本文摘录自腾讯高级工程师在「全球C++及系统软件技术大会」上的专题演讲。
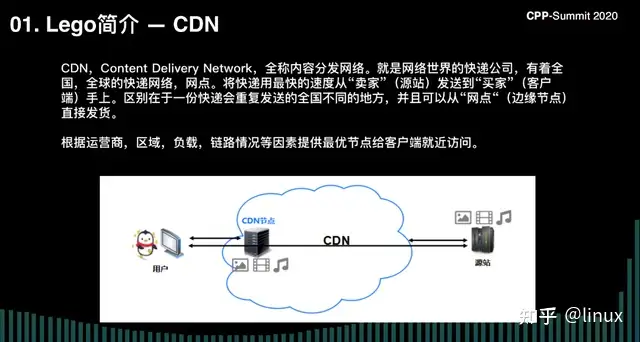
首先介绍一下 CDN。非常早期的时候有一个大牛创建了一个公司叫阿卡曼,他把服务器部署到全球各地,然后把源站的内容缓存在就近的服务器。比如我们广东,可能在深圳有个机房,我们就缓存了一份跟源站一模一样的内容。这样用户在访问这个内容的时候不用“跋山涉水”到北京的服务器去拿需要的视频了,只要在本地就能服务。所以 CDN 其实就是网络世界的快递工。
那么为什么说 CDN 大规模且需要高性能呢?首先,我们 CDN 每时每刻都会跑大概 100t 流量,我相信这个流量级别在国内也算是数一数二的。腾讯,包括腾讯云本身的访问量都非常大,QPS 基本上都是千万级,所以我们服务的是一个流量这么大,并且 QPS 并发量这么高的服务器。存储量更不用说,都是10万级别的,量级非常大。腾讯 CDN 支持的场景也非常多,业务纷繁多样,各种类型都有。
但今天我不讲怎么去运营这种大规模服务器,我主要会讲单机层面怎么去设计服务器,来尽可能地提升单机的性能和服务能力。

服务器肯定要支持高性能、高QPS、高能量,但除了这一部分,我们更要考虑的是可扩展性这一块。特别要提前讲一点,其实传统的服务器基于异步调用是非常难以去写、难以去维护的,写过异步回调的同事应该知道。所以我们希望这个服务器是所有新人,包括所有开发者,都能够尽快上手的。
那怎么去衡量呢?其实就是一个写 Nginx 服务器的人需要多久能够精通,能够去把控完整的代码让它跑起来,并且出了问题能够快速排查处理?一般这种都要按月算,但是用我们的架构,我们希望新人过来,按周、按天就能够上手去写代码,去学习,去尽快投入到工作,说白了就是尽可能高地产效。
另外就是CDN友好,它的功能很多,特别是可能大家觉得除了缓存之外也没什么东西,其实产品非常多。比如直播带货,在CDN里会有很多的功能需求,比如怎么尽快地把流、把内容发放给用户,尽可能减少延迟;比如抢红包,你可能要等个10秒钟,但有人可能一瞬间、1毫秒就看到了。所以在CDN上面会不停地迭代很多新的功能特效,比如编解码,比如直播的一些特性,比如电商需要的一些边缘计算能力的开放特性。
回过头来看一下传统Web框架有哪些呢?这里抽取了三个比较典型的去做对比。

比如像 Nginx 就是经典的异步回调。异步回调本质上就是一个状态机,有很多的事件。比如很多网络收发的事件、网络磁盘的事件来了之后,内部怎么去流转这个状态,怎么尽快处理。这种框架的好处是性能非常高,现在大家都认为 Nginx 是服务器里性能最高的一个代表。
另外,最早协程没有 C++,所以我们找的是 Libco,是微信做的一个协程框架。我后面会讲一下协程,在考虑选型的时候有考虑这个协程,但它有其他方面的一些问题,包括怎么去开销的部分。
最后一个是 ATS。ATS 里有个 Continuation,是 CPS 编程模型,C++ 里其实也有,叫 Future/Promise。

我们先来具体看一下传统异步框架。
首先它是基于事件的,另外它事件的转换去维护的时候很复杂,比如 Nginx 内部就有11个阶段,再加上各种 handler,你要去处理的事件非常多,所以为什么异步回调非常难处理,就是需要人工去维护这个状态机。你要去处理每个事件,要预想到每个流程,要知道它的每个状态,来哪个事件都要能够处理。
另外就是 Coroutine,它的主要问题在哪呢?不管任何协程都有开销,比如我们有很多的 stackless、stackful。stackful 需要去存这个协议、存这个栈的内容,那么这时候内存就有问题了。你的编程模型会受限于占空间的大小,你要写多大?会不会溢出?比如 Libco 就是用 128k。stackless 会限制你开发的模式,比如 C++ Coroutine 现在就是 stackless 的一种模式,但 stackless 对编程者也是有要求的。
还有在协程本身做切换的时候,我们认为它还是有不小的开销,切换的时候会拷贝很多内存,就会有很多 memory copy;比如这个栈可能要恢复,一些 register 可能也要重新赋值,这些恢复的开销我们测试下来还是挺可观的,特别在高 QPS 的时候。

然后回到我们的主题,Continuation-Passing Style 是什么概念?你可以认为是一些 Callback 的组合,Callback 一个一个去做,但在 ATS 里并不能完全实现。所以当时我们认为基于 ATS 去做这个事情的复杂度也很高,但它的想法非常好。基于回调的话它的性能相对来说是比较好的,同时它的方式对开发者非常友好。其实就是一个一个函数往后调,用法接近于串行的程序写法。早期在 C++ 里做这个事情非常复杂,到了 C++ 11 之后有了一些特性的支持才使得这个事情变得非常简单自然,包括 C++11 的一些 Lamdba, declytype 的概念。所以早期我们也没有发现比较好的,到后面才决定去做这个事情。

然后看一下大的架构图大概是这样子,上面有一些模块,就是乐高的积木,下面很多 Epoll 的线程,基于这个线程,上面也会分层。当然这个是传统架构图,我们还有一些异步的事情。

先看一下为什么异步回调这个事情会比较麻烦。比如我处理一个事情要写很多 handler,这是预状态机里的事件,怎么跳的线,要转到什么状态。异步回调里面就写这个状态机里的这个线。这个时候就很麻烦,状态非常多,每个事件都要去处理。很多时候你是不知道异常怎么跳过来的,你可能没考虑到或者考虑不完全,这时候突然就陷到了异常状态。特别在网络事件非常多的时候,比如客户端关闭、超时,比如甚至到源站,比如到远端的服务器超时等等,你完全没法考虑全,所以导致你写的时候可能认为有几个事件但写漏了几个,再去做调试就会非常复杂,而且这个状态跳转的过程也很难去维护。
另外一个非常明显的问题是代码非常分散。比如我这个事件写在哪了,每个事件都要去处理的话,我的代码是按事件去划呢,还是按状态去划分。所以我们后来就选用了 Future 和 Promise 的方式。

Future 是什么概念?就是有一个事件我们认为未来会完成,但我不关心这个东西怎么完成或什么时候完成。Promise 就是这个东西能够复制回去,然后回调回 Future。
Future/Promise 跟 Continuation-Passing 有什么联系呢?Continuation-Passing 的意思是通过后续逻辑可以一个个函数不停地往后去叠加。比如我有一个处理请求的函数,接着可以再往后面传 Lambda 函数,这样在读完 Body 之后,ReadBody 返回 Future,Future在完成之后调 .Then 后面的函数。我完全不需要关心你下面的状态怎么扭转的,我只关心你业务的逻辑。这是一个串行的流程,读完 Body 写 Response,返回一些数据。然后我通过不停地去写错误、写 .Then,把整个逻辑串联起来。这就是 Continuation-Passing 的概念,也是最基础的一部分。
我们还设计了一个 Finally,我们在写代码的时候有一些异常希望在最后处理,这在 Python、Java 都有类似的概念,就是在最后 Cache 所有的异常,这样程序运行到任何状态都能够正常处理一些资源,关掉一些链接,关掉一些 file、handler,这些事情都在 Finally 去做处理。

Future 和 Promise 对比是什么样子?一个直观对比,是异步回调提出一个状态机,在不停地写连线的时候去写代码,我的连线就是我的代码,然后我在代码里面会触发这个事情到什么样的状态,不停地去写,这么一个逻辑,当然维护就比较复杂。我们希望做到的方式是通过 CPS 能够把整个事情拉平,把逻辑变成串行,让用户或者编程人员不需要关心我下面的事情是怎么完成的,只要我帮你完成这个事情,让你能往后继续走,就有点像写应用程序一样,完全不需要关心服务器内部是怎么做的。这样子,新的程序员不需要像在状态机那样了解很多,比如服务器内部实现跳转怎么做,每个接口的含义是什么,服务器本身内部的编程方式等等。我只要给到你一些函数,并且你自己通过 .Then Callback 的串联方式就把整个逻辑串联起来。这是两个编程模式的直观对比。

异常部分,刚也讲到了 Finally,但其实我个人认为 C++ 本身的异常不应该变成常态。我自己的观点是Fail-Fast,如果出现 Exception 非常严重就直接让服务器当掉,当然这跟应用场景有关系。像 CDN 是一个完全分布式系统,有几十万台机器,当掉一台也能够通过其他系统恢复,所以我们倒是希望服务器正常的一些异常,就是特别 Critical 的异常能够尽可能出来,而且异常本身的性能开销是非常大的。当然我不知道现在怎么样,C++ 20 应该没对这部分做优化。原来的异常会不停地去 Unwind 这个 stack,里面会存很多信息,导致其性能比较重,而且特别在网络经常出现异常的情况下,异常是常态,更不能用性能开销这么大的东西。
所以我个人在写服务器的时候不赞同去做try、cache,而是用更传统的一些方式对 Exception 结构重新做设计,在 .Then Callback 时不停地往下层抛,所以在设计方式上就有点不一样。就是我们希望后面的人去处理异常时,比如读取一个 http 请求的 body 或者读取头部时出现异常,在往回发响应数据的时候,可以自己判断出现这个异常周围应该怎么处理,而不是往上层发起这个请求的地方去做,因为我们后面会更理解这个逻辑,更理解出现异常之后你应该怎么去做处理。所以我们在做异常的时候定制了比较轻量化的异常的一个类,然后不停地往下面去抛,下面的去做处理。
刚才也说到我们有个 Finally 去做这一部分的完整清理,包括一些数据的清理,不管出现任何异常,在最后一步都能保证资源的释放,不会出现内存泄露,句柄泄漏,包括忘了关 socket 的这种异常,这是我们希望做的一个比较轻量化、高性能的 Exception 框架,可能跟 C++ 原有的 Exception 区别就比较大。

那做完这个事情之后,我们最开始看到的异步回调会在你处理完一个请求和要做的其他事情后就把所有的逻辑浓缩到一个函数里面,这样比原来分成三个函数去看的时候会更加清晰。当一个请求来的时候我去做请求处理,再跳转另外一个事件,之后再去发起一些业务逻辑,这里写的是像源站 CDN 的一个场景,比如我要去另外一个地方获取一些数据的逻辑,最后我甚至要写一个错误处理,所有东西都放到一个函数里面,这样逻辑其实是更清晰的,新人一眼就能看懂这个代码逻辑是干什么的,不用到处去看。这就是我们选取 Future/Promise 时达到的一个效果。

Future/Promise 讲起来非常简单,那它背后的实现是什么样子?虽然说起来它只是一个函数,但这个函数到底层怎么去保证。它其实就是一个代码块,我们在做的时候就变成了对代码块的调度,虽然程序员看到 ReadRequest 这么一个函数会认为它是异步的,但异步怎么执行呢?它到底层是怎么样实现的呢?一个异步代码块在一个框架底层的时候,我们会做一个调度器,把所有生成的 ReadRequest 的 Future 变成一个个 task,从底层去做调度,这样就达到了在上面写完之后,下面自动去扭转这个状态去做这些事情。

另外我们还做了很多的性能优化,包括 Future Folding 这一部分,跟我们调度器是非常相关的。因为我们以前遇到过 Future 去不停地做 .Then 的时候,最开始是以批量压入的方式去做的,后面发现这么写的话,比如你的 copy 非常多的时候,不停压栈就会发现一些内存的溢出,这个跟框架就比较相关了。但是刚说到 Folding 的部分也提到一点就是 Future 在代码里面会大量的创建,所以我们选取了这个编程模型之后就发现有个问题,大量创建 Future 之后内存是会炸的,比如并发1万个请求,业务逻辑有十个,内部可能要创建10万个 Future/Promise 的对象,所以导致内存不停的申请示范,开销非常大。所以在这过程中我们就发现需要去做一些解决方案,经过研究之后发现有两个,一个最简单的是替换 malloc库,后来发现 jemalloc 是比较好的,特别在这个场景下。另外,我们针对每一个进程去分配一个 ThreadLocal 的内存池,让内存在本地就有些缓存,不需要去内核申请很多内存。如果对内存分配比较熟悉的话就知道malloc,tmalloc有很多的内存管理,包括去内存,用 brk 申请大一点的内存,所以我们的做法是提前申请一大批,自己去管,完全不用库去关心这些事情。

另外一个Future/Promise 遇到的问题是局部变量 holder 的问题。这里有个 case 。程序员写代码时,在局部变量创建完之后可能做很多事情,可能去解析请求的用户来源是谁,解析完后面肯定要用,那我肯定会往后面的 copy 去传,但这样其实是有问题的。就是因为这些代码全是异步的,是一个个代码块在底层的调度器做调度,那这就有一个问题是代码块在底层做调度的 stack 上分配的变量可能已经被释放了,所以会导致这个 Future 在调度的时候 task 变量已经没有了。所以在做这个事情的时候我们就发现写 Future/Promise 对程序员有一个要求是尽可能用栈上的变量。这是我们后来才发现的一个比较小的区隔方式,它会导致你没办法跟原来一样写栈变量往下传,很多时候要用堆上的一些变量去传递。

上面讲的是我们编程模型的选择,下面我想分享一下怎么达到高性能。昨天有些演讲嘉宾也说了,现在英特尔已经发现搞不定单 CPU 去赫兹不停往上升,摩尔定律终不终结其实大家心里都是有一个小小的问号了。就单 CPU 来看,它的性能已经很难再往上提了,但现在厂商怎么做呢,一个 CPU 尽可能 pack 更多的 CPU 进去,比如早些年我看这个24核、32核、64核感觉挺多了,现在 AMD 直接有两三百核来提升单机服务器的性能,但是我们在实践的时候却发现我们在用这么高端、这么大量 CPU 的机器的时候,性能却是没有呈线性提升的,就是在服务器 Scale Up 之后,性能不是平行扩展的。
后来我们发现一个比较大的问题,之前也有很多大牛说的一些Cache 问题,就是这个内存和 CPU 之间的高速通路其实是非常拥堵的,特别在 CPU 变多了之后这条路就更堵了,所以在写高性能程序的时候,Cache 非常的重要。另外就是锁,当 CPU 变多了之后,这些锁之间的竞争开销会导致机器没办法完全发挥出硬件的性能。那现在业界算是公认比较好的能够解决现在单机性能瓶颈的一个模型就是 Shared-Nothing。每个 CPU 核上尽可能只干独立完整的一件事,当然这个事情说起来比较简单。大家写程序都会发现有很多需要共享,就是全局的一些变量,比如我的用户信息肯定是全局共享,不可能每一个 CPU 存一份,因为这样会导致很多不一致的情况。比如最简单的金融付费,一个用户付完费了,其他核心肯定也要看到这个结果,那么这就有一个问题:全局的东西怎么办?

这个是 Shared-Nothing 简单的框架图,就是每个进程和线程之间都尽可能规避这个东西。每个东西做一个事情怎么做呢?其实我们现在网络层就是通过 Reuse Port 去做,非常简单,直接这么去导就行了,通过这样我们网络收发就可以线性了,但全局变量就不行,那我们怎么做?就是有一些异步的进程去处理这一部分的能力,通过 Reuse Port,网络部分有独立的线程去收发,但非常重、非常复杂的东西就通过独立的 worker 去处理这些全局的内容,但在这个过程中是没有锁的,中间会通过无锁队列去传递我想要的信息。比如我需要获取一个用户的信息,通过无锁队列这边网络收发完之后,再向这边发送一个消息,之后全局的数据处理完之后再通过无锁队列返回来,这样中间是没有任何的锁和增强的开销的,这样就达到全局数据的共享,这就是我们解决全局数据的方法理念。
但如果读取非常频繁的情况下怎么去解决呢?我们在每一个收发线程上还会做一些 ThreadLocal 的快照,发过去之后拿回来的东西在本地做缓存,每个线程上去做缓存,这样就解决了需要频繁读写的问题。熟悉 Kernel Reuse Port 的同学可能知道 Reuse Port在处理很多 case 的时候是没办法完整地持续分发的,它只会根据 IP 和 Port 去做。但这有一个问题是,比如现在在4G和wifi之间做切换,IP 和 Port 会变对吧,那变了之后再去做分发的时候,做Shared-Nothing 很重要的一个事情是用户请求一定要转发到同一个线程进程里面。那如果网络一变,它通过 Reuse Port 的方式就不会转发到同一个里面去了,那这种问题在正常 TCP 链接的部分不会出现,因为 TCP 就是根据 IP 和 Port去定义链接的,但在新的一些业务场景比如 Quic、UDP,会出现一个问题:它不是通过 IP 和 Port 来定义一个链接,而是通过协议自带的信息去做,所以在原有的内核的 Reuse Port 方式就完全失效了,没办法做 Shared-Nothing,于是我们在中间内核做了一些模块,根据一些 UDP 协议信息做转发,选择一些 ID 去做。这也是我们在做 Shared-Nothing 时遇到的链接转发的一个问题。

这里我还想讲我们在写的时候遇到另外一个 Shared-Nothing 的问题是原子变量。Share Pointer 大家应该都不陌生,但其实问题挺多的,就是我去做 Atomic Pointer 的时候,它只保证了引用计数的原子性,但在多个线程同时去读写 Share Pointer 时,它不是原子的,不保护那个指针,只保护它的 reference counter。C++ 后来也出了那个 Atomic Share Pointer,早期是通过 atomic_load 的方式来保护。这是现有的做 Pointer 在一个线程之间能够达到安全共享的两种方式。
但虽然有这些东西,用了之后我们发现问题非常多:第一,它的 referencecounter 会导致 Cache 出现问题。比如用 Share Pointer 时一个典型的场景:多个代码块之间都要读取这个指针,但在用这个指针时,原子变量增加和读写都要刷 Cache,导致 Cache 失效,那么就算我在单一线程里面做共享的时候也会发现这个东西导致 CPU 性能大规模地下降,所以在没有做跨线程这种 case 的时候,我们把 Reference Pointer 改成了正常的数据和变量,就不用那个原子的引用计数了,只用一个简单的 int 去做引用计数。
那我怎么规避不同进程之间共享呢?其实我不规避,因为我会保证它只在本进程的不同的上下文去共享,然后针对不同进程的共享,我们会采取跟 atomic_load 一样的方式,会去加一个锁,但是这个锁是有点类似于全局的部分,全局有一个 Local 的池,这个池子里我会尽可能规避这个开销。

简单总结一下,性能部分我们主要是通过 Shared-Nothing 去解决,中间也解决了很多问题,包括 Shared_Ptr、内存管理,包括 Exception Handle 的问题,这一部分是要不停地去深挖每一个细节。性能是需要不停地去优化一个个 case 解决的,不是有一个架构就能解决所有问题。另外是可维护性,我们是通过 Future/Promise 来解决。我们抛弃了原有异步回调的方式,通过 Future/Promise 去不停地去串联代码,尽可能达到线性写代码的方式。

当然 Future/Promise 有一个问题是,大家都这么串行写代码,最后代码会非常长,可能会集中在一个代码块里面,这样对代码的规范管理是要求非常高的,所以在选择工具的时候,大家可能要考虑一下配套的代码管理工具,包括代码的规范。我们认为这个在写 Future/Promise 的时候会写很多,即使有非常好的代码规范和运营方式也会出现很难维护的问题,所以我们希望做到的方式是它能够完全没有任何东西,有点像现在 C++ Coroutine 做的事情,就是在一个代码块里就把事情全部解决。

但现在 Coroutine 问题也挺多,C++ Coroutine 的代码除了前面加 co_await 之外,跟正常的代码没有差别,但这对开发人员要求非常的高,你需要去实现 Awaitable 的成员函数,更像是说针对库开发者提供的,而不是向程序员开发提供的。比如你去实现四个异步函数,就要实现四遍 Awaitable 的对象,那我要实现10个、20个呢?这个复杂度非常高。另外一个问题是做 Awaitable 的时候,比如我的调度函数里面有一个 func 1,再去掉 func 2,再去掉 func 3。假设 func 3 要去做成 C++20 Coroutine 的时候,反过来可能 func 2 用户也不需要知道我这东西也能去 co_await,那 func 2 即使内部没有其他东西是 Coroutine,我也需要去实现 Awaitable,相当于整条调用链上的东西都需要去实现,即使我只有一个函数需要做异步。

可能我们未来服务器上有很多东西要去做,包括现在云原生比较火的一些概念,就是这服务器怎么去做到开包即用,怎么去给到用户就能用上。上午冯富秋老师也说我们怎么尽可能开放硬件上的能力,软件跟硬件怎么去做结合,怎么尽可能去提升这部分的最大化收益。这些是现在包括 Kernel 和社区也都在讨论的 Kernel Bypassing,就是怎么绕过内核,尽可能直接触达硬件。另外就是新的一些硬件也在不停出现, 比如解密卡,包括 FPGA 这一部分,就是我可以在硬件上写我程序,写完之后你直接去用。
最后,很多时候我们希望这个服务是优化部分,就是一些可中断的服务,可能有一些东西不是特别的重要,这一部分是可以抛弃的,可以中断掉的,就比如我日常离线的一些计算,离线的一些压缩,在正常服务器执行过程中,假设低负载可以尽可能利用的时候,我可能会去跑,但如果没有事情的时候我就希望他尽早停掉,就是可中断服务的支持。
原文地址:https://zhuanlan.zhihu.com/p/528344890
作者:linux