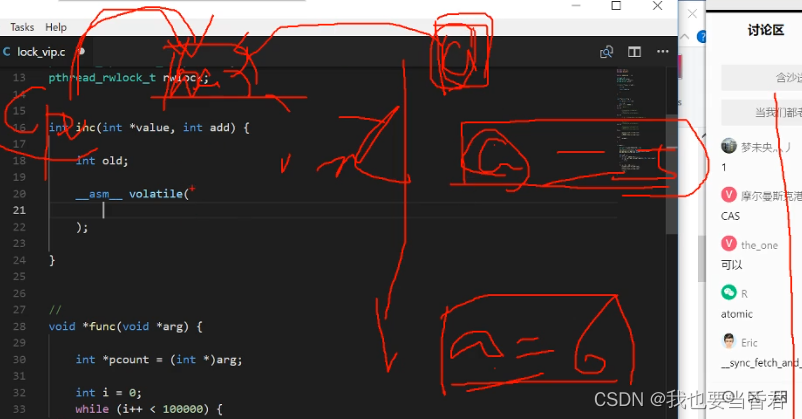
int inc(int *value, int add) {
int old;
__asm__ volatile (
"lock; xaddl %2, %1;" // "lock; xchg %2, %1, %3;"
: "=a" (old)
: "m" (*value), "a" (add)
: "cc", "memory"
);
return old;
}
//
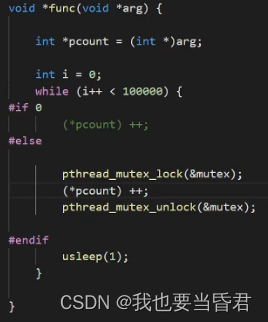
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
while (i++ < 100000) {
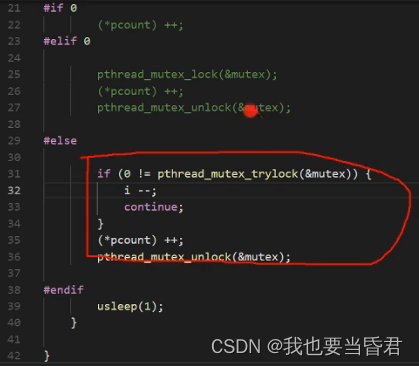
#if 0
(*pcount) ++;
#elif 0
pthread_mutex_lock(&mutex);
(*pcount) ++;
pthread_mutex_unlock(&mutex);
#elif 0
if (0 != pthread_mutex_trylock(&mutex)) {
i --;
continue;
}
(*pcount) ++;
pthread_mutex_unlock(&mutex);
#elif 0
pthread_spin_lock(&spinlock);
(*pcount) ++;
pthread_spin_unlock(&spinlock);
#elif 0
pthread_rwlock_wrlock(&rwlock);
(*pcount) ++;
pthread_rwlock_unlock(&rwlock);
#else
inc(pcount, 1);
#endif
usleep(1);
}
}
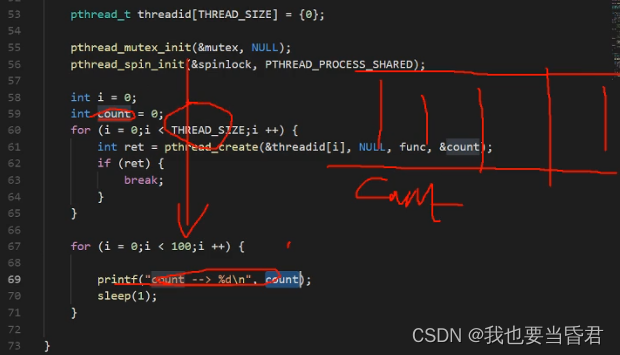
int main() {
#if 0
pthread_t threadid[THREAD_SIZE] = {0};
pthread_mutex_init(&mutex, NULL);
pthread_spin_init(&spinlock, PTHREAD_PROCESS_SHARED);
pthread_rwlock_init(&rwlock, NULL);
int i = 0;
int count = 0;
for (i = 0;i < THREAD_SIZE;i ++) {
int ret = pthread_create(&threadid[i], NULL, func, &count);
if (ret) {
break;
}
}
for (i = 0;i < 100;i ++) {
pthread_rwlock_rdlock(&rwlock);
printf("count --> %d\n", count);
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
#else
int *pcount = mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_ANON|MAP_SHARED, -1, 0);
int i = 0;
pid_t pid = 0;
for (i = 0;i < THREAD_SIZE;i ++) {
pid = fork();
if (pid <= 0) {
usleep(1);
break;
}
}
if (pid > 0) { //
for (i = 0;i < 100;i ++) {
printf("count --> %d\n", (*pcount));
sleep(1);
}
} else {
int i = 0;
while (i++ < 100000) {
#if 0
(*pcount) ++;
#else
inc(pcount, 1);
#endif
usleep(1);
}
}
#endif
}
———————————————— 版权声明:本文为CSDN博主「我也要当昏君」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_46118239/article/details/124610993