@@ -402,9 +408,9 @@ python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
```shell
python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
- configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
- work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
- --target-layer neck.out_layers[0]
+ configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
+ work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
+ --target-layer neck.out_layers[0]
```
@@ -526,4 +532,4 @@ Here we choose to save the inference results under `output` instead of displayin
This completes the transformation deployment of the trained model and checks the inference results. This is the end of the tutorial.
-The full content above can be viewed: [15_minutes_object_detection.ipynb](<>). If you encounter problems during training or testing, please check the \[common troubleshooting steps\](... /recommended_topics/troubleshooting_steps.md) first and feel free to raise an issue if you still can't solve it.
+The full content above can be viewed in [15_minutes_object_detection.ipynb](https://github.com/open-mmlab/mmyolo/blob/dev/demo/15_minutes_object_detection.ipynb). If you encounter problems during training or testing, please check the [common troubleshooting steps](../recommended_topics/troubleshooting_steps.md) first and feel free to open an [issue](https://github.com/open-mmlab/mmyolo/issues/new/choose) if you still can't solve it.
diff --git a/docs/en/get_started/dependencies.md b/docs/en/get_started/dependencies.md
index 06802025b..0d7fc6ad0 100644
--- a/docs/en/get_started/dependencies.md
+++ b/docs/en/get_started/dependencies.md
@@ -4,7 +4,8 @@ Compatible MMEngine, MMCV and MMDetection versions are shown as below. Please in
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc6, \<3.1.0 | mmengine>=0.6.0, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| main | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| 0.6.0 | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
| 0.5.0 | mmdet>=3.0.0rc6, \<3.1.0 | mmengine>=0.6.0, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
| 0.4.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
diff --git a/docs/en/get_started/installation.md b/docs/en/get_started/installation.md
index 113f29041..3259acfbb 100644
--- a/docs/en/get_started/installation.md
+++ b/docs/en/get_started/installation.md
@@ -8,14 +8,14 @@
pip install -U openmim
mim install "mmengine>=0.6.0"
mim install "mmcv>=2.0.0rc4,<2.1.0"
-mim install "mmdet>=3.0.0rc6,<3.1.0"
+mim install "mmdet>=3.0.0,<4.0.0"
```
If you are currently in the mmyolo project directory, you can use the following simplified commands
```shell
cd mmyolo
-pip install -U openmom
+pip install -U openmim
mim install -r requirements/mminstall.txt
```
diff --git a/docs/en/index.rst b/docs/en/index.rst
index a4edc8ef7..1a0ab6c3b 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -19,15 +19,16 @@ You can switch between Chinese and English documents in the top-right corner of
:caption: Recommended Topics
recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
recommended_topics/model_design.md
recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/application_examples/index.rst
recommended_topics/replace_backbone.md
recommended_topics/complexity_analysis.md
recommended_topics/labeling_to_deployment_tutorials.md
recommended_topics/visualization.md
recommended_topics/deploy/index.rst
recommended_topics/troubleshooting_steps.md
- recommended_topics/industry_examples.md
recommended_topics/mm_basics.md
recommended_topics/dataset_preparation.md
@@ -38,6 +39,7 @@ You can switch between Chinese and English documents in the top-right corner of
common_usage/resume_training.md
common_usage/syncbn.md
common_usage/amp_training.md
+ common_usage/ms_training_testing.md
common_usage/tta.md
common_usage/plugins.md
common_usage/freeze_layers.md
diff --git a/docs/en/notes/changelog.md b/docs/en/notes/changelog.md
index 310b930b0..fa3e1a776 100644
--- a/docs/en/notes/changelog.md
+++ b/docs/en/notes/changelog.md
@@ -1,5 +1,43 @@
# Changelog
+## v0.6.0 (15/8/2023)
+
+### Highlights
+
+- Support YOLOv5 instance segmentation
+- Support YOLOX-Pose based on MMPose
+- Add 15 minutes instance segmentation tutorial.
+- YOLOv5 supports using mask annotation to optimize bbox
+- Add Multi-scale training and testing docs
+
+### New Features
+
+- Add training and testing tricks doc (#659)
+- Support setting the cache_size_limit parameter and support mmdet 3.0.0 (#707)
+- Support YOLOv5u and YOLOv6 3.0 inference (#624, #744)
+- Support model-only inference (#733)
+- Add YOLOv8 deepstream config (#633)
+- Add ionogram example in MMYOLO application (#643)
+
+### Bug Fixes
+
+- Fix the browse_dataset for visualization of test and val (#641)
+- Fix installation doc error (#662)
+- Fix yolox-l ckpt link (#677)
+- Fix typos in the YOLOv7 and YOLOv8 diagram (#621, #710)
+- Adjust the order of package imports in `boxam_vis_demo.py` (#655)
+
+### Improvements
+
+- Optimize the `convert_kd_ckpt_to_student.py` file (#647)
+- Add en doc of `FAQ` and `training_testing_tricks` (#691,#693)
+
+### Contributors
+
+A total of 21 developers contributed to this release.
+
+Thank @Lum1104,@azure-wings,@FeiGeChuanShu,@Lingrui Gu,@Nioolek,@huayuan4396,@RangeKing,@danielhonies,@yechenzhi,@JosonChan1998,@kitecats,@Qingrenn,@triple-Mu,@kikefdezl,@zhangrui-wolf,@xin-li-67,@Ben-Louis,@zgzhengSEU,@VoyagerXvoyagerx,@tang576225574,@hhaAndroid
+
## v0.5.0 (2/3/2023)
### Highlights
diff --git a/docs/en/recommended_topics/algorithm_descriptions/yolov8_description.md b/docs/en/recommended_topics/algorithm_descriptions/yolov8_description.md
index a4923b121..70f1686b4 100644
--- a/docs/en/recommended_topics/algorithm_descriptions/yolov8_description.md
+++ b/docs/en/recommended_topics/algorithm_descriptions/yolov8_description.md
@@ -3,7 +3,7 @@
## 0 Introduction
-

+

Figure 1:YOLOv8-P5
@@ -201,7 +201,7 @@ In particular, to ensure that the feature map and image are shown aligned, the o
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # change
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
diff --git a/docs/en/recommended_topics/application_examples/index.rst b/docs/en/recommended_topics/application_examples/index.rst
new file mode 100644
index 000000000..03c091d19
--- /dev/null
+++ b/docs/en/recommended_topics/application_examples/index.rst
@@ -0,0 +1,7 @@
+MMYOLO application examples
+********************
+
+.. toctree::
+ :maxdepth: 1
+
+ ionogram_detection.md
diff --git a/docs/en/recommended_topics/application_examples/ionogram_detection.md b/docs/en/recommended_topics/application_examples/ionogram_detection.md
new file mode 100644
index 000000000..a1bc7cc91
--- /dev/null
+++ b/docs/en/recommended_topics/application_examples/ionogram_detection.md
@@ -0,0 +1,307 @@
+# A benchmark for ionogram real-time object detection based on MMYOLO
+
+## Dataset
+
+Digital ionogram is the most important way to obtain real-time ionospheric information.
+Ionospheric structure detection is of great research significance for accurate extraction of ionospheric key parameters.
+
+This study utilize 4311 ionograms with different seasons obtained by the Chinese Academy of Sciences in Hainan, Wuhan, and Huailai to establish a dataset. The six structures, including Layer E, Es-l, Es-c, F1, F2, and Spread F are manually annotated using [labelme](https://github.com/wkentaro/labelme). [Dataset Download](https://github.com/VoyagerXvoyagerx/Ionogram_detection/releases/download/Dataset/Iono4311.zip)
+
+
+

+
+Preview of annotated images
+
+
+
+1. Dataset prepration
+
+After downloading the data, put it in the root directory of the MMYOLO repository, and use `unzip test.zip` (for Linux) to unzip it to the current folder. The structure of the unzipped folder is as follows:
+
+```shell
+Iono4311/
+├── images
+| ├── 20130401005200.png
+| └── ...
+└── labels
+ ├── 20130401005200.json
+ └── ...
+```
+
+The `images` directory contains input images,while the `labels` directory contains annotation files generated by labelme.
+
+2. Convert the dataset into COCO format
+
+Use the script `tools/dataset_converters/labelme2coco.py` to convert labelme labels to COCO labels.
+
+```shell
+python tools/dataset_converters/labelme2coco.py --img-dir ./Iono4311/images \
+ --labels-dir ./Iono4311/labels \
+ --out ./Iono4311/annotations/annotations_all.json
+```
+
+3. Check the converted COCO labels
+
+To confirm that the conversion process went successfully, use the following command to display the COCO labels on the images.
+
+```shell
+python tools/analysis_tools/browse_coco_json.py --img-dir ./Iono4311/images \
+ --ann-file ./Iono4311/annotations/annotations_all.json
+```
+
+4. Divide dataset into training set, validation set and test set
+
+Set 70% of the images in the dataset as the training set, 15% as the validation set, and 15% as the test set.
+
+```shell
+python tools/misc/coco_split.py --json ./Iono4311/annotations/annotations_all.json \
+ --out-dir ./Iono4311/annotations \
+ --ratios 0.7 0.15 0.15 \
+ --shuffle \
+ --seed 14
+```
+
+The file tree after division is as follows:
+
+```shell
+Iono4311/
+├── annotations
+│ ├── annotations_all.json
+│ ├── class_with_id.txt
+│ ├── test.json
+│ ├── train.json
+│ └── val.json
+├── classes_with_id.txt
+├── images
+├── labels
+├── test_images
+├── train_images
+└── val_images
+```
+
+## Config files
+
+The configuration files are stored in the directory `/projects/misc/ionogram_detection/`.
+
+1. Dataset analysis
+
+To perform a dataset analysis, a sample of 200 images from the dataset can be analyzed using the `tools/analysis_tools/dataset_analysis.py` script.
+
+```shell
+python tools/analysis_tools/dataset_analysis.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ --out-dir output
+```
+
+Part of the output is as follows:
+
+```shell
+The information obtained is as follows:
++------------------------------+
+| Information of dataset class |
++---------------+--------------+
+| Class name | Bbox num |
++---------------+--------------+
+| E | 98 |
+| Es-l | 27 |
+| Es-c | 46 |
+| F1 | 100 |
+| F2 | 194 |
+| Spread-F | 6 |
++---------------+--------------+
+```
+
+This indicates that the distribution of categories in the dataset is unbalanced.
+
+
+

+
+Statistics of object sizes for each category
+
+
+
+According to the statistics, small objects are predominant in the E, Es-l, Es-c, and F1 categories, while medium-sized objects are more common in the F2 and Spread F categories.
+
+2. Visualization of the data processing part in the config
+
+Taking YOLOv5-s as an example, according to the `train_pipeline` in the config file, the data augmentation strategies used during training include:
+
+- Mosaic augmentation
+- Random affine
+- Albumentations (include various digital image processing methods)
+- HSV augmentation
+- Random affine
+
+Use the **'pipeline'** mode of the script `tools/analysis_tools/browse_dataset.py` to obtains all intermediate images in the data pipeline.
+
+```shell
+python tools/analysis_tools/browse_dataset.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ -m pipeline \
+ --out-dir output
+```
+
+
+

+
+Visualization for intermediate images in the data pipeline
+
+
+
+3. Optimize anchor size
+
+Use the script `tools/analysis_tools/optimize_anchors.py` to obtain prior anchor box sizes suitable for the dataset.
+
+```shell
+python tools/analysis_tools/optimize_anchors.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ --algorithm v5-k-means \
+ --input-shape 640 640 \
+ --prior-match-thr 4.0 \
+ --out-dir work_dirs/dataset_analysis_5_s
+```
+
+4. Model complexity analysis
+
+With the config file, the parameters and FLOPs can be calculated by the script `tools/analysis_tools/get_flops.py`. Take yolov5-s as an example:
+
+```shell
+python tools/analysis_tools/get_flops.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
+```
+
+The following output indicates that the model has 7.947G FLOPs with the input shape (640, 640), and a total of 7.036M learnable parameters.
+
+```shell
+==============================
+Input shape: torch.Size([640, 640])
+Model Flops: 7.947G
+Model Parameters: 7.036M
+==============================
+```
+
+## Train and test
+
+1. Train
+
+**Training visualization**: By following the tutorial of [Annotation-to-deployment workflow for custom dataset](https://mmyolo.readthedocs.io/en/dev/recommended_topics/labeling_to_deployment_tutorials.html#id11), this example uses [wandb](https://wandb.ai/site) to visulize training.
+
+**Debug tricks**: During the process of debugging code, sometimes it is necessary to train for several epochs, such as debugging the validation process or checking whether the checkpoint saving meets expectations. For datasets inherited from `BaseDataset` (such as `YOLOv5CocoDataset` in this example), setting `indices` in the `dataset` field can specify the number of samples per epoch to reduce the iteration time.
+
+```python
+train_dataloader = dict(
+ batch_size=train_batch_size_per_gpu,
+ num_workers=train_num_workers,
+ dataset=dict(
+ _delete_=True,
+ type='RepeatDataset',
+ times=1,
+ dataset=dict(
+ type=_base_.dataset_type,
+ indices=200, # set indices=200,represent every epoch only iterator 200 samples
+ data_root=data_root,
+ metainfo=metainfo,
+ ann_file=train_ann_file,
+ data_prefix=dict(img=train_data_prefix),
+ filter_cfg=dict(filter_empty_gt=False, min_size=32),
+ pipeline=_base_.train_pipeline)))
+```
+
+**Start training**:
+
+```shell
+python tools/train.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
+```
+
+2. Test
+
+Specify the path of the config file and the model to start the test:
+
+```shell
+python tools/test.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ work_dirs/yolov5_s-v61_fast_1xb96-100e_ionogram/xxx
+```
+
+## Experiments and results
+
+### Choose a suitable batch size
+
+- Often, the batch size governs the training speed, and the ideal batch size will be the largest batch size supported by the available hardware.
+- If the video memory is not yet fully utilized, doubling the batch size should result in a corresponding doubling (or close to doubling) of the training throughput. This is equivalent to maintaining a constant (or nearly constant) time per step as the batch size increases.
+- Automatic Mixed Precision (AMP) is a technique to accelerate the training with minimal loss in accuracy. To enable AMP training, add `--amp` to the end of the training command.
+
+Hardware information:
+
+- GPU:V100 with 32GB memory
+- CPU:10-core CPU with 40GB memory
+
+Results:
+
+| Model | Epoch(best) | AMP | Batchsize | Num workers | Memory Allocated | Training Time | Val mAP |
+| -------- | ----------- | ----- | --------- | ----------- | ---------------- | ------------- | ------- |
+| YOLOv5-s | 100(82) | False | 32 | 6 | 35.07% | 54 min | 0.575 |
+| YOLOv5-s | 100(96) | True | 32 | 6 | 24.93% | 49 min | 0.578 |
+| YOLOv5-s | 100(100) | False | 96 | 6 | 96.64% | 48 min | 0.571 |
+| YOLOv5-s | 100(100) | True | 96 | 6 | 54.66% | **37** min | 0.575 |
+| YOLOv5-s | 100(90) | True | 144 | 6 | 77.06% | 39 min | 0.573 |
+| YOLOv5-s | 200(148) | True | 96 | 6 | 54.66% | 72 min | 0.575 |
+| YOLOv5-s | 200(188) | True | 96 | **8** | 54.66% | 67 min | 0.576 |
+
+
+

+
+The proportion of data loading time to the total time of each step.
+
+
+
+Based on the results above, we can conclude that
+
+- AMP has little impact on the accuracy of the model, but can significantly reduce memory usage while training.
+- Increasing batch size by three times does not reduce the training time by a corresponding factor of three. According to the `data_time` recorded during training, the larger the batch size, the larger the `data_time`, indicating that data loading has become the bottleneck limiting the training speed. Increasing `num_workers`, the number of processes used to load data, can accelerate the training speed.
+
+### Ablation studies
+
+In order to obtain a training pipeline applicable to the dataset, the following ablation studies with the YOLOv5-s model as an example are performed.
+
+#### Data augmentation
+
+| Aug Method | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_aug0.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb32-100e_ionogram_mosaic.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_mosaic_affine.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_mosaic_affine_albu_hsv.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) |
+| ---------- | ------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------- |
+| Mosaic | | √ | √ | √ | √ |
+| Affine | | | √ | √ | √ |
+| Albu | | | | √ | √ |
+| HSV | | | | √ | √ |
+| Flip | | | | | √ |
+| Val mAP | 0.507 | 0.550 | 0.572 | 0.567 | 0.575 |
+
+The results indicate that mosaic augmentation and random affine transformation can significantly improve the performance on the validation set.
+
+#### Using pre-trained models
+
+If you prefer not to use pre-trained weights, you can simply set `load_from = None` in the config file. For experiments that do not use pre-trained weights, it is recommended to increase the base learning rate by a factor of four and extend the number of training epochs to 200 to ensure adequate model training.
+
+| Model | Epoch(best) | FLOPs(G) | Params(M) | Pretrain | Val mAP | Config |
+| -------- | ----------- | -------- | --------- | -------- | ------- | ------------------------------------------------------------------------------------------------ |
+| YOLOv5-s | 100(82) | 7.95 | 7.04 | Coco | 0.575 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) |
+| YOLOv5-s | 200(145) | 7.95 | 7.04 | None | 0.565 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-200e_ionogram_pre0.py) |
+| YOLOv6-s | 100(54) | 24.2 | 18.84 | Coco | 0.584 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-100e_ionogram.py) |
+| YOLOv6-s | 200(188) | 24.2 | 18.84 | None | 0.557 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-200e_ionogram_pre0.py) |
+
+
+

+
+Comparison of loss reduction during training
+
+
+
+The loss reduction curve shows that when using pre-trained weights, the loss decreases faster. It can be seen that even using models pre-trained on natural image datasets can accelerate model convergence when fine-tuned on radar image datasets.
+
+### Benchmark for ionogram object detection
+
+| Model | epoch(best) | FLOPs(G) | Params(M) | pretrain | val mAP | test mAP | Config | Log |
+| ----------- | ----------- | -------- | --------- | -------- | ------- | -------- | ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+| YOLOv5-s | 100(82) | 7.95 | 7.04 | Coco | 0.575 | 0.584 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov5_s_20230105_213510.json) |
+| YOLOv5-m | 100(70) | 24.05 | 20.89 | Coco | 0.587 | 0.586 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_m-v61_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov5_m_20230106_004642.json) |
+| YOLOv6-s | 100(54) | 24.2 | 18.84 | Coco | 0.584 | 0.594 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_s_20230107_003207.json) |
+| YOLOv6-m | 100(76) | 37.08 | 44.42 | Coco | 0.590 | 0.590 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_m_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_m_20230107_201029.json) |
+| YOLOv6-l | 100(76) | 71.33 | 58.47 | Coco | 0.605 | 0.597 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_l_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_l_20230108_005634.json) |
+| YOLOv7-tiny | 100(78) | 6.57 | 6.02 | Coco | 0.549 | 0.568 | [config](/projects/misc/ionogram_detection/yolov7/yolov7_tiny_fast_1xb16-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov7_tiny_20230215_202837.json) |
+| YOLOv7-x | 100(58) | 94.27 | 70.85 | Coco | 0.602 | 0.595 | [config](/projects/misc/ionogram_detection/yolov7/yolov7_x_fast_1xb16-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov7_x_20230110_165832.json) |
+| rtmdet-tiny | 100(100) | 8.03 | 4.88 | Coco | 0.582 | 0.589 | [config](/projects/misc/ionogram_detection/rtmdet/rtmdet_tiny_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/rtmdet_tiny_20230310_125440.json) |
+| rtmdet-s | 100(92) | 14.76 | 8.86 | Coco | 0.588 | 0.585 | [config](/projects/misc/ionogram_detection/rtmdet/rtmdet_s_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/rtmdet_s_20230310_163853.json) |
diff --git a/docs/en/recommended_topics/deploy/mmdeploy_guide.md b/docs/en/recommended_topics/deploy/mmdeploy_guide.md
index 69258f540..096d39fbc 100644
--- a/docs/en/recommended_topics/deploy/mmdeploy_guide.md
+++ b/docs/en/recommended_topics/deploy/mmdeploy_guide.md
@@ -4,7 +4,7 @@
MMDeploy is an open-source deep learning model deployment toolset. It is a part of the [OpenMMLab](https://openmmlab.com/) project, and provides **a unified experience of exporting different models** to various platforms and devices of the OpenMMLab series libraries. Using MMDeploy, developers can easily export the specific compiled SDK they need from the training result, which saves a lot of effort.
-More detailed introduction and guides can be found [here](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/get_started.md)
+More detailed introduction and guides can be found [here](https://mmdeploy.readthedocs.io/en/latest/get_started.html)
## Supported Algorithms
@@ -19,6 +19,14 @@ Currently our deployment kit supports on the following models and backends:
Note: ncnn and other inference backends support are coming soon.
+## Installation
+
+Please install mmdeploy by following [this](https://mmdeploy.readthedocs.io/en/latest/get_started.html) guide.
+
+```{note}
+If you install mmdeploy prebuilt package, please also clone its repository by 'git clone https://github.com/open-mmlab/mmdeploy.git --depth=1' to get the 'tools' file for deployment.
+```
+
## How to Write Config for MMYOLO
All config files related to the deployment are located at [`configs/deploy`](../../../configs/deploy/).
@@ -45,7 +53,7 @@ codebase_config = dict(
- `score_threshold`: set the score threshold to filter candidate bboxes before `nms`
- `confidence_threshold`: set the confidence threshold to filter candidate bboxes before `nms`
-- `iou_threshold`: set the `iou` threshold for removing duplicates in `nums`
+- `iou_threshold`: set the `iou` threshold for removing duplicates in `nms`
- `max_output_boxes_per_class`: set the maximum number of bboxes for each class
- `pre_top_k`: set the number of fixedcandidate bboxes before `nms`, sorted by scores
- `keep_top_k`: set the number of output candidate bboxs after `nms`
@@ -61,7 +69,7 @@ Taking `YOLOv5` of MMYOLO as an example, here are the details:
_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(
type='LetterResize',
scale=_base_.img_scale,
@@ -87,7 +95,7 @@ test_dataloader = dict(
#### 2. Deployment Config
-Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy \`YOLOv5\` to \`ONNXRuntim\` with static inputs.
+Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy `YOLOv5` to `ONNXRuntime` with static inputs.
```python
_base_ = ['./base_static.py']
@@ -128,7 +136,7 @@ backend_config = dict(
use_efficientnms = False
```
-`backend_config` indices the backend with `type=‘tensorrt’`.
+`backend_config` indices the backend with `type='tensorrt'`.
Different from `ONNXRuntime` deployment configuration, `TensorRT` needs to specify the input image size and the parameters required to build the engine file, including:
@@ -206,6 +214,8 @@ Note: Int8 quantization support will soon be released.
### Usage
+#### Deploy with MMDeploy Tools
+
Set the root directory of `MMDeploy` as an env parameter `MMDEPLOY_DIR` using `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy` command.
```shell
@@ -237,6 +247,125 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
- `--show`: show the result on screen or not
- `--dump-info`: output SDK information or not
+#### Deploy with MMDeploy API
+
+Suppose the working directory is the root path of mmyolo. Take [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) model as an example. You can download its checkpoint from [here](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth), and then convert it to onnx model as follows:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## Model specification
+
+Before moving on to model inference chapter, let's know more about the converted result structure which is very important for model inference. It is saved in the directory specified with `--wodk_dir`.
+
+The converted results are saved in the working directory `mmdeploy_models/mmyolo/onnx` in the previous example. It includes:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+in which,
+
+- **end2end.onnx**: backend model which can be inferred by ONNX Runtime
+- ***xxx*.json**: the necessary information for mmdeploy SDK
+
+The whole package **mmdeploy_models/mmyolo/onnx** is defined as **mmdeploy SDK model**, i.e., **mmdeploy SDK model** includes both backend model and inference meta information.
+
+## Model inference
+
+### Backend model inference
+
+Take the previous converted `end2end.onnx` model as an example, you can use the following code to inference the model and visualize the results.
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+With the above code, you can find the inference result `output_detection.png` in `work_dir`.
+
+### SDK model inference
+
+You can also perform SDK model inference like following,
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
+
## How to Evaluate Model
### Usage
@@ -248,40 +377,38 @@ python3 ${MMDEPLOY_DIR}/tools/test.py \
${DEPLOY_CFG} \
${MODEL_CFG} \
--model ${BACKEND_MODEL_FILES} \
- [--out ${OUTPUT_PKL_FILE}] \
- [--format-only] \
- [--metrics ${METRICS}] \
- [--show] \
- [--show-dir ${OUTPUT_IMAGE_DIR}] \
- [--show-score-thr ${SHOW_SCORE_THR}] \
--device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
[--cfg-options ${CFG_OPTIONS}] \
- [--metric-options ${METRIC_OPTIONS}]
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
[--log2file work_dirs/output.txt]
- [--batch-size ${BATCH_SIZE}]
[--speed-test] \
[--warmup ${WARM_UP}] \
- [--log-interval ${LOG_INTERVERL}]
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
```
### Parameter Description
-- `deploy_cfg`: set the deployment config file path
-- `model_cfg`: set the MMYOLO model config file path
-- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine"
-- `--out`: save the output result in pickle format, use only when you need it
-- `--format-only`: format the output without evaluating it. It is useful when you want to format the result into a specific format and submit it to a test server
-- `--metrics`: use the specific metric supported in MMYOLO to evaluate, such as "proposal" in COCO format data.
-- `--show`: show the evaluation result on screen or not
-- `--show-dir`: save the evaluation result to this directory, valid only when specified
-- `--show-score-thr`: show the threshold for the detected bboxes or not
-- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA
-- `--cfg-options`: pass in additional configs, which will override the current deployment configs
-- `--metric-options`: add custom options for metrics. The key-value pair format in xxx=yyy will be the kwargs of the dataset.evaluate() method
-- `--log2file`: save the evaluation results (with the speed) to a file
-- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`
-- `--speed-test`: test the inference speed or not
-- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified
-- `--log-interval`: set the interval between each log, works only when `speed-test` is specified
+- `deploy_cfg`: set the deployment config file path.
+- `model_cfg`: set the MMYOLO model config file path.
+- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine".
+- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA.
+- `--work-dir`: the directory to save the file containing evaluation metrics.
+- `--cfg-options`: pass in additional configs, which will override the current deployment configs.
+- `--show`: show the evaluation result on screen or not.
+- `--show-dir`: save the evaluation result to this directory, valid only when specified.
+- `--interval`: set the display interval between each two evaluation results.
+- `--wait-time`: set the display time of each window.
+- `--log2file`: log evaluation results and speed to file.
+- `--speed-test`: test the inference speed or not.
+- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified.
+- `--log-interval`: the interval between each log, works only when `speed-test` is specified.
+- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`.
+- `--uri`: Remote ipv4:port or ipv6:port for inference on edge device.
Note: other parameters in `${MMDEPLOY_DIR}/tools/test.py` are used for speed test, they will not affect the evaluation results.
diff --git a/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
index 7eb85b24d..321a6734f 100644
--- a/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
+++ b/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -28,7 +28,7 @@ Here is a example in [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo
_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(
type='LetterResize',
scale=_base_.img_scale,
@@ -113,7 +113,7 @@ batch_shapes_cfg = dict(
extra_pad_ratio=0.5)
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -252,6 +252,7 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
--work-dir work_dir \
--show \
--device cpu
+ --dump-info
```
#### TensorRT
@@ -265,19 +266,20 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
--work-dir work_dir \
--show \
--device cuda:0
+ --dump-info
```
When convert the model using the above commands, you will find the following files under the `work_dir` folder:
-
+
or
-
+
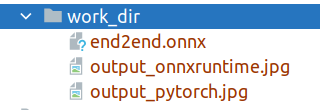
-After exporting to `onnxruntime`, you will get three files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model.
+After exporting to `onnxruntime`, you will get six files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
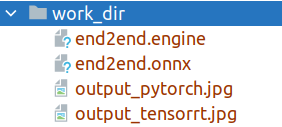
-After exporting to `TensorRT`, you will get the four files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment.
+After exporting to `TensorRT`, you will get the seven files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
## How to Evaluate Model
@@ -429,4 +431,142 @@ python3 ${MMDEPLOY_DIR}/tools/profiler.py \
## Model Inference
-TODO
+### Backend Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
diff --git a/docs/en/recommended_topics/industry_examples.md b/docs/en/recommended_topics/industry_examples.md
deleted file mode 100644
index 2380143b9..000000000
--- a/docs/en/recommended_topics/industry_examples.md
+++ /dev/null
@@ -1 +0,0 @@
-# MMYOLO industry examples
diff --git a/docs/en/recommended_topics/training_testing_tricks.md b/docs/en/recommended_topics/training_testing_tricks.md
new file mode 100644
index 000000000..48ce25f8b
--- /dev/null
+++ b/docs/en/recommended_topics/training_testing_tricks.md
@@ -0,0 +1,310 @@
+# Training testing tricks
+
+MMYOLO has already supported most of the YOLO series object detection related algorithms. Different algorithms may involve some practical tricks. This section will describe in detail the commonly used training and testing tricks supported by MMYOLO based on the implemented object detection algorithms.
+
+## Training tricks
+
+### Improve performance of detection
+
+#### 1. Multi-scale training
+
+In the field of object detection, multi-scale training is a very common trick. However, in YOLO, most of the models are trained with a single-scale input of 640x640. There are two reasons for this:
+
+1. Single-scale training is faster than multi-scale training. When the training epoch is at 300 or 500, training efficiency is a major concern for users. Multi-scale training will be slower.
+2. Multi-scale augmentation is implied in the training pipeline, which is equivalent to the application of multi-scale training, such as the 'Mosaic', 'RandomAffine' and 'Resize', so there is no need to introduce the multi-scale training of model input again.
+
+Through experiments on the COCO dataset, it is founded that the multi-scale training is introduced directly after the output of YOLOv5's DataLoader, the actual performance improvement is very small. If you want to start multi-scale training for YOLO series algorithms in MMYOLO, you can refer to [ms_training_testing](../common_usage/ms_training_testing.md),
+however, this does not mean that there are no significant gains in user-defined dataset fine-tuning mode
+
+#### 2 Use Mask annotation to optimize object detection performance
+
+When the dataset annotation is complete, such as boundary box annotation and instance segmentation annotation exist at the same time, but only part of the annotation is required for the task, the task can be trained with complete data annotation to improve the performance.
+In object detection, we can also learn from instance segmentation annotation to improve the performance of object detection. The following is the detection result of additional instance segmentation annotation optimization introduced by YOLOv8. The performance gains are shown below:
+
+
+

+
+
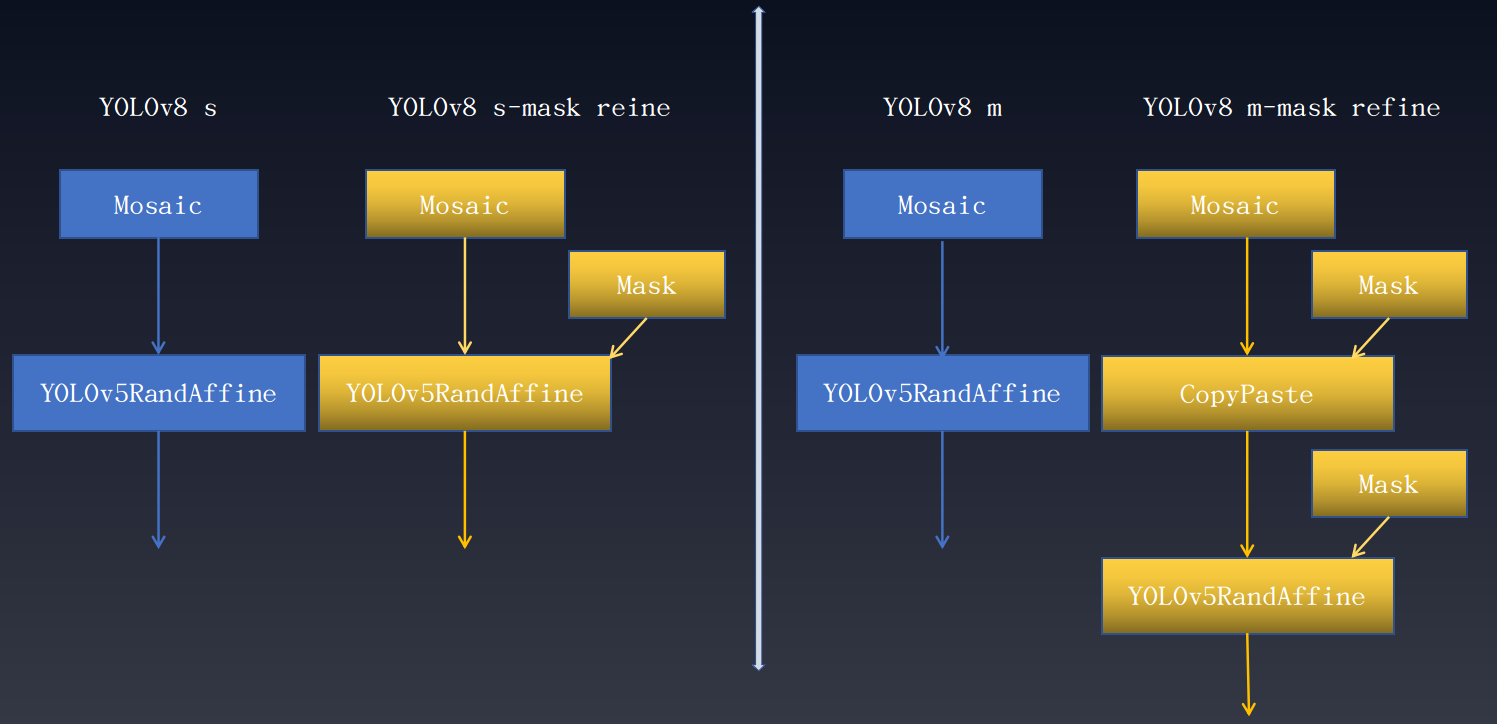
+As shown in the figure, different scale models have different degrees of performance improvement.
+It is important to note that 'Mask Refine' only functions in the data enhancement phase and does not require any changes to other training parts of the model and does not affect the speed of training. The details are as follows:
+
+
+
+
+
+The above-mentioned Mask represents a data augmentation transformation in which instance segmentation annotations play a key role.
+The application of this technique to other YOLO series has varying degrees of increase.
+
+#### 3 Turn off strong augmentation in the later stage of training to improve detection performance
+
+This strategy is proposed for the first time in YOLOX algorithm and can greatly improve the detection performance.
+The paper points out that Mosaic+MixUp can greatly improve the target detection performance, but the training pictures are far from the real distribution of natural pictures, and Mosaic's large number of cropping operations will bring many inaccurate label boxes,
+therefore, YOLOX proposes to turn off the strong enhancement in the last 15 epochs and use the weaker enhancement instead, so that the detector can avoid the influence of inaccurate labeled boxes and complete the final convergence under the data distribution of the natural picture.
+
+This strategy has been applied to most YOLO algorithms. Taking YOLOv8 as an example, its data augmentation pipeline is shown as follows:
+
+
+

+
+
+However, when to turn off the strong augmentation is a hyper-parameter. If you turn off the strong augmentation too early, it may not give full play to Mosaic and other strong augmentation effects. If you turn off the strong enhancement too late, it will have no gain because it has been overfitted before. This phenomenon can be observed in YOLOv8 experiment
+
+| Backbone | Mask Refine | box AP | Epoch of best mAP |
+| :------: | :---------: | :---------: | :---------------: |
+| YOLOv8-n | No | 37.2 | 500 |
+| YOLOv8-n | Yes | 37.4 (+0.2) | 499 |
+| YOLOv8-s | No | 44.2 | 430 |
+| YOLOv8-s | Yes | 45.1 (+0.9) | 460 |
+| YOLOv8-m | No | 49.8 | 460 |
+| YOLOv8-m | Yes | 50.6 (+0.8) | 480 |
+| YOLOv8-l | No | 52.1 | 460 |
+| YOLOv8-l | Yes | 53.0 (+0.9) | 491 |
+| YOLOv8-x | No | 52.7 | 450 |
+| YOLOv8-x | Yes | 54.0 (+1.3) | 460 |
+
+As can be seen from the above table:
+
+- Large models trained on COCO dataset for 500 epochs are prone to overfitting, and disabling strong augmentations such as Mosaic may not be effective in reducing overfitting in such cases.
+- Using Mask annotations can alleviate overfitting and improve performance
+
+#### 4 Add pure background images to suppress false positives
+
+For non-open-world datasets in object detection, both training and testing are conducted on a fixed set of classes, and there is a possibility of producing false positives when applied to images with classes that have not been trained. A common mitigation strategy is to add a certain proportion of pure background images.
+In most YOLO series, the function of suppressing false positives by adding pure background images is enabled by default. Users only need to set train_dataloader.dataset.filter_cfg.filter_empty_gt to False, indicating that pure background images should not be filtered out during training.
+
+#### 5 Maybe the AdamW works wonders
+
+YOLOv5, YOLOv6, YOLOv7 and YOLOv8 all adopt the SGD optimizer, which is strict about parameter settings, while AdamW is on the contrary, which is not so sensitive to learning rate. If user fine-tune a custom-dataset can try to select the AdamW optimizer. We did a simple trial in YOLOX and found that replacing the optimizer with AdamW on the tiny, s, and m scale models all had some improvement.
+
+| Backbone | Size | Batch Size | RTMDet-Hyp | Box AP |
+| :--------: | :--: | :--------: | :--------: | :---------: |
+| YOLOX-tiny | 416 | 8xb8 | No | 32.7 |
+| YOLOX-tiny | 416 | 8xb32 | Yes | 34.3 (+1.6) |
+| YOLOX-s | 640 | 8xb8 | No | 40.7 |
+| YOLOX-s | 640 | 8xb32 | Yes | 41.9 (+1.2) |
+| YOLOX-m | 640 | 8xb8 | No | 46.9 |
+| YOLOX-m | 640 | 8xb32 | Yes | 47.5 (+0.6) |
+
+More details can be found in [configs/yolox/README.md](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolox/README.md#--results-and-models).
+
+#### 6 Consider ignore scenarios to avoid uncertain annotations
+
+Take CrowdHuman as an example, a crowded pedestrian detection dataset. Here's a typical image:
+
+
+

+
+
+The image is sourced from [detectron2 issue](https://github.com/facebookresearch/detectron2/issues/1909). The area marked with a yellow cross indicates the `iscrowd` label. There are two reasons for this:
+
+- This area is not a real person, such as the person on the poster
+- The area is too crowded to mark
+
+In this scenario, you cannot simply delete such annotations, because once you delete them, it means treating them as background areas during training. However, they are different from the background. Firstly, the people on the posters are very similar to real people, and there are indeed people in crowded areas that are difficult to annotate. If you simply train them as background, it will cause false negatives. The best approach is to treat the crowded area as an ignored region, where any output in this area is directly ignored, with no loss calculated and no model fitting enforced.
+
+MMYOLO quickly and easily verifies the function of 'iscrowd' annotation on YOLOv5. The performance is as follows:
+
+| Backbone | ignore_iof_thr | box AP50(CrowDHuman Metric) | MR | JI |
+| :------: | :------------: | :-------------------------: | :--: | :---: |
+| YOLOv5-s | -1 | 85.79 | 48.7 | 75.33 |
+| YOLOv5-s | 0.5 | 86.17 | 48.8 | 75.87 |
+
+`ignore_iof_thr` set to -1 indicates that the ignored labels are not considered, and it can be seen that the performance is improved to a certain extent, more details can be found in [CrowdHuman results](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/README.md#crowdhuman). If you encounter similar situations in your custom dataset, it is recommended that you consider using `ignore` labels to avoid uncertain annotations.
+
+#### 7 Use knowledge distillation
+
+Knowledge distillation is a widely used technique that can transfer the performance of a large model to a smaller model, thereby improving the detection performance of the smaller model. Currently, MMYOLO and MMRazor have supported this feature and conducted initial verification on RTMDet.
+
+| Model | box AP |
+| :------------: | :---------: |
+| RTMDet-tiny | 41.0 |
+| RTMDet-tiny \* | 41.8 (+0.8) |
+| RTMDet-s | 44.6 |
+| RTMDet-s \* | 45.7 (+1.1) |
+| RTMDet-m | 49.3 |
+| RTMDet-m \* | 50.2 (+0.9) |
+| RTMDet-l | 51.4 |
+| RTMDet-l \* | 52.3 (+0.9) |
+
+`*` indicates the result of using the large model distillation, more details can be found in [Distill RTMDet](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet/distillation).
+
+#### 8 Stronger augmentation parameters are used for larger models
+
+If you have modified the model based on the default configuration or replaced the backbone network, it is recommended to scale the data augmentation parameters based on the current model size. Generally, larger models require stronger augmentation parameters, otherwise they may not fully leverage the benefits of large models. Conversely, if strong augmentations are applied to small models, it may result in underfitting. Taking RTMDet as an example, we can observe the data augmentation parameters for different model sizes.
+
+
+

+
+
+`random_resize_ratio_range` represents the random scaling range of `RandomResize`, and `mosaic_max_cached_images/mixup_max_cached_images` represents the number of cached images during `Mosaic/MixUp` augmentation, which can be used to adjust the strength of augmentation. The YOLO series models all follow the same set of parameter settings principles.
+
+### Accelerate training speed
+
+#### 1 Enable cudnn_benchmark for single-scale training
+
+Most of the input image sizes in the YOLO series algorithms are fixed, which is single-scale training. In this case, you can turn on cudnn_benchmark to accelerate the training speed. This parameter is mainly set for PyTorch's cuDNN underlying library, and setting this flag can allow the built-in cuDNN to automatically find the most efficient algorithm that is best suited for the current configuration to optimize the running efficiency. If this flag is turned on in multi-scale mode, it will continuously search for the optimal algorithm, which may slow down the training speed instead.
+
+To enable `cudnn_benchmark` in MMYOLO, you can set `env_cfg = dict(cudnn_benchmark=True)` in the configuration.
+
+#### 2 Use Mosaic and MixUp with caching
+
+If you have applied Mosaic and MixUp in your data augmentation, and after investigating the training bottleneck, it is found that the random image reading is causing the issue, then it is recommended to replace the regular Mosaic and MixUp with the cache-enabled versions proposed in RTMDet.
+
+| Data Aug | Use cache | ms/100 imgs |
+| :------: | :-------: | :---------: |
+| Mosaic | No | 87.1 |
+| Mosaic | Yes | 24.0 |
+| MixUp | No | 19.3 |
+| MixUp | Yes | 12.4 |
+
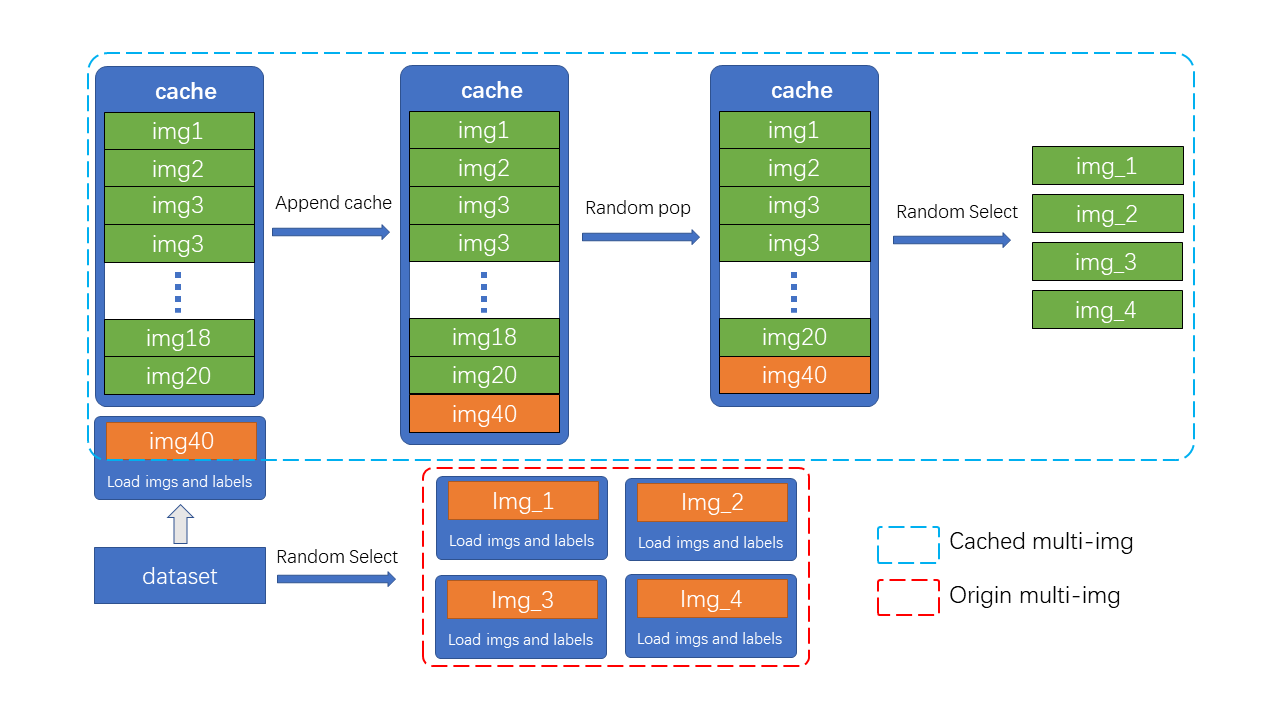
+Mosaic and MixUp involve mixing multiple images, and their time consumption is K times that of ordinary data augmentation (K is the number of images mixed). For example, in YOLOv5, when doing Mosaic each time, the information of 4 images needs to be reloaded from the hard disk. However, the cached version of Mosaic and MixUp only needs to reload the current image, while the remaining images involved in the mixed augmentation are obtained from the cache queue, greatly improving efficiency by sacrificing a certain amount of memory space.
+
+
+
+
+
+As shown in the figure, N preloaded images and label data are stored in the cache queue. In each training step, only one new image and its label data need to be loaded and updated in the cache queue. (Images in the cache queue can be duplicated, as shown in the figure with img3 appearing twice.) If the length of the cache queue exceeds the preset length, a random image will be popped out. When it is necessary to perform mixed data augmentation, only the required images need to be randomly selected from the cache for concatenation or other processing, without the need to load all images from the hard disk, thus saving image loading time.
+
+### Reduce the number of hyperparameter
+
+YOLOv5 provides some practical methods for reducing the number of hyperparameter, which are described below.
+
+#### 1 Adaptive loss weighting, reducing one hyperparameter
+
+In general, it can be challenging to set hyperparameters specifically for different tasks or categories. YOLOv5 proposes some adaptive methods for scaling loss weights based on the number of classes and the number of detection output layers have been proposed based on practical experience, as shown below:
+
+```python
+# scaled based on number of detection layers
+loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=loss_cls_weight *
+ (num_classes / 80 * 3 / num_det_layers)),
+loss_bbox=dict(
+ type='IoULoss',
+ iou_mode='ciou',
+ bbox_format='xywh',
+ eps=1e-7,
+ reduction='mean',
+ loss_weight=loss_bbox_weight * (3 / num_det_layer
+ return_iou=True),
+loss_obj=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=loss_obj_weight *
+ ((img_scale[0] / 640)**2 * 3 / num_det_layers)),
+```
+
+`loss_cls` can adaptively scale `loss_weight` based on the custom number of classes and the number of detection layers, `loss_bbox` can adaptively calculate based on the number of detection layers, and `loss_obj` can adaptively scale based on the input image size and the number of detection layers. This strategy allows users to avoid setting Loss weight hyperparameters.
+It should be noted that this is only an empirical principle and not necessarily the optimal setting combination, it should be used as a reference.
+
+#### 2 Adaptive Weight Decay and Loss output values base on Batch Size, reducing two hyperparameters
+
+In general,when training on different `Batch Size`, it is necessary to follow the rule of automatic learning rate scaling. However, validation on various datasets shows that YOLOv5 can achieve good results without scaling the learning rate when changing the Batch Size, and sometimes scaling can even lead to worse results. The reason lies in the technique of `Weight Decay` and Loss output based on `Batch Size` adaptation in the code. In YOLOv5, `Weight Decay` and Loss output values will be scaled based on the total `Batch Size` being trained. The corresponding code is:
+
+```python
+# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/engine/optimizers/yolov5_optim_constructor.py#L86
+if 'batch_size_per_gpu' in optimizer_cfg:
+ batch_size_per_gpu = optimizer_cfg.pop('batch_size_per_gpu')
+ # No scaling if total_batch_size is less than
+ # base_total_batch_size, otherwise linear scaling.
+ total_batch_size = get_world_size() * batch_size_per_gpu
+ accumulate = max(
+ round(self.base_total_batch_size / total_batch_size), 1)
+ scale_factor = total_batch_size * \
+ accumulate / self.base_total_batch_size
+ if scale_factor != 1:
+ weight_decay *= scale_factor
+ print_log(f'Scaled weight_decay to {weight_decay}', 'current')
+```
+
+```python
+# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/dense_heads/yolov5_head.py#L635
+ _, world_size = get_dist_info()
+ return dict(
+ loss_cls=loss_cls * batch_size * world_size,
+ loss_obj=loss_obj * batch_size * world_size,
+ loss_bbox=loss_box * batch_size * world_size)
+```
+
+The weight of Loss varies in different Batch Sizes, and generally, the larger Batch Size means most larger the Loss and gradient. I personally speculate that this can be equivalent to a scenario of linearly increasing learning rate when Batch Size increases.
+In fact, from the [YOLOv5 Study: mAP vs Batch-Size](https://github.com/ultralytics/yolov5/discussions/2452) of YOLOv5, it can be found that it is desirable for users to achieve similar performance without modifying other parameters when modifying the Batch Size. The above two strategies are very good training techniques.
+
+### Save memory on GPU
+
+How to reduce training memory usage is a frequently discussed issue, and there are many techniques involved. The training executor of MMYOLO comes from MMEngine, so you can refer to the MMEngine documentation for how to reduce training memory usage. Currently, MMEngine supports gradient accumulation, gradient checkpointing, and large model training techniques, details of which can be found in the
+[SAVE MEMORY ON GPU](https://mmengine.readthedocs.io/zh_CN/latest/common_usage/save_gpu_memory.html).
+
+## Testing trick
+
+### Balance between inference speed and testing accuracy
+
+During model performance testing, we generally require a higher mAP, but in practical applications or inference, we want the model to perform faster while maintaining low false positive and false negative rates. In other words, the testing only focuses on mAP while ignoring post-processing and evaluation speed, while in practical applications, a balance between speed and accuracy is pursued.
+In the YOLO series, it is possible to achieve a balance between speed and accuracy by controlling certain parameters. In this example, we will describe this in detail using YOLOv5.
+
+#### 1 Avoiding multiple class outputs for a single detection box during inference
+
+YOLOv5 uses BCE Loss (use_sigmoid=True) during the training of the classification branch. Assuming there are 4 object categories, the number of categories output by the classification branch is 4 instead of 5. Moreover, due to the use of sigmoid instead of softmax prediction, it is possible to predict multiple detection boxes that meet the filtering threshold at a certain position, which means that there may be a situation where one predicted bbox corresponds to multiple predicted labels. This is shown in the figure below:
+
+
+

+
+
+Generally, when calculating mAP, the filtering threshold is set to 0.001. Due to the non-competitive prediction mode of sigmoid, one box may correspond to multiple labels. This calculation method can increase the recall rate when calculating mAP, but it may not be convenient for practical applications.
+
+One common approach is to increase the filtering threshold. However, if you don't want to have many false negatives, it is recommended to set the `multi_label` parameter to False. It is located in the configuration file at `mode.test_cfg.multi_label` and its default value is True, which allows one detection box to correspond to multiple labels.
+
+#### 2 Simplify test pipeline
+
+Note that the test pipeline for YOLOv5 is as follows:
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+It uses two different Resizes with different functions, with the aim of improving the mAP value during evaluation. In actual deployment, you can simplify this pipeline as shown below:
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=True,
+ use_mini_pad=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+In practical applications, YOLOv5 algorithm uses a simplified pipeline with multi_label set to False, score_thr increased to 0.25, and iou_threshold reduced to 0.45.
+In the YOLOv5 configuration, we provide a set of configuration parameters for detection on the ground, as detailed in [yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py).
+
+#### 3 Batch Shape speeds up the testing speed
+
+Batch Shape is a testing technique proposed in YOLOv5 that can speed up inference. The idea is to no longer require that all images in the testing process be 640x640, but to test at variable scales, as long as the shapes within the current batch are the same. This approach can reduce additional image pixel padding and speed up the inference process. The specific implementation of Batch Shape can be found in the [link](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/datasets/utils.py#L55).
+Almost all algorithms in MMYOLO default to enabling the Batch Shape strategy during testing. If users want to disable this feature, you can set `val_dataloader.dataset.batch_shapes_cfg=None`.
+
+In practical applications, because dynamic shape is not as fast and efficient as fixed shape. Therefore, this strategy is generally not used in real-world scenarios.
+
+### TTA improves test accuracy
+
+Data augmentation with TTA (Test Time Augmentation) is a versatile trick that can improve the performance of object detection models and is particularly useful in competition scenarios. MMYOLO has already supported TTA, and it can be enabled simply by adding `--tta` when testing. For more details, please refer to the [TTA](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/common_usage/tta.md).
diff --git a/docs/en/recommended_topics/visualization.md b/docs/en/recommended_topics/visualization.md
index 30caa9e11..f986648f3 100644
--- a/docs/en/recommended_topics/visualization.md
+++ b/docs/en/recommended_topics/visualization.md
@@ -90,7 +90,7 @@ The original `test_pipeline` is:
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -111,7 +111,7 @@ Change to the following version:
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # change the LetterResize to mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
@@ -197,7 +197,7 @@ The original `test_pipeline` is:
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -218,7 +218,7 @@ Change to the following version:
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # change the LetterResize to mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
diff --git a/docs/en/tutorials/config.md b/docs/en/tutorials/config.md
index 01937f300..448452243 100644
--- a/docs/en/tutorials/config.md
+++ b/docs/en/tutorials/config.md
@@ -86,12 +86,10 @@ The training and testing data flow of YOLOv5 have a certain difference. We will
```python
dataset_type = 'CocoDataset' # Dataset type, this will be used to define the dataset
data_root = 'data/coco/' # Root path of data
-file_client_args = dict(backend='disk') # file client arguments, default backend loads from local disk
pre_transform = [ # Training data loading pipeline
dict(
- type='LoadImageFromFile', # First pipeline to load images from file path
- file_client_args=file_client_args), # file client arguments, default backend loads from local disk
+ type='LoadImageFromFile'), # First pipeline to load images from file path
dict(type='LoadAnnotations', # Second pipeline to load annotations for current image
with_bbox=True) # Whether to use bounding box, True for detection
]
@@ -156,8 +154,7 @@ In the testing phase of YOLOv5, the [Letter Resize](https://github.com/open-mmla
```python
test_pipeline = [ # Validation/ Testing dataloader config
dict(
- type='LoadImageFromFile', # First pipeline to load images from file path
- file_client_args=file_client_args), # file client arguments, default backend loads from local disk
+ type='LoadImageFromFile'), # First pipeline to load images from file path
dict(type='YOLOv5KeepRatioResize', # Second pipeline to resize images with the same aspect ratio
scale=img_scale), # Pipeline that resizes the images
dict(
@@ -475,8 +472,7 @@ train_pipeline = [
test_pipeline = [
dict(
- type='LoadImageFromFile',
- file_client_args={{_base_.file_client_args}}),
+ type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -517,7 +513,6 @@ E.g:
```python
_base_ = '../_base_/default_runtime.py'
-file_client_args = {{_base_.file_client_args}} # `file_client_args` equals to `file_client_args` that defined in the _base_ config
pre_transform = _base_.pre_transform # `pre_transform` equals to `pre_transform` in the _base_ config
```
diff --git a/docs/en/tutorials/custom_installation.md b/docs/en/tutorials/custom_installation.md
index 327de64ec..604a77a30 100644
--- a/docs/en/tutorials/custom_installation.md
+++ b/docs/en/tutorials/custom_installation.md
@@ -75,7 +75,7 @@ thus we only need to install MMEngine, MMCV, MMDetection, and MMYOLO with the fo
!pip3 install openmim
!mim install "mmengine>=0.6.0"
!mim install "mmcv>=2.0.0rc4,<2.1.0"
-!mim install "mmdet>=3.0.0rc6,<3.1.0"
+!mim install "mmdet>=3.0.0,<4.0.0"
```
**Step 2.** Install MMYOLO from the source.
diff --git a/docs/en/tutorials/faq.md b/docs/en/tutorials/faq.md
index b79f27207..ca2a0b25f 100644
--- a/docs/en/tutorials/faq.md
+++ b/docs/en/tutorials/faq.md
@@ -8,12 +8,94 @@ Why do we need to launch MMYOLO? Why do we need to open a separate repository in
**(1) Unified operation and inference platform**
-At present, there are very many improved algorithms for YOLO in the field of target detection, and they are very popular, but such algorithms are based on different frameworks for different back-end implementations, and there are large differences, lacking a unified and convenient fair evaluation process from training to deployment.
+At present, there are very many improved algorithms for YOLO in the field of target detection, and they are very popular, but such algorithms are based on different frameworks for different back-end implementations, and there are significant differences, lacking a unified and convenient fair evaluation process from training to deployment.
**(2) Protocol limitations**
-As we all know, YOLOv5 and its derived algorithms such as YOLOv6 and YOLOv7 are GPL 3.0 protocols, which are different from the Apache protocol of MMDetection. Due to the protocol issue, it is not possible to incorporate MMYOLO directly into MMDetection.
+As we all know, YOLOv5 and its derived algorithms, such as YOLOv6 and YOLOv7 are GPL 3.0 protocols, which differ from the Apache protocol of MMDetection. Therefore, due to the protocol issue, it is not possible to incorporate MMYOLO directly into MMDetection.
**(3) Multitasking support**
-There is another far-reaching reason: **MMYOLO tasks are not limited to MMDetection**, and more tasks will be supported in the future, such as MMPose based keypoint related applications and MMTracking based tracking related applications, so it is not suitable to be directly incorporated into MMDetection.
+There is another far-reaching reason: **MMYOLO tasks are not limited to MMDetection**, and more tasks will be supported in the future, such as MMPose based keypoint-related applications and MMTracking based tracking related applications, so it is not suitable to be directly incorporated into MMDetection.
+
+## What is the projects folder used for?
+
+The `projects` folder is newly introduced in OpenMMLab 2.0. There are three primary purposes:
+
+1. facilitate community contributors: Since OpenMMLab series codebases have a rigorous code management process, this inevitably leads to long algorithm reproduction cycles, which is not friendly to community contributions.
+2. facilitate rapid support for new algorithms: A long development cycle can also lead to another problem users may not be able to experience the latest algorithms as soon as possible.
+3. facilitate rapid support for new approaches and features: New approaches or new features may be incompatible with the current design of the codebases and cannot be quickly incorporated.
+
+In summary, the `projects` folder solves the problems of slow support for new algorithms and complicated support for new features due to the long algorithm reproduction cycle. Each folder in `projects` is an entirely independent project, and community users can quickly support some algorithms in the current version through `projects`. This allows the community to quickly use new algorithms and features that are difficult to adapt in the current version. When the design is stable or the code meets the merge specification, it will be considered to merge into the main branch.
+
+## Why does the performance drop significantly by switching the YOLOv5 backbone to Swin?
+
+In [Replace the backbone network](../recommended_topics/replace_backbone.md), we provide many tutorials on replacing the backbone module. However, you may not get a desired result once you replace the module and start directly training the model. This is because different networks have very distinct hyperparameters. Take the backbones of Swin and YOLOv5 as an example. Swin belongs to the transformer family, and the YOLOv5 is a convolutional network. Their training optimizers, learning rates, and other hyperparameters are different. If we force using Swin as the backbone of YOLOv5 and try to get a moderate performance, we must modify many parameters.
+
+## How to use the components implemented in all MM series repositories?
+
+In OpenMMLab 2.0, we have enhanced the ability to use different modules across MM series libraries. Currently, users can call any module that has been registered in MM series algorithm libraries via `MM Algorithm Library A. Module Name`. We demonstrated using MMClassification backbones in the [Replace the backbone network](../recommended_topics/replace_backbone.md). Other modules can be used in the same way.
+
+## Can pure background pictures be added in MMYOLO for training?
+
+Adding pure background images to training can suppress the false positive rate in most scenarios, and this feature has already been supported for most datasets. Take `YOLOv5CocoDataset` as an example. The control parameter is `train_dataloader.dataset.filter_cfg.filter_empty_gt`. If `filter_empty_gt` is True, the pure background images will be filtered out and not used in training, and vice versa. Most of the algorithms in MMYOLO have added this feature by default.
+
+## Is there a script to calculate the inference FPS in MMYOLO?
+
+MMYOLO is based on MMDet 3.x, which provides a [benchmark script](https://github.com/open-mmlab/mmdetection/blob/3.x/tools/analysis_tools/benchmark.py) to calculate the inference FPS. We recommend using `mim` to run the script in MMDet directly across the library instead of copying them to MMYOLO. More details about `mim` usages can be found at [Use mim to run scripts from other OpenMMLab repositories](../common_usage/mim_usage.md).
+
+## What is the difference between MMDeploy and EasyDeploy?
+
+MMDeploy is developed and maintained by the OpenMMLab deployment team to provide model deployment solutions for the OpenMMLab series algorithms, which support various inference backends and customization features. EasyDeploy is an easier and more lightweight deployment project provided by the community. However, it does not support as many features as MMDeploy. Users can choose which one to use in MMYOLO according to their needs.
+
+## How to check the AP of every category in COCOMetric?
+
+Just set `test_evaluator.classwise` to True or add `--cfg-options test_evaluator.classwise=True` when running the test script.
+
+## Why doesn't MMYOLO support the auto-learning rate scaling feature as MMDet?
+
+It is because the YOLO series algorithms are not very well suited for linear scaling. We have verified on several datasets that the performance is better without the auto-scaling based on batch size.
+
+## Why is the weight size of my trained model larger than the official one?
+
+The reason is that user-trained weights usually include extra data such as `optimizer`, `ema_state_dict`, and `message_hub`, which are removed when we publish the models. While on the contrary, the weight users trained by themselves are kept. You can use the [publish_model.py](https://github.com/open-mmlab/mmyolo/blob/main/tools/misc/publish_model.py) to remove these unnecessary components.
+
+## Why does the RTMDet cost more graphics memory during the training than YOLOv5?
+
+It is due to the assigner in RTMDet. YOLOv5 uses a simple and efficient shape-matching assigner, while RTMDet uses a dynamic soft label assigner for entire batch computation. Therefore, it consumes more memory in its internal cost matrix, especially when there are too many labeled bboxes in the current batch. We are considering solving this problem soon.
+
+## Do I need to reinstall MMYOLO after modifying some code?
+
+Without adding any new python code, and if you installed the MMYOLO by `mim install -v -e .`, any new modifications will take effect without reinstalling. However, if you add new python codes and are using them, you need to reinstall with `mim install -v -e .`.
+
+## How to use multiple versions of MMYOLO to develop?
+
+If users have multiple versions of the MMYOLO, such as mmyolo-v1 and mmyolo-v2. They can specify the target version of their MMYOLO by using this command in the shell:
+
+```shell
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
+```
+
+Users can unset the `PYTHONPATH` when they want to reset to the default MMYOLO by this command:
+
+```shell
+unset PYTHONPATH
+```
+
+## How to save the best checkpoints during the training?
+
+Users can choose what metrics to filter the best models by setting the `default_hooks.checkpoint.save_best` in the configuration. Take the COCO dataset detection task as an example. Users can customize the `default_hooks.checkpoint.save_best` with these parameters:
+
+1. `auto` works based on the first evaluation metric in the validation set.
+2. `coco/bbox_mAP` works based on `bbox_mAP`.
+3. `coco/bbox_mAP_50` works based on `bbox_mAP_50`.
+4. `coco/bbox_mAP_75` works based on `bbox_mAP_75`.
+5. `coco/bbox_mAP_s` works based on `bbox_mAP_s`.
+6. `coco/bbox_mAP_m` works based on `bbox_mAP_m`.
+7. `coco/bbox_mAP_l` works based on `bbox_mAP_l`.
+
+In addition, users can also choose the filtering logic by setting `default_hooks.checkpoint.rule` in the configuration. For example, `default_hooks.checkpoint.rule=greater` means that the larger the indicator is, the better it is. More details can be found at [checkpoint_hook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py).
+
+## How to train and test with non-square input sizes?
+
+The default configurations of the YOLO series algorithms are mostly squares like 640x640 or 1280x1280. However, if users want to train with a non-square shape, they can modify the `image_scale` to the desired value in the configuration. A more detailed example could be found at [yolov5_s-v61_fast_1xb12-40e_608x352_cat.py](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov5/yolov5_s-v61_fast_1xb12-40e_608x352_cat.py).
diff --git a/docs/en/tutorials/warning_notes.md b/docs/en/tutorials/warning_notes.md
index 54ed973da..791cd9d4b 100644
--- a/docs/en/tutorials/warning_notes.md
+++ b/docs/en/tutorials/warning_notes.md
@@ -1 +1,24 @@
# Common Warning Notes
+
+The purpose of this document is to collect warning messages that users often find confusing, and provide explanations to facilitate understanding.
+
+## xxx registry in mmyolo did not set import location
+
+The warning message complete information is that The xxx registry in mmyolo did not set import location. Fallback to call `mmyolo.utils.register_all_modules` instead.
+
+This warning means that a module was not set with an import location when importing it, making it impossible to determine its location. Therefore, `mmyolo.utils.register_all_modules` is automatically called to trigger the package import.
+This warning belongs to the very low-level module warning in MMEngine, which may be difficult for users to understand, but it has no impact on the actual use and can be ignored directly.
+
+## save_param_schedulers is true but self.param_schedulers is None
+
+The following information is an example using the YOLOv5 algorithm. This is because the parameter scheduler strategy `YOLOv5ParamSchedulerHook` has been rewritten in YOLOv5, so the ParamScheduler designed in MMEngine is not used. However, `save_param_schedulers` is not set to False in the YOLOv5 configuration.
+
+First of all, this warning has no impact on performance and resuming training. If users think this warning affects experience, you can set `default_hooks.checkpoint.save_param_scheduler` to False, or set `--cfg-options default_hooks.checkpoint.save_param_scheduler=False` when training via the command line.
+
+## The loss_cls will be 0. This is a normal phenomenon.
+
+This is related to specific algorithms. Taking YOLOv5 as an example, its classification loss only considers positive samples. If the number of classes is 1, then the classification loss and object loss are functionally redundant. Therefore, in the design, when the number of classes is 1, the loss_cls is not calculated and is always 0. This is a normal phenomenon.
+
+## The model and loaded state dict do not match exactly
+
+Whether this warning will affect performance needs to be determined based on more information. If it occurs during fine-tuning, it is a normal phenomenon that the COCO pre-trained weights of the Head module cannot be loaded due to the user's custom class differences, and it will not affect performance.
diff --git a/docs/en/useful_tools/log_analysis.md b/docs/en/useful_tools/log_analysis.md
index 6b3e60402..c45170aaa 100644
--- a/docs/en/useful_tools/log_analysis.md
+++ b/docs/en/useful_tools/log_analysis.md
@@ -2,7 +2,7 @@
## Curve plotting
-`tools/analysis_tools/analyze_logs.py` plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+`tools/analysis_tools/analyze_logs.py` in MMDetection plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
```shell
mim run mmdet analyze_logs plot_curve \
diff --git a/docs/zh_cn/common_usage/ms_training_testing.md b/docs/zh_cn/common_usage/ms_training_testing.md
new file mode 100644
index 000000000..1f271c54d
--- /dev/null
+++ b/docs/zh_cn/common_usage/ms_training_testing.md
@@ -0,0 +1,41 @@
+# 多尺度训练和测试
+
+## 多尺度训练
+
+MMYOLO 中目前支持了主流的 YOLOv5、YOLOv6、YOLOv7、YOLOv8 和 RTMDet 等算法,其默认配置均为单尺度 640x640 训练。 在 MM 系列开源库中常用的多尺度训练有两种实现方式:
+
+1. 在 `train_pipeline` 中输出的每张图都是不定尺度的,然后在 [DataPreprocessor](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/data_preprocessors/data_preprocessor.py) 中将不同尺度的输入图片
+ 通过 [stack_batch](https://github.com/open-mmlab/mmengine/blob/dbae83c52fa54d6dda08b6692b124217fe3b2135/mmengine/model/base_model/data_preprocessor.py#L260-L261) 函数填充到同一尺度,从而组成 batch 进行训练。MMDet 中大部分算法都是采用这个实现方式。
+2. 在 `train_pipeline` 中输出的每张图都是固定尺度的,然后直接在 `DataPreprocessor` 中进行 batch 张图片的上下采样,从而实现多尺度训练功能
+
+在 MMYOLO 中两种多尺度训练方式都是支持的。理论上第一种实现方式所生成的尺度会更加丰富,但是由于其对单张图进行独立增强,训练效率不如第二种方式。所以我们更推荐使用第二种方式。
+
+以 `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` 配置为例,其默认配置采用的是 640x640 固定尺度训练,假设想实现以 32 为倍数,且多尺度范围为 (480, 800) 的训练方式,则可以参考 YOLOX 做法通过 DataPreprocessor 中的 [YOLOXBatchSyncRandomResize](https://github.com/open-mmlab/mmyolo/blob/dc85144fab20a970341550794857a2f2f9b11564/mmyolo/models/data_preprocessors/data_preprocessor.py#L20) 实现。
+
+在 `configs/yolov5` 路径下新建配置,命名为 `configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py`,其内容如下:
+
+```python
+_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
+
+model = dict(
+ data_preprocessor=dict(
+ type='YOLOv5DetDataPreprocessor',
+ pad_size_divisor=32,
+ batch_augments=[
+ dict(
+ type='YOLOXBatchSyncRandomResize',
+ # 多尺度范围是 480~800
+ random_size_range=(480, 800),
+ # 输出尺度需要被 32 整除
+ size_divisor=32,
+ # 每隔 1 个迭代改变一次输出输出
+ interval=1)
+ ])
+)
+```
+
+上述配置就可以实现多尺度训练了。为了方便,我们已经在 `configs/yolov5/` 下已经提供了该配置。其余 YOLO 系列算法也是类似做法。
+
+## 多尺度测试
+
+MMYOLO 多尺度测试功能等同于测试时增强 TTA,目前已经支持,详情请查看 [测试时增强 TTA](./tta.md) 。
diff --git a/docs/zh_cn/get_started/15_minutes_instance_segmentation.md b/docs/zh_cn/get_started/15_minutes_instance_segmentation.md
index 48fe3ca90..2b9e6aab8 100644
--- a/docs/zh_cn/get_started/15_minutes_instance_segmentation.md
+++ b/docs/zh_cn/get_started/15_minutes_instance_segmentation.md
@@ -1,3 +1,330 @@
# 15 分钟上手 MMYOLO 实例分割
+实例分割是计算机视觉中的一个任务,旨在将图像中的每个对象都分割出来,并为每个对象分配一个唯一的标识符。与语义分割不同,实例分割不仅分割出图像中的不同类别,还将同一类别的不同实例分开。
+
+
+

+
+
+以可供下载的气球 balloon 小数据集为例,带大家 15 分钟轻松上手 MMYOLO 实例分割。整个流程包含如下步骤:
+
+- [环境安装](#环境安装)
+- [数据集准备](#数据集准备)
+- [配置准备](#配置准备)
+- [模型训练](#模型训练)
+- [模型测试](#模型测试)
+- [EasyDeploy 模型部署](#easydeploy-模型部署)
+
+本文以 YOLOv5-s 为例,其余 YOLO 系列算法的气球 balloon 小数据集 demo 配置请查看对应的算法配置文件夹下。
+
+## 环境安装
+
+假设你已经提前安装好了 Conda,接下来安装 PyTorch
+
+```shell
+conda create -n mmyolo python=3.8 -y
+conda activate mmyolo
+# 如果你有 GPU
+conda install pytorch torchvision -c pytorch
+# 如果你是 CPU
+# conda install pytorch torchvision cpuonly -c pytorch
+```
+
+安装 MMYOLO 和依赖库
+
+```shell
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+pip install -U openmim
+mim install -r requirements/mminstall.txt
+# Install albumentations
+mim install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+# "-v" 指详细说明,或更多的输出
+# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
+```
+
+```{note}
+温馨提醒:由于本仓库采用的是 OpenMMLab 2.0,请最好新建一个 conda 虚拟环境,防止和 OpenMMLab 1.0 已经安装的仓库冲突。
+```
+
+详细环境配置操作请查看 [安装和验证](./installation.md)
+
+## 数据集准备
+
+Balloon 数据集是一个包括 74 张图片的单类别数据集, 包括了训练所需的标注信息。 样例图片如下所示:
+
+
+

+
+
+你只需执行如下命令即可下载并且直接用起来
+
+```shell
+python tools/misc/download_dataset.py --dataset-name balloon --save-dir ./data/balloon --unzip --delete
+python ./tools/dataset_converters/balloon2coco.py
+```
+
+data 位于 mmyolo 工程目录下, `train.json`, `val.json` 中存放的是 COCO 格式的标注,`data/balloon/train`, `data/balloon/val` 中存放的是所有图片
+
+## 配置准备
+
+以 YOLOv5 算法为例,考虑到用户显存和内存有限,我们需要修改一些默认训练参数来让大家愉快的跑起来,核心需要修改的参数如下
+
+- YOLOv5 是 Anchor-Based 类算法,不同的数据集需要自适应计算合适的 Anchor
+- 默认配置是 8 卡,每张卡 batch size 为 16,现将其改成单卡,每张卡 batch size 为 4
+- 原则上 batch size 改变后,学习率也需要进行线性缩放,但是实测发现不需要
+
+具体操作为在 `configs/yolov5/ins_seg` 文件夹下新建 `yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py` 配置文件(为了方便大家直接使用,我们已经提供了该配置),并把以下内容复制配置文件中。
+
+```python
+_base_ = './yolov5_ins_s-v61_syncbn_fast_8xb16-300e_coco_instance.py' # noqa
+
+data_root = 'data/balloon/'
+# 训练集标注路径
+train_ann_file = 'train.json'
+train_data_prefix = 'train/' # 训练集图片路径
+# 测试集标注路径
+val_ann_file = 'val.json'
+val_data_prefix = 'val/' # 验证集图片路径
+metainfo = {
+ 'classes': ('balloon', ), # 数据集类别名称
+ 'palette': [
+ (220, 20, 60),
+ ]
+}
+num_classes = 1
+# 批处理大小batch size设置为 4
+train_batch_size_per_gpu = 4
+# dataloader 加载进程数
+train_num_workers = 2
+log_interval = 1
+#####################
+train_dataloader = dict(
+ batch_size=train_batch_size_per_gpu,
+ num_workers=train_num_workers,
+ dataset=dict(
+ data_root=data_root,
+ metainfo=metainfo,
+ data_prefix=dict(img=train_data_prefix),
+ ann_file=train_ann_file))
+val_dataloader = dict(
+ dataset=dict(
+ data_root=data_root,
+ metainfo=metainfo,
+ data_prefix=dict(img=val_data_prefix),
+ ann_file=val_ann_file))
+test_dataloader = val_dataloader
+val_evaluator = dict(ann_file=data_root + val_ann_file)
+test_evaluator = val_evaluator
+default_hooks = dict(logger=dict(interval=log_interval))
+#####################
+
+model = dict(bbox_head=dict(head_module=dict(num_classes=num_classes)))
+```
+
+以上配置从 `yolov5_ins_s-v61_syncbn_fast_8xb16-300e_coco_instance.py` 中继承,并根据 balloon 数据的特点更新了 `data_root`、`metainfo`、`train_dataloader`、`val_dataloader`、`num_classes` 等配置。
+
+## 模型训练
+
+```shell
+python tools/train.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py
+```
+
+运行以上训练命令 `work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance` 文件夹会被自动生成,权重文件以及此次的训练配置文件将会保存在此文件夹中。 在 1660 低端显卡上,整个训练过程大概需要 30 分钟。
+
+
+

+
+
+在 `val.json` 上性能如下所示:
+
+```text
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.330
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.509
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.317
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.103
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.417
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.150
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.396
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.454
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.317
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.525
+```
+
+上述性能是通过 COCO API 打印,其中 -1 表示不存在对于尺度的物体。
+
+### 一些注意事项
+
+在训练过程中会打印如下关键警告:
+
+- You are using `YOLOv5Head` with num_classes == 1. The loss_cls will be 0. This is a normal phenomenon.
+
+这个警告都不会对性能有任何影响。第一个警告是说明由于当前训练的类别数是 1,根据 YOLOv5 算法的社区, 分类分支的 loss 始终是 0,这是正常现象。
+
+### 中断后恢复训练
+
+如果训练中途停止,可以在训练命令最后加上 `--resume` ,程序会自动从 `work_dirs` 中加载最新的权重文件恢复训练。
+
+```shell
+python tools/train.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py --resume
+```
+
+### 节省显存策略
+
+上述配置大概需要 1.0G 显存,如果你的显存不够,可以考虑开启混合精度训练
+
+```shell
+python tools/train.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py --amp
+```
+
+### 训练可视化
+
+MMYOLO 目前支持本地、TensorBoard 以及 WandB 等多种后端可视化,默认是采用本地可视化方式,你可以切换为 WandB 等实时可视化训练过程中各类指标。
+
+#### 1 WandB 可视化使用
+
+WandB 官网注册并在 https://wandb.ai/settings 获取到 WandB 的 API Keys。
+
+
+
+
+
+```shell
+pip install wandb
+# 运行了 wandb login 后输入上文中获取到的 API Keys ,便登录成功。
+wandb login
+```
+
+在 `configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py` 配置文件最后添加 WandB 配置
+
+```python
+visualizer = dict(vis_backends = [dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
+```
+
+重新运行训练命令便可以在命令行中提示的网页链接中看到 loss、学习率和 coco/bbox_mAP 等数据可视化了。
+
+```shell
+python tools/train.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py
+```
+
+#### 2 Tensorboard 可视化使用
+
+安装 Tensorboard 环境
+
+```shell
+pip install tensorboard
+```
+
+同上述在配置文件 `configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py`配置的最后添加 `tensorboard` 配置
+
+```python
+visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='TensorboardVisBackend')])
+```
+
+重新运行训练命令后,Tensorboard 文件会生成在可视化文件夹 `work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/{timestamp}/vis_data` 下,
+运行下面的命令便可以在网页链接使用 Tensorboard 查看 loss、学习率和 coco/bbox_mAP 等可视化数据了:
+
+```shell
+tensorboard --logdir=work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance
+```
+
+## 模型测试
+
+```shell
+python tools/test.py configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py \
+ work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/best_coco_bbox_mAP_epoch_300.pth \
+ --show-dir show_results
+```
+
+运行以上测试命令, 你不仅可以得到**模型训练**部分所打印的 AP 性能,还可以将推理结果图片自动保存至 `work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/{timestamp}/show_results` 文件夹中。下面为其中一张结果图片,左图为实际标注,右图为模型推理结果。
+
+
+

+
+
+如果你使用了 `WandbVisBackend` 或者 `TensorboardVisBackend`,则还可以在浏览器窗口可视化模型推理结果。
+
+## 特征图相关可视化
+
+MMYOLO 中提供了特征图相关可视化脚本,用于分析当前模型训练效果。 详细使用流程请参考 [特征图可视化](../recommended_topics/visualization.md)
+
+由于 `test_pipeline` 直接可视化会存在偏差,故将需要 `configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py` 中 `test_pipeline`
+
+```python
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ backend_args=_base_.backend_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+修改为如下配置:
+
+```python
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ backend_args=_base_.backend_args),
+ dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 删除 YOLOv5KeepRatioResize, 将 LetterResize 修改成 mmdet.Resize
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor')) # 删除 pad_param
+]
+```
+
+我们选择 `data/balloon/train/3927754171_9011487133_b.jpg` 图片作为例子,可视化 YOLOv5 backbone 和 neck 层的输出特征图。
+
+```shell
+python demo/featmap_vis_demo.py data/balloon/train/3927754171_9011487133_b.jpg \
+ configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py \
+ work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/best_coco_bbox_mAP_epoch_300.pth \ --target-layers backbone \
+ --channel-reduction squeeze_mean
+```
+
+
+

+
+
+结果会保存到当前路径的 output 文件夹下。上图中绘制的 3 个输出特征图对应大中小输出特征图。
+
+**2. 可视化 YOLOv5 neck 输出的 3 个通道**
+
+```shell
+python demo/featmap_vis_demo.py data/balloon/train/3927754171_9011487133_b.jpg \
+ configs/yolov5/ins_seg/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance.py \
+ work_dirs/yolov5_ins_s-v61_syncbn_fast_8xb16-300e_balloon_instance/best_coco_bbox_mAP_epoch_300.pth \ --target-layers neck \
+ --channel-reduction squeeze_mean
+```
+
+
+

+
+
+**3. Grad-Based CAM 可视化**
+
TODO
+
+## EasyDeploy 模型部署
+
+TODO
+
+至此本教程结束。
+
+以上完整内容可以查看 [15_minutes_instance_segmentation.ipynb](../../../demo/15_minutes_instance_segmentation.ipynb)。 如果你在训练或者测试过程中碰到问题,请先查看 [常见错误排除步骤](../recommended_topics/troubleshooting_steps.md), 如果依然无法解决欢迎提 issue。
diff --git a/docs/zh_cn/get_started/15_minutes_object_detection.md b/docs/zh_cn/get_started/15_minutes_object_detection.md
index aeac5e59b..51022baa9 100644
--- a/docs/zh_cn/get_started/15_minutes_object_detection.md
+++ b/docs/zh_cn/get_started/15_minutes_object_detection.md
@@ -256,7 +256,7 @@ python tools/train.py configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py
#### 2 Tensorboard 可视化使用
-安装 Tensorboard 环境
+安装 Tensorboard 依赖
```shell
pip install tensorboard
@@ -268,11 +268,11 @@ pip install tensorboard
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='TensorboardVisBackend')])
```
-重新运行训练命令后,Tensorboard 文件会生成在可视化文件夹 `work_dirs/yolov5_s-v61_fast_1xb12-40e_cat.py/{timestamp}/vis_data` 下,
+重新运行训练命令后,Tensorboard 文件会生成在可视化文件夹 `work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/{timestamp}/vis_data` 下,
运行下面的命令便可以在网页链接使用 Tensorboard 查看 loss、学习率和 coco/bbox_mAP 等可视化数据了:
```shell
-tensorboard --logdir=work_dirs/yolov5_s-v61_fast_1xb12-40e_cat.py
+tensorboard --logdir=work_dirs/yolov5_s-v61_fast_1xb12-40e_cat
```
## 模型测试
@@ -301,7 +301,7 @@ MMYOLO 中提供了特征图相关可视化脚本,用于分析当前模型训
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -322,13 +322,13 @@ test_pipeline = [
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
- dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
+ backend_args=_base_.backend_args),
+ dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 删除 YOLOv5KeepRatioResize, 将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
type='mmdet.PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
- 'scale_factor'))
+ 'scale_factor')) # 删除 pad_param
]
```
@@ -370,6 +370,12 @@ python demo/featmap_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
基于上述特征图可视化效果,我们可以分析特征层 bbox 级别的 Grad CAM。
+安装 `grad-cam` 依赖:
+
+```shell
+pip install "grad-cam"
+```
+
(a) 查看 neck 输出的最小输出特征图的 Grad CAM
```shell
@@ -416,28 +422,28 @@ python demo/boxam_vis_demo.py data/cat/images/IMG_20221020_112705.jpg \
首先需要在当前 MMYOLO 的虚拟环境中按照 EasyDeploy 的 [基本文档](../../../projects/easydeploy/docs/model_convert.md) 对照自己的设备安装好所需的各个库。
```shell
-pip install onnx
+pip install onnx onnxruntime
pip install onnx-simplifier # 如果需要使用 simplify 功能需要安装
pip install tensorrt # 如果有 GPU 环境并且需要输出 TensorRT 模型需要继续执行
```
-完成安装后就可以用以下命令对已经训练好的针对 cat 数据集的模型一键转换部署,当前设备的 ONNX 版本为 1.13.0,TensorRT 版本为 8.5.3.1,故可保持 `--opset` 为 11,其余各项参数的具体含义和参数值需要对照使用的 config 文件进行调整。此处我们先导出 CPU 版本的 ONNX 模型,`--backend` 为 1。
+完成安装后就可以用以下命令对已经训练好的针对 cat 数据集的模型一键转换部署,当前设备的 ONNX 版本为 1.13.0,TensorRT 版本为 8.5.3.1,故可保持 `--opset` 为 11,其余各项参数的具体含义和参数值需要对照使用的 config 文件进行调整。此处我们先导出 CPU 版本的 ONNX 模型,`--backend` 为 ONNXRUNTIME。
```shell
-python projects/easydeploy/tools/export.py \
- configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
- work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
- --work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
+python projects/easydeploy/tools/export_onnx.py \
+ configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
+ work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/epoch_40.pth \
+ --work-dir work_dirs/yolov5_s-v61_fast_1xb12-40e_cat \
--img-size 640 640 \
--batch 1 \
--device cpu \
--simplify \
- --opset 11 \
- --backend 1 \
- --pre-topk 1000 \
- --keep-topk 100 \
- --iou-threshold 0.65 \
- --score-threshold 0.25
+ --opset 11 \
+ --backend ONNXRUNTIME \
+ --pre-topk 1000 \
+ --keep-topk 100 \
+ --iou-threshold 0.65 \
+ --score-threshold 0.25
```
成功运行后就可以在 `work-dir` 下得到转换后的 ONNX 模型,默认使用 `end2end.onnx` 命名。
@@ -446,7 +452,7 @@ python projects/easydeploy/tools/export.py \
```shell
python projects/easydeploy/tools/image-demo.py \
- data/cat/images/IMG_20210728_205312.jpg \
+ data/cat/images/IMG_20210728_205117.jpg \
configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py \
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat/end2end.onnx \
--device cpu
@@ -488,7 +494,7 @@ python projects/easydeploy/tools/build_engine.py \
成功执行后会在 `work-dir` 下生成 `end2end.engine` 文件:
-```shell
+```text
work_dirs/yolov5_s-v61_fast_1xb12-40e_cat
├── 202302XX_XXXXXX
│ ├── 202302XX_XXXXXX.log
@@ -524,4 +530,4 @@ python projects/easydeploy/tools/image-demo.py \
这样我们就完成了将训练完成的模型进行转换部署并且检查推理结果的工作。至此本教程结束。
-以上完整内容可以查看 [15_minutes_object_detection.ipynb](<>)。 如果你在训练或者测试过程中碰到问题,请先查看 [常见错误排除步骤](../recommended_topics/troubleshooting_steps.md), 如果依然无法解决欢迎提 issue。
+以上完整内容可以查看 [15_minutes_object_detection.ipynb](../../..//demo/15_minutes_object_detection.ipynb)。 如果你在训练或者测试过程中碰到问题,请先查看 [常见错误排除步骤](../recommended_topics/troubleshooting_steps.md),如果依然无法解决欢迎提 [issue](https://github.com/open-mmlab/mmyolo/issues/new/choose)。
diff --git a/docs/zh_cn/get_started/article.md b/docs/zh_cn/get_started/article.md
index 0ec160c8b..07f75e42b 100644
--- a/docs/zh_cn/get_started/article.md
+++ b/docs/zh_cn/get_started/article.md
@@ -48,7 +48,7 @@
| :---: | :--------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| 第1讲 | 源码阅读和调试「必备」技巧 | [](https://www.bilibili.com/video/BV1N14y1V7mB) [](https://www.bilibili.com/video/BV1N14y1V7mB) | [源码阅读和调试「必备」技巧文档](https://zhuanlan.zhihu.com/p/580885852) |
| 第2讲 | 10分钟换遍主干网络 | [](https://www.bilibili.com/video/BV1JG4y1d7GC) [](https://www.bilibili.com/video/BV1JG4y1d7GC) | [10分钟换遍主干网络文档](https://zhuanlan.zhihu.com/p/585641598)
[10分钟换遍主干网络.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第二期]10分钟换遍主干网络.ipynb) |
-| 第3讲 | 自定义数据集从标注到部署保姆级教程 | [](https://www.bilibili.com/video/BV1RG4y137i5) [](https://www.bilibili.com/video/BV1RG4y137i5) | [自定义数据集从标注到部署保姆级教程](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md) |
+| 第3讲 | 自定义数据集从标注到部署保姆级教程 | [](https://www.bilibili.com/video/BV1RG4y137i5) [](https://www.bilibili.com/video/BV1RG4y137i5) | [自定义数据集从标注到部署保姆级教程](../recommended_topics/labeling_to_deployment_tutorials.md) |
| 第4讲 | 顶会第一步 · 模块自定义 | [](https://www.bilibili.com/video/BV1yd4y1j7VD) [](https://www.bilibili.com/video/BV1yd4y1j7VD) | [顶会第一步·模块自定义.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第四期]顶会第一步·模块自定义.ipynb) |
#### 源码解读类
diff --git a/docs/zh_cn/get_started/dependencies.md b/docs/zh_cn/get_started/dependencies.md
index b950519c7..8713c1393 100644
--- a/docs/zh_cn/get_started/dependencies.md
+++ b/docs/zh_cn/get_started/dependencies.md
@@ -4,7 +4,8 @@
| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
| :------------: | :----------------------: | :----------------------: | :---------------------: |
-| main | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| main | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| 0.6.0 | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
| 0.5.0 | mmdet>=3.0.0rc6, \<3.1.0 | mmengine>=0.6.0, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
| 0.4.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
diff --git a/docs/zh_cn/get_started/installation.md b/docs/zh_cn/get_started/installation.md
index 32927b6e6..be77bccc9 100644
--- a/docs/zh_cn/get_started/installation.md
+++ b/docs/zh_cn/get_started/installation.md
@@ -8,7 +8,7 @@
pip install -U openmim
mim install "mmengine>=0.6.0"
mim install "mmcv>=2.0.0rc4,<2.1.0"
-mim install "mmdet>=3.0.0rc6,<3.1.0"
+mim install "mmdet>=3.0.0,<4.0.0"
```
如果你当前已经处于 mmyolo 工程目录下,则可以采用如下简化写法
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index e32f76d8c..9f150ac6c 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -19,15 +19,16 @@
:caption: 推荐专题
recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
recommended_topics/model_design.md
recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/application_examples/index.rst
recommended_topics/replace_backbone.md
recommended_topics/complexity_analysis.md
recommended_topics/labeling_to_deployment_tutorials.md
recommended_topics/visualization.md
recommended_topics/deploy/index.rst
recommended_topics/troubleshooting_steps.md
- recommended_topics/industry_examples.md
recommended_topics/mm_basics.md
recommended_topics/dataset_preparation.md
@@ -38,6 +39,7 @@
common_usage/resume_training.md
common_usage/syncbn.md
common_usage/amp_training.md
+ common_usage/ms_training_testing.md
common_usage/tta.md
common_usage/plugins.md
common_usage/freeze_layers.md
diff --git a/docs/zh_cn/notes/changelog.md b/docs/zh_cn/notes/changelog.md
index bd5110713..90fef5958 100644
--- a/docs/zh_cn/notes/changelog.md
+++ b/docs/zh_cn/notes/changelog.md
@@ -1,5 +1,43 @@
# 更新日志
+## v0.6.0 (15/8/2023)
+
+### 亮点
+
+- 支持 YOLOv5 实例分割
+- 基于 MMPose 支持 YOLOX-Pose
+- 添加 15 分钟的实例分割教程
+- YOLOv5 支持使用 mask 标注来优化边界框
+- 添加多尺度训练和测试文档
+
+### 新特性
+
+- 添加训练和测试技巧文档 (#659)
+- 支持设置 `cache_size_limit` 参数,并支持 mmdet 3.0.0 (#707)
+- 支持 YOLOv5u 和 YOLOv6 3.0 推理 (#624, #744)
+- 支持仅模型推断 (#733)
+- 添加 YOLOv8 deepstream 配置 (#633)
+- 在 MMYOLO 应用程序中添加电离图示例 (#643)
+
+### Bug 修复
+
+- 修复 browse_dataset 以可视化测试和验证集的问题 (#641)
+- 修复安装文档错误 (#662)
+- 修复 yolox-l ckpt 链接 (#677)
+- 修正 YOLOv7 和 YOLOv8 图表中的拼写错误 (#621, #710)
+- 调整 `boxam_vis_demo.py` 中包导入的顺序 (#655)
+
+### 完善
+
+- 优化 `convert_kd_ckpt_to_student.py` 文件 (#647)
+- 添加 FAQ 和 training_testing_tricks 的英文文档 (#691, #693)
+
+### 贡献者
+
+总共 21 位开发者参与了本次版本
+
+感谢 @Lum1104,@azure-wings,@FeiGeChuanShu,@Lingrui Gu,@Nioolek,@huayuan4396,@RangeKing,@danielhonies,@yechenzhi,@JosonChan1998,@kitecats,@Qingrenn,@triple-Mu,@kikefdezl,@zhangrui-wolf,@xin-li-67,@Ben-Louis,@zgzhengSEU,@VoyagerXvoyagerx,@tang576225574,@hhaAndroid
+
## v0.5.0 (2/3/2023)
### 亮点
diff --git a/docs/zh_cn/notes/code_style.md b/docs/zh_cn/notes/code_style.md
index fc6120ccf..6e169b371 100644
--- a/docs/zh_cn/notes/code_style.md
+++ b/docs/zh_cn/notes/code_style.md
@@ -324,9 +324,6 @@ docstring 是对一个类、一个函数功能与 API 接口的详细描述,
specified, the ``out_dir`` will be the concatenation of
``out_dir`` and the last level directory of ``runner.work_dir``.
Defaults to None. `Changed in version 1.3.15.`
- file_client_args (dict, optional): Arguments to instantiate a
- FileClient. See :class:`mmcv.fileio.FileClient` for details.
- Defaults to None. `New in version 1.3.15.`
Warning:
Before v1.3.15, the ``out_dir`` argument indicates the path where the
diff --git a/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
index d28ee4423..fb5e218db 100644
--- a/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
+++ b/docs/zh_cn/recommended_topics/algorithm_descriptions/yolov8_description.md
@@ -3,7 +3,7 @@
## 0 简介
-
+
图 1:YOLOv8-P5 模型结构
@@ -203,7 +203,7 @@ python demo/featmap_vis_demo.py demo/demo.jpg configs/yolov8/yolov8_s_syncbn_fas
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
diff --git a/docs/zh_cn/recommended_topics/application_examples/index.rst b/docs/zh_cn/recommended_topics/application_examples/index.rst
new file mode 100644
index 000000000..f552dbe5a
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/application_examples/index.rst
@@ -0,0 +1,7 @@
+MMYOLO 应用范例介绍
+********************
+
+.. toctree::
+ :maxdepth: 1
+
+ ionogram_detection.md
diff --git a/docs/zh_cn/recommended_topics/application_examples/ionogram_detection.md b/docs/zh_cn/recommended_topics/application_examples/ionogram_detection.md
new file mode 100644
index 000000000..84e6daf00
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/application_examples/ionogram_detection.md
@@ -0,0 +1,306 @@
+# 基于 MMYOLO 的频高图实时目标检测 benchmark
+
+## 数据集构建
+
+数字频高图是获取电离层实时信息最重要的途径。电离层结构检测对精准提取电离层关键参数,具有非常重要的研究意义。
+
+利用中国科学院在海南、武汉、怀来获取的不同季节的 4311 张频高图建立数据集,使用 [labelme](https://github.com/wkentaro/labelme) 人工标注出 E 层、Es-c 层、Es-l 层、F1 层、F2 层、Spread F 层共 6 种结构。[数据集下载](https://github.com/VoyagerXvoyagerx/Ionogram_detection/releases/download/Dataset/Iono4311.zip)
+
+
+
+
+使用 labelme 标注的图像预览
+
+
+
+1. 数据集准备
+
+下载数据后,放置在 MMYOLO 仓库的根目录下,使用 `unzip test.zip` 命令(linux)解压至当前文件夹。解压后的文件夹结构为:
+
+```shell
+Iono4311/
+├── images
+| ├── 20130401005200.png
+| └── ...
+└── labels
+ ├── 20130401005200.json
+ └── ...
+```
+
+其中,`images` 目录下存放输入图片,`labels` 目录下存放使用 labelme 标注得到的 json 文件。
+
+2. 数据集格式转换
+
+使用MMYOLO提供的 `tools/dataset_converters/labelme2coco.py` 脚本将 labelme 格式的标注文件转换为 COCO 格式的标注文件。
+
+```shell
+python tools/dataset_converters/labelme2coco.py --img-dir ./Iono4311/images \
+ --labels-dir ./Iono4311/labels \
+ --out ./Iono4311/annotations/annotations_all.json
+```
+
+3. 浏览数据集
+
+使用下面的命令可以将 COCO 的 label 在图片上进行显示,这一步可以验证刚刚转换是否有问题。
+
+```shell
+python tools/analysis_tools/browse_coco_json.py --img-dir ./Iono4311/images \
+ --ann-file ./Iono4311/annotations/annotations_all.json
+```
+
+4. 划分训练集、验证集、测试集
+
+设置 70% 的图片为训练集,15% 作为验证集,15% 为测试集。
+
+```shell
+python tools/misc/coco_split.py --json ./Iono4311/annotations/annotations_all.json \
+ --out-dir ./Iono4311/annotations \
+ --ratios 0.7 0.15 0.15 \
+ --shuffle \
+ --seed 14
+```
+
+划分后的文件夹结构:
+
+```shell
+Iono4311/
+├── annotations
+│ ├── annotations_all.json
+│ ├── class_with_id.txt
+│ ├── test.json
+│ ├── train.json
+│ └── val.json
+├── classes_with_id.txt
+├── images
+├── labels
+├── test_images
+├── train_images
+└── val_images
+```
+
+## 配置文件
+
+配置文件存放在目录 `/projects/misc/ionogram_detection/` 下。
+
+1. 数据集分析
+
+使用 `tools/analysis_tools/dataset_analysis.py` 从数据集中采样 200 张图片进行可视化分析:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ --out-dir output
+```
+
+得到以下输出:
+
+```shell
+The information obtained is as follows:
++------------------------------+
+| Information of dataset class |
++---------------+--------------+
+| Class name | Bbox num |
++---------------+--------------+
+| E | 98 |
+| Es-l | 27 |
+| Es-c | 46 |
+| F1 | 100 |
+| F2 | 194 |
+| Spread-F | 6 |
++---------------+--------------+
+```
+
+说明本数据集存在样本不均衡的现象。
+
+
+
+
+各类别目标大小统计
+
+
+
+根据统计结果,E、Es-l、Esc、F1 类别以小目标居多,F2、Spread F 类主要是中等大小目标。
+
+2. 可视化 config 中的数据处理部分
+
+以 YOLOv5-s 为例,根据配置文件中的 `train_pipeline`,训练时采用的数据增强策略包括:
+
+- 马赛克增强
+- 随机仿射变换
+- Albumentations 数据增强工具包(包括多种数字图像处理方法)
+- HSV 随机增强图像
+- 随机水平翻转
+
+使用 `tools/analysis_tools/browse_dataset.py` 脚本的 **'pipeline'** 模式,可以可视化每个 pipeline 的输出效果:
+
+```shell
+python tools/analysis_tools/browse_dataset.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ -m pipeline \
+ --out-dir output
+```
+
+
+
+
+pipeline 输出可视化
+
+
+
+3. 优化 Anchor 尺寸
+
+使用分析工具中的 `tools/analysis_tools/optimize_anchors.py` 脚本得到适用于本数据集的先验锚框尺寸。
+
+```shell
+python tools/analysis_tools/optimize_anchors.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ --algorithm v5-k-means \
+ --input-shape 640 640 \
+ --prior-match-thr 4.0 \
+ --out-dir work_dirs/dataset_analysis_5_s
+```
+
+4. 模型复杂度分析
+
+根据配置文件,使用分析工具中的 `tools/analysis_tools/get_flops.py` 脚本可以得到模型的参数量、浮点计算量等信息。以 YOLOv5-s 为例:
+
+```shell
+python tools/analysis_tools/get_flops.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
+```
+
+得到如下输出,表示模型的浮点运算量为 7.947G,一共有 7.036M 个可学习参数。
+
+```shell
+==============================
+Input shape: torch.Size([640, 640])
+Model Flops: 7.947G
+Model Parameters: 7.036M
+==============================
+```
+
+## 训练和测试
+
+1. 训练
+
+训练可视化:本范例按照[标注+训练+测试+部署全流程](https://mmyolo.readthedocs.io/zh_CN/dev/recommended_topics/labeling_to_deployment_tutorials.html#id11)中的步骤安装和配置 [wandb](https://wandb.ai/site)。
+
+调试技巧:在调试代码的过程中,有时需要训练几个 epoch,例如调试验证过程或者权重的保存是否符合期望。对于继承自 `BaseDataset` 的数据集(如本范例中的 `YOLOv5CocoDataset`),在 `train_dataloader` 中的 `dataset` 字段增加 `indices` 参数,即可指定每个 epoch 迭代的样本数,减少迭代时间。
+
+```python
+train_dataloader = dict(
+ batch_size=train_batch_size_per_gpu,
+ num_workers=train_num_workers,
+ dataset=dict(
+ _delete_=True,
+ type='RepeatDataset',
+ times=1,
+ dataset=dict(
+ type=_base_.dataset_type,
+ indices=200, # 设置 indices=200,表示每个 epoch 只迭代 200 个样本
+ data_root=data_root,
+ metainfo=metainfo,
+ ann_file=train_ann_file,
+ data_prefix=dict(img=train_data_prefix),
+ filter_cfg=dict(filter_empty_gt=False, min_size=32),
+ pipeline=_base_.train_pipeline)))
+```
+
+启动训练:
+
+```shell
+python tools/train.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py
+```
+
+2. 测试
+
+指定配置文件和模型的路径以启动测试:
+
+```shell
+python tools/test.py projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py \
+ work_dirs/yolov5_s-v61_fast_1xb96-100e_ionogram/xxx
+```
+
+## 实验与结果分析
+
+### 选择合适的 batch size
+
+- Batch size 主导了训练速度。通常,理想的 batch size 是是硬件能支持的最大 batch size。
+- 当显存占用没有达到饱和时,如果 batch size 翻倍,训练吞吐量也应该翻倍(或接近翻倍),训练时间应该减半或接近减半。
+- 使用**混合精度训练**可以加快训练速度、减小显存。在执行 `train.py` 脚本时添加 `--amp` 参数即可开启。
+
+硬件信息:
+
+- GPU:V100,显存 32G
+- CPU:10核,内存 40G
+
+实验结果:
+
+| Model | Epoch(best) | AMP | Batchsize | Num workers | Memory Allocated | Training Time | Val mAP |
+| -------- | ----------- | ----- | --------- | ----------- | ---------------- | ------------- | ------- |
+| YOLOv5-s | 100(82) | False | 32 | 6 | 35.07% | 54 min | 0.575 |
+| YOLOv5-s | 100(96) | True | 32 | 6 | 24.93% | 49 min | 0.578 |
+| YOLOv5-s | 100(100) | False | 96 | 6 | 96.64% | 48 min | 0.571 |
+| YOLOv5-s | 100(100) | True | 96 | 6 | 54.66% | **37** min | 0.575 |
+| YOLOv5-s | 100(90) | True | 144 | 6 | 77.06% | 39 min | 0.573 |
+| YOLOv5-s | 200(148) | True | 96 | 6 | 54.66% | 72 min | 0.575 |
+| YOLOv5-s | 200(188) | True | 96 | **8** | 54.66% | 67 min | 0.576 |
+
+
+
+
+不同 batch size 的训练过程中,数据加载时间 `data_time` 占每步总时长的比例
+
+
+
+分析结果,可以得出以下结论:
+
+- 混合精度训练对模型的精度几乎没有影响,并且可以明显减少显存占用。
+- Batch size 增加 3 倍,和训练时长并没有相应地减小 3 倍。根据训练过程中 `data_time` 的记录,batch size 越大,`data_time` 也越大,说明数据加载成为了限制训练速度的瓶颈。增大加载数据的进程数 `num_workers` 可以加快数据加载。
+
+### 消融实验
+
+为了得到适用于本数据集的训练流水线,以 YOLOv5-s 模型为例,进行以下消融实验。
+
+#### 不同数据增强方法
+
+| Aug Method | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_aug0.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb32-100e_ionogram_mosaic.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_mosaic_affine.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram_mosaic_affine_albu_hsv.py) | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) |
+| ---------- | ------------------------------------------------------------------------------------------------ | -------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------- |
+| Mosaic | | √ | √ | √ | √ |
+| Affine | | | √ | √ | √ |
+| Albu | | | | √ | √ |
+| HSV | | | | √ | √ |
+| Flip | | | | | √ |
+| Val mAP | 0.507 | 0.550 | 0.572 | 0.567 | 0.575 |
+
+结果表明,马赛克增强和随机仿射变换可以对验证集表现带来明显的提升。
+
+#### 是否使用预训练权重
+
+在配置文件中,修改 `load_from = None` 即可不使用预训练权重。对不使用预训练权重的实验,将基础学习率增大四倍,训练轮数增加至 200 轮,使模型得到较为充分的训练。
+
+| Model | Epoch(best) | FLOPs(G) | Params(M) | Pretrain | Val mAP | Config |
+| -------- | ----------- | -------- | --------- | -------- | ------- | ------------------------------------------------------------------------------------------------ |
+| YOLOv5-s | 100(82) | 7.95 | 7.04 | Coco | 0.575 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) |
+| YOLOv5-s | 200(145) | 7.95 | 7.04 | None | 0.565 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-200e_ionogram_pre0.py) |
+| YOLOv6-s | 100(54) | 24.2 | 18.84 | Coco | 0.584 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-100e_ionogram.py) |
+| YOLOv6-s | 200(188) | 24.2 | 18.84 | None | 0.557 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-200e_ionogram_pre0.py) |
+
+
+
+
+训练过程中的损失下降对比图
+
+
+
+损失下降曲线表明,使用预训练权重时,loss 下降得更快。可见即使是自然图像数据集上预训练的模型,在雷达图像数据集上微调时,也可以加快模型收敛。
+
+### 频高图结构检测 benchmark
+
+| Model | epoch(best) | FLOPs(G) | Params(M) | pretrain | val mAP | test mAP | Config | Log |
+| ----------- | ----------- | -------- | --------- | -------- | ------- | -------- | ------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
+| YOLOv5-s | 100(82) | 7.95 | 7.04 | Coco | 0.575 | 0.584 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_s-v61_fast_1xb96-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov5_s_20230105_213510.json) |
+| YOLOv5-m | 100(70) | 24.05 | 20.89 | Coco | 0.587 | 0.586 | [config](/projects/misc/ionogram_detection/yolov5/yolov5_m-v61_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov5_m_20230106_004642.json) |
+| YOLOv6-s | 100(54) | 24.2 | 18.84 | Coco | 0.584 | 0.594 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_s_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_s_20230107_003207.json) |
+| YOLOv6-m | 100(76) | 37.08 | 44.42 | Coco | 0.590 | 0.590 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_m_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_m_20230107_201029.json) |
+| YOLOv6-l | 100(76) | 71.33 | 58.47 | Coco | 0.605 | 0.597 | [config](/projects/misc/ionogram_detection/yolov6/yolov6_l_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov6_l_20230108_005634.json) |
+| YOLOv7-tiny | 100(78) | 6.57 | 6.02 | Coco | 0.549 | 0.568 | [config](/projects/misc/ionogram_detection/yolov7/yolov7_tiny_fast_1xb16-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov7_tiny_20230215_202837.json) |
+| YOLOv7-x | 100(58) | 94.27 | 70.85 | Coco | 0.602 | 0.595 | [config](/projects/misc/ionogram_detection/yolov7/yolov7_x_fast_1xb16-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/yolov7_x_20230110_165832.json) |
+| rtmdet-tiny | 100(100) | 8.03 | 4.88 | Coco | 0.582 | 0.589 | [config](/projects/misc/ionogram_detection/rtmdet/rtmdet_tiny_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/rtmdet_tiny_20230310_125440.json) |
+| rtmdet-s | 100(92) | 14.76 | 8.86 | Coco | 0.588 | 0.585 | [config](/projects/misc/ionogram_detection/rtmdet/rtmdet_s_fast_1xb32-100e_ionogram.py) | [log](https://github.com/VoyagerXvoyagerx/Ionogram_detection/blob/main/logs/rtmdet_s_20230310_163853.json) |
diff --git a/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
index a6a98d3d4..e935d36e9 100644
--- a/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
@@ -4,7 +4,7 @@
MMDeploy 是 [OpenMMLab](https://openmmlab.com/) 模型部署工具箱,**为各算法库提供统一的部署体验**。基于 MMDeploy,开发者可以轻松从训练 repo 生成指定硬件所需 SDK,省去大量适配时间。
-更多介绍和使用指南见 https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/zh_cn/get_started.md
+更多介绍和使用指南见 https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html
## 算法支持列表
@@ -19,6 +19,14 @@ MMDeploy 是 [OpenMMLab](https://openmmlab.com/) 模型部署工具箱,**为
ncnn 和其他后端的支持会在后续支持。
+## 安装
+
+按照[说明](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html)安装 mmdeploy。
+
+```{note}
+如果安装的是 mmdeploy 预编译包,那么也请通过 ‘git clone https://github.com/open-mmlab/mmdeploy.git –depth=1’ 下载 mmdeploy 源码。因为它包含了部署时所需的 tools 文件夹。
+```
+
## MMYOLO 中部署相关配置说明
所有部署配置文件在 [`configs/deploy`](../../../configs/deploy/) 目录下。
@@ -61,7 +69,7 @@ codebase_config = dict(
_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(
type='LetterResize',
scale=_base_.img_scale,
@@ -109,7 +117,7 @@ codebase_config = dict(
backend_config = dict(type='onnxruntime')
```
-`backend_config` 中指定了部署后端 `type=‘onnxruntime’`,其他信息可参考第三小节。
+`backend_config` 中指定了部署后端 `type='onnxruntime'`,其他信息可参考第三小节。
`TensorRT` 部署 `YOLOv5` 可以使用 [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) 配置。
@@ -208,6 +216,8 @@ use_efficientnms = False
### 使用方法
+#### 从源码安装的 MMDeploy
+
设置 `MMDeploy` 根目录为环境变量 `MMDEPLOY_DIR` ,例如 `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy`
```shell
@@ -239,6 +249,126 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
- `--show` : 是否显示检测的结果。
- `--dump-info` : 是否输出 SDK 信息。
+#### 通过 pip install 安装的 MMDeploy
+
+假设当前的工作目录为 mmyolo 的根目录, 那么以 [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) 模型为例,你可以从[此处](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth)下载对应的 checkpoint,并使用以下代码将之转换为 onnx 模型:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## 模型规范
+
+在使用转换后的模型进行推理之前,有必要了解转换结果的结构。 它存放在 `--work-dir` 指定的路路径下。
+
+上例中的`mmdeploy_models/mmyolo/onnx`,结构如下:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+重要的是:
+
+- **end2end.onnx**: 推理引擎文件。可用 ONNX Runtime 推理
+- ***xxx*.json**: mmdeploy SDK 推理所需的 meta 信息
+
+整个文件夹被定义为**mmdeploy SDK model**。换言之,**mmdeploy SDK model**既包括推理引擎,也包括推理 meta 信息。
+
+## 模型推理
+
+### 后端模型推理
+
+以上述模型转换后的 `end2end.onnx` 为例,你可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+运行上述代码后,你可以在 `work_dir` 中看到推理的结果图片 `output_detection.png`。
+
+### SDK模型推理
+
+你也可以参考如下代码,对 SDK model 进行推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
+
## 模型评测
当您将 PyTorch 模型转换为后端支持的模型后,您可能需要验证模型的精度,使用 `${MMDEPLOY_DIR}/tools/test.py`
@@ -248,20 +378,19 @@ python3 ${MMDEPLOY_DIR}/tools/test.py \
${DEPLOY_CFG} \
${MODEL_CFG} \
--model ${BACKEND_MODEL_FILES} \
- [--out ${OUTPUT_PKL_FILE}] \
- [--format-only] \
- [--metrics ${METRICS}] \
- [--show] \
- [--show-dir ${OUTPUT_IMAGE_DIR}] \
- [--show-score-thr ${SHOW_SCORE_THR}] \
--device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
[--cfg-options ${CFG_OPTIONS}] \
- [--metric-options ${METRIC_OPTIONS}]
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
[--log2file work_dirs/output.txt]
- [--batch-size ${BATCH_SIZE}]
[--speed-test] \
[--warmup ${WARM_UP}] \
- [--log-interval ${LOG_INTERVERL}]
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
```
### 参数描述
@@ -269,19 +398,18 @@ python3 ${MMDEPLOY_DIR}/tools/test.py \
- `deploy_cfg`: 部署配置文件。
- `model_cfg`: MMYOLO 模型配置文件。
- `--model`: 导出的后端模型。 例如, 如果我们导出了 TensorRT 模型,我们需要传入后缀为 ".engine" 文件路径。
-- `--out`: 保存 pickle 格式的输出结果,仅当您传入这个参数时启用。
-- `--format-only`: 是否格式化输出结果而不进行评估。当您要将结果格式化为特定格式并将其提交到测试服务器时,它很有用。
-- `--metrics`: 用于评估 MMYOLO 中定义的模型的指标,如 COCO 标注格式的 "proposal" 。
-- `--show`: 是否在屏幕上显示评估结果。
-- `--show-dir`: 保存评估结果的目录。(只有给出这个参数才会保存结果)。
-- `--show-score-thr`: 确定是否显示检测边界框的阈值。
- `--device`: 运行模型的设备。请注意,某些后端会限制设备。例如,TensorRT 必须在 cuda 上运行。
+- `--work-dir`: 模型转换、报告生成的路径。
- `--cfg-options`: 传入额外的配置,将会覆盖当前部署配置。
-- `--metric-options`: 用于评估的自定义选项。 xxx=yyy 中的键值对格式,将是 dataset.evaluate() 函数的 kwargs。
+- `--show`: 是否在屏幕上显示评估结果。
+- `--show-dir`: 保存评估结果的目录。(只有给出这个参数才会保存结果)。
+- `--interval`: 屏幕上显示评估结果的间隔。
+- `--wait-time`: 每个窗口的显示时间
- `--log2file`: 将评估结果(和速度)记录到文件中。
-- `--batch-size`: 推理的批量大小,它将覆盖数据配置中的 `samples_per_gpu`。默认为 `1`。请注意,并非所有模型都支持 `batch_size > 1`。
-- `--speed-test`: 是否开启速度测试。
+- `--speed-test`: 是否开启速度测试。
- `--warmup`: 在计算推理时间之前进行预热,需要先开启 `speed-test`。
- `--log-interval`: 每个日志之间的间隔,需要先设置 `speed-test`。
+- `--batch-size`: 推理的批量大小,它将覆盖数据配置中的 `samples_per_gpu`。默认为 `1`。请注意,并非所有模型都支持 `batch_size > 1`。
+- `--uri`: 在边缘设备上推理时的 ipv4 或 ipv6 端口号。
注意:`${MMDEPLOY_DIR}/tools/test.py` 中的其他参数用于速度测试。他们不影响评估。
diff --git a/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
index c48a64062..e035e1764 100644
--- a/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
+++ b/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -28,7 +28,7 @@
_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(
type='LetterResize',
scale=_base_.img_scale,
@@ -113,7 +113,7 @@ batch_shapes_cfg = dict(
extra_pad_ratio=0.5)
test_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -251,6 +251,7 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
--work-dir work_dir \
--show \
--device cpu
+ --dump-info
```
#### TensorRT
@@ -264,19 +265,20 @@ python3 ${MMDEPLOY_DIR}/tools/deploy.py \
--work-dir work_dir \
--show \
--device cuda:0
+ --dump-info
```
当您使用上述命令转换模型时,您将会在 `work_dir` 文件夹下发现以下文件:
-
+
或者
-
+
-在导出 `onnxruntime`模型后,您将得到图1的三个文件,其中 `end2end.onnx` 表示导出的`onnxruntime`模型。
+在导出 `onnxruntime`模型后,您将得到图1的六个文件,其中 `end2end.onnx` 表示导出的`onnxruntime`模型,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
-在导出 `TensorRT`模型后,您将得到图2的四个文件,其中 `end2end.onnx` 表示导出的中间模型,`MMDeploy`利用该模型自动继续转换获得 `end2end.engine` 模型用于 `TensorRT `部署。
+在导出 `TensorRT`模型后,您将得到图2的七个文件,其中 `end2end.onnx` 表示导出的中间模型,`MMDeploy`利用该模型自动继续转换获得 `end2end.engine` 模型用于 `TensorRT `部署,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
## 模型评测
@@ -428,4 +430,143 @@ python3 ${MMDEPLOY_DIR}/tools/profiler.py \
## 模型推理
-TODO
+### 后端模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK 模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
diff --git a/docs/zh_cn/recommended_topics/industry_examples.md b/docs/zh_cn/recommended_topics/industry_examples.md
deleted file mode 100644
index 19960ce46..000000000
--- a/docs/zh_cn/recommended_topics/industry_examples.md
+++ /dev/null
@@ -1 +0,0 @@
-# MMYOLO 产业范例介绍
diff --git a/docs/zh_cn/recommended_topics/training_testing_tricks.md b/docs/zh_cn/recommended_topics/training_testing_tricks.md
new file mode 100644
index 000000000..ba67063f0
--- /dev/null
+++ b/docs/zh_cn/recommended_topics/training_testing_tricks.md
@@ -0,0 +1,303 @@
+# 训练和测试技巧
+
+MMYOLO 中已经支持了大部分 YOLO 系列目标检测相关算法。不同算法可能涉及到一些实用技巧。本章节将基于所实现的目标检测算法,详细描述 MMYOLO 中已经支持的常用的训练和测试技巧。
+
+## 训练技巧
+
+### 提升检测性能
+
+#### 1 开启多尺度训练
+
+在目标检测领域,多尺度训练是一个非常常用的技巧,但是在 YOLO 中大部分模型的训练输入都是单尺度的 640x640,原因有两个方面:
+
+1. 单尺度训练速度快。当训练 epoch 在 300 或者 500 的时候训练效率是用户非常关注的,多尺度训练会比较慢
+2. 训练 pipeline 中隐含了多尺度增强,等价于应用了多尺度训练,典型的如 `Mosaic`、`RandomAffine` 和 `Resize` 等,故没有必要再次引入模型输入的多尺度训练
+
+在 COCO 数据集上进行了简单实验,如果直接在 YOLOv5 的 DataLoader 输出后再次引入多尺度训练增强实际性能提升非常小,但是这不代表用户自定义数据集微调模式下没有明显增益。如果想在 MMYOLO 中对 YOLO 系列算法开启多尺度训练,可以参考 [多尺度训练文档](../common_usage/ms_training_testing.md)
+
+#### 2 使用 Mask 标注优化目标检测性能
+
+在数据集标注完备例如同时存在边界框和实例分割标注但任务只需要其中部分标注情况下,可以借助完备的数据标注训练单一任务从而提升性能。在目标检测中同样可以借鉴实例分割标注来提升目标检测性能。 以下是 YOLOv8 额外引入实例分割标注优化目标检测结果。 性能增益如下所示:
+
+
+
+
+
+从上述曲线图可以看出,不同尺度模型都有了不同程度性能提升。需要注意的是 `Mask Refine` 仅仅的是作用在数据增强阶段,对模型其他训练部分不需要任何改动,且不会影响训练速度。具体如下所示:
+
+
+
+
+
+上述的 Mask 表示实例分割标注发挥关键作用的数据增强变换,将该技巧应用到其他 YOLO 系列中均有不同程度涨点。
+
+#### 3 训练后期关闭强增强提升检测性能
+
+该策略是在 YOLOX 算法中第一次被提出可以极大的提升检测性能。 论文中指出虽然 Mosaic+MixUp 可以极大的提升目标检测性能,但是它生成的训练图片远远脱离自然图片的真实分布,并且 Mosaic 大量的裁剪操作会带来很多不准确的标注框,所以 YOLOX 提出在最后 15 个 epoch 关掉强增强,转而使用较弱的增强,从而为了让检测器避开不准确标注框的影响,在自然图片的数据分布下完成最终的收敛。
+
+该策略已经被应用到了大部分 YOLO 算法中,以 YOLOv8 为例其数据增强 pipeline 如下所示:
+
+
+
+
+
+不过在何时关闭强增强是一个超参,如果关闭太早则可能没有充分发挥 Mosaic 等强增强效果,如果关闭太晚则由于之前已经过拟合,此时再关闭则没有任何增益。 在 YOLOv8 实验中可以观察到该现象
+
+| Backbone | Mask Refine | box AP | Epoch of best mAP |
+| :------: | :---------: | :---------: | :---------------: |
+| YOLOv8-n | No | 37.2 | 500 |
+| YOLOv8-n | Yes | 37.4 (+0.2) | 499 |
+| YOLOv8-s | No | 44.2 | 430 |
+| YOLOv8-s | Yes | 45.1 (+0.9) | 460 |
+| YOLOv8-m | No | 49.8 | 460 |
+| YOLOv8-m | Yes | 50.6 (+0.8) | 480 |
+| YOLOv8-l | No | 52.1 | 460 |
+| YOLOv8-l | Yes | 53.0 (+0.9) | 491 |
+| YOLOv8-x | No | 52.7 | 450 |
+| YOLOv8-x | Yes | 54.0 (+1.3) | 460 |
+
+从上表可以看出:
+
+- 大模型在 COCO 数据集训练 500 epoch 会过拟合,在过拟合情况下再关闭 Mosaic 等强增强效果没有效果
+- 使用 Mask 标注可以缓解过拟合,并且提升性能
+
+#### 4 加入纯背景图片抑制误报率
+
+对于非开放世界数据集目标检测而言,训练和测试都是在固定类别上进行,一旦应用到没有训练过的类别图片上有可能会产生误报,一个常见的缓解策略是加入一定比例的纯背景图片。 在大部分 YOLO 系列中都是默认开启了加入纯背景图片抑制误报率功能,用户只需要设置 `train_dataloader.dataset.filter_cfg.filter_empty_gt` 为 False 即可,表示将纯背景图片不过滤掉加入训练。
+
+#### 5 试试 AdamW 也许效果显著
+
+YOLOv5,YOLOv6,YOLOv7 和 YOLOv8 等都是采用了 SGD 优化器,该参数器对参数的设置比较严格,而 AdamW 则正好相反,其对学习率设置等没有那么敏感。因此如果用户在自定义数据集微调可以尝试选择 AdamW 优化器。我们在 YOLOX 中进行了简单尝试,发现在 tiny、s 和 m 尺度模型上将其优化器替换为 AdamW 均有一定程度涨点。
+
+| Backbone | Size | Batch Size | RTMDet-Hyp | Box AP |
+| :--------: | :--: | :--------: | :--------: | :---------: |
+| YOLOX-tiny | 416 | 8xb8 | No | 32.7 |
+| YOLOX-tiny | 416 | 8xb32 | Yes | 34.3 (+1.6) |
+| YOLOX-s | 640 | 8xb8 | No | 40.7 |
+| YOLOX-s | 640 | 8xb32 | Yes | 41.9 (+1.2) |
+| YOLOX-m | 640 | 8xb8 | No | 46.9 |
+| YOLOX-m | 640 | 8xb32 | Yes | 47.5 (+0.6) |
+
+具体见 [configs/yolox/README.md](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolox/README.md#--results-and-models)。
+
+#### 6 考虑 ignore 场景避免不确定性标注
+
+以 CrowdHuman 为例,其是一个拥挤行人检测数据集,下面是一张典型图片:
+
+
+
+
+
+图片来自 [detectron2 issue](https://github.com/facebookresearch/detectron2/issues/1909)。黄色打叉的区域表示 `iscrowd` 标注。原因有两个方面:
+
+- 这个区域不是真的人,例如海报上的人
+- 该区域过于拥挤,很难标注
+
+在该场景下,你不能简单的将这类标注删掉,因为你一旦删掉就表示当做背景区域来训练了,但是其和背景是不一样的,首先海报上的人和真人很像,并且拥挤区域确实有人只是不好标注。如果你简单的将其当做背景训练,那么会造成漏报。最合适的做法应该是把拥挤区域当做忽略区域即该区域的任何输出都直接忽略,不计算任何 Loss,不强迫模型拟合。
+
+MMYOLO 在 YOLOv5 上简单快速的验证了 `iscrowd` 标注的作用,性能如下所示:
+
+| Backbone | ignore_iof_thr | box AP50(CrowDHuman Metric) | MR | JI |
+| :------: | :------------: | :-------------------------: | :--: | :---: |
+| YOLOv5-s | -1 | 85.79 | 48.7 | 75.33 |
+| YOLOv5-s | 0.5 | 86.17 | 48.8 | 75.87 |
+
+`ignore_iof_thr`为 -1 表示不考虑忽略标签,可以看出性能有一定程度的提升,具体见 [CrowdHuman 结果](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/README.md#crowdhuman)。 如果你的自定义数据集上也有上述情况,则建议你考虑 ignore 场景避免不确定性标注。
+
+#### 7 使用知识蒸馏
+
+知识蒸馏是一个被广泛使用的技巧,可以将大模型性能转移到小模型上从而提升小模型检测性能。 目前 MMYOLO 和 MMRazor 已支持了该功能,并在 RTMDet 上进行了初步验证。
+
+| Model | box AP |
+| :------------: | :---------: |
+| RTMDet-tiny | 41.0 |
+| RTMDet-tiny \* | 41.8 (+0.8) |
+| RTMDet-s | 44.6 |
+| RTMDet-s \* | 45.7 (+1.1) |
+| RTMDet-m | 49.3 |
+| RTMDet-m \* | 50.2 (+0.9) |
+| RTMDet-l | 51.4 |
+| RTMDet-l \* | 52.3 (+0.9) |
+
+星号即为采用了大模型蒸馏的结果,详情见 [Distill RTMDet](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet/distillation)。
+
+#### 8 更大的模型用更强的增强参数
+
+如果你基于默认配置修改了模型或者替换了骨干网络,那么建议你基于此刻模型大小来缩放数据增强参数。 一般来说更大的模型需要使用更强的增强参数,否则可能无法发挥大模型的效果,反之如果小模型应用了较强的增强则可能会欠拟合。 以 RTMDet 为例,我们可以观察其不同模型大小的数据增强参数
+
+
+
+
+
+其中 `random_resize_ratio_range` 表示 `RandomResize` 的随机缩放范围,`mosaic_max_cached_images/mixup_max_cached_images`表示 `Mosaic/MixUp` 增强时候缓存的图片个数,可以用于调整增强的强度。 YOLO 系列模型都是遵循同一套参数设置原则。
+
+### 加快训练速度
+
+#### 1 单尺度训练开启 cudnn_benchmark
+
+YOLO 系列算法中大部分网络输入图片大小都是固定的即单尺度,此时可以开启 `cudnn_benchmark` 来加快训练速度。该参数主要针对 PyTorch 的 cuDNN 底层库进行设置, 设置这个标志可以让内置的 cuDNN 自动寻找最适合当前配置的高效算法来优化运行效率。如果是多尺度模式开启该标志则会不断的寻找最优算法,反而会拖慢训练速度。
+
+在 MMYOLO 中开启 `cudnn_benchmark`,只需要在配置中设置 `env_cfg = dict(cudnn_benchmark=True)`
+
+#### 2 使用带缓存的 Mosaic 和 MixUp
+
+如果你的数据增强中应用了 Mosaic 和 MixUp,并且经过排查训练瓶颈来自图片的随机读取,那么建议将常规的 Mosaic 和 MixUp 替换为 RTMDet 中提出的带缓存的版本。
+
+| Data Aug | Use cache | ms/100 imgs |
+| :------: | :-------: | :---------: |
+| Mosaic | No | 87.1 |
+| Mosaic | Yes | 24.0 |
+| MixUp | No | 19.3 |
+| MixUp | Yes | 12.4 |
+
+Mosaic 和 MixUp 涉及到多张图片的混合,它们的耗时会是普通数据增强的 K 倍(K 为混入图片的数量)。 如在 YOLOv5 中每次做 Mosaic 时, 4 张图片的信息都需要从硬盘中重新加载。 而带缓存的 Mosaic 和 MixUp 只需要重新载入当前的一张图片,其余参与混合增强的图片则从缓存队列中获取,通过牺牲一定内存空间的方式大幅提升了效率。
+
+
+
+
+
+如图所示,cache 队列中预先储存了 N 张已加载的图像与标签数据,每一个训练 step 中只需加载一张新的图片及其标签数据并更新到 cache 队列中(cache 队列中的图像可重复,如图中出现两次 img3),同时如果 cache 队列长度超过预设长度,则随机 pop 一张图,当需要进行混合数据增强时,只需要从 cache 中随机选择需要的图像进行拼接等处理,而不需要全部从硬盘中加载,节省了图像加载的时间。
+
+### 减少超参
+
+YOLOv5 中通过实践提供了一些减少超参数的方法,下面详细说明。
+
+#### 1 Loss 权重自适应,少 1 个超参
+
+一般来说,对于不同的任务或者不同的类别,可能需要针对性的设置超参,而这通常比较难。YOLOv5 中根据实践提出了一些根据类别数和检测输出层个数来自适应缩放 Loss 权重的方法,如下所示:
+
+```python
+# scaled based on number of detection layers
+loss_cls=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=loss_cls_weight *
+ (num_classes / 80 * 3 / num_det_layers)),
+loss_bbox=dict(
+ type='IoULoss',
+ iou_mode='ciou',
+ bbox_format='xywh',
+ eps=1e-7,
+ reduction='mean',
+ loss_weight=loss_bbox_weight * (3 / num_det_layer
+ return_iou=True),
+loss_obj=dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='mean',
+ loss_weight=loss_obj_weight *
+ ((img_scale[0] / 640)**2 * 3 / num_det_layers)),
+```
+
+`loss_cls` 可以根据自定义类别数和检测层数对 `loss_weight` 进行自适应缩放,`loss_bbox` 可以根据检测层数进行自适应计算,而 `loss_obj` 可以根据输入图片大小和检测层数进行自适应缩放。这种策略可以让用户不用去设置 Loss 权重超参。
+需要说明的是:这个只是经验规则,并不是说是最佳设置组合,只是作为一个参考。
+
+#### 2 Weight Decay 和 Loss 输出值基于 Batch Size 自适应,少 2 个超参
+
+一般来说,在不同的 `Batch Size` 上进行训练,需要遵循学习率自动缩放规则。但是在各个数据集上验证表明 YOLOv5 实际上在改变 `Batch Size` 时候不缩放学习率也可以取得不错的效果,甚至有时候你缩放了效果还更差。原因就在于代码中存在 `Weight Decay` 和 Loss 输出值基于 `Batch Size` 自适应的技巧。在 YOLOv5 中会基于当前训练的总 `Batch Size` 来缩放 `Weight Decay` 和 Loss 输出值。对应代码为:
+
+```python
+# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/engine/optimizers/yolov5_optim_constructor.py#L86
+if 'batch_size_per_gpu' in optimizer_cfg:
+ batch_size_per_gpu = optimizer_cfg.pop('batch_size_per_gpu')
+ # No scaling if total_batch_size is less than
+ # base_total_batch_size, otherwise linear scaling.
+ total_batch_size = get_world_size() * batch_size_per_gpu
+ accumulate = max(
+ round(self.base_total_batch_size / total_batch_size), 1)
+ scale_factor = total_batch_size * \
+ accumulate / self.base_total_batch_size
+ if scale_factor != 1:
+ weight_decay *= scale_factor
+ print_log(f'Scaled weight_decay to {weight_decay}', 'current')
+```
+
+```python
+# https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/dense_heads/yolov5_head.py#L635
+ _, world_size = get_dist_info()
+ return dict(
+ loss_cls=loss_cls * batch_size * world_size,
+ loss_obj=loss_obj * batch_size * world_size,
+ loss_bbox=loss_box * batch_size * world_size)
+```
+
+在不同的 Batch Size 下 Loss 的权重是不一样大的,Batch Size 越大,Loss 就越大,梯度就越大,我个人猜测这可以等价于 Batch Size 增大时候,学习率线性增加的场合。
+实际上从 YOLOv5 的 [YOLOv5 Study: mAP vs Batch-Size](https://github.com/ultralytics/yolov5/discussions/2452) 中可以发现确实是希望用户在修改 Batch Size 时不需要修改其他参数也可以相近的性能。上述两个策略是一个非常不错的训练技巧。
+
+### 减少训练显存
+
+如何减少训练显存是一个经常谈论的问题,所涉及的技术也非常多。 MMYOLO 的训练执行器来自 MMEngine,因此如何减少训练显存可以查阅 MMEngine 的文档。 MMEngine 目前支持梯度累加、梯度检查点和大模型训练技术,详情见
+[节省显存](https://mmengine.readthedocs.io/zh_CN/latest/common_usage/save_gpu_memory.html)。
+
+## 测试技巧
+
+### 推理速度和测试精度的平衡
+
+在模型性能测试时候,我们一般是要求 mAP 越高越好,但是在实际应用或者推理时候我们希望在保证低误报率和漏报率情况下模型推理越快越好,或者说测试只关注 mAP 而忽略了后处理和评估速度,而实际落地应用时候会追求速度和精度的平衡。
+在 YOLO 系列中可以通过控制某些参数实现速度和精度平衡,下面以 YOLOv5 为例对其进行详细描述。
+
+#### 1 推理时避免一个检测框输出多个类别
+
+YOLOv5 在训练分类分支时候采用的是 BCE Loss 即 `use_sigmoid=True`。假设物体类别数是 4,那么分类分支输出的类别数是 4 而不是 5,并且由于使用的是 sigmoid 而非 softmax 预测模式,很可能在某个位置预测出多个满足过滤阈值的检测框,也就是会出现一个预测 bbox 对应多个预测 label 的情况。如下图所示
+
+
+
+
+
+一般在计算 mAP 时候过滤阈值为 0.001,由于 sigmoid 非竞争性预测模式会导致一个框对应多个 label。这种计算方式可以提高 mAP 计算时候的召回率,但是实际落地应用会不方便。
+
+一个常用的办法就是提高过滤阈值,但是如果你不需要出现较多漏报,此时推荐你修改 `multi_label` 参数为 False,其位于配置的 `mode.test_cfg.multi_label` 中,默认值是 True 表示允许一个检测框对应多个 label。
+
+#### 2 简化 test pipeline
+
+注意到 YOLOv5 的 test pipeline 为如下:
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+其使用了两个不同功能的 Resize,目的依然是提高评估时候的 mAP 值。在实际落地应用时候你可以简化该 pipeline,如下所示:
+
+```python
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=True,
+ use_mini_pad=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+```
+
+实际上 YOLOv5 算法在实际应用时候是采用简化的 pipeline,并将 multi_label 设为 False, score_thr 提高为 0.25, iou_threshold 降低为 0.45。
+在 YOLOv5 配置中我们提供了一套 detect 落地时候的配置参数,具体见 [yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn-detect_8xb16-300e_coco.py)。
+
+#### 3 Batch Shape 策略加快测试速度
+
+Batch Shape 是 YOLOv5 中提出的可以加快推理的一个测试技巧,其思路是不再强制要求整个测试过程图片都是 640x640,而是可以变尺度测试,只需要保证当前 batch 内的 shape 是一样的就行。这种方式可以减少额外的图片像素填充,从而实现加速推理过程。
+Batch Shape 的具体实现可以参考 [链接](https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/datasets/utils.py#L55)。MMYOLO 中几乎所有算法在测试时候都是默认开启了 Batch Shape 策略。 如果用户想关闭该功能,可以设置 `val_dataloader.dataset.batch_shapes_cfg=None`。
+
+在实际落地场景下,因为动态 shape 没有固定 shape 快且高效,所以一般会不采用这个策略。
+
+### TTA 提升测试精度
+
+TTA 测试时增强是一个万能的涨点技巧,在打比赛时候非常有用。MMYOLO 已经支持了 TTA,只需要在测试时候输入 `--tta` 即可开启。详情见 [TTA 说明](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/common_usage/tta.md)。
diff --git a/docs/zh_cn/recommended_topics/visualization.md b/docs/zh_cn/recommended_topics/visualization.md
index 8a1b8c6fb..ed4bbf94d 100644
--- a/docs/zh_cn/recommended_topics/visualization.md
+++ b/docs/zh_cn/recommended_topics/visualization.md
@@ -90,8 +90,7 @@ python demo/featmap_vis_demo.py demo/dog.jpg \
```python
test_pipeline = [
dict(
- type='LoadImageFromFile',
- file_client_args={{_base_.file_client_args}}),
+ type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -112,7 +111,7 @@ test_pipeline = [
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
@@ -197,7 +196,7 @@ python demo/featmap_vis_demo.py demo/dog.jpg \
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -218,7 +217,7 @@ test_pipeline = [
test_pipeline = [
dict(
type='LoadImageFromFile',
- file_client_args=_base_.file_client_args),
+ backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=img_scale, keep_ratio=False), # 这里将 LetterResize 修改成 mmdet.Resize
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
dict(
diff --git a/docs/zh_cn/tutorials/config.md b/docs/zh_cn/tutorials/config.md
index 12c7aafe2..d43a4fceb 100644
--- a/docs/zh_cn/tutorials/config.md
+++ b/docs/zh_cn/tutorials/config.md
@@ -86,12 +86,10 @@ YOLOv5 的训练与测试的数据流存在一定差异,这里我们分别进
```python
dataset_type = 'CocoDataset' # 数据集类型,这将被用来定义数据集
data_root = 'data/coco/' # 数据的根路径
-file_client_args = dict(backend='disk') # 文件读取后端的配置,默认从硬盘读取
pre_transform = [ # 训练数据读取流程
dict(
- type='LoadImageFromFile', # 第 1 个流程,从文件路径里加载图像
- file_client_args=file_client_args), # 文件读取后端的配置,默认从硬盘读取
+ type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像
dict(type='LoadAnnotations', # 第 2 个流程,对于当前图像,加载它的注释信息
with_bbox=True) # 是否使用标注框(bounding box),目标检测需要设置为 True
]
@@ -156,8 +154,7 @@ YOLOv5 测试阶段采用 [Letter Resize](https://github.com/open-mmlab/mmyolo/b
```python
test_pipeline = [ # 测试数据处理流程
dict(
- type='LoadImageFromFile', # 第 1 个流程,从文件路径里加载图像
- file_client_args=file_client_args), # 文件读取后端的配置,默认从硬盘读取
+ type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像
dict(type='YOLOv5KeepRatioResize', # 第 2 个流程,保持长宽比的图像大小缩放
scale=img_scale), # 图像缩放的目标尺寸
dict(
@@ -475,8 +472,7 @@ train_pipeline = [
test_pipeline = [
dict(
- type='LoadImageFromFile',
- file_client_args={{_base_.file_client_args}}),
+ type='LoadImageFromFile'),
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
dict(
type='LetterResize',
@@ -515,7 +511,6 @@ model = dict(
```python
_base_ = '../_base_/default_runtime.py'
-file_client_args = {{_base_.file_client_args}} # 变量 file_client_args 等于 _base_ 中定义的 file_client_args
pre_transform = _base_.pre_transform # 变量 pre_transform 等于 _base_ 中定义的 pre_transform
```
diff --git a/docs/zh_cn/tutorials/custom_installation.md b/docs/zh_cn/tutorials/custom_installation.md
index cdec9ed35..d20d659f6 100644
--- a/docs/zh_cn/tutorials/custom_installation.md
+++ b/docs/zh_cn/tutorials/custom_installation.md
@@ -77,7 +77,7 @@ pip install "mmcv>=2.0.0rc4" -f https://download.openmmlab.com/mmcv/dist/cu116/t
!pip3 install openmim
!mim install "mmengine>=0.6.0"
!mim install "mmcv>=2.0.0rc4,<2.1.0"
-!mim install "mmdet>=3.0.0rc6,<3.1.0"
+!mim install "mmdet>=3.0.0,<4.0.0"
```
**步骤 2.** 使用源码安装 MMYOLO:
diff --git a/docs/zh_cn/tutorials/faq.md b/docs/zh_cn/tutorials/faq.md
index 053cbb32c..71ee01d47 100644
--- a/docs/zh_cn/tutorials/faq.md
+++ b/docs/zh_cn/tutorials/faq.md
@@ -79,7 +79,7 @@ EasyDeploy 支持的功能目前没有 MMDeploy 多,但是使用上更加简
## 如何使用多个 MMYOLO 版本进行开发
-推荐你拥有多个 MMYOLO 工程文件夹,例如 mmyolo-v1, mmyolo-v2。 在使用不同版本 MMYOLO 时候,你可以在终端运行前设置
+若你拥有多个 MMYOLO 工程文件夹,例如 mmyolo-v1, mmyolo-v2。 在使用不同版本 MMYOLO 时候,你可以在终端运行前设置
```shell
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH
@@ -94,7 +94,7 @@ unset PYTHONPATH
## 训练中保存最好模型
用户可以通过在配置中设置 `default_hooks.checkpoint.save_best` 参数来选择根据什么指标来筛选最优模型。以 `COCO` 数据集检测任务为例,
-则 `default_hooks.checkpoint.save_best` 可以选择输入的参数有:
+`default_hooks.checkpoint.save_best` 可以选择输入的参数有:
1. `auto` 将会根据验证集中的第一个评价指标作为筛选条件。
2. `coco/bbox_mAP` 将会根据 `bbox_mAP` 作为筛选条件。
@@ -106,6 +106,6 @@ unset PYTHONPATH
此外用户还可以选择筛选的逻辑,通过设置配置中的 `default_hooks.checkpoint.rule` 来选择判断逻辑,如:`default_hooks.checkpoint.rule=greater` 表示指标越大越好。更详细的使用可以参考 [checkpoint_hook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py) 来修改
-## 如何进行非正方形输入尺寸训练和测试 ?
+## 如何进行非正方形输入尺寸训练和测试?
在 YOLO 系列算法中默认配置基本上都是 640x640 或者 1280x1280 正方形尺度输入训练的。用户如果想进行非正方形尺度训练,你可以修改配置中 `image_scale` 参数,并将其他对应位置进行修改即可。用户可以参考我们提供的 [yolov5_s-v61_fast_1xb12-40e_608x352_cat.py](https://github.com/open-mmlab/mmyolo/tree/dev/configs/yolov5/yolov5_s-v61_fast_1xb12-40e_608x352_cat.py) 配置。
diff --git a/docs/zh_cn/tutorials/rotated_detection.md b/docs/zh_cn/tutorials/rotated_detection.md
index b06df9b91..1ee974b10 100644
--- a/docs/zh_cn/tutorials/rotated_detection.md
+++ b/docs/zh_cn/tutorials/rotated_detection.md
@@ -64,15 +64,13 @@ mmyolo
```python
dataset_type = 'YOLOv5DOTADataset' # 数据集类型,这将被用来定义数据集
data_root = 'data/split_ss_dota/' # 数据的根路径
-file_client_args = dict(backend='disk') # 文件读取后端的配置,默认从硬盘读取
angle_version = 'le90' # 角度范围的定义,目前支持 oc, le90 和 le135
train_pipeline = [
# 训练数据读取流程
dict(
- type='LoadImageFromFile', # 第 1 个流程,从文件路径里加载图像
- file_client_args=file_client_args), # 文件读取后端的配置,默认从硬盘读取
+ type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像
dict(type='LoadAnnotations', # 第 2 个流程,对于当前图像,加载它的注释信息
with_bbox=True, # 是否使用标注框 (bounding box),目标检测需要设置为 True
box_type='qbox'), # 指定读取的标注格式,旋转框数据集默认的数据格式为四边形
@@ -122,7 +120,7 @@ RTMDet-R 测试阶段仅采用 Resize 和 Pad,在验证和评测时,都采
```python
val_pipeline = [
- dict(type='LoadImageFromFile', file_client_args=_base_.file_client_args),
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
dict(type='mmdet.Resize', scale=(1024, 1024), keep_ratio=True),
dict(
type='mmdet.Pad', size=(1024, 1024),
@@ -205,8 +203,7 @@ dataset_type='YOLOv5CocoDataset'
train_pipeline = [
# 训练数据读取流程
dict(
- type='LoadImageFromFile', # 第 1 个流程,从文件路径里加载图像
- file_client_args=file_client_args), # 文件读取后端的配置,默认从硬盘读取
+ type='LoadImageFromFile'), # 第 1 个流程,从文件路径里加载图像
dict(type='LoadAnnotations', # 第 2 个流程,对于当前图像,加载它的注释信息
with_bbox=True, # 是否使用标注框 (bounding box),目标检测需要设置为 True
with_mask=True, # 读取储存在 segmentation 标注中的多边形标注
diff --git a/docs/zh_cn/tutorials/warning_notes.md b/docs/zh_cn/tutorials/warning_notes.md
index d1051ba14..38b65c983 100644
--- a/docs/zh_cn/tutorials/warning_notes.md
+++ b/docs/zh_cn/tutorials/warning_notes.md
@@ -19,4 +19,4 @@
## The model and loaded state dict do not match exactly
-这个警告是否会影响性能要根据进一步的打印信息来确定。如果是在微调模式下,由于用户自定义类别不一样无法加载 Head 模块的 COCO 预训练,这是一个正常现象,不会影响性能。
+这个警告是否会影响性能要根据进一步的打印信息来确定。如果是在微调模式下,由于用户自定义类别不一样无法加载 Head 模块的 COCO 预训练权重,这是一个正常现象,不会影响性能。
diff --git a/mmyolo/__init__.py b/mmyolo/__init__.py
index a7a2f3333..6a0bd5d30 100644
--- a/mmyolo/__init__.py
+++ b/mmyolo/__init__.py
@@ -10,12 +10,12 @@
mmcv_maximum_version = '2.1.0'
mmcv_version = digit_version(mmcv.__version__)
-mmengine_minimum_version = '0.6.0'
+mmengine_minimum_version = '0.7.1'
mmengine_maximum_version = '1.0.0'
mmengine_version = digit_version(mmengine.__version__)
-mmdet_minimum_version = '3.0.0rc6'
-mmdet_maximum_version = '3.1.0'
+mmdet_minimum_version = '3.0.0'
+mmdet_maximum_version = '4.0.0'
mmdet_version = digit_version(mmdet.__version__)
diff --git a/mmyolo/datasets/__init__.py b/mmyolo/datasets/__init__.py
index b3b6b9719..9db439045 100644
--- a/mmyolo/datasets/__init__.py
+++ b/mmyolo/datasets/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .pose_coco import PoseCocoDataset
from .transforms import * # noqa: F401,F403
from .utils import BatchShapePolicy, yolov5_collate
from .yolov5_coco import YOLOv5CocoDataset
@@ -8,5 +9,6 @@
__all__ = [
'YOLOv5CocoDataset', 'YOLOv5VOCDataset', 'BatchShapePolicy',
- 'yolov5_collate', 'YOLOv5CrowdHumanDataset', 'YOLOv5DOTADataset'
+ 'yolov5_collate', 'YOLOv5CrowdHumanDataset', 'YOLOv5DOTADataset',
+ 'PoseCocoDataset'
]
diff --git a/mmyolo/datasets/pose_coco.py b/mmyolo/datasets/pose_coco.py
new file mode 100644
index 000000000..b17f9836a
--- /dev/null
+++ b/mmyolo/datasets/pose_coco.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any
+
+from mmengine.dataset import force_full_init
+
+try:
+ from mmpose.datasets import CocoDataset as MMPoseCocoDataset
+except ImportError:
+ MMPoseCocoDataset = object
+
+from ..registry import DATASETS
+
+
+@DATASETS.register_module()
+class PoseCocoDataset(MMPoseCocoDataset):
+
+ METAINFO: dict = dict(from_file='configs/_base_/pose/coco.py')
+
+ def __init__(self, *args, **kwargs):
+ if MMPoseCocoDataset is object:
+ raise ImportError(
+ 'Please run "mim install -r requirements/mmpose.txt" '
+ 'to install mmpose first for PoseCocoDataset.')
+ super().__init__(*args, **kwargs)
+
+ @force_full_init
+ def prepare_data(self, idx) -> Any:
+ data_info = self.get_data_info(idx)
+ data_info['dataset'] = self
+ return self.pipeline(data_info)
diff --git a/mmyolo/datasets/transforms/__init__.py b/mmyolo/datasets/transforms/__init__.py
index 58f4e6fdb..7cdcf8625 100644
--- a/mmyolo/datasets/transforms/__init__.py
+++ b/mmyolo/datasets/transforms/__init__.py
@@ -1,8 +1,10 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .formatting import PackDetInputs
from .mix_img_transforms import Mosaic, Mosaic9, YOLOv5MixUp, YOLOXMixUp
-from .transforms import (LetterResize, LoadAnnotations, PPYOLOERandomCrop,
- PPYOLOERandomDistort, RegularizeRotatedBox,
- RemoveDataElement, YOLOv5CopyPaste,
+from .transforms import (FilterAnnotations, LetterResize, LoadAnnotations,
+ Polygon2Mask, PPYOLOERandomCrop, PPYOLOERandomDistort,
+ RandomAffine, RandomFlip, RegularizeRotatedBox,
+ RemoveDataElement, Resize, YOLOv5CopyPaste,
YOLOv5HSVRandomAug, YOLOv5KeepRatioResize,
YOLOv5RandomAffine)
@@ -10,5 +12,7 @@
'YOLOv5KeepRatioResize', 'LetterResize', 'Mosaic', 'YOLOXMixUp',
'YOLOv5MixUp', 'YOLOv5HSVRandomAug', 'LoadAnnotations',
'YOLOv5RandomAffine', 'PPYOLOERandomDistort', 'PPYOLOERandomCrop',
- 'Mosaic9', 'YOLOv5CopyPaste', 'RemoveDataElement', 'RegularizeRotatedBox'
+ 'Mosaic9', 'YOLOv5CopyPaste', 'RemoveDataElement', 'RegularizeRotatedBox',
+ 'Polygon2Mask', 'PackDetInputs', 'RandomAffine', 'RandomFlip', 'Resize',
+ 'FilterAnnotations'
]
diff --git a/mmyolo/datasets/transforms/formatting.py b/mmyolo/datasets/transforms/formatting.py
new file mode 100644
index 000000000..07eb0121e
--- /dev/null
+++ b/mmyolo/datasets/transforms/formatting.py
@@ -0,0 +1,113 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmcv.transforms import to_tensor
+from mmdet.datasets.transforms import PackDetInputs as MMDET_PackDetInputs
+from mmdet.structures import DetDataSample
+from mmdet.structures.bbox import BaseBoxes
+from mmengine.structures import InstanceData, PixelData
+
+from mmyolo.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class PackDetInputs(MMDET_PackDetInputs):
+ """Pack the inputs data for the detection / semantic segmentation /
+ panoptic segmentation.
+
+ Compared to mmdet, we just add the `gt_panoptic_seg` field and logic.
+ """
+ mapping_table = {
+ 'gt_bboxes': 'bboxes',
+ 'gt_bboxes_labels': 'labels',
+ 'gt_masks': 'masks',
+ 'gt_keypoints': 'keypoints',
+ 'gt_keypoints_visible': 'keypoints_visible'
+ }
+
+ def transform(self, results: dict) -> dict:
+ """Method to pack the input data.
+ Args:
+ results (dict): Result dict from the data pipeline.
+ Returns:
+ dict:
+ - 'inputs' (obj:`torch.Tensor`): The forward data of models.
+ - 'data_sample' (obj:`DetDataSample`): The annotation info of the
+ sample.
+ """
+ packed_results = dict()
+ if 'img' in results:
+ img = results['img']
+ if len(img.shape) < 3:
+ img = np.expand_dims(img, -1)
+ # To improve the computational speed by by 3-5 times, apply:
+ # If image is not contiguous, use
+ # `numpy.transpose()` followed by `numpy.ascontiguousarray()`
+ # If image is already contiguous, use
+ # `torch.permute()` followed by `torch.contiguous()`
+ # Refer to https://github.com/open-mmlab/mmdetection/pull/9533
+ # for more details
+ if not img.flags.c_contiguous:
+ img = np.ascontiguousarray(img.transpose(2, 0, 1))
+ img = to_tensor(img)
+ else:
+ img = to_tensor(img).permute(2, 0, 1).contiguous()
+
+ packed_results['inputs'] = img
+
+ if 'gt_ignore_flags' in results:
+ valid_idx = np.where(results['gt_ignore_flags'] == 0)[0]
+ ignore_idx = np.where(results['gt_ignore_flags'] == 1)[0]
+ if 'gt_keypoints' in results:
+ results['gt_keypoints_visible'] = results[
+ 'gt_keypoints'].keypoints_visible
+ results['gt_keypoints'] = results['gt_keypoints'].keypoints
+
+ data_sample = DetDataSample()
+ instance_data = InstanceData()
+ ignore_instance_data = InstanceData()
+
+ for key in self.mapping_table.keys():
+ if key not in results:
+ continue
+ if key == 'gt_masks' or isinstance(results[key], BaseBoxes):
+ if 'gt_ignore_flags' in results:
+ instance_data[
+ self.mapping_table[key]] = results[key][valid_idx]
+ ignore_instance_data[
+ self.mapping_table[key]] = results[key][ignore_idx]
+ else:
+ instance_data[self.mapping_table[key]] = results[key]
+ else:
+ if 'gt_ignore_flags' in results:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][valid_idx])
+ ignore_instance_data[self.mapping_table[key]] = to_tensor(
+ results[key][ignore_idx])
+ else:
+ instance_data[self.mapping_table[key]] = to_tensor(
+ results[key])
+ data_sample.gt_instances = instance_data
+ data_sample.ignored_instances = ignore_instance_data
+
+ if 'gt_seg_map' in results:
+ gt_sem_seg_data = dict(
+ sem_seg=to_tensor(results['gt_seg_map'][None, ...].copy()))
+ data_sample.gt_sem_seg = PixelData(**gt_sem_seg_data)
+
+ # In order to unify the support for the overlap mask annotations
+ # i.e. mask overlap annotations in (h,w) format,
+ # we use the gt_panoptic_seg field to unify the modeling
+ if 'gt_panoptic_seg' in results:
+ data_sample.gt_panoptic_seg = PixelData(
+ pan_seg=results['gt_panoptic_seg'])
+
+ img_meta = {}
+ for key in self.meta_keys:
+ assert key in results, f'`{key}` is not found in `results`, ' \
+ f'the valid keys are {list(results)}.'
+ img_meta[key] = results[key]
+
+ data_sample.set_metainfo(img_meta)
+ packed_results['data_samples'] = data_sample
+
+ return packed_results
diff --git a/mmyolo/datasets/transforms/keypoint_structure.py b/mmyolo/datasets/transforms/keypoint_structure.py
new file mode 100644
index 000000000..7b8402be9
--- /dev/null
+++ b/mmyolo/datasets/transforms/keypoint_structure.py
@@ -0,0 +1,248 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import ABCMeta
+from copy import deepcopy
+from typing import List, Optional, Sequence, Tuple, Type, TypeVar, Union
+
+import numpy as np
+import torch
+from torch import Tensor
+
+DeviceType = Union[str, torch.device]
+T = TypeVar('T')
+IndexType = Union[slice, int, list, torch.LongTensor, torch.cuda.LongTensor,
+ torch.BoolTensor, torch.cuda.BoolTensor, np.ndarray]
+
+
+class Keypoints(metaclass=ABCMeta):
+ """The Keypoints class is for keypoints representation.
+
+ Args:
+ keypoints (Tensor or np.ndarray): The keypoint data with shape of
+ (N, K, 2).
+ keypoints_visible (Tensor or np.ndarray): The visibility of keypoints
+ with shape of (N, K).
+ device (str or torch.device, Optional): device of keypoints.
+ Default to None.
+ clone (bool): Whether clone ``keypoints`` or not. Defaults to True.
+ flip_indices (list, Optional): The indices of keypoints when the
+ images is flipped. Defaults to None.
+
+ Notes:
+ N: the number of instances.
+ K: the number of keypoints.
+ """
+
+ def __init__(self,
+ keypoints: Union[Tensor, np.ndarray],
+ keypoints_visible: Union[Tensor, np.ndarray],
+ device: Optional[DeviceType] = None,
+ clone: bool = True,
+ flip_indices: Optional[List] = None) -> None:
+
+ assert len(keypoints_visible) == len(keypoints)
+ assert keypoints.ndim == 3
+ assert keypoints_visible.ndim == 2
+
+ keypoints = torch.as_tensor(keypoints)
+ keypoints_visible = torch.as_tensor(keypoints_visible)
+
+ if device is not None:
+ keypoints = keypoints.to(device=device)
+ keypoints_visible = keypoints_visible.to(device=device)
+
+ if clone:
+ keypoints = keypoints.clone()
+ keypoints_visible = keypoints_visible.clone()
+
+ self.keypoints = keypoints
+ self.keypoints_visible = keypoints_visible
+ self.flip_indices = flip_indices
+
+ def flip_(self,
+ img_shape: Tuple[int, int],
+ direction: str = 'horizontal') -> None:
+ """Flip boxes & kpts horizontally in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ direction (str): Flip direction, options are "horizontal",
+ "vertical" and "diagonal". Defaults to "horizontal"
+ """
+ assert direction == 'horizontal'
+ self.keypoints[..., 0] = img_shape[1] - self.keypoints[..., 0]
+ self.keypoints = self.keypoints[:, self.flip_indices]
+ self.keypoints_visible = self.keypoints_visible[:, self.flip_indices]
+
+ def translate_(self, distances: Tuple[float, float]) -> None:
+ """Translate boxes and keypoints in-place.
+
+ Args:
+ distances (Tuple[float, float]): translate distances. The first
+ is horizontal distance and the second is vertical distance.
+ """
+ assert len(distances) == 2
+ distances = self.keypoints.new_tensor(distances).reshape(1, 1, 2)
+ self.keypoints = self.keypoints + distances
+
+ def rescale_(self, scale_factor: Tuple[float, float]) -> None:
+ """Rescale boxes & keypoints w.r.t. rescale_factor in-place.
+
+ Note:
+ Both ``rescale_`` and ``resize_`` will enlarge or shrink boxes
+ w.r.t ``scale_facotr``. The difference is that ``resize_`` only
+ changes the width and the height of boxes, but ``rescale_`` also
+ rescales the box centers simultaneously.
+
+ Args:
+ scale_factor (Tuple[float, float]): factors for scaling boxes.
+ The length should be 2.
+ """
+ assert len(scale_factor) == 2
+
+ scale_factor = self.keypoints.new_tensor(scale_factor).reshape(1, 1, 2)
+ self.keypoints = self.keypoints * scale_factor
+
+ def clip_(self, img_shape: Tuple[int, int]) -> None:
+ """Clip bounding boxes and set invisible keypoints outside the image
+ boundary in-place.
+
+ Args:
+ img_shape (Tuple[int, int]): A tuple of image height and width.
+ """
+
+ kpt_outside = torch.logical_or(
+ torch.logical_or(self.keypoints[..., 0] < 0,
+ self.keypoints[..., 1] < 0),
+ torch.logical_or(self.keypoints[..., 0] > img_shape[1],
+ self.keypoints[..., 1] > img_shape[0]))
+ self.keypoints_visible[kpt_outside] *= 0
+
+ def project_(self, homography_matrix: Union[Tensor, np.ndarray]) -> None:
+ """Geometrically transform bounding boxes and keypoints in-place using
+ a homography matrix.
+
+ Args:
+ homography_matrix (Tensor or np.ndarray): A 3x3 tensor or ndarray
+ representing the homography matrix for the transformation.
+ """
+ keypoints = self.keypoints
+ if isinstance(homography_matrix, np.ndarray):
+ homography_matrix = keypoints.new_tensor(homography_matrix)
+
+ # Convert keypoints to homogeneous coordinates
+ keypoints = torch.cat([
+ self.keypoints,
+ self.keypoints.new_ones(*self.keypoints.shape[:-1], 1)
+ ],
+ dim=-1)
+
+ # Transpose keypoints for matrix multiplication
+ keypoints_T = torch.transpose(keypoints, -1, 0).contiguous().flatten(1)
+
+ # Apply homography matrix to corners and keypoints
+ keypoints_T = torch.matmul(homography_matrix, keypoints_T)
+
+ # Transpose back to original shape
+ keypoints_T = keypoints_T.reshape(3, self.keypoints.shape[1], -1)
+ keypoints = torch.transpose(keypoints_T, -1, 0).contiguous()
+
+ # Convert corners and keypoints back to non-homogeneous coordinates
+ keypoints = keypoints[..., :2] / keypoints[..., 2:3]
+
+ # Convert corners back to bounding boxes and update object attributes
+ self.keypoints = keypoints
+
+ @classmethod
+ def cat(cls: Type[T], kps_list: Sequence[T], dim: int = 0) -> T:
+ """Cancatenates an instance list into one single instance. Similar to
+ ``torch.cat``.
+
+ Args:
+ box_list (Sequence[T]): A sequence of instances.
+ dim (int): The dimension over which the box and keypoint are
+ concatenated. Defaults to 0.
+
+ Returns:
+ T: Concatenated instance.
+ """
+ assert isinstance(kps_list, Sequence)
+ if len(kps_list) == 0:
+ raise ValueError('kps_list should not be a empty list.')
+
+ assert dim == 0
+ assert all(isinstance(keypoints, cls) for keypoints in kps_list)
+
+ th_kpt_list = torch.cat(
+ [keypoints.keypoints for keypoints in kps_list], dim=dim)
+ th_kpt_vis_list = torch.cat(
+ [keypoints.keypoints_visible for keypoints in kps_list], dim=dim)
+ flip_indices = kps_list[0].flip_indices
+ return cls(
+ th_kpt_list,
+ th_kpt_vis_list,
+ clone=False,
+ flip_indices=flip_indices)
+
+ def __getitem__(self: T, index: IndexType) -> T:
+ """Rewrite getitem to protect the last dimension shape."""
+ if isinstance(index, np.ndarray):
+ index = torch.as_tensor(index, device=self.device)
+ if isinstance(index, Tensor) and index.dtype == torch.bool:
+ assert index.dim() < self.keypoints.dim() - 1
+ elif isinstance(index, tuple):
+ assert len(index) < self.keypoints.dim() - 1
+ # `Ellipsis`(...) is commonly used in index like [None, ...].
+ # When `Ellipsis` is in index, it must be the last item.
+ if Ellipsis in index:
+ assert index[-1] is Ellipsis
+
+ keypoints = self.keypoints[index]
+ keypoints_visible = self.keypoints_visible[index]
+ if self.keypoints.dim() == 2:
+ keypoints = keypoints.reshape(1, -1, 2)
+ keypoints_visible = keypoints_visible.reshape(1, -1)
+ return type(self)(
+ keypoints,
+ keypoints_visible,
+ flip_indices=self.flip_indices,
+ clone=False)
+
+ def __repr__(self) -> str:
+ """Return a strings that describes the object."""
+ return self.__class__.__name__ + '(\n' + str(self.keypoints) + ')'
+
+ @property
+ def num_keypoints(self) -> Tensor:
+ """Compute the number of visible keypoints for each object."""
+ return self.keypoints_visible.sum(dim=1).int()
+
+ def __deepcopy__(self, memo):
+ """Only clone the tensors when applying deepcopy."""
+ cls = self.__class__
+ other = cls.__new__(cls)
+ memo[id(self)] = other
+ other.keypoints = self.keypoints.clone()
+ other.keypoints_visible = self.keypoints_visible.clone()
+ other.flip_indices = deepcopy(self.flip_indices)
+ return other
+
+ def clone(self: T) -> T:
+ """Reload ``clone`` for tensors."""
+ return type(self)(
+ self.keypoints,
+ self.keypoints_visible,
+ flip_indices=self.flip_indices,
+ clone=True)
+
+ def to(self: T, *args, **kwargs) -> T:
+ """Reload ``to`` for tensors."""
+ return type(self)(
+ self.keypoints.to(*args, **kwargs),
+ self.keypoints_visible.to(*args, **kwargs),
+ flip_indices=self.flip_indices,
+ clone=False)
+
+ @property
+ def device(self) -> torch.device:
+ """Reload ``device`` from self.tensor."""
+ return self.keypoints.device
diff --git a/mmyolo/datasets/transforms/mix_img_transforms.py b/mmyolo/datasets/transforms/mix_img_transforms.py
index 4a25f6f7e..29e4a4057 100644
--- a/mmyolo/datasets/transforms/mix_img_transforms.py
+++ b/mmyolo/datasets/transforms/mix_img_transforms.py
@@ -318,7 +318,9 @@ def mix_img_transform(self, results: dict) -> dict:
mosaic_bboxes_labels = []
mosaic_ignore_flags = []
mosaic_masks = []
+ mosaic_kps = []
with_mask = True if 'gt_masks' in results else False
+ with_kps = True if 'gt_keypoints' in results else False
# self.img_scale is wh format
img_scale_w, img_scale_h = self.img_scale
@@ -374,7 +376,7 @@ def mix_img_transform(self, results: dict) -> dict:
mosaic_ignore_flags.append(gt_ignore_flags_i)
if with_mask and results_patch.get('gt_masks', None) is not None:
gt_masks_i = results_patch['gt_masks']
- gt_masks_i = gt_masks_i.rescale(float(scale_ratio_i))
+ gt_masks_i = gt_masks_i.resize(img_i.shape[:2])
gt_masks_i = gt_masks_i.translate(
out_shape=(int(self.img_scale[0] * 2),
int(self.img_scale[1] * 2)),
@@ -386,6 +388,12 @@ def mix_img_transform(self, results: dict) -> dict:
offset=padh,
direction='vertical')
mosaic_masks.append(gt_masks_i)
+ if with_kps and results_patch.get('gt_keypoints',
+ None) is not None:
+ gt_kps_i = results_patch['gt_keypoints']
+ gt_kps_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_kps_i.translate_([padw, padh])
+ mosaic_kps.append(gt_kps_i)
mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
@@ -396,6 +404,10 @@ def mix_img_transform(self, results: dict) -> dict:
if with_mask:
mosaic_masks = mosaic_masks[0].cat(mosaic_masks)
results['gt_masks'] = mosaic_masks
+ if with_kps:
+ mosaic_kps = mosaic_kps[0].cat(mosaic_kps, 0)
+ mosaic_kps.clip_([2 * img_scale_h, 2 * img_scale_w])
+ results['gt_keypoints'] = mosaic_kps
else:
# remove outside bboxes
inside_inds = mosaic_bboxes.is_inside(
@@ -406,6 +418,10 @@ def mix_img_transform(self, results: dict) -> dict:
if with_mask:
mosaic_masks = mosaic_masks[0].cat(mosaic_masks)[inside_inds]
results['gt_masks'] = mosaic_masks
+ if with_kps:
+ mosaic_kps = mosaic_kps[0].cat(mosaic_kps, 0)
+ mosaic_kps = mosaic_kps[inside_inds]
+ results['gt_keypoints'] = mosaic_kps
results['img'] = mosaic_img
results['img_shape'] = mosaic_img.shape
@@ -1131,6 +1147,31 @@ def mix_img_transform(self, results: dict) -> dict:
mixup_gt_bboxes_labels = mixup_gt_bboxes_labels[inside_inds]
mixup_gt_ignore_flags = mixup_gt_ignore_flags[inside_inds]
+ if 'gt_keypoints' in results:
+ # adjust kps
+ retrieve_gt_keypoints = retrieve_results['gt_keypoints']
+ retrieve_gt_keypoints.rescale_([scale_ratio, scale_ratio])
+ if self.bbox_clip_border:
+ retrieve_gt_keypoints.clip_([origin_h, origin_w])
+
+ if is_filp:
+ retrieve_gt_keypoints.flip_([origin_h, origin_w],
+ direction='horizontal')
+
+ # filter
+ cp_retrieve_gt_keypoints = retrieve_gt_keypoints.clone()
+ cp_retrieve_gt_keypoints.translate_([-x_offset, -y_offset])
+ if self.bbox_clip_border:
+ cp_retrieve_gt_keypoints.clip_([target_h, target_w])
+
+ # mixup
+ mixup_gt_keypoints = cp_retrieve_gt_keypoints.cat(
+ (results['gt_keypoints'], cp_retrieve_gt_keypoints), dim=0)
+ if not self.bbox_clip_border:
+ # remove outside bbox
+ mixup_gt_keypoints = mixup_gt_keypoints[inside_inds]
+ results['gt_keypoints'] = mixup_gt_keypoints
+
results['img'] = mixup_img.astype(np.uint8)
results['img_shape'] = mixup_img.shape
results['gt_bboxes'] = mixup_gt_bboxes
diff --git a/mmyolo/datasets/transforms/transforms.py b/mmyolo/datasets/transforms/transforms.py
index d5179fba3..8060e9c72 100644
--- a/mmyolo/datasets/transforms/transforms.py
+++ b/mmyolo/datasets/transforms/transforms.py
@@ -7,16 +7,21 @@
import mmcv
import numpy as np
import torch
+from mmcv.image.geometric import _scale_size
from mmcv.transforms import BaseTransform, Compose
from mmcv.transforms.utils import cache_randomness
+from mmdet.datasets.transforms import FilterAnnotations as FilterDetAnnotations
from mmdet.datasets.transforms import LoadAnnotations as MMDET_LoadAnnotations
+from mmdet.datasets.transforms import RandomAffine as MMDET_RandomAffine
+from mmdet.datasets.transforms import RandomFlip as MMDET_RandomFlip
from mmdet.datasets.transforms import Resize as MMDET_Resize
from mmdet.structures.bbox import (HorizontalBoxes, autocast_box_type,
get_box_type)
-from mmdet.structures.mask import PolygonMasks
+from mmdet.structures.mask import PolygonMasks, polygon_to_bitmap
from numpy import random
from mmyolo.registry import TRANSFORMS
+from .keypoint_structure import Keypoints
# TODO: Waiting for MMCV support
TRANSFORMS.register_module(module=Compose, force=True)
@@ -99,17 +104,21 @@ def _resize_img(self, results: dict):
self.scale)
if ratio != 1:
- # resize image according to the ratio
- image = mmcv.imrescale(
+ # resize image according to the shape
+ # NOTE: We are currently testing on COCO that modifying
+ # this code will not affect the results.
+ # If you find that it has an effect on your results,
+ # please feel free to contact us.
+ image = mmcv.imresize(
img=image,
- scale=ratio,
+ size=(int(original_w * ratio), int(original_h * ratio)),
interpolation='area' if ratio < 1 else 'bilinear',
backend=self.backend)
resized_h, resized_w = image.shape[:2]
- scale_ratio = resized_h / original_h
-
- scale_factor = (scale_ratio, scale_ratio)
+ scale_ratio_h = resized_h / original_h
+ scale_ratio_w = resized_w / original_w
+ scale_factor = (scale_ratio_w, scale_ratio_h)
results['img'] = image
results['img_shape'] = image.shape[:2]
@@ -142,6 +151,11 @@ class LetterResize(MMDET_Resize):
stretch_only (bool): Whether stretch to the specified size directly.
Defaults to False
allow_scale_up (bool): Allow scale up when ratio > 1. Defaults to True
+ half_pad_param (bool): If set to True, left and right pad_param will
+ be given by dividing padding_h by 2. If set to False, pad_param is
+ in int format. We recommend setting this to False for object
+ detection tasks, and True for instance segmentation tasks.
+ Default to False.
"""
def __init__(self,
@@ -150,6 +164,7 @@ def __init__(self,
use_mini_pad: bool = False,
stretch_only: bool = False,
allow_scale_up: bool = True,
+ half_pad_param: bool = False,
**kwargs):
super().__init__(scale=scale, keep_ratio=True, **kwargs)
@@ -162,6 +177,7 @@ def __init__(self,
self.use_mini_pad = use_mini_pad
self.stretch_only = stretch_only
self.allow_scale_up = allow_scale_up
+ self.half_pad_param = half_pad_param
def _resize_img(self, results: dict):
"""Resize images with ``results['scale']``."""
@@ -212,7 +228,8 @@ def _resize_img(self, results: dict):
interpolation=self.interpolation,
backend=self.backend)
- scale_factor = (ratio[1], ratio[0]) # mmcv scale factor is (w, h)
+ scale_factor = (no_pad_shape[1] / image_shape[1],
+ no_pad_shape[0] / image_shape[0])
if 'scale_factor' in results:
results['scale_factor_origin'] = results['scale_factor']
@@ -246,7 +263,15 @@ def _resize_img(self, results: dict):
if 'pad_param' in results:
results['pad_param_origin'] = results['pad_param'] * \
np.repeat(ratio, 2)
- results['pad_param'] = np.array(padding_list, dtype=np.float32)
+
+ if self.half_pad_param:
+ results['pad_param'] = np.array(
+ [padding_h / 2, padding_h / 2, padding_w / 2, padding_w / 2],
+ dtype=np.float32)
+ else:
+ # We found in object detection, using padding list with
+ # int type can get higher mAP.
+ results['pad_param'] = np.array(padding_list, dtype=np.float32)
def _resize_masks(self, results: dict):
"""Resize masks with ``results['scale']``"""
@@ -370,13 +395,26 @@ def __repr__(self) -> str:
class LoadAnnotations(MMDET_LoadAnnotations):
"""Because the yolo series does not need to consider ignore bboxes for the
time being, in order to speed up the pipeline, it can be excluded in
- advance."""
+ advance.
+
+ Args:
+ mask2bbox (bool): Whether to use mask annotation to get bbox.
+ Defaults to False.
+ poly2mask (bool): Whether to transform the polygons to bitmaps.
+ Defaults to False.
+ merge_polygons (bool): Whether to merge polygons into one polygon.
+ If merged, the storage structure is simpler and training is more
+ effcient, especially if the mask inside a bbox is divided into
+ multiple polygons. Defaults to True.
+ """
def __init__(self,
mask2bbox: bool = False,
poly2mask: bool = False,
- **kwargs) -> None:
+ merge_polygons: bool = True,
+ **kwargs):
self.mask2bbox = mask2bbox
+ self.merge_polygons = merge_polygons
assert not poly2mask, 'Does not support BitmapMasks considering ' \
'that bitmap consumes more memory.'
super().__init__(poly2mask=poly2mask, **kwargs)
@@ -402,6 +440,11 @@ def transform(self, results: dict) -> dict:
self._update_mask_ignore_data(results)
gt_bboxes = results['gt_masks'].get_bboxes(dst_type='hbox')
results['gt_bboxes'] = gt_bboxes
+ elif self.with_keypoints:
+ self._load_kps(results)
+ _, box_type_cls = get_box_type(self.box_type)
+ results['gt_bboxes'] = box_type_cls(
+ results.get('bbox', []), dtype=torch.float32)
else:
results = super().transform(results)
self._update_mask_ignore_data(results)
@@ -485,6 +528,8 @@ def _load_masks(self, results: dict) -> None:
# ignore
self._mask_ignore_flag.append(0)
else:
+ if len(gt_mask) > 1 and self.merge_polygons:
+ gt_mask = self.merge_multi_segment(gt_mask)
gt_masks.append(gt_mask)
gt_ignore_flags.append(instance['ignore_flag'])
self._mask_ignore_flag.append(1)
@@ -503,6 +548,109 @@ def _load_masks(self, results: dict) -> None:
gt_masks = PolygonMasks([mask for mask in gt_masks], h, w)
results['gt_masks'] = gt_masks
+ def merge_multi_segment(self,
+ gt_masks: List[np.ndarray]) -> List[np.ndarray]:
+ """Merge multi segments to one list.
+
+ Find the coordinates with min distance between each segment,
+ then connect these coordinates with one thin line to merge all
+ segments into one.
+ Args:
+ gt_masks(List(np.array)):
+ original segmentations in coco's json file.
+ like [segmentation1, segmentation2,...],
+ each segmentation is a list of coordinates.
+ Return:
+ gt_masks(List(np.array)): merged gt_masks
+ """
+ s = []
+ segments = [np.array(i).reshape(-1, 2) for i in gt_masks]
+ idx_list = [[] for _ in range(len(gt_masks))]
+
+ # record the indexes with min distance between each segment
+ for i in range(1, len(segments)):
+ idx1, idx2 = self.min_index(segments[i - 1], segments[i])
+ idx_list[i - 1].append(idx1)
+ idx_list[i].append(idx2)
+
+ # use two round to connect all the segments
+ # first round: first to end, i.e. A->B(partial)->C
+ # second round: end to first, i.e. C->B(remaining)-A
+ for k in range(2):
+ # forward first round
+ if k == 0:
+ for i, idx in enumerate(idx_list):
+ # middle segments have two indexes
+ # reverse the index of middle segments
+ if len(idx) == 2 and idx[0] > idx[1]:
+ idx = idx[::-1]
+ segments[i] = segments[i][::-1, :]
+ # add the idx[0] point for connect next segment
+ segments[i] = np.roll(segments[i], -idx[0], axis=0)
+ segments[i] = np.concatenate(
+ [segments[i], segments[i][:1]])
+ # deal with the first segment and the last one
+ if i in [0, len(idx_list) - 1]:
+ s.append(segments[i])
+ # deal with the middle segment
+ # Note that in the first round, only partial segment
+ # are appended.
+ else:
+ idx = [0, idx[1] - idx[0]]
+ s.append(segments[i][idx[0]:idx[1] + 1])
+ # forward second round
+ else:
+ for i in range(len(idx_list) - 1, -1, -1):
+ # deal with the middle segment
+ # append the remaining points
+ if i not in [0, len(idx_list) - 1]:
+ idx = idx_list[i]
+ nidx = abs(idx[1] - idx[0])
+ s.append(segments[i][nidx:])
+ return [np.concatenate(s).reshape(-1, )]
+
+ def min_index(self, arr1: np.ndarray, arr2: np.ndarray) -> Tuple[int, int]:
+ """Find a pair of indexes with the shortest distance.
+
+ Args:
+ arr1: (N, 2).
+ arr2: (M, 2).
+ Return:
+ tuple: a pair of indexes.
+ """
+ dis = ((arr1[:, None, :] - arr2[None, :, :])**2).sum(-1)
+ return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
+
+ def _load_kps(self, results: dict) -> None:
+ """Private function to load keypoints annotations.
+
+ Args:
+ results (dict): Result dict from
+ :class:`mmengine.dataset.BaseDataset`.
+
+ Returns:
+ dict: The dict contains loaded keypoints annotations.
+ """
+ results['height'] = results['img_shape'][0]
+ results['width'] = results['img_shape'][1]
+ num_instances = len(results.get('bbox', []))
+
+ if num_instances == 0:
+ results['keypoints'] = np.empty(
+ (0, len(results['flip_indices']), 2), dtype=np.float32)
+ results['keypoints_visible'] = np.empty(
+ (0, len(results['flip_indices'])), dtype=np.int32)
+ results['category_id'] = []
+
+ results['gt_keypoints'] = Keypoints(
+ keypoints=results['keypoints'],
+ keypoints_visible=results['keypoints_visible'],
+ flip_indices=results['flip_indices'],
+ )
+
+ results['gt_ignore_flags'] = np.array([False] * num_instances)
+ results['gt_bboxes_labels'] = np.array(results['category_id']) - 1
+
def __repr__(self) -> str:
repr_str = self.__class__.__name__
repr_str += f'(with_bbox={self.with_bbox}, '
@@ -512,7 +660,7 @@ def __repr__(self) -> str:
repr_str += f'mask2bbox={self.mask2bbox}, '
repr_str += f'poly2mask={self.poly2mask}, '
repr_str += f"imdecode_backend='{self.imdecode_backend}', "
- repr_str += f'file_client_args={self.file_client_args})'
+ repr_str += f'backend_args={self.backend_args})'
return repr_str
@@ -571,7 +719,7 @@ class YOLOv5RandomAffine(BaseTransform):
min_area_ratio (float): Threshold of area ratio between
original bboxes and wrapped bboxes. If smaller than this value,
the box will be removed. Defaults to 0.1.
- use_mask_refine (bool): Whether to refine bbox by mask.
+ use_mask_refine (bool): Whether to refine bbox by mask. Deprecated.
max_aspect_ratio (float): Aspect ratio of width and height
threshold to filter bboxes. If max(h/w, w/h) larger than this
value, the box will be removed. Defaults to 20.
@@ -603,6 +751,7 @@ def __init__(self,
self.bbox_clip_border = bbox_clip_border
self.min_bbox_size = min_bbox_size
self.min_area_ratio = min_area_ratio
+ # The use_mask_refine parameter has been deprecated.
self.use_mask_refine = use_mask_refine
self.max_aspect_ratio = max_aspect_ratio
self.resample_num = resample_num
@@ -644,7 +793,8 @@ def transform(self, results: dict) -> dict:
num_bboxes = len(bboxes)
if num_bboxes:
orig_bboxes = bboxes.clone()
- if self.use_mask_refine and 'gt_masks' in results:
+ orig_bboxes.rescale_([scaling_ratio, scaling_ratio])
+ if 'gt_masks' in results:
# If the dataset has annotations of mask,
# the mask will be used to refine bbox.
gt_masks = results['gt_masks']
@@ -654,10 +804,13 @@ def transform(self, results: dict) -> dict:
img_h, img_w)
# refine bboxes by masks
- bboxes = gt_masks.get_bboxes(dst_type='hbox')
+ bboxes = self.segment2box(gt_masks, height, width)
# filter bboxes outside image
valid_index = self.filter_gt_bboxes(orig_bboxes,
bboxes).numpy()
+ if self.bbox_clip_border:
+ bboxes.clip_([height - 1e-3, width - 1e-3])
+ gt_masks = self.clip_polygons(gt_masks, height, width)
results['gt_masks'] = gt_masks[valid_index]
else:
bboxes.project_(warp_matrix)
@@ -665,24 +818,88 @@ def transform(self, results: dict) -> dict:
bboxes.clip_([height, width])
# filter bboxes
- orig_bboxes.rescale_([scaling_ratio, scaling_ratio])
-
# Be careful: valid_index must convert to numpy,
# otherwise it will raise out of bounds when len(valid_index)=1
valid_index = self.filter_gt_bboxes(orig_bboxes,
bboxes).numpy()
- if 'gt_masks' in results:
- results['gt_masks'] = PolygonMasks(
- results['gt_masks'].masks, img_h, img_w)
results['gt_bboxes'] = bboxes[valid_index]
results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
valid_index]
results['gt_ignore_flags'] = results['gt_ignore_flags'][
valid_index]
+ else:
+ if 'gt_masks' in results:
+ results['gt_masks'] = PolygonMasks([], img_h, img_w)
return results
+ def segment2box(self, gt_masks: PolygonMasks, height: int,
+ width: int) -> HorizontalBoxes:
+ """
+ Convert 1 segment label to 1 box label, applying inside-image
+ constraint i.e. (xy1, xy2, ...) to (xyxy)
+ Args:
+ gt_masks (torch.Tensor): the segment label
+ width (int): the width of the image. Defaults to 640
+ height (int): The height of the image. Defaults to 640
+ Returns:
+ HorizontalBoxes: the clip bboxes from gt_masks.
+ """
+ bboxes = []
+ for _, poly_per_obj in enumerate(gt_masks):
+ # simply use a number that is big enough for comparison with
+ # coordinates
+ xy_min = np.array([width * 2, height * 2], dtype=np.float32)
+ xy_max = np.zeros(2, dtype=np.float32) - 1
+
+ for p in poly_per_obj:
+ xy = np.array(p).reshape(-1, 2).astype(np.float32)
+ x, y = xy.T
+ inside = (x >= 0) & (y >= 0) & (x <= width) & (y <= height)
+ x, y = x[inside], y[inside]
+ if not any(x):
+ continue
+ xy = np.stack([x, y], axis=0).T
+
+ xy_min = np.minimum(xy_min, np.min(xy, axis=0))
+ xy_max = np.maximum(xy_max, np.max(xy, axis=0))
+ if xy_max[0] == -1:
+ bbox = np.zeros(4, dtype=np.float32)
+ else:
+ bbox = np.concatenate([xy_min, xy_max], axis=0)
+ bboxes.append(bbox)
+
+ return HorizontalBoxes(np.stack(bboxes, axis=0))
+
+ # TODO: Move to mmdet
+ def clip_polygons(self, gt_masks: PolygonMasks, height: int,
+ width: int) -> PolygonMasks:
+ """Function to clip points of polygons with height and width.
+
+ Args:
+ gt_masks (PolygonMasks): Annotations of instance segmentation.
+ height (int): height of clip border.
+ width (int): width of clip border.
+ Return:
+ clipped_masks (PolygonMasks):
+ Clip annotations of instance segmentation.
+ """
+ if len(gt_masks) == 0:
+ clipped_masks = PolygonMasks([], height, width)
+ else:
+ clipped_masks = []
+ for poly_per_obj in gt_masks:
+ clipped_poly_per_obj = []
+ for p in poly_per_obj:
+ p = p.copy()
+ p[0::2] = p[0::2].clip(0, width)
+ p[1::2] = p[1::2].clip(0, height)
+ clipped_poly_per_obj.append(p)
+ clipped_masks.append(clipped_poly_per_obj)
+ clipped_masks = PolygonMasks(clipped_masks, height, width)
+ return clipped_masks
+
@staticmethod
def warp_poly(poly: np.ndarray, warp_matrix: np.ndarray, img_w: int,
img_h: int) -> np.ndarray:
@@ -707,10 +924,7 @@ def warp_poly(poly: np.ndarray, warp_matrix: np.ndarray, img_w: int,
poly = poly @ warp_matrix.T
poly = poly[:, :2] / poly[:, 2:3]
- # filter point outside image
- x, y = poly.T
- valid_ind_point = (x >= 0) & (y >= 0) & (x <= img_w) & (y <= img_h)
- return poly[valid_ind_point].reshape(-1)
+ return poly.reshape(-1)
def warp_mask(self, gt_masks: PolygonMasks, warp_matrix: np.ndarray,
img_w: int, img_h: int) -> PolygonMasks:
@@ -1284,8 +1498,8 @@ def _iou_matrix(self,
overlap = np.prod(
rightbottom - lefttop,
axis=2) * (lefttop < rightbottom).all(axis=2)
- area_gt_bbox = np.prod(gt_bbox[:, 2:] - crop_bbox[:, :2], axis=1)
- area_crop_bbox = np.prod(gt_bbox[:, 2:] - crop_bbox[:, :2], axis=1)
+ area_gt_bbox = np.prod(gt_bbox[:, 2:] - gt_bbox[:, :2], axis=1)
+ area_crop_bbox = np.prod(crop_bbox[:, 2:] - crop_bbox[:, :2], axis=1)
area_o = (area_gt_bbox[:, np.newaxis] + area_crop_bbox - overlap)
return overlap / (area_o + eps)
@@ -1374,7 +1588,7 @@ def transform(self, results: dict) -> Union[dict, None]:
if len(results.get('gt_masks', [])) == 0:
return results
gt_masks = results['gt_masks']
- assert isinstance(gt_masks, PolygonMasks),\
+ assert isinstance(gt_masks, PolygonMasks), \
'only support type of PolygonMasks,' \
' but get type: %s' % type(gt_masks)
gt_bboxes = results['gt_bboxes']
@@ -1555,3 +1769,334 @@ def transform(self, results: dict) -> dict:
results['gt_bboxes'] = self.box_type(
results['gt_bboxes'].regularize_boxes(self.angle_version))
return results
+
+
+@TRANSFORMS.register_module()
+class Polygon2Mask(BaseTransform):
+ """Polygons to bitmaps in YOLOv5.
+
+ Args:
+ downsample_ratio (int): Downsample ratio of mask.
+ mask_overlap (bool): Whether to use maskoverlap in mask process.
+ When set to True, the implementation here is the same as the
+ official, with higher training speed. If set to True, all gt masks
+ will compress into one overlap mask, the value of mask indicates
+ the index of gt masks. If set to False, one mask is a binary mask.
+ Default to True.
+ coco_style (bool): Whether to use coco_style to convert the polygons to
+ bitmaps. Note that this option is only used to test if there is an
+ improvement in training speed and we recommend setting it to False.
+ """
+
+ def __init__(self,
+ downsample_ratio: int = 4,
+ mask_overlap: bool = True,
+ coco_style: bool = False):
+ self.downsample_ratio = downsample_ratio
+ self.mask_overlap = mask_overlap
+ self.coco_style = coco_style
+
+ def polygon2mask(self,
+ img_shape: Tuple[int, int],
+ polygons: np.ndarray,
+ color: int = 1) -> np.ndarray:
+ """
+ Args:
+ img_shape (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ color (int): color in fillPoly.
+ Return:
+ np.ndarray: the overlap mask.
+ """
+ nh, nw = (img_shape[0] // self.downsample_ratio,
+ img_shape[1] // self.downsample_ratio)
+ if self.coco_style:
+ # This practice can lead to the loss of small objects
+ # polygons = polygons.resize((nh, nw)).masks
+ # polygons = np.asarray(polygons).reshape(-1)
+ # mask = polygon_to_bitmap([polygons], nh, nw)
+
+ polygons = np.asarray(polygons).reshape(-1)
+ mask = polygon_to_bitmap([polygons], img_shape[0],
+ img_shape[1]).astype(np.uint8)
+ mask = mmcv.imresize(mask, (nw, nh))
+ else:
+ mask = np.zeros(img_shape, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ # NOTE: fillPoly firstly then resize is trying the keep the same
+ # way of loss calculation when mask-ratio=1.
+ mask = mmcv.imresize(mask, (nw, nh))
+ return mask
+
+ def polygons2masks(self,
+ img_shape: Tuple[int, int],
+ polygons: PolygonMasks,
+ color: int = 1) -> np.ndarray:
+ """Return a list of bitmap masks.
+
+ Args:
+ img_shape (tuple): The image size.
+ polygons (PolygonMasks): The mask annotations.
+ color (int): color in fillPoly.
+ Return:
+ List[np.ndarray]: the list of masks in bitmaps.
+ """
+ if self.coco_style:
+ nh, nw = (img_shape[0] // self.downsample_ratio,
+ img_shape[1] // self.downsample_ratio)
+ masks = polygons.resize((nh, nw)).to_ndarray()
+ return masks
+ else:
+ masks = []
+ for si in range(len(polygons)):
+ mask = self.polygon2mask(img_shape, polygons[si], color)
+ masks.append(mask)
+ return np.array(masks)
+
+ def polygons2masks_overlap(
+ self, img_shape: Tuple[int, int],
+ polygons: PolygonMasks) -> Tuple[np.ndarray, np.ndarray]:
+ """Return a overlap mask and the sorted idx of area.
+
+ Args:
+ img_shape (tuple): The image size.
+ polygons (PolygonMasks): The mask annotations.
+ color (int): color in fillPoly.
+ Return:
+ Tuple[np.ndarray, np.ndarray]:
+ the overlap mask and the sorted idx of area.
+ """
+ masks = np.zeros((img_shape[0] // self.downsample_ratio,
+ img_shape[1] // self.downsample_ratio),
+ dtype=np.int32 if len(polygons) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(polygons)):
+ mask = self.polygon2mask(img_shape, polygons[si], color=1)
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(polygons)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
+
+ def transform(self, results: dict) -> dict:
+ gt_masks = results['gt_masks']
+ assert isinstance(gt_masks, PolygonMasks)
+
+ if self.mask_overlap:
+ masks, sorted_idx = self.polygons2masks_overlap(
+ (gt_masks.height, gt_masks.width), gt_masks)
+ results['gt_bboxes'] = results['gt_bboxes'][sorted_idx]
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ sorted_idx]
+
+ # In this case we put gt_masks in gt_panoptic_seg
+ results.pop('gt_masks')
+ results['gt_panoptic_seg'] = torch.from_numpy(masks[None])
+ else:
+ masks = self.polygons2masks((gt_masks.height, gt_masks.width),
+ gt_masks,
+ color=1)
+ masks = torch.from_numpy(masks)
+ # Consistent logic with mmdet
+ results['gt_masks'] = masks
+ return results
+
+
+@TRANSFORMS.register_module()
+class FilterAnnotations(FilterDetAnnotations):
+ """Filter invalid annotations.
+
+ In addition to the conditions checked by ``FilterDetAnnotations``, this
+ filter adds a new condition requiring instances to have at least one
+ visible keypoints.
+ """
+
+ def __init__(self, by_keypoints: bool = False, **kwargs) -> None:
+ # TODO: add more filter options
+ super().__init__(**kwargs)
+ self.by_keypoints = by_keypoints
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> Union[dict, None]:
+ """Transform function to filter annotations.
+
+ Args:
+ results (dict): Result dict.
+ Returns:
+ dict: Updated result dict.
+ """
+ assert 'gt_bboxes' in results
+ gt_bboxes = results['gt_bboxes']
+ if gt_bboxes.shape[0] == 0:
+ return results
+
+ tests = []
+ if self.by_box:
+ tests.append(
+ ((gt_bboxes.widths > self.min_gt_bbox_wh[0]) &
+ (gt_bboxes.heights > self.min_gt_bbox_wh[1])).numpy())
+
+ if self.by_mask:
+ assert 'gt_masks' in results
+ gt_masks = results['gt_masks']
+ tests.append(gt_masks.areas >= self.min_gt_mask_area)
+
+ if self.by_keypoints:
+ assert 'gt_keypoints' in results
+ num_keypoints = results['gt_keypoints'].num_keypoints
+ tests.append((num_keypoints > 0).numpy())
+
+ keep = tests[0]
+ for t in tests[1:]:
+ keep = keep & t
+
+ if not keep.any():
+ if self.keep_empty:
+ return None
+
+ keys = ('gt_bboxes', 'gt_bboxes_labels', 'gt_masks', 'gt_ignore_flags',
+ 'gt_keypoints')
+ for key in keys:
+ if key in results:
+ results[key] = results[key][keep]
+
+ return results
+
+
+# TODO: Check if it can be merged with mmdet.YOLOXHSVRandomAug
+@TRANSFORMS.register_module()
+class RandomAffine(MMDET_RandomAffine):
+
+ def __init__(self, **kwargs) -> None:
+ super().__init__(**kwargs)
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ height = img.shape[0] + self.border[1] * 2
+ width = img.shape[1] + self.border[0] * 2
+
+ warp_matrix = self._get_random_homography_matrix(height, width)
+
+ img = cv2.warpPerspective(
+ img,
+ warp_matrix,
+ dsize=(width, height),
+ borderValue=self.border_val)
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ bboxes = results['gt_bboxes']
+ num_bboxes = len(bboxes)
+ if num_bboxes:
+ bboxes.project_(warp_matrix)
+ if self.bbox_clip_border:
+ bboxes.clip_([height, width])
+ # remove outside bbox
+ valid_index = bboxes.is_inside([height, width]).numpy()
+ results['gt_bboxes'] = bboxes[valid_index]
+ results['gt_bboxes_labels'] = results['gt_bboxes_labels'][
+ valid_index]
+ results['gt_ignore_flags'] = results['gt_ignore_flags'][
+ valid_index]
+
+ if 'gt_masks' in results:
+ raise NotImplementedError('RandomAffine only supports bbox.')
+
+ if 'gt_keypoints' in results:
+ keypoints = results['gt_keypoints']
+ keypoints.project_(warp_matrix)
+ if self.bbox_clip_border:
+ keypoints.clip_([height, width])
+ results['gt_keypoints'] = keypoints[valid_index]
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(hue_delta={self.hue_delta}, '
+ repr_str += f'saturation_delta={self.saturation_delta}, '
+ repr_str += f'value_delta={self.value_delta})'
+ return repr_str
+
+
+# TODO: Check if it can be merged with mmdet.YOLOXHSVRandomAug
+@TRANSFORMS.register_module()
+class RandomFlip(MMDET_RandomFlip):
+
+ @autocast_box_type()
+ def _flip(self, results: dict) -> None:
+ """Flip images, bounding boxes, and semantic segmentation map."""
+ # flip image
+ results['img'] = mmcv.imflip(
+ results['img'], direction=results['flip_direction'])
+
+ img_shape = results['img'].shape[:2]
+
+ # flip bboxes
+ if results.get('gt_bboxes', None) is not None:
+ results['gt_bboxes'].flip_(img_shape, results['flip_direction'])
+
+ # flip keypoints
+ if results.get('gt_keypoints', None) is not None:
+ results['gt_keypoints'].flip_(img_shape, results['flip_direction'])
+
+ # flip masks
+ if results.get('gt_masks', None) is not None:
+ results['gt_masks'] = results['gt_masks'].flip(
+ results['flip_direction'])
+
+ # flip segs
+ if results.get('gt_seg_map', None) is not None:
+ results['gt_seg_map'] = mmcv.imflip(
+ results['gt_seg_map'], direction=results['flip_direction'])
+
+ # record homography matrix for flip
+ self._record_homography_matrix(results)
+
+
+@TRANSFORMS.register_module()
+class Resize(MMDET_Resize):
+
+ def _resize_keypoints(self, results: dict) -> None:
+ """Resize bounding boxes with ``results['scale_factor']``."""
+ if results.get('gt_keypoints', None) is not None:
+ results['gt_keypoints'].rescale_(results['scale_factor'])
+ if self.clip_object_border:
+ results['gt_keypoints'].clip_(results['img_shape'])
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Transform function to resize images, bounding boxes and semantic
+ segmentation map.
+
+ Args:
+ results (dict): Result dict from loading pipeline.
+ Returns:
+ dict: Resized results, 'img', 'gt_bboxes', 'gt_seg_map',
+ 'scale', 'scale_factor', 'height', 'width', and 'keep_ratio' keys
+ are updated in result dict.
+ """
+ if self.scale:
+ results['scale'] = self.scale
+ else:
+ img_shape = results['img'].shape[:2]
+ results['scale'] = _scale_size(img_shape[::-1], self.scale_factor)
+ self._resize_img(results)
+ self._resize_bboxes(results)
+ self._resize_keypoints(results)
+ self._resize_masks(results)
+ self._resize_seg(results)
+ self._record_homography_matrix(results)
+ return results
diff --git a/mmyolo/datasets/utils.py b/mmyolo/datasets/utils.py
index 62fe5484b..efa2ff5ef 100644
--- a/mmyolo/datasets/utils.py
+++ b/mmyolo/datasets/utils.py
@@ -4,6 +4,7 @@
import numpy as np
import torch
from mmengine.dataset import COLLATE_FUNCTIONS
+from mmengine.dist import get_dist_info
from ..registry import TASK_UTILS
@@ -20,6 +21,8 @@ def yolov5_collate(data_batch: Sequence,
batch_imgs = []
batch_bboxes_labels = []
batch_masks = []
+ batch_keyponits = []
+ batch_keypoints_visible = []
for i in range(len(data_batch)):
datasamples = data_batch[i]['data_samples']
inputs = data_batch[i]['inputs']
@@ -28,14 +31,20 @@ def yolov5_collate(data_batch: Sequence,
gt_bboxes = datasamples.gt_instances.bboxes.tensor
gt_labels = datasamples.gt_instances.labels
if 'masks' in datasamples.gt_instances:
- masks = datasamples.gt_instances.masks.to_tensor(
- dtype=torch.bool, device=gt_bboxes.device)
+ masks = datasamples.gt_instances.masks
batch_masks.append(masks)
+ if 'gt_panoptic_seg' in datasamples:
+ batch_masks.append(datasamples.gt_panoptic_seg.pan_seg)
+ if 'keypoints' in datasamples.gt_instances:
+ keypoints = datasamples.gt_instances.keypoints
+ keypoints_visible = datasamples.gt_instances.keypoints_visible
+ batch_keyponits.append(keypoints)
+ batch_keypoints_visible.append(keypoints_visible)
+
batch_idx = gt_labels.new_full((len(gt_labels), 1), i)
bboxes_labels = torch.cat((batch_idx, gt_labels[:, None], gt_bboxes),
dim=1)
batch_bboxes_labels.append(bboxes_labels)
-
collated_results = {
'data_samples': {
'bboxes_labels': torch.cat(batch_bboxes_labels, 0)
@@ -44,6 +53,12 @@ def yolov5_collate(data_batch: Sequence,
if len(batch_masks) > 0:
collated_results['data_samples']['masks'] = torch.cat(batch_masks, 0)
+ if len(batch_keyponits) > 0:
+ collated_results['data_samples']['keypoints'] = torch.cat(
+ batch_keyponits, 0)
+ collated_results['data_samples']['keypoints_visible'] = torch.cat(
+ batch_keypoints_visible, 0)
+
if use_ms_training:
collated_results['inputs'] = batch_imgs
else:
@@ -70,10 +85,14 @@ def __init__(self,
img_size: int = 640,
size_divisor: int = 32,
extra_pad_ratio: float = 0.5):
- self.batch_size = batch_size
self.img_size = img_size
self.size_divisor = size_divisor
self.extra_pad_ratio = extra_pad_ratio
+ _, world_size = get_dist_info()
+ # During multi-gpu testing, the batchsize should be multiplied by
+ # worldsize, so that the number of batches can be calculated correctly.
+ # The index of batches will affect the calculation of batch shape.
+ self.batch_size = batch_size * world_size
def __call__(self, data_list: List[dict]) -> List[dict]:
image_shapes = []
diff --git a/mmyolo/models/backbones/efficient_rep.py b/mmyolo/models/backbones/efficient_rep.py
index 691c5b846..32e455f06 100644
--- a/mmyolo/models/backbones/efficient_rep.py
+++ b/mmyolo/models/backbones/efficient_rep.py
@@ -6,7 +6,7 @@
import torch.nn as nn
from mmdet.utils import ConfigType, OptMultiConfig
-from mmyolo.models.layers.yolo_bricks import SPPFBottleneck
+from mmyolo.models.layers.yolo_bricks import CSPSPPFBottleneck, SPPFBottleneck
from mmyolo.registry import MODELS
from ..layers import BepC3StageBlock, RepStageBlock
from ..utils import make_round
@@ -72,6 +72,7 @@ def __init__(self,
input_channels: int = 3,
out_indices: Tuple[int] = (2, 3, 4),
frozen_stages: int = -1,
+ use_cspsppf: bool = False,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='ReLU', inplace=True),
@@ -79,6 +80,7 @@ def __init__(self,
block_cfg: ConfigType = dict(type='RepVGGBlock'),
init_cfg: OptMultiConfig = None):
self.block_cfg = block_cfg
+ self.use_cspsppf = use_cspsppf
super().__init__(
self.arch_settings[arch],
deepen_factor,
@@ -145,6 +147,13 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
kernel_sizes=5,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
+ if self.use_cspsppf:
+ spp = CSPSPPFBottleneck(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_sizes=5,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
stage.append(spp)
return stage
@@ -222,6 +231,7 @@ def __init__(self,
hidden_ratio: float = 0.5,
out_indices: Tuple[int] = (2, 3, 4),
frozen_stages: int = -1,
+ use_cspsppf: bool = False,
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
act_cfg: ConfigType = dict(type='SiLU', inplace=True),
@@ -229,6 +239,7 @@ def __init__(self,
block_cfg: ConfigType = dict(type='ConvWrapper'),
init_cfg: OptMultiConfig = None):
self.hidden_ratio = hidden_ratio
+ self.use_cspsppf = use_cspsppf
super().__init__(
arch=arch,
deepen_factor=deepen_factor,
@@ -283,5 +294,12 @@ def build_stage_layer(self, stage_idx: int, setting: list) -> list:
kernel_sizes=5,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
+ if self.use_cspsppf:
+ spp = CSPSPPFBottleneck(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_sizes=5,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
stage.append(spp)
return stage
diff --git a/mmyolo/models/data_preprocessors/data_preprocessor.py b/mmyolo/models/data_preprocessors/data_preprocessor.py
index f09fd8e74..a29b90844 100644
--- a/mmyolo/models/data_preprocessors/data_preprocessor.py
+++ b/mmyolo/models/data_preprocessors/data_preprocessor.py
@@ -49,6 +49,10 @@ def forward(self, inputs: Tensor, data_samples: dict) -> Tensor and dict:
data_samples['bboxes_labels'][:, 2::2] *= scale_x
data_samples['bboxes_labels'][:, 3::2] *= scale_y
+ if 'keypoints' in data_samples:
+ data_samples['keypoints'][..., 0] *= scale_x
+ data_samples['keypoints'][..., 1] *= scale_y
+
message_hub = MessageHub.get_current_instance()
if (message_hub.get_info('iter') + 1) % self._interval == 0:
self._input_size = self._get_random_size(
@@ -102,6 +106,10 @@ def forward(self, data: dict, training: bool = False) -> dict:
}
if 'masks' in data_samples:
data_samples_output['masks'] = data_samples['masks']
+ if 'keypoints' in data_samples:
+ data_samples_output['keypoints'] = data_samples['keypoints']
+ data_samples_output['keypoints_visible'] = data_samples[
+ 'keypoints_visible']
return {'inputs': inputs, 'data_samples': data_samples_output}
diff --git a/mmyolo/models/dense_heads/__init__.py b/mmyolo/models/dense_heads/__init__.py
index a95abd611..90587c3fb 100644
--- a/mmyolo/models/dense_heads/__init__.py
+++ b/mmyolo/models/dense_heads/__init__.py
@@ -5,10 +5,12 @@
from .rtmdet_rotated_head import (RTMDetRotatedHead,
RTMDetRotatedSepBNHeadModule)
from .yolov5_head import YOLOv5Head, YOLOv5HeadModule
+from .yolov5_ins_head import YOLOv5InsHead, YOLOv5InsHeadModule
from .yolov6_head import YOLOv6Head, YOLOv6HeadModule
from .yolov7_head import YOLOv7Head, YOLOv7HeadModule, YOLOv7p6HeadModule
from .yolov8_head import YOLOv8Head, YOLOv8HeadModule
from .yolox_head import YOLOXHead, YOLOXHeadModule
+from .yolox_pose_head import YOLOXPoseHead, YOLOXPoseHeadModule
__all__ = [
'YOLOv5Head', 'YOLOv6Head', 'YOLOXHead', 'YOLOv5HeadModule',
@@ -16,5 +18,6 @@
'RTMDetSepBNHeadModule', 'YOLOv7Head', 'PPYOLOEHead', 'PPYOLOEHeadModule',
'YOLOv7HeadModule', 'YOLOv7p6HeadModule', 'YOLOv8Head', 'YOLOv8HeadModule',
'RTMDetRotatedHead', 'RTMDetRotatedSepBNHeadModule', 'RTMDetInsSepBNHead',
- 'RTMDetInsSepBNHeadModule'
+ 'RTMDetInsSepBNHeadModule', 'YOLOv5InsHead', 'YOLOv5InsHeadModule',
+ 'YOLOXPoseHead', 'YOLOXPoseHeadModule'
]
diff --git a/mmyolo/models/dense_heads/ppyoloe_head.py b/mmyolo/models/dense_heads/ppyoloe_head.py
index 72d820041..f46898767 100644
--- a/mmyolo/models/dense_heads/ppyoloe_head.py
+++ b/mmyolo/models/dense_heads/ppyoloe_head.py
@@ -106,8 +106,7 @@ def _init_layers(self):
nn.Conv2d(in_channel, 4 * (self.reg_max + 1), 3, padding=1))
# init proj
- proj = torch.linspace(0, self.reg_max, self.reg_max + 1).view(
- [1, self.reg_max + 1, 1, 1])
+ proj = torch.arange(self.reg_max + 1, dtype=torch.float)
self.register_buffer('proj', proj, persistent=False)
def forward(self, x: Tuple[Tensor]) -> Tensor:
@@ -130,16 +129,17 @@ def forward_single(self, x: Tensor, cls_stem: nn.ModuleList,
reg_pred: nn.ModuleList) -> Tensor:
"""Forward feature of a single scale level."""
b, _, h, w = x.shape
- hw = h * w
avg_feat = F.adaptive_avg_pool2d(x, (1, 1))
cls_logit = cls_pred(cls_stem(x, avg_feat) + x)
bbox_dist_preds = reg_pred(reg_stem(x, avg_feat))
- # TODO: Test whether use matmul instead of conv can speed up training.
- bbox_dist_preds = bbox_dist_preds.reshape(
- [-1, 4, self.reg_max + 1, hw]).permute(0, 2, 3, 1)
-
- bbox_preds = F.conv2d(F.softmax(bbox_dist_preds, dim=1), self.proj)
-
+ if self.reg_max > 1:
+ bbox_dist_preds = bbox_dist_preds.reshape(
+ [-1, 4, self.reg_max + 1, h * w]).permute(0, 3, 1, 2)
+ bbox_preds = bbox_dist_preds.softmax(3).matmul(
+ self.proj.view([-1, 1])).squeeze(-1)
+ bbox_preds = bbox_preds.transpose(1, 2).reshape(b, -1, h, w)
+ else:
+ bbox_preds = bbox_dist_preds
if self.training:
return cls_logit, bbox_preds, bbox_dist_preds
else:
diff --git a/mmyolo/models/dense_heads/yolov5_head.py b/mmyolo/models/dense_heads/yolov5_head.py
index c49d08518..fb24617fc 100644
--- a/mmyolo/models/dense_heads/yolov5_head.py
+++ b/mmyolo/models/dense_heads/yolov5_head.py
@@ -95,7 +95,12 @@ def init_weights(self):
b = mi.bias.data.view(self.num_base_priors, -1)
# obj (8 objects per 640 image)
b.data[:, 4] += math.log(8 / (640 / s)**2)
- b.data[:, 5:] += math.log(0.6 / (self.num_classes - 0.999999))
+ # NOTE: The following initialization can only be performed on the
+ # bias of the category, if the following initialization is
+ # performed on the bias of mask coefficient,
+ # there will be a significant decrease in mask AP.
+ b.data[:, 5:5 + self.num_classes] += math.log(
+ 0.6 / (self.num_classes - 0.999999))
mi.bias.data = b.view(-1)
diff --git a/mmyolo/models/dense_heads/yolov5_ins_head.py b/mmyolo/models/dense_heads/yolov5_ins_head.py
new file mode 100644
index 000000000..df94f422e
--- /dev/null
+++ b/mmyolo/models/dense_heads/yolov5_ins_head.py
@@ -0,0 +1,740 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Sequence, Tuple, Union
+
+import mmcv
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmdet.models.utils import filter_scores_and_topk, multi_apply
+from mmdet.structures.bbox import bbox_cxcywh_to_xyxy
+from mmdet.utils import ConfigType, OptInstanceList
+from mmengine.config import ConfigDict
+from mmengine.dist import get_dist_info
+from mmengine.model import BaseModule
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.registry import MODELS
+from ..utils import make_divisible
+from .yolov5_head import YOLOv5Head, YOLOv5HeadModule
+
+
+class ProtoModule(BaseModule):
+ """Mask Proto module for segmentation models of YOLOv5.
+
+ Args:
+ in_channels (int): Number of channels in the input feature map.
+ middle_channels (int): Number of channels in the middle feature map.
+ mask_channels (int): Number of channels in the output mask feature
+ map. This is the channel count of the mask.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to ``dict(type='BN', momentum=0.03, eps=0.001)``.
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Default: dict(type='SiLU', inplace=True).
+ """
+
+ def __init__(self,
+ *args,
+ in_channels: int = 32,
+ middle_channels: int = 256,
+ mask_channels: int = 32,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self.conv1 = ConvModule(
+ in_channels,
+ middle_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
+ self.conv2 = ConvModule(
+ middle_channels,
+ middle_channels,
+ kernel_size=3,
+ padding=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv3 = ConvModule(
+ middle_channels,
+ mask_channels,
+ kernel_size=1,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ return self.conv3(self.conv2(self.upsample(self.conv1(x))))
+
+
+@MODELS.register_module()
+class YOLOv5InsHeadModule(YOLOv5HeadModule):
+ """Detection and Instance Segmentation Head of YOLOv5.
+
+ Args:
+ num_classes (int): Number of categories excluding the background
+ category.
+ mask_channels (int): Number of channels in the mask feature map.
+ This is the channel count of the mask.
+ proto_channels (int): Number of channels in the proto feature map.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ norm_cfg (:obj:`ConfigDict` or dict): Config dict for normalization
+ layer. Defaults to ``dict(type='BN', momentum=0.03, eps=0.001)``.
+ act_cfg (:obj:`ConfigDict` or dict): Config dict for activation layer.
+ Default: dict(type='SiLU', inplace=True).
+ """
+
+ def __init__(self,
+ *args,
+ num_classes: int,
+ mask_channels: int = 32,
+ proto_channels: int = 256,
+ widen_factor: float = 1.0,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ **kwargs):
+ self.mask_channels = mask_channels
+ self.num_out_attrib_with_proto = 5 + num_classes + mask_channels
+ self.proto_channels = make_divisible(proto_channels, widen_factor)
+ self.norm_cfg = norm_cfg
+ self.act_cfg = act_cfg
+ super().__init__(
+ *args,
+ num_classes=num_classes,
+ widen_factor=widen_factor,
+ **kwargs)
+
+ def _init_layers(self):
+ """initialize conv layers in YOLOv5 Ins head."""
+ self.convs_pred = nn.ModuleList()
+ for i in range(self.num_levels):
+ conv_pred = nn.Conv2d(
+ self.in_channels[i],
+ self.num_base_priors * self.num_out_attrib_with_proto, 1)
+ self.convs_pred.append(conv_pred)
+
+ self.proto_pred = ProtoModule(
+ in_channels=self.in_channels[0],
+ middle_channels=self.proto_channels,
+ mask_channels=self.mask_channels,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List]:
+ """Forward features from the upstream network.
+
+ Args:
+ x (Tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ Returns:
+ Tuple[List]: A tuple of multi-level classification scores, bbox
+ predictions, objectnesses, and mask predictions.
+ """
+ assert len(x) == self.num_levels
+ cls_scores, bbox_preds, objectnesses, coeff_preds = multi_apply(
+ self.forward_single, x, self.convs_pred)
+ mask_protos = self.proto_pred(x[0])
+ return cls_scores, bbox_preds, objectnesses, coeff_preds, mask_protos
+
+ def forward_single(
+ self, x: Tensor,
+ convs_pred: nn.Module) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
+ """Forward feature of a single scale level."""
+
+ pred_map = convs_pred(x)
+ bs, _, ny, nx = pred_map.shape
+ pred_map = pred_map.view(bs, self.num_base_priors,
+ self.num_out_attrib_with_proto, ny, nx)
+
+ cls_score = pred_map[:, :, 5:self.num_classes + 5,
+ ...].reshape(bs, -1, ny, nx)
+ bbox_pred = pred_map[:, :, :4, ...].reshape(bs, -1, ny, nx)
+ objectness = pred_map[:, :, 4:5, ...].reshape(bs, -1, ny, nx)
+ coeff_pred = pred_map[:, :, self.num_classes + 5:,
+ ...].reshape(bs, -1, ny, nx)
+
+ return cls_score, bbox_pred, objectness, coeff_pred
+
+
+@MODELS.register_module()
+class YOLOv5InsHead(YOLOv5Head):
+ """YOLOv5 Instance Segmentation and Detection head.
+
+ Args:
+ mask_overlap(bool): Defaults to True.
+ loss_mask (:obj:`ConfigDict` or dict): Config of mask loss.
+ loss_mask_weight (float): The weight of mask loss.
+ """
+
+ def __init__(self,
+ *args,
+ mask_overlap: bool = True,
+ loss_mask: ConfigType = dict(
+ type='mmdet.CrossEntropyLoss',
+ use_sigmoid=True,
+ reduction='none'),
+ loss_mask_weight=0.05,
+ **kwargs):
+ super().__init__(*args, **kwargs)
+ self.mask_overlap = mask_overlap
+ self.loss_mask: nn.Module = MODELS.build(loss_mask)
+ self.loss_mask_weight = loss_mask_weight
+
+ def loss(self, x: Tuple[Tensor], batch_data_samples: Union[list,
+ dict]) -> dict:
+ """Perform forward propagation and loss calculation of the detection
+ head on the features of the upstream network.
+
+ Args:
+ x (tuple[Tensor]): Features from the upstream network, each is
+ a 4D-tensor.
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+
+ Returns:
+ dict: A dictionary of loss components.
+ """
+
+ if isinstance(batch_data_samples, list):
+ # TODO: support non-fast version ins segmention
+ raise NotImplementedError
+ else:
+ outs = self(x)
+ # Fast version
+ loss_inputs = outs + (batch_data_samples['bboxes_labels'],
+ batch_data_samples['masks'],
+ batch_data_samples['img_metas'])
+ losses = self.loss_by_feat(*loss_inputs)
+
+ return losses
+
+ def loss_by_feat(
+ self,
+ cls_scores: Sequence[Tensor],
+ bbox_preds: Sequence[Tensor],
+ objectnesses: Sequence[Tensor],
+ coeff_preds: Sequence[Tensor],
+ proto_preds: Tensor,
+ batch_gt_instances: Sequence[InstanceData],
+ batch_gt_masks: Sequence[Tensor],
+ batch_img_metas: Sequence[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
+ coeff_preds (Sequence[Tensor]): Mask coefficient for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * mask_channels.
+ proto_preds (Tensor): Mask prototype features extracted from the
+ mask head, has shape (batch_size, mask_channels, H, W).
+ batch_gt_instances (Sequence[InstanceData]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_gt_masks (Sequence[Tensor]): Batch of gt_mask.
+ batch_img_metas (Sequence[dict]): Meta information of each image,
+ e.g., image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ dict[str, Tensor]: A dictionary of losses.
+ """
+ # 1. Convert gt to norm format
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ device = cls_scores[0].device
+ loss_cls = torch.zeros(1, device=device)
+ loss_box = torch.zeros(1, device=device)
+ loss_obj = torch.zeros(1, device=device)
+ loss_mask = torch.zeros(1, device=device)
+ scaled_factor = torch.ones(8, device=device)
+
+ for i in range(self.num_levels):
+ batch_size, _, h, w = bbox_preds[i].shape
+ target_obj = torch.zeros_like(objectnesses[i])
+
+ # empty gt bboxes
+ if batch_targets_normed.shape[1] == 0:
+ loss_box += bbox_preds[i].sum() * 0
+ loss_cls += cls_scores[i].sum() * 0
+ loss_obj += self.loss_obj(
+ objectnesses[i], target_obj) * self.obj_level_weights[i]
+ loss_mask += coeff_preds[i].sum() * 0
+ continue
+
+ priors_base_sizes_i = self.priors_base_sizes[i]
+ # feature map scale whwh
+ scaled_factor[2:6] = torch.tensor(
+ bbox_preds[i].shape)[[3, 2, 3, 2]]
+ # Scale batch_targets from range 0-1 to range 0-features_maps size.
+ # (num_base_priors, num_bboxes, 8)
+ batch_targets_scaled = batch_targets_normed * scaled_factor
+
+ # 2. Shape match
+ wh_ratio = batch_targets_scaled[...,
+ 4:6] / priors_base_sizes_i[:, None]
+ match_inds = torch.max(
+ wh_ratio, 1 / wh_ratio).max(2)[0] < self.prior_match_thr
+ batch_targets_scaled = batch_targets_scaled[match_inds]
+
+ # no gt bbox matches anchor
+ if batch_targets_scaled.shape[0] == 0:
+ loss_box += bbox_preds[i].sum() * 0
+ loss_cls += cls_scores[i].sum() * 0
+ loss_obj += self.loss_obj(
+ objectnesses[i], target_obj) * self.obj_level_weights[i]
+ loss_mask += coeff_preds[i].sum() * 0
+ continue
+
+ # 3. Positive samples with additional neighbors
+
+ # check the left, up, right, bottom sides of the
+ # targets grid, and determine whether assigned
+ # them as positive samples as well.
+ batch_targets_cxcy = batch_targets_scaled[:, 2:4]
+ grid_xy = scaled_factor[[2, 3]] - batch_targets_cxcy
+ left, up = ((batch_targets_cxcy % 1 < self.near_neighbor_thr) &
+ (batch_targets_cxcy > 1)).T
+ right, bottom = ((grid_xy % 1 < self.near_neighbor_thr) &
+ (grid_xy > 1)).T
+ offset_inds = torch.stack(
+ (torch.ones_like(left), left, up, right, bottom))
+
+ batch_targets_scaled = batch_targets_scaled.repeat(
+ (5, 1, 1))[offset_inds]
+ retained_offsets = self.grid_offset.repeat(1, offset_inds.shape[1],
+ 1)[offset_inds]
+
+ # prepare pred results and positive sample indexes to
+ # calculate class loss and bbox lo
+ _chunk_targets = batch_targets_scaled.chunk(4, 1)
+ img_class_inds, grid_xy, grid_wh,\
+ priors_targets_inds = _chunk_targets
+ (priors_inds, targets_inds) = priors_targets_inds.long().T
+ (img_inds, class_inds) = img_class_inds.long().T
+
+ grid_xy_long = (grid_xy -
+ retained_offsets * self.near_neighbor_thr).long()
+ grid_x_inds, grid_y_inds = grid_xy_long.T
+ bboxes_targets = torch.cat((grid_xy - grid_xy_long, grid_wh), 1)
+
+ # 4. Calculate loss
+ # bbox loss
+ retained_bbox_pred = bbox_preds[i].reshape(
+ batch_size, self.num_base_priors, -1, h,
+ w)[img_inds, priors_inds, :, grid_y_inds, grid_x_inds]
+ priors_base_sizes_i = priors_base_sizes_i[priors_inds]
+ decoded_bbox_pred = self._decode_bbox_to_xywh(
+ retained_bbox_pred, priors_base_sizes_i)
+ loss_box_i, iou = self.loss_bbox(decoded_bbox_pred, bboxes_targets)
+ loss_box += loss_box_i
+
+ # obj loss
+ iou = iou.detach().clamp(0)
+ target_obj[img_inds, priors_inds, grid_y_inds,
+ grid_x_inds] = iou.type(target_obj.dtype)
+ loss_obj += self.loss_obj(objectnesses[i],
+ target_obj) * self.obj_level_weights[i]
+
+ # cls loss
+ if self.num_classes > 1:
+ pred_cls_scores = cls_scores[i].reshape(
+ batch_size, self.num_base_priors, -1, h,
+ w)[img_inds, priors_inds, :, grid_y_inds, grid_x_inds]
+
+ target_class = torch.full_like(pred_cls_scores, 0.)
+ target_class[range(batch_targets_scaled.shape[0]),
+ class_inds] = 1.
+ loss_cls += self.loss_cls(pred_cls_scores, target_class)
+ else:
+ loss_cls += cls_scores[i].sum() * 0
+
+ # mask regression
+ retained_coeff_preds = coeff_preds[i].reshape(
+ batch_size, self.num_base_priors, -1, h,
+ w)[img_inds, priors_inds, :, grid_y_inds, grid_x_inds]
+
+ _, c, mask_h, mask_w = proto_preds.shape
+ if batch_gt_masks.shape[-2:] != (mask_h, mask_w):
+ batch_gt_masks = F.interpolate(
+ batch_gt_masks[None], (mask_h, mask_w), mode='nearest')[0]
+
+ xywh_normed = batch_targets_scaled[:, 2:6] / scaled_factor[2:6]
+ area_normed = xywh_normed[:, 2:].prod(1)
+ xywh_scaled = xywh_normed * torch.tensor(
+ proto_preds.shape, device=device)[[3, 2, 3, 2]]
+ xyxy_scaled = bbox_cxcywh_to_xyxy(xywh_scaled)
+
+ for bs in range(batch_size):
+ match_inds = (img_inds == bs) # matching index
+ if not match_inds.any():
+ continue
+
+ if self.mask_overlap:
+ mask_gti = torch.where(
+ batch_gt_masks[bs][None] ==
+ targets_inds[match_inds].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = batch_gt_masks[targets_inds][match_inds]
+
+ mask_preds = (retained_coeff_preds[match_inds]
+ @ proto_preds[bs].view(c, -1)).view(
+ -1, mask_h, mask_w)
+ loss_mask_full = self.loss_mask(mask_preds, mask_gti)
+ loss_mask += (
+ self.crop_mask(loss_mask_full[None],
+ xyxy_scaled[match_inds]).mean(dim=(2, 3)) /
+ area_normed[match_inds]).mean()
+
+ _, world_size = get_dist_info()
+ return dict(
+ loss_cls=loss_cls * batch_size * world_size,
+ loss_obj=loss_obj * batch_size * world_size,
+ loss_bbox=loss_box * batch_size * world_size,
+ loss_mask=loss_mask * self.loss_mask_weight * world_size)
+
+ def _convert_gt_to_norm_format(self,
+ batch_gt_instances: Sequence[InstanceData],
+ batch_img_metas: Sequence[dict]) -> Tensor:
+ """Add target_inds for instance segmentation."""
+ batch_targets_normed = super()._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ if self.mask_overlap:
+ batch_size = len(batch_img_metas)
+ target_inds = []
+ for i in range(batch_size):
+ # find number of targets of each image
+ num_gts = (batch_gt_instances[:, 0] == i).sum()
+ # (num_anchor, num_gts)
+ target_inds.append(
+ torch.arange(num_gts, device=batch_gt_instances.device).
+ float().view(1, num_gts).repeat(self.num_base_priors, 1) +
+ 1)
+ target_inds = torch.cat(target_inds, 1)
+ else:
+ num_gts = batch_gt_instances.shape[0]
+ target_inds = torch.arange(
+ num_gts, device=batch_gt_instances.device).float().view(
+ 1, num_gts).repeat(self.num_base_priors, 1)
+ batch_targets_normed = torch.cat(
+ [batch_targets_normed, target_inds[..., None]], 2)
+ return batch_targets_normed
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: Optional[List[Tensor]] = None,
+ coeff_preds: Optional[List[Tensor]] = None,
+ proto_preds: Optional[Tensor] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = True,
+ with_nms: bool = True) -> List[InstanceData]:
+ """Transform a batch of output features extracted from the head into
+ bbox results.
+ Note: When score_factors is not None, the cls_scores are
+ usually multiplied by it then obtain the real score used in NMS.
+ Args:
+ cls_scores (list[Tensor]): Classification scores for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * num_classes, H, W).
+ bbox_preds (list[Tensor]): Box energies / deltas for all
+ scale levels, each is a 4D-tensor, has shape
+ (batch_size, num_priors * 4, H, W).
+ objectnesses (list[Tensor], Optional): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W).
+ coeff_preds (list[Tensor]): Mask coefficients predictions
+ for all scale levels, each is a 4D-tensor, has shape
+ (batch_size, mask_channels, H, W).
+ proto_preds (Tensor): Mask prototype features extracted from the
+ mask head, has shape (batch_size, mask_channels, H, W).
+ batch_img_metas (list[dict], Optional): Batch image meta info.
+ Defaults to None.
+ cfg (ConfigDict, optional): Test / postprocessing
+ configuration, if None, test_cfg would be used.
+ Defaults to None.
+ rescale (bool): If True, return boxes in original image space.
+ Defaults to False.
+ with_nms (bool): If True, do nms before return boxes.
+ Defaults to True.
+ Returns:
+ list[:obj:`InstanceData`]: Object detection and instance
+ segmentation results of each image after the post process.
+ Each item usually contains following keys.
+ - scores (Tensor): Classification scores, has a shape
+ (num_instance, )
+ - labels (Tensor): Labels of bboxes, has a shape
+ (num_instances, ).
+ - bboxes (Tensor): Has a shape (num_instances, 4),
+ the last dimension 4 arrange as (x1, y1, x2, y2).
+ - masks (Tensor): Has a shape (num_instances, h, w).
+ """
+ assert len(cls_scores) == len(bbox_preds) == len(coeff_preds)
+ if objectnesses is None:
+ with_objectnesses = False
+ else:
+ with_objectnesses = True
+ assert len(cls_scores) == len(objectnesses)
+
+ cfg = self.test_cfg if cfg is None else cfg
+ cfg = copy.deepcopy(cfg)
+
+ multi_label = cfg.multi_label
+ multi_label &= self.num_classes > 1
+ cfg.multi_label = multi_label
+
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+
+ # If the shape does not change, use the previous mlvl_priors
+ if featmap_sizes != self.featmap_sizes:
+ self.mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device)
+ self.featmap_sizes = featmap_sizes
+ flatten_priors = torch.cat(self.mlvl_priors)
+
+ mlvl_strides = [
+ flatten_priors.new_full(
+ (featmap_size.numel() * self.num_base_priors, ), stride) for
+ featmap_size, stride in zip(featmap_sizes, self.featmap_strides)
+ ]
+ flatten_stride = torch.cat(mlvl_strides)
+
+ # flatten cls_scores, bbox_preds and objectness
+ flatten_cls_scores = [
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_classes)
+ for cls_score in cls_scores
+ ]
+ flatten_bbox_preds = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ flatten_coeff_preds = [
+ coeff_pred.permute(0, 2, 3,
+ 1).reshape(num_imgs, -1,
+ self.head_module.mask_channels)
+ for coeff_pred in coeff_preds
+ ]
+
+ flatten_cls_scores = torch.cat(flatten_cls_scores, dim=1).sigmoid()
+ flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
+ flatten_decoded_bboxes = self.bbox_coder.decode(
+ flatten_priors.unsqueeze(0), flatten_bbox_preds, flatten_stride)
+
+ flatten_coeff_preds = torch.cat(flatten_coeff_preds, dim=1)
+
+ if with_objectnesses:
+ flatten_objectness = [
+ objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
+ for objectness in objectnesses
+ ]
+ flatten_objectness = torch.cat(flatten_objectness, dim=1).sigmoid()
+ else:
+ flatten_objectness = [None for _ in range(len(featmap_sizes))]
+
+ results_list = []
+ for (bboxes, scores, objectness, coeffs, mask_proto,
+ img_meta) in zip(flatten_decoded_bboxes, flatten_cls_scores,
+ flatten_objectness, flatten_coeff_preds,
+ proto_preds, batch_img_metas):
+ ori_shape = img_meta['ori_shape']
+ batch_input_shape = img_meta['batch_input_shape']
+ input_shape_h, input_shape_w = batch_input_shape
+ if 'pad_param' in img_meta:
+ pad_param = img_meta['pad_param']
+ input_shape_withoutpad = (input_shape_h - pad_param[0] -
+ pad_param[1], input_shape_w -
+ pad_param[2] - pad_param[3])
+ else:
+ pad_param = None
+ input_shape_withoutpad = batch_input_shape
+ scale_factor = (input_shape_withoutpad[1] / ori_shape[1],
+ input_shape_withoutpad[0] / ori_shape[0])
+
+ score_thr = cfg.get('score_thr', -1)
+ # yolox_style does not require the following operations
+ if objectness is not None and score_thr > 0 and not cfg.get(
+ 'yolox_style', False):
+ conf_inds = objectness > score_thr
+ bboxes = bboxes[conf_inds, :]
+ scores = scores[conf_inds, :]
+ objectness = objectness[conf_inds]
+ coeffs = coeffs[conf_inds]
+
+ if objectness is not None:
+ # conf = obj_conf * cls_conf
+ scores *= objectness[:, None]
+ # NOTE: Important
+ coeffs *= objectness[:, None]
+
+ if scores.shape[0] == 0:
+ empty_results = InstanceData()
+ empty_results.bboxes = bboxes
+ empty_results.scores = scores[:, 0]
+ empty_results.labels = scores[:, 0].int()
+ h, w = ori_shape[:2] if rescale else img_meta['img_shape'][:2]
+ empty_results.masks = torch.zeros(
+ size=(0, h, w), dtype=torch.bool, device=bboxes.device)
+ results_list.append(empty_results)
+ continue
+
+ nms_pre = cfg.get('nms_pre', 100000)
+ if cfg.multi_label is False:
+ scores, labels = scores.max(1, keepdim=True)
+ scores, _, keep_idxs, results = filter_scores_and_topk(
+ scores,
+ score_thr,
+ nms_pre,
+ results=dict(labels=labels[:, 0], coeffs=coeffs))
+ labels = results['labels']
+ coeffs = results['coeffs']
+ else:
+ out = filter_scores_and_topk(
+ scores, score_thr, nms_pre, results=dict(coeffs=coeffs))
+ scores, labels, keep_idxs, filtered_results = out
+ coeffs = filtered_results['coeffs']
+
+ results = InstanceData(
+ scores=scores,
+ labels=labels,
+ bboxes=bboxes[keep_idxs],
+ coeffs=coeffs)
+
+ if cfg.get('yolox_style', False):
+ # do not need max_per_img
+ cfg.max_per_img = len(results)
+
+ results = self._bbox_post_process(
+ results=results,
+ cfg=cfg,
+ rescale=False,
+ with_nms=with_nms,
+ img_meta=img_meta)
+
+ if len(results.bboxes):
+ masks = self.process_mask(mask_proto, results.coeffs,
+ results.bboxes,
+ (input_shape_h, input_shape_w), True)
+ if rescale:
+ if pad_param is not None:
+ # bbox minus pad param
+ top_pad, _, left_pad, _ = pad_param
+ results.bboxes -= results.bboxes.new_tensor(
+ [left_pad, top_pad, left_pad, top_pad])
+ # mask crop pad param
+ top, left = int(top_pad), int(left_pad)
+ bottom, right = int(input_shape_h -
+ top_pad), int(input_shape_w -
+ left_pad)
+ masks = masks[:, :, top:bottom, left:right]
+ results.bboxes /= results.bboxes.new_tensor(
+ scale_factor).repeat((1, 2))
+
+ fast_test = cfg.get('fast_test', False)
+ if fast_test:
+ masks = F.interpolate(
+ masks,
+ size=ori_shape,
+ mode='bilinear',
+ align_corners=False)
+ masks = masks.squeeze(0)
+ masks = masks > cfg.mask_thr_binary
+ else:
+ masks.gt_(cfg.mask_thr_binary)
+ masks = torch.as_tensor(masks, dtype=torch.uint8)
+ masks = masks[0].permute(1, 2,
+ 0).contiguous().cpu().numpy()
+ masks = mmcv.imresize(masks,
+ (ori_shape[1], ori_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ masks = torch.from_numpy(masks).permute(2, 0, 1)
+
+ results.bboxes[:, 0::2].clamp_(0, ori_shape[1])
+ results.bboxes[:, 1::2].clamp_(0, ori_shape[0])
+
+ results.masks = masks.bool()
+ results_list.append(results)
+ else:
+ h, w = ori_shape[:2] if rescale else img_meta['img_shape'][:2]
+ results.masks = torch.zeros(
+ size=(0, h, w), dtype=torch.bool, device=bboxes.device)
+ results_list.append(results)
+ return results_list
+
+ def process_mask(self,
+ mask_proto: Tensor,
+ mask_coeff_pred: Tensor,
+ bboxes: Tensor,
+ shape: Tuple[int, int],
+ upsample: bool = False) -> Tensor:
+ """Generate mask logits results.
+
+ Args:
+ mask_proto (Tensor): Mask prototype features.
+ Has shape (num_instance, mask_channels).
+ mask_coeff_pred (Tensor): Mask coefficients prediction for
+ single image. Has shape (mask_channels, H, W)
+ bboxes (Tensor): Tensor of the bbox. Has shape (num_instance, 4).
+ shape (Tuple): Batch input shape of image.
+ upsample (bool): Whether upsample masks results to batch input
+ shape. Default to False.
+ Return:
+ Tensor: Instance segmentation masks for each instance.
+ Has shape (num_instance, H, W).
+ """
+ c, mh, mw = mask_proto.shape # CHW
+ masks = (
+ mask_coeff_pred @ mask_proto.float().view(c, -1)).sigmoid().view(
+ -1, mh, mw)[None]
+ if upsample:
+ masks = F.interpolate(
+ masks, shape, mode='bilinear', align_corners=False) # 1CHW
+ masks = self.crop_mask(masks, bboxes)
+ return masks
+
+ def crop_mask(self, masks: Tensor, boxes: Tensor) -> Tensor:
+ """Crop mask by the bounding box.
+
+ Args:
+ masks (Tensor): Predicted mask results. Has shape
+ (1, num_instance, H, W).
+ boxes (Tensor): Tensor of the bbox. Has shape (num_instance, 4).
+ Returns:
+ (torch.Tensor): The masks are being cropped to the bounding box.
+ """
+ _, n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1)
+ r = torch.arange(
+ w, device=masks.device,
+ dtype=x1.dtype)[None, None, None, :] # rows shape(1, 1, w, 1)
+ c = torch.arange(
+ h, device=masks.device,
+ dtype=x1.dtype)[None, None, :, None] # cols shape(1, h, 1, 1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
diff --git a/mmyolo/models/dense_heads/yolov6_head.py b/mmyolo/models/dense_heads/yolov6_head.py
index 4b492d121..3b01133f0 100644
--- a/mmyolo/models/dense_heads/yolov6_head.py
+++ b/mmyolo/models/dense_heads/yolov6_head.py
@@ -50,6 +50,7 @@ def __init__(self,
in_channels: Union[int, Sequence],
widen_factor: float = 1.0,
num_base_priors: int = 1,
+ reg_max=0,
featmap_strides: Sequence[int] = (8, 16, 32),
norm_cfg: ConfigType = dict(
type='BN', momentum=0.03, eps=0.001),
@@ -61,6 +62,7 @@ def __init__(self,
self.featmap_strides = featmap_strides
self.num_levels = len(self.featmap_strides)
self.num_base_priors = num_base_priors
+ self.reg_max = reg_max
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
@@ -80,6 +82,12 @@ def _init_layers(self):
self.cls_preds = nn.ModuleList()
self.reg_preds = nn.ModuleList()
self.stems = nn.ModuleList()
+
+ if self.reg_max > 1:
+ proj = torch.arange(
+ self.reg_max + self.num_base_priors, dtype=torch.float)
+ self.register_buffer('proj', proj, persistent=False)
+
for i in range(self.num_levels):
self.stems.append(
ConvModule(
@@ -116,7 +124,7 @@ def _init_layers(self):
self.reg_preds.append(
nn.Conv2d(
in_channels=self.in_channels[i],
- out_channels=self.num_base_priors * 4,
+ out_channels=(self.num_base_priors + self.reg_max) * 4,
kernel_size=1))
def init_weights(self):
@@ -148,6 +156,7 @@ def forward_single(self, x: Tensor, stem: nn.Module, cls_conv: nn.Module,
cls_pred: nn.Module, reg_conv: nn.Module,
reg_pred: nn.Module) -> Tuple[Tensor, Tensor]:
"""Forward feature of a single scale level."""
+ b, _, h, w = x.shape
y = stem(x)
cls_x = y
reg_x = y
@@ -155,9 +164,26 @@ def forward_single(self, x: Tensor, stem: nn.Module, cls_conv: nn.Module,
reg_feat = reg_conv(reg_x)
cls_score = cls_pred(cls_feat)
- bbox_pred = reg_pred(reg_feat)
+ bbox_dist_preds = reg_pred(reg_feat)
+
+ if self.reg_max > 1:
+ bbox_dist_preds = bbox_dist_preds.reshape(
+ [-1, 4, self.reg_max + self.num_base_priors,
+ h * w]).permute(0, 3, 1, 2)
+
+ # TODO: The get_flops script cannot handle the situation of
+ # matmul, and needs to be fixed later
+ # bbox_preds = bbox_dist_preds.softmax(3).matmul(self.proj)
+ bbox_preds = bbox_dist_preds.softmax(3).matmul(
+ self.proj.view([-1, 1])).squeeze(-1)
+ bbox_preds = bbox_preds.transpose(1, 2).reshape(b, -1, h, w)
+ else:
+ bbox_preds = bbox_dist_preds
- return cls_score, bbox_pred
+ if self.training:
+ return cls_score, bbox_preds, bbox_dist_preds
+ else:
+ return cls_score, bbox_preds
@MODELS.register_module()
@@ -238,6 +264,7 @@ def loss_by_feat(
self,
cls_scores: Sequence[Tensor],
bbox_preds: Sequence[Tensor],
+ bbox_dist_preds: Sequence[Tensor],
batch_gt_instances: Sequence[InstanceData],
batch_img_metas: Sequence[dict],
batch_gt_instances_ignore: OptInstanceList = None) -> dict:
diff --git a/mmyolo/models/dense_heads/yolov7_head.py b/mmyolo/models/dense_heads/yolov7_head.py
index 80e6aadd2..124883cf4 100644
--- a/mmyolo/models/dense_heads/yolov7_head.py
+++ b/mmyolo/models/dense_heads/yolov7_head.py
@@ -39,7 +39,7 @@ def init_weights(self):
for mi, s in zip(self.convs_pred, self.featmap_strides): # from
mi = mi[1] # nn.Conv2d
- b = mi.bias.data.view(3, -1)
+ b = mi.bias.data.view(self.num_base_priors, -1)
# obj (8 objects per 640 image)
b.data[:, 4] += math.log(8 / (640 / s)**2)
b.data[:, 5:] += math.log(0.6 / (self.num_classes - 0.99))
diff --git a/mmyolo/models/dense_heads/yolox_pose_head.py b/mmyolo/models/dense_heads/yolox_pose_head.py
new file mode 100644
index 000000000..96264e552
--- /dev/null
+++ b/mmyolo/models/dense_heads/yolox_pose_head.py
@@ -0,0 +1,409 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import defaultdict
+from typing import List, Optional, Sequence, Tuple, Union
+
+import torch
+import torch.nn as nn
+from mmcv.ops import batched_nms
+from mmdet.models.utils import filter_scores_and_topk
+from mmdet.utils import ConfigType, OptInstanceList
+from mmengine.config import ConfigDict
+from mmengine.model import ModuleList, bias_init_with_prob
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.registry import MODELS
+from ..utils import OutputSaveFunctionWrapper, OutputSaveObjectWrapper
+from .yolox_head import YOLOXHead, YOLOXHeadModule
+
+
+@MODELS.register_module()
+class YOLOXPoseHeadModule(YOLOXHeadModule):
+ """YOLOXPoseHeadModule serves as a head module for `YOLOX-Pose`.
+
+ In comparison to `YOLOXHeadModule`, this module introduces branches for
+ keypoint prediction.
+ """
+
+ def __init__(self, num_keypoints: int, *args, **kwargs):
+ self.num_keypoints = num_keypoints
+ super().__init__(*args, **kwargs)
+
+ def _init_layers(self):
+ """Initializes the layers in the head module."""
+ super()._init_layers()
+
+ # The pose branch requires additional layers for precise regression
+ self.stacked_convs *= 2
+
+ # Create separate layers for each level of feature maps
+ pose_convs, offsets_preds, vis_preds = [], [], []
+ for _ in self.featmap_strides:
+ pose_convs.append(self._build_stacked_convs())
+ offsets_preds.append(
+ nn.Conv2d(self.feat_channels, self.num_keypoints * 2, 1))
+ vis_preds.append(
+ nn.Conv2d(self.feat_channels, self.num_keypoints, 1))
+
+ self.multi_level_pose_convs = ModuleList(pose_convs)
+ self.multi_level_conv_offsets = ModuleList(offsets_preds)
+ self.multi_level_conv_vis = ModuleList(vis_preds)
+
+ def init_weights(self):
+ """Initialize weights of the head."""
+ super().init_weights()
+
+ # Use prior in model initialization to improve stability
+ bias_init = bias_init_with_prob(0.01)
+ for conv_vis in self.multi_level_conv_vis:
+ conv_vis.bias.data.fill_(bias_init)
+
+ def forward(self, x: Tuple[Tensor]) -> Tuple[List]:
+ """Forward features from the upstream network."""
+ offsets_pred, vis_pred = [], []
+ for i in range(len(x)):
+ pose_feat = self.multi_level_pose_convs[i](x[i])
+ offsets_pred.append(self.multi_level_conv_offsets[i](pose_feat))
+ vis_pred.append(self.multi_level_conv_vis[i](pose_feat))
+ return (*super().forward(x), offsets_pred, vis_pred)
+
+
+@MODELS.register_module()
+class YOLOXPoseHead(YOLOXHead):
+ """YOLOXPoseHead head used in `YOLO-Pose.
+
+
`_.
+ Args:
+ loss_pose (ConfigDict, optional): Config of keypoint OKS loss.
+ """
+
+ def __init__(
+ self,
+ loss_pose: Optional[ConfigType] = None,
+ *args,
+ **kwargs,
+ ):
+ super().__init__(*args, **kwargs)
+ self.loss_pose = MODELS.build(loss_pose)
+ self.num_keypoints = self.head_module.num_keypoints
+
+ # set up buffers to save variables generated in methods of
+ # the class's base class.
+ self._log = defaultdict(list)
+ self.sampler = OutputSaveObjectWrapper(self.sampler)
+
+ # ensure that the `sigmas` in self.assigner.oks_calculator
+ # is on the same device as the model
+ if hasattr(self.assigner, 'oks_calculator'):
+ self.add_module('assigner_oks_calculator',
+ self.assigner.oks_calculator)
+
+ def _clear(self):
+ """Clear variable buffers."""
+ self.sampler.clear()
+ self._log.clear()
+
+ def loss(self, x: Tuple[Tensor], batch_data_samples: Union[list,
+ dict]) -> dict:
+
+ if isinstance(batch_data_samples, list):
+ losses = super().loss(x, batch_data_samples)
+ else:
+ outs = self(x)
+ # Fast version
+ loss_inputs = outs + (batch_data_samples['bboxes_labels'],
+ batch_data_samples['keypoints'],
+ batch_data_samples['keypoints_visible'],
+ batch_data_samples['img_metas'])
+ losses = self.loss_by_feat(*loss_inputs)
+
+ return losses
+
+ def loss_by_feat(
+ self,
+ cls_scores: Sequence[Tensor],
+ bbox_preds: Sequence[Tensor],
+ objectnesses: Sequence[Tensor],
+ kpt_preds: Sequence[Tensor],
+ vis_preds: Sequence[Tensor],
+ batch_gt_instances: Tensor,
+ batch_gt_keypoints: Tensor,
+ batch_gt_keypoints_visible: Tensor,
+ batch_img_metas: Sequence[dict],
+ batch_gt_instances_ignore: OptInstanceList = None) -> dict:
+ """Calculate the loss based on the features extracted by the detection
+ head.
+
+ In addition to the base class method, keypoint losses are also
+ calculated in this method.
+ """
+
+ self._clear()
+ batch_gt_instances = self.gt_kps_instances_preprocess(
+ batch_gt_instances, batch_gt_keypoints, batch_gt_keypoints_visible,
+ len(batch_img_metas))
+
+ # collect keypoints coordinates and visibility from model predictions
+ kpt_preds = torch.cat([
+ kpt_pred.flatten(2).permute(0, 2, 1).contiguous()
+ for kpt_pred in kpt_preds
+ ],
+ dim=1)
+
+ featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
+ mlvl_priors = self.prior_generator.grid_priors(
+ featmap_sizes,
+ dtype=cls_scores[0].dtype,
+ device=cls_scores[0].device,
+ with_stride=True)
+ grid_priors = torch.cat(mlvl_priors)
+
+ flatten_kpts = self.decode_pose(grid_priors[..., :2], kpt_preds,
+ grid_priors[..., 2])
+
+ vis_preds = torch.cat([
+ vis_pred.flatten(2).permute(0, 2, 1).contiguous()
+ for vis_pred in vis_preds
+ ],
+ dim=1)
+
+ # compute detection losses and collect targets for keypoints
+ # predictions simultaneously
+ self._log['pred_keypoints'] = list(flatten_kpts.detach().split(
+ 1, dim=0))
+ self._log['pred_keypoints_vis'] = list(vis_preds.detach().split(
+ 1, dim=0))
+
+ losses = super().loss_by_feat(cls_scores, bbox_preds, objectnesses,
+ batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore)
+
+ kpt_targets, vis_targets = [], []
+ sampling_results = self.sampler.log['sample']
+ sampling_result_idx = 0
+ for gt_instances in batch_gt_instances:
+ if len(gt_instances) > 0:
+ sampling_result = sampling_results[sampling_result_idx]
+ kpt_target = gt_instances['keypoints'][
+ sampling_result.pos_assigned_gt_inds]
+ vis_target = gt_instances['keypoints_visible'][
+ sampling_result.pos_assigned_gt_inds]
+ sampling_result_idx += 1
+ kpt_targets.append(kpt_target)
+ vis_targets.append(vis_target)
+
+ if len(kpt_targets) > 0:
+ kpt_targets = torch.cat(kpt_targets, 0)
+ vis_targets = torch.cat(vis_targets, 0)
+
+ # compute keypoint losses
+ if len(kpt_targets) > 0:
+ vis_targets = (vis_targets > 0).float()
+ pos_masks = torch.cat(self._log['foreground_mask'], 0)
+ bbox_targets = torch.cat(self._log['bbox_target'], 0)
+ loss_kpt = self.loss_pose(
+ flatten_kpts.view(-1, self.num_keypoints, 2)[pos_masks],
+ kpt_targets, vis_targets, bbox_targets)
+ loss_vis = self.loss_cls(
+ vis_preds.view(-1, self.num_keypoints)[pos_masks],
+ vis_targets) / vis_targets.sum()
+ else:
+ loss_kpt = kpt_preds.sum() * 0
+ loss_vis = vis_preds.sum() * 0
+
+ losses.update(dict(loss_kpt=loss_kpt, loss_vis=loss_vis))
+
+ self._clear()
+ return losses
+
+ @torch.no_grad()
+ def _get_targets_single(
+ self,
+ priors: Tensor,
+ cls_preds: Tensor,
+ decoded_bboxes: Tensor,
+ objectness: Tensor,
+ gt_instances: InstanceData,
+ img_meta: dict,
+ gt_instances_ignore: Optional[InstanceData] = None) -> tuple:
+ """Calculates targets for a single image, and saves them to the log.
+
+ This method is similar to the _get_targets_single method in the base
+ class, but additionally saves the foreground mask and bbox targets to
+ the log.
+ """
+
+ # Construct a combined representation of bboxes and keypoints to
+ # ensure keypoints are also involved in the positive sample
+ # assignment process
+ kpt = self._log['pred_keypoints'].pop(0).squeeze(0)
+ kpt_vis = self._log['pred_keypoints_vis'].pop(0).squeeze(0)
+ kpt = torch.cat((kpt, kpt_vis.unsqueeze(-1)), dim=-1)
+ decoded_bboxes = torch.cat((decoded_bboxes, kpt.flatten(1)), dim=1)
+
+ targets = super()._get_targets_single(priors, cls_preds,
+ decoded_bboxes, objectness,
+ gt_instances, img_meta,
+ gt_instances_ignore)
+ self._log['foreground_mask'].append(targets[0])
+ self._log['bbox_target'].append(targets[3])
+ return targets
+
+ def predict_by_feat(self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: Optional[List[Tensor]] = None,
+ kpt_preds: Optional[List[Tensor]] = None,
+ vis_preds: Optional[List[Tensor]] = None,
+ batch_img_metas: Optional[List[dict]] = None,
+ cfg: Optional[ConfigDict] = None,
+ rescale: bool = True,
+ with_nms: bool = True) -> List[InstanceData]:
+ """Transform a batch of output features extracted by the head into bbox
+ and keypoint results.
+
+ In addition to the base class method, keypoint predictions are also
+ calculated in this method.
+ """
+ """calculate predicted bboxes and get the kept instances indices.
+
+ use OutputSaveFunctionWrapper as context manager to obtain
+ intermediate output from a parent class without copying a
+ arge block of code
+ """
+ with OutputSaveFunctionWrapper(
+ filter_scores_and_topk,
+ super().predict_by_feat.__globals__) as outputs_1:
+ with OutputSaveFunctionWrapper(
+ batched_nms,
+ super()._bbox_post_process.__globals__) as outputs_2:
+ results_list = super().predict_by_feat(cls_scores, bbox_preds,
+ objectnesses,
+ batch_img_metas, cfg,
+ rescale, with_nms)
+ keep_indices_topk = [
+ out[2][:cfg.max_per_img] for out in outputs_1
+ ]
+ keep_indices_nms = [
+ out[1][:cfg.max_per_img] for out in outputs_2
+ ]
+
+ num_imgs = len(batch_img_metas)
+
+ # recover keypoints coordinates from model predictions
+ featmap_sizes = [vis_pred.shape[2:] for vis_pred in vis_preds]
+ priors = torch.cat(self.mlvl_priors)
+ strides = [
+ priors.new_full((featmap_size.numel() * self.num_base_priors, ),
+ stride) for featmap_size, stride in zip(
+ featmap_sizes, self.featmap_strides)
+ ]
+ strides = torch.cat(strides)
+ kpt_preds = torch.cat([
+ kpt_pred.permute(0, 2, 3, 1).reshape(
+ num_imgs, -1, self.num_keypoints * 2) for kpt_pred in kpt_preds
+ ],
+ dim=1)
+ flatten_decoded_kpts = self.decode_pose(priors, kpt_preds, strides)
+
+ vis_preds = torch.cat([
+ vis_pred.permute(0, 2, 3, 1).reshape(
+ num_imgs, -1, self.num_keypoints) for vis_pred in vis_preds
+ ],
+ dim=1).sigmoid()
+
+ # select keypoints predictions according to bbox scores and nms result
+ keep_indices_nms_idx = 0
+ for pred_instances, kpts, kpts_vis, img_meta, keep_idxs \
+ in zip(
+ results_list, flatten_decoded_kpts, vis_preds,
+ batch_img_metas, keep_indices_topk):
+
+ pred_instances.bbox_scores = pred_instances.scores
+
+ if len(pred_instances) == 0:
+ pred_instances.keypoints = kpts[:0]
+ pred_instances.keypoint_scores = kpts_vis[:0]
+ continue
+
+ kpts = kpts[keep_idxs]
+ kpts_vis = kpts_vis[keep_idxs]
+
+ if rescale:
+ pad_param = img_meta.get('img_meta', None)
+ scale_factor = img_meta['scale_factor']
+ if pad_param is not None:
+ kpts -= kpts.new_tensor([pad_param[2], pad_param[0]])
+ kpts /= kpts.new_tensor(scale_factor).repeat(
+ (1, self.num_keypoints, 1))
+
+ keep_idxs_nms = keep_indices_nms[keep_indices_nms_idx]
+ kpts = kpts[keep_idxs_nms]
+ kpts_vis = kpts_vis[keep_idxs_nms]
+ keep_indices_nms_idx += 1
+
+ pred_instances.keypoints = kpts
+ pred_instances.keypoint_scores = kpts_vis
+
+ results_list = [r.numpy() for r in results_list]
+ return results_list
+
+ def decode_pose(self, grids: torch.Tensor, offsets: torch.Tensor,
+ strides: Union[torch.Tensor, int]) -> torch.Tensor:
+ """Decode regression offsets to keypoints.
+
+ Args:
+ grids (torch.Tensor): The coordinates of the feature map grids.
+ offsets (torch.Tensor): The predicted offset of each keypoint
+ relative to its corresponding grid.
+ strides (torch.Tensor | int): The stride of the feature map for
+ each instance.
+ Returns:
+ torch.Tensor: The decoded keypoints coordinates.
+ """
+
+ if isinstance(strides, int):
+ strides = torch.tensor([strides]).to(offsets)
+
+ strides = strides.reshape(1, -1, 1, 1)
+ offsets = offsets.reshape(*offsets.shape[:2], -1, 2)
+ xy_coordinates = (offsets[..., :2] * strides) + grids.unsqueeze(1)
+ return xy_coordinates
+
+ @staticmethod
+ def gt_kps_instances_preprocess(batch_gt_instances: Tensor,
+ batch_gt_keypoints,
+ batch_gt_keypoints_visible,
+ batch_size: int) -> List[InstanceData]:
+ """Split batch_gt_instances with batch size.
+
+ Args:
+ batch_gt_instances (Tensor): Ground truth
+ a 2D-Tensor for whole batch, shape [all_gt_bboxes, 6]
+ batch_size (int): Batch size.
+
+ Returns:
+ List: batch gt instances data, shape [batch_size, InstanceData]
+ """
+ # faster version
+ batch_instance_list = []
+ for i in range(batch_size):
+ batch_gt_instance_ = InstanceData()
+ single_batch_instance = \
+ batch_gt_instances[batch_gt_instances[:, 0] == i, :]
+ keypoints = \
+ batch_gt_keypoints[batch_gt_instances[:, 0] == i, :]
+ keypoints_visible = \
+ batch_gt_keypoints_visible[batch_gt_instances[:, 0] == i, :]
+ batch_gt_instance_.bboxes = single_batch_instance[:, 2:]
+ batch_gt_instance_.labels = single_batch_instance[:, 1]
+ batch_gt_instance_.keypoints = keypoints
+ batch_gt_instance_.keypoints_visible = keypoints_visible
+ batch_instance_list.append(batch_gt_instance_)
+
+ return batch_instance_list
+
+ @staticmethod
+ def gt_instances_preprocess(batch_gt_instances: List[InstanceData], *args,
+ **kwargs) -> List[InstanceData]:
+ return batch_gt_instances
diff --git a/mmyolo/models/layers/__init__.py b/mmyolo/models/layers/__init__.py
index f709dbb7e..02753057f 100644
--- a/mmyolo/models/layers/__init__.py
+++ b/mmyolo/models/layers/__init__.py
@@ -1,6 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .ema import ExpMomentumEMA
-from .yolo_bricks import (BepC3StageBlock, CSPLayerWithTwoConv,
+from .yolo_bricks import (BepC3StageBlock, BiFusion, CSPLayerWithTwoConv,
DarknetBottleneck, EELANBlock, EffectiveSELayer,
ELANBlock, ImplicitA, ImplicitM,
MaxPoolAndStrideConvBlock, PPYOLOEBasicBlock,
@@ -12,5 +12,5 @@
'ELANBlock', 'MaxPoolAndStrideConvBlock', 'SPPFCSPBlock',
'PPYOLOEBasicBlock', 'EffectiveSELayer', 'TinyDownSampleBlock',
'EELANBlock', 'ImplicitA', 'ImplicitM', 'BepC3StageBlock',
- 'CSPLayerWithTwoConv', 'DarknetBottleneck'
+ 'CSPLayerWithTwoConv', 'DarknetBottleneck', 'BiFusion'
]
diff --git a/mmyolo/models/layers/yolo_bricks.py b/mmyolo/models/layers/yolo_bricks.py
index 2e69d528b..19175be1a 100644
--- a/mmyolo/models/layers/yolo_bricks.py
+++ b/mmyolo/models/layers/yolo_bricks.py
@@ -1,5 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Optional, Sequence, Tuple, Union
+from typing import List, Optional, Sequence, Tuple, Union
import numpy as np
import torch
@@ -1508,3 +1508,221 @@ def forward(self, x: Tensor) -> Tensor:
x_main = list(x_main.split((self.mid_channels, self.mid_channels), 1))
x_main.extend(blocks(x_main[-1]) for blocks in self.blocks)
return self.final_conv(torch.cat(x_main, 1))
+
+
+class BiFusion(nn.Module):
+ """BiFusion Block in YOLOv6.
+
+ BiFusion fuses current-, high- and low-level features.
+ Compared with concatenation in PAN, it fuses an extra low-level feature.
+
+ Args:
+ in_channels0 (int): The channels of current-level feature.
+ in_channels1 (int): The input channels of lower-level feature.
+ out_channels (int): The out channels of the BiFusion module.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU', inplace=True).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels0: int,
+ in_channels1: int,
+ out_channels: int,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True)):
+ super().__init__()
+ self.conv1 = ConvModule(
+ in_channels0,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv2 = ConvModule(
+ in_channels1,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv3 = ConvModule(
+ out_channels * 3,
+ out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.upsample = nn.ConvTranspose2d(
+ out_channels, out_channels, kernel_size=2, stride=2, bias=True)
+ self.downsample = ConvModule(
+ out_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ bias=False,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x: List[torch.Tensor]) -> Tensor:
+ """Forward process
+ Args:
+ x (List[torch.Tensor]): The tensor list of length 3.
+ x[0]: The high-level feature.
+ x[1]: The current-level feature.
+ x[2]: The low-level feature.
+ """
+ x0 = self.upsample(x[0])
+ x1 = self.conv1(x[1])
+ x2 = self.downsample(self.conv2(x[2]))
+ return self.conv3(torch.cat((x0, x1, x2), dim=1))
+
+
+class CSPSPPFBottleneck(BaseModule):
+ """The SPPF block having a CSP-like version in YOLOv6 3.0.
+
+ Args:
+ in_channels (int): The input channels of this Module.
+ out_channels (int): The output channels of this Module.
+ kernel_sizes (int, tuple[int]): Sequential or number of kernel
+ sizes of pooling layers. Defaults to 5.
+ use_conv_first (bool): Whether to use conv before pooling layer.
+ In YOLOv5 and YOLOX, the para set to True.
+ In PPYOLOE, the para set to False.
+ Defaults to True.
+ mid_channels_scale (float): Channel multiplier, multiply in_channels
+ by this amount to get mid_channels. This parameter is valid only
+ when use_conv_fist=True.Defaults to 0.5.
+ conv_cfg (dict): Config dict for convolution layer. Defaults to None.
+ which means using conv2d. Defaults to None.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='SiLU', inplace=True).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: int,
+ out_channels: int,
+ kernel_sizes: Union[int, Sequence[int]] = 5,
+ use_conv_first: bool = True,
+ mid_channels_scale: float = 0.5,
+ conv_cfg: ConfigType = None,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ init_cfg: OptMultiConfig = None):
+ super().__init__(init_cfg)
+
+ if use_conv_first:
+ mid_channels = int(in_channels * mid_channels_scale)
+ self.conv1 = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv3 = ConvModule(
+ mid_channels,
+ mid_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv4 = ConvModule(
+ mid_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ mid_channels = in_channels
+ self.conv1 = None
+ self.conv3 = None
+ self.conv4 = None
+
+ self.conv2 = ConvModule(
+ in_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ self.kernel_sizes = kernel_sizes
+
+ if isinstance(kernel_sizes, int):
+ self.poolings = nn.MaxPool2d(
+ kernel_size=kernel_sizes, stride=1, padding=kernel_sizes // 2)
+ conv2_in_channels = mid_channels * 4
+ else:
+ self.poolings = nn.ModuleList([
+ nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
+ for ks in kernel_sizes
+ ])
+ conv2_in_channels = mid_channels * (len(kernel_sizes) + 1)
+
+ self.conv5 = ConvModule(
+ conv2_in_channels,
+ mid_channels,
+ 1,
+ stride=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv6 = ConvModule(
+ mid_channels,
+ mid_channels,
+ 3,
+ stride=1,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ self.conv7 = ConvModule(
+ mid_channels * 2,
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, x: Tensor) -> Tensor:
+ """Forward process
+ Args:
+ x (Tensor): The input tensor.
+ """
+ x0 = self.conv4(self.conv3(self.conv1(x))) if self.conv1 else x
+ y = self.conv2(x)
+
+ if isinstance(self.kernel_sizes, int):
+ x1 = self.poolings(x0)
+ x2 = self.poolings(x1)
+ x3 = torch.cat([x0, x1, x2, self.poolings(x2)], dim=1)
+ else:
+ x3 = torch.cat(
+ [x0] + [pooling(x0) for pooling in self.poolings], dim=1)
+
+ x3 = self.conv6(self.conv5(x3))
+ x = self.conv7(torch.cat([y, x3], dim=1))
+ return x
diff --git a/mmyolo/models/losses/__init__.py b/mmyolo/models/losses/__init__.py
index ee192921b..c89fe4dc4 100644
--- a/mmyolo/models/losses/__init__.py
+++ b/mmyolo/models/losses/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .iou_loss import IoULoss, bbox_overlaps
+from .oks_loss import OksLoss
-__all__ = ['IoULoss', 'bbox_overlaps']
+__all__ = ['IoULoss', 'bbox_overlaps', 'OksLoss']
diff --git a/mmyolo/models/losses/oks_loss.py b/mmyolo/models/losses/oks_loss.py
new file mode 100644
index 000000000..62c63422b
--- /dev/null
+++ b/mmyolo/models/losses/oks_loss.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmyolo.registry import MODELS
+
+try:
+ from mmpose.datasets.datasets.utils import parse_pose_metainfo
+except ImportError:
+ parse_pose_metainfo = None
+
+
+@MODELS.register_module()
+class OksLoss(nn.Module):
+ """A PyTorch implementation of the Object Keypoint Similarity (OKS) loss as
+ described in the paper "YOLO-Pose: Enhancing YOLO for Multi Person Pose
+ Estimation Using Object Keypoint Similarity Loss" by Debapriya et al.
+
+ (2022).
+ The OKS loss is used for keypoint-based object recognition and consists
+ of a measure of the similarity between predicted and ground truth
+ keypoint locations, adjusted by the size of the object in the image.
+ The loss function takes as input the predicted keypoint locations, the
+ ground truth keypoint locations, a mask indicating which keypoints are
+ valid, and bounding boxes for the objects.
+ Args:
+ metainfo (Optional[str]): Path to a JSON file containing information
+ about the dataset's annotations.
+ loss_weight (float): Weight for the loss.
+ """
+
+ def __init__(self,
+ metainfo: Optional[str] = None,
+ loss_weight: float = 1.0):
+ super().__init__()
+
+ if metainfo is not None:
+ if parse_pose_metainfo is None:
+ raise ImportError(
+ 'Please run "mim install -r requirements/mmpose.txt" '
+ 'to install mmpose first for OksLossn.')
+ metainfo = parse_pose_metainfo(dict(from_file=metainfo))
+ sigmas = metainfo.get('sigmas', None)
+ if sigmas is not None:
+ self.register_buffer('sigmas', torch.as_tensor(sigmas))
+ self.loss_weight = loss_weight
+
+ def forward(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Tensor,
+ bboxes: Optional[Tensor] = None) -> Tensor:
+ oks = self.compute_oks(output, target, target_weights, bboxes)
+ loss = 1 - oks
+ return loss * self.loss_weight
+
+ def compute_oks(self,
+ output: Tensor,
+ target: Tensor,
+ target_weights: Tensor,
+ bboxes: Optional[Tensor] = None) -> Tensor:
+ """Calculates the OKS loss.
+
+ Args:
+ output (Tensor): Predicted keypoints in shape N x k x 2, where N
+ is batch size, k is the number of keypoints, and 2 are the
+ xy coordinates.
+ target (Tensor): Ground truth keypoints in the same shape as
+ output.
+ target_weights (Tensor): Mask of valid keypoints in shape N x k,
+ with 1 for valid and 0 for invalid.
+ bboxes (Optional[Tensor]): Bounding boxes in shape N x 4,
+ where 4 are the xyxy coordinates.
+ Returns:
+ Tensor: The calculated OKS loss.
+ """
+
+ dist = torch.norm(output - target, dim=-1)
+
+ if hasattr(self, 'sigmas'):
+ sigmas = self.sigmas.reshape(*((1, ) * (dist.ndim - 1)), -1)
+ dist = dist / sigmas
+ if bboxes is not None:
+ area = torch.norm(bboxes[..., 2:] - bboxes[..., :2], dim=-1)
+ dist = dist / area.clip(min=1e-8).unsqueeze(-1)
+
+ return (torch.exp(-dist.pow(2) / 2) * target_weights).sum(
+ dim=-1) / target_weights.sum(dim=-1).clip(min=1e-8)
diff --git a/mmyolo/models/necks/__init__.py b/mmyolo/models/necks/__init__.py
index 6da9641ce..159fae8d6 100644
--- a/mmyolo/models/necks/__init__.py
+++ b/mmyolo/models/necks/__init__.py
@@ -3,7 +3,8 @@
from .cspnext_pafpn import CSPNeXtPAFPN
from .ppyoloe_csppan import PPYOLOECSPPAFPN
from .yolov5_pafpn import YOLOv5PAFPN
-from .yolov6_pafpn import YOLOv6CSPRepPAFPN, YOLOv6RepPAFPN
+from .yolov6_pafpn import (YOLOv6CSPRepBiPAFPN, YOLOv6CSPRepPAFPN,
+ YOLOv6RepBiPAFPN, YOLOv6RepPAFPN)
from .yolov7_pafpn import YOLOv7PAFPN
from .yolov8_pafpn import YOLOv8PAFPN
from .yolox_pafpn import YOLOXPAFPN
@@ -11,5 +12,5 @@
__all__ = [
'YOLOv5PAFPN', 'BaseYOLONeck', 'YOLOv6RepPAFPN', 'YOLOXPAFPN',
'CSPNeXtPAFPN', 'YOLOv7PAFPN', 'PPYOLOECSPPAFPN', 'YOLOv6CSPRepPAFPN',
- 'YOLOv8PAFPN'
+ 'YOLOv8PAFPN', 'YOLOv6RepBiPAFPN', 'YOLOv6CSPRepBiPAFPN'
]
diff --git a/mmyolo/models/necks/yolov6_pafpn.py b/mmyolo/models/necks/yolov6_pafpn.py
index 74b7ce932..877827123 100644
--- a/mmyolo/models/necks/yolov6_pafpn.py
+++ b/mmyolo/models/necks/yolov6_pafpn.py
@@ -7,7 +7,7 @@
from mmdet.utils import ConfigType, OptMultiConfig
from mmyolo.registry import MODELS
-from ..layers import BepC3StageBlock, RepStageBlock
+from ..layers import BepC3StageBlock, BiFusion, RepStageBlock
from ..utils import make_round
from .base_yolo_neck import BaseYOLONeck
@@ -283,3 +283,245 @@ def build_bottom_up_layer(self, idx: int) -> nn.Module:
hidden_ratio=self.hidden_ratio,
norm_cfg=self.norm_cfg,
act_cfg=self.block_act_cfg)
+
+
+@MODELS.register_module()
+class YOLOv6RepBiPAFPN(YOLOv6RepPAFPN):
+ """Path Aggregation Network used in YOLOv6 3.0.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer. Defaults to 1.
+ freeze_all(bool): Whether to freeze the model.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='ReLU', inplace=True).
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ out_channels: int,
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ num_csp_blocks: int = 12,
+ freeze_all: bool = False,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True),
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
+ init_cfg: OptMultiConfig = None):
+ self.extra_in_channel = in_channels[0]
+ super().__init__(
+ in_channels=in_channels[1:],
+ out_channels=out_channels,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ num_csp_blocks=num_csp_blocks,
+ freeze_all=freeze_all,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ block_cfg=block_cfg,
+ init_cfg=init_cfg)
+
+ def build_top_down_layer(self, idx: int) -> nn.Module:
+ """build top down layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The top down layer.
+ """
+ block_cfg = self.block_cfg.copy()
+
+ layer0 = RepStageBlock(
+ in_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg)
+
+ if idx == 1:
+ return layer0
+ elif idx == 2:
+ layer1 = ConvModule(
+ in_channels=int(self.out_channels[idx - 1] *
+ self.widen_factor),
+ out_channels=int(self.out_channels[idx - 2] *
+ self.widen_factor),
+ kernel_size=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ return nn.Sequential(layer0, layer1)
+
+ def build_upsample_layer(self, idx: int) -> nn.Module:
+ """build upsample layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The upsample layer.
+ """
+ in_channels1 = self.in_channels[
+ idx - 2] if idx > 1 else self.extra_in_channel
+ return BiFusion(
+ in_channels0=int(self.in_channels[idx - 1] * self.widen_factor),
+ in_channels1=int(in_channels1 * self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+
+ def forward(self, inputs: List[torch.Tensor]) -> tuple:
+ """Forward function."""
+ assert len(inputs) == len(self.in_channels) + 1
+ # reduce layers
+ reduce_outs = [inputs[0]]
+ for idx in range(len(self.in_channels)):
+ reduce_outs.append(self.reduce_layers[idx](inputs[idx + 1]))
+
+ # top-down path
+ inner_outs = [reduce_outs[-1]]
+ for idx in range(len(self.in_channels) - 1, 0, -1):
+ feat_high = inner_outs[0]
+ feat_cur = reduce_outs[idx]
+ feat_low = reduce_outs[idx - 1]
+ top_down_layer_inputs = self.upsample_layers[len(self.in_channels)
+ - 1 - idx]([
+ feat_high,
+ feat_cur, feat_low
+ ])
+ inner_out = self.top_down_layers[len(self.in_channels) - 1 - idx](
+ top_down_layer_inputs)
+ inner_outs.insert(0, inner_out)
+
+ # bottom-up path
+ outs = [inner_outs[0]]
+ for idx in range(len(self.in_channels) - 1):
+ feat_low = outs[-1]
+ feat_high = inner_outs[idx + 1]
+ downsample_feat = self.downsample_layers[idx](feat_low)
+ out = self.bottom_up_layers[idx](
+ torch.cat([downsample_feat, feat_high], 1))
+ outs.append(out)
+
+ # out_layers
+ results = []
+ for idx in range(len(self.in_channels)):
+ results.append(self.out_layers[idx](outs[idx]))
+
+ return tuple(results)
+
+
+@MODELS.register_module()
+class YOLOv6CSPRepBiPAFPN(YOLOv6RepBiPAFPN):
+ """Path Aggregation Network used in YOLOv6 3.0.
+
+ Args:
+ in_channels (List[int]): Number of input channels per scale.
+ out_channels (int): Number of output channels (used at each scale)
+ deepen_factor (float): Depth multiplier, multiply number of
+ blocks in CSP layer by this amount. Defaults to 1.0.
+ widen_factor (float): Width multiplier, multiply number of
+ channels in each layer by this amount. Defaults to 1.0.
+ num_csp_blocks (int): Number of bottlenecks in CSPLayer. Defaults to 1.
+ freeze_all(bool): Whether to freeze the model.
+ norm_cfg (dict): Config dict for normalization layer.
+ Defaults to dict(type='BN', momentum=0.03, eps=0.001).
+ act_cfg (dict): Config dict for activation layer.
+ Defaults to dict(type='ReLU', inplace=True).
+ block_cfg (dict): Config dict for the block used to build each
+ layer. Defaults to dict(type='RepVGGBlock').
+ block_act_cfg (dict): Config dict for activation layer used in each
+ stage. Defaults to dict(type='SiLU', inplace=True).
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ in_channels: List[int],
+ out_channels: int,
+ deepen_factor: float = 1.0,
+ widen_factor: float = 1.0,
+ hidden_ratio: float = 0.5,
+ num_csp_blocks: int = 12,
+ freeze_all: bool = False,
+ norm_cfg: ConfigType = dict(
+ type='BN', momentum=0.03, eps=0.001),
+ act_cfg: ConfigType = dict(type='ReLU', inplace=True),
+ block_act_cfg: ConfigType = dict(type='SiLU', inplace=True),
+ block_cfg: ConfigType = dict(type='RepVGGBlock'),
+ init_cfg: OptMultiConfig = None):
+ self.hidden_ratio = hidden_ratio
+ self.block_act_cfg = block_act_cfg
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ num_csp_blocks=num_csp_blocks,
+ freeze_all=freeze_all,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ block_cfg=block_cfg,
+ init_cfg=init_cfg)
+
+ def build_top_down_layer(self, idx: int) -> nn.Module:
+ """build top down layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The top down layer.
+ """
+ block_cfg = self.block_cfg.copy()
+
+ layer0 = BepC3StageBlock(
+ in_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ out_channels=int(self.out_channels[idx - 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg,
+ hidden_ratio=self.hidden_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.block_act_cfg)
+
+ if idx == 1:
+ return layer0
+ elif idx == 2:
+ layer1 = ConvModule(
+ in_channels=int(self.out_channels[idx - 1] *
+ self.widen_factor),
+ out_channels=int(self.out_channels[idx - 2] *
+ self.widen_factor),
+ kernel_size=1,
+ stride=1,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.act_cfg)
+ return nn.Sequential(layer0, layer1)
+
+ def build_bottom_up_layer(self, idx: int) -> nn.Module:
+ """build bottom up layer.
+
+ Args:
+ idx (int): layer idx.
+ Returns:
+ nn.Module: The bottom up layer.
+ """
+ block_cfg = self.block_cfg.copy()
+
+ return BepC3StageBlock(
+ in_channels=int(self.out_channels[idx] * 2 * self.widen_factor),
+ out_channels=int(self.out_channels[idx + 1] * self.widen_factor),
+ num_blocks=make_round(self.num_csp_blocks, self.deepen_factor),
+ block_cfg=block_cfg,
+ hidden_ratio=self.hidden_ratio,
+ norm_cfg=self.norm_cfg,
+ act_cfg=self.block_act_cfg)
diff --git a/mmyolo/models/task_modules/assigners/__init__.py b/mmyolo/models/task_modules/assigners/__init__.py
index e74ab728b..7b2e2e69c 100644
--- a/mmyolo/models/task_modules/assigners/__init__.py
+++ b/mmyolo/models/task_modules/assigners/__init__.py
@@ -2,11 +2,13 @@
from .batch_atss_assigner import BatchATSSAssigner
from .batch_dsl_assigner import BatchDynamicSoftLabelAssigner
from .batch_task_aligned_assigner import BatchTaskAlignedAssigner
+from .pose_sim_ota_assigner import PoseSimOTAAssigner
from .utils import (select_candidates_in_gts, select_highest_overlaps,
yolov6_iou_calculator)
__all__ = [
'BatchATSSAssigner', 'BatchTaskAlignedAssigner',
'select_candidates_in_gts', 'select_highest_overlaps',
- 'yolov6_iou_calculator', 'BatchDynamicSoftLabelAssigner'
+ 'yolov6_iou_calculator', 'BatchDynamicSoftLabelAssigner',
+ 'PoseSimOTAAssigner'
]
diff --git a/mmyolo/models/task_modules/assigners/pose_sim_ota_assigner.py b/mmyolo/models/task_modules/assigners/pose_sim_ota_assigner.py
new file mode 100644
index 000000000..e66a9bf15
--- /dev/null
+++ b/mmyolo/models/task_modules/assigners/pose_sim_ota_assigner.py
@@ -0,0 +1,210 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn.functional as F
+from mmdet.models.task_modules.assigners import AssignResult, SimOTAAssigner
+from mmdet.utils import ConfigType
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.registry import MODELS, TASK_UTILS
+
+INF = 100000.0
+EPS = 1.0e-7
+
+
+@TASK_UTILS.register_module()
+class PoseSimOTAAssigner(SimOTAAssigner):
+
+ def __init__(self,
+ center_radius: float = 2.5,
+ candidate_topk: int = 10,
+ iou_weight: float = 3.0,
+ cls_weight: float = 1.0,
+ oks_weight: float = 0.0,
+ vis_weight: float = 0.0,
+ iou_calculator: ConfigType = dict(type='BboxOverlaps2D'),
+ oks_calculator: ConfigType = dict(type='OksLoss')):
+
+ self.center_radius = center_radius
+ self.candidate_topk = candidate_topk
+ self.iou_weight = iou_weight
+ self.cls_weight = cls_weight
+ self.oks_weight = oks_weight
+ self.vis_weight = vis_weight
+
+ self.iou_calculator = TASK_UTILS.build(iou_calculator)
+ self.oks_calculator = MODELS.build(oks_calculator)
+
+ def assign(self,
+ pred_instances: InstanceData,
+ gt_instances: InstanceData,
+ gt_instances_ignore: Optional[InstanceData] = None,
+ **kwargs) -> AssignResult:
+ """Assign gt to priors using SimOTA.
+
+ Args:
+ pred_instances (:obj:`InstanceData`): Instances of model
+ predictions. It includes ``priors``, and the priors can
+ be anchors or points, or the bboxes predicted by the
+ previous stage, has shape (n, 4). The bboxes predicted by
+ the current model or stage will be named ``bboxes``,
+ ``labels``, and ``scores``, the same as the ``InstanceData``
+ in other places.
+ gt_instances (:obj:`InstanceData`): Ground truth of instance
+ annotations. It usually includes ``bboxes``, with shape (k, 4),
+ and ``labels``, with shape (k, ).
+ gt_instances_ignore (:obj:`InstanceData`, optional): Instances
+ to be ignored during training. It includes ``bboxes``
+ attribute data that is ignored during training and testing.
+ Defaults to None.
+ Returns:
+ obj:`AssignResult`: The assigned result.
+ """
+ gt_bboxes = gt_instances.bboxes
+ gt_labels = gt_instances.labels
+ gt_keypoints = gt_instances.keypoints
+ gt_keypoints_visible = gt_instances.keypoints_visible
+ num_gt = gt_bboxes.size(0)
+
+ decoded_bboxes = pred_instances.bboxes[..., :4]
+ pred_kpts = pred_instances.bboxes[..., 4:]
+ pred_kpts = pred_kpts.reshape(*pred_kpts.shape[:-1], -1, 3)
+ pred_kpts_vis = pred_kpts[..., -1]
+ pred_kpts = pred_kpts[..., :2]
+ pred_scores = pred_instances.scores
+ priors = pred_instances.priors
+ num_bboxes = decoded_bboxes.size(0)
+
+ # assign 0 by default
+ assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
+ 0,
+ dtype=torch.long)
+ if num_gt == 0 or num_bboxes == 0:
+ # No ground truth or boxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ valid_mask, is_in_boxes_and_center = self.get_in_gt_and_in_center_info(
+ priors, gt_bboxes)
+ valid_decoded_bbox = decoded_bboxes[valid_mask]
+ valid_pred_scores = pred_scores[valid_mask]
+ valid_pred_kpts = pred_kpts[valid_mask]
+ valid_pred_kpts_vis = pred_kpts_vis[valid_mask]
+ num_valid = valid_decoded_bbox.size(0)
+ if num_valid == 0:
+ # No valid bboxes, return empty assignment
+ max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
+ assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
+ -1,
+ dtype=torch.long)
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ cost_matrix = (~is_in_boxes_and_center) * INF
+
+ # calculate iou
+ pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes)
+ if self.iou_weight > 0:
+ iou_cost = -torch.log(pairwise_ious + EPS)
+ cost_matrix = cost_matrix + iou_cost * self.iou_weight
+
+ # calculate oks
+ pairwise_oks = self.oks_calculator.compute_oks(
+ valid_pred_kpts.unsqueeze(1), # [num_valid, -1, k, 2]
+ gt_keypoints.unsqueeze(0), # [1, num_gt, k, 2]
+ gt_keypoints_visible.unsqueeze(0), # [1, num_gt, k]
+ bboxes=gt_bboxes.unsqueeze(0), # [1, num_gt, 4]
+ ) # -> [num_valid, num_gt]
+ if self.oks_weight > 0:
+ oks_cost = -torch.log(pairwise_oks + EPS)
+ cost_matrix = cost_matrix + oks_cost * self.oks_weight
+
+ # calculate cls
+ if self.cls_weight > 0:
+ gt_onehot_label = (
+ F.one_hot(gt_labels.to(torch.int64),
+ pred_scores.shape[-1]).float().unsqueeze(0).repeat(
+ num_valid, 1, 1))
+
+ valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(
+ 1, num_gt, 1)
+ # disable AMP autocast to avoid overflow
+ with torch.cuda.amp.autocast(enabled=False):
+ cls_cost = (
+ F.binary_cross_entropy(
+ valid_pred_scores.to(dtype=torch.float32),
+ gt_onehot_label,
+ reduction='none',
+ ).sum(-1).to(dtype=valid_pred_scores.dtype))
+ cost_matrix = cost_matrix + cls_cost * self.cls_weight
+
+ # calculate vis
+ if self.vis_weight > 0:
+ valid_pred_kpts_vis = valid_pred_kpts_vis.sigmoid().unsqueeze(
+ 1).repeat(1, num_gt, 1) # [num_valid, 1, k]
+ gt_kpt_vis = gt_keypoints_visible.unsqueeze(
+ 0).float() # [1, num_gt, k]
+ with torch.cuda.amp.autocast(enabled=False):
+ vis_cost = (
+ F.binary_cross_entropy(
+ valid_pred_kpts_vis.to(dtype=torch.float32),
+ gt_kpt_vis.repeat(num_valid, 1, 1),
+ reduction='none',
+ ).sum(-1).to(dtype=valid_pred_kpts_vis.dtype))
+ cost_matrix = cost_matrix + vis_cost * self.vis_weight
+
+ # mixed metric
+ pairwise_oks = pairwise_oks.pow(0.5)
+ matched_pred_oks, matched_gt_inds = \
+ self.dynamic_k_matching(
+ cost_matrix, pairwise_ious, pairwise_oks, num_gt, valid_mask)
+
+ # convert to AssignResult format
+ assigned_gt_inds[valid_mask] = matched_gt_inds + 1
+ assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
+ assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
+ max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
+ -INF,
+ dtype=torch.float32)
+ max_overlaps[valid_mask] = matched_pred_oks
+ return AssignResult(
+ num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
+
+ def dynamic_k_matching(self, cost: Tensor, pairwise_ious: Tensor,
+ pairwise_oks: Tensor, num_gt: int,
+ valid_mask: Tensor) -> Tuple[Tensor, Tensor]:
+ """Use IoU and matching cost to calculate the dynamic top-k positive
+ targets."""
+ matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
+ # select candidate topk ious for dynamic-k calculation
+ candidate_topk = min(self.candidate_topk, pairwise_ious.size(0))
+ topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0)
+ # calculate dynamic k for each gt
+ dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
+ for gt_idx in range(num_gt):
+ _, pos_idx = torch.topk(
+ cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
+ matching_matrix[:, gt_idx][pos_idx] = 1
+
+ del topk_ious, dynamic_ks, pos_idx
+
+ prior_match_gt_mask = matching_matrix.sum(1) > 1
+ if prior_match_gt_mask.sum() > 0:
+ cost_min, cost_argmin = torch.min(
+ cost[prior_match_gt_mask, :], dim=1)
+ matching_matrix[prior_match_gt_mask, :] *= 0
+ matching_matrix[prior_match_gt_mask, cost_argmin] = 1
+ # get foreground mask inside box and center prior
+ fg_mask_inboxes = matching_matrix.sum(1) > 0
+ valid_mask[valid_mask.clone()] = fg_mask_inboxes
+
+ matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
+ matched_pred_oks = (matching_matrix *
+ pairwise_oks).sum(1)[fg_mask_inboxes]
+ return matched_pred_oks, matched_gt_inds
diff --git a/mmyolo/models/utils/__init__.py b/mmyolo/models/utils/__init__.py
index cdfeaaf0f..d62ff80e2 100644
--- a/mmyolo/models/utils/__init__.py
+++ b/mmyolo/models/utils/__init__.py
@@ -1,4 +1,8 @@
# Copyright (c) OpenMMLab. All rights reserved.
-from .misc import gt_instances_preprocess, make_divisible, make_round
+from .misc import (OutputSaveFunctionWrapper, OutputSaveObjectWrapper,
+ gt_instances_preprocess, make_divisible, make_round)
-__all__ = ['make_divisible', 'make_round', 'gt_instances_preprocess']
+__all__ = [
+ 'make_divisible', 'make_round', 'gt_instances_preprocess',
+ 'OutputSaveFunctionWrapper', 'OutputSaveObjectWrapper'
+]
diff --git a/mmyolo/models/utils/misc.py b/mmyolo/models/utils/misc.py
index 531558b69..96cd1195a 100644
--- a/mmyolo/models/utils/misc.py
+++ b/mmyolo/models/utils/misc.py
@@ -1,6 +1,8 @@
# Copyright (c) OpenMMLab. All rights reserved.
import math
-from typing import Sequence, Union
+from collections import defaultdict
+from copy import deepcopy
+from typing import Any, Callable, Dict, Optional, Sequence, Tuple, Union
import torch
from mmdet.structures.bbox.transforms import get_box_tensor
@@ -95,3 +97,90 @@ def gt_instances_preprocess(batch_gt_instances: Union[Tensor, Sequence],
device=batch_gt_instances.device)
return batch_instance
+
+
+class OutputSaveObjectWrapper:
+ """A wrapper class that saves the output of function calls on an object."""
+
+ def __init__(self, obj: Any) -> None:
+ self.obj = obj
+ self.log = defaultdict(list)
+
+ def __getattr__(self, attr: str) -> Any:
+ """Overrides the default behavior when an attribute is accessed.
+
+ - If the attribute is callable, hooks the attribute and saves the
+ returned value of the function call to the log.
+ - If the attribute is not callable, saves the attribute's value to the
+ log and returns the value.
+ """
+ orig_attr = getattr(self.obj, attr)
+
+ if not callable(orig_attr):
+ self.log[attr].append(orig_attr)
+ return orig_attr
+
+ def hooked(*args: Tuple, **kwargs: Dict) -> Any:
+ """The hooked function that logs the return value of the original
+ function."""
+ result = orig_attr(*args, **kwargs)
+ self.log[attr].append(result)
+ return result
+
+ return hooked
+
+ def clear(self):
+ """Clears the log of function call outputs."""
+ self.log.clear()
+
+ def __deepcopy__(self, memo):
+ """Only copy the object when applying deepcopy."""
+ other = type(self)(deepcopy(self.obj))
+ memo[id(self)] = other
+ return other
+
+
+class OutputSaveFunctionWrapper:
+ """A class that wraps a function and saves its outputs.
+
+ This class can be used to decorate a function to save its outputs. It wraps
+ the function with a `__call__` method that calls the original function and
+ saves the results in a log attribute.
+ Args:
+ func (Callable): A function to wrap.
+ spec (Optional[Dict]): A dictionary of global variables to use as the
+ namespace for the wrapper. If `None`, the global namespace of the
+ original function is used.
+ """
+
+ def __init__(self, func: Callable, spec: Optional[Dict]) -> None:
+ """Initializes the OutputSaveFunctionWrapper instance."""
+ assert callable(func)
+ self.log = []
+ self.func = func
+ self.func_name = func.__name__
+
+ if isinstance(spec, dict):
+ self.spec = spec
+ elif hasattr(func, '__globals__'):
+ self.spec = func.__globals__
+ else:
+ raise ValueError
+
+ def __call__(self, *args, **kwargs) -> Any:
+ """Calls the wrapped function with the given arguments and saves the
+ results in the `log` attribute."""
+ results = self.func(*args, **kwargs)
+ self.log.append(results)
+ return results
+
+ def __enter__(self) -> None:
+ """Enters the context and sets the wrapped function to be a global
+ variable in the specified namespace."""
+ self.spec[self.func_name] = self
+ return self.log
+
+ def __exit__(self, exc_type, exc_val, exc_tb) -> None:
+ """Exits the context and resets the wrapped function to its original
+ value in the specified namespace."""
+ self.spec[self.func_name] = self.func
diff --git a/mmyolo/utils/boxam_utils.py b/mmyolo/utils/boxam_utils.py
index 4a46f21c1..50d6c09ec 100644
--- a/mmyolo/utils/boxam_utils.py
+++ b/mmyolo/utils/boxam_utils.py
@@ -202,8 +202,10 @@ def __call__(self, *args, **kwargs):
if self.is_need_loss:
# Maybe this is a direction that can be optimized
# self.detector.init_weights()
-
- self.detector.bbox_head.head_module.training = True
+ if hasattr(self.detector.bbox_head, 'head_module'):
+ self.detector.bbox_head.head_module.training = True
+ else:
+ self.detector.bbox_head.training = True
if hasattr(self.detector.bbox_head, 'featmap_sizes'):
# Prevent the model algorithm error when calculating loss
self.detector.bbox_head.featmap_sizes = None
@@ -219,7 +221,10 @@ def __call__(self, *args, **kwargs):
return [loss]
else:
- self.detector.bbox_head.head_module.training = False
+ if hasattr(self.detector.bbox_head, 'head_module'):
+ self.detector.bbox_head.head_module.training = False
+ else:
+ self.detector.bbox_head.training = False
with torch.no_grad():
results = self.detector.test_step(self.input_data)
return results
diff --git a/mmyolo/utils/misc.py b/mmyolo/utils/misc.py
index c90f52b94..f5d366d75 100644
--- a/mmyolo/utils/misc.py
+++ b/mmyolo/utils/misc.py
@@ -72,7 +72,9 @@ def get_file_list(source_root: str) -> [list, dict]:
source_file_path_list = []
if is_dir:
# when input source is dir
- for file in scandir(source_root, IMG_EXTENSIONS, recursive=True):
+ for file in scandir(
+ source_root, IMG_EXTENSIONS, recursive=True,
+ case_sensitive=False):
source_file_path_list.append(os.path.join(source_root, file))
elif is_url:
# when input source is url
diff --git a/mmyolo/version.py b/mmyolo/version.py
index 75c44c7b2..6e4f0e8e3 100644
--- a/mmyolo/version.py
+++ b/mmyolo/version.py
@@ -1,6 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
-__version__ = '0.5.0'
+__version__ = '0.6.0'
from typing import Tuple
diff --git a/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt b/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
new file mode 100644
index 000000000..6ad7d6429
--- /dev/null
+++ b/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/projects/easydeploy/docs/model_convert.md b/projects/easydeploy/docs/model_convert.md
index 062247fc4..9af62599d 100644
--- a/projects/easydeploy/docs/model_convert.md
+++ b/projects/easydeploy/docs/model_convert.md
@@ -1,5 +1,7 @@
# MMYOLO 模型 ONNX 转换
+## 1. 导出后端支持的 ONNX
+
## 环境依赖
- [onnx](https://github.com/onnx/onnx)
@@ -14,9 +16,11 @@
pip install onnx-simplifier
```
+\*\*\* 请确保您在 `MMYOLO` 根目录下运行相关脚本,避免无法找到相关依赖包。\*\*\*
+
## 使用方法
-[模型导出脚本](./projects/easydeploy/tools/export.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
+[模型导出脚本](./projects/easydeploy/tools/export_onnx.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
### 参数介绍:
@@ -28,11 +32,12 @@
- `--device`: 转换模型使用的设备,默认为 `cuda:0`。
- `--simplify`: 是否简化导出的 `onnx` 模型,需要安装 [onnx-simplifier](https://github.com/daquexian/onnx-simplifier),默认关闭。
- `--opset`: 指定导出 `onnx` 的 `opset`,默认为 `11` 。
-- `--backend`: 指定导出 `onnx` 用于的后端 id,`ONNXRuntime`: `1`, `TensorRT8`: `2`, `TensorRT7`: `3`,默认为`1`即 `ONNXRuntime`。
+- `--backend`: 指定导出 `onnx` 用于的后端名称,`ONNXRuntime`: `onnxruntime`, `TensorRT8`: `tensorrt8`, `TensorRT7`: `tensorrt7`,默认为`onnxruntime`即 `ONNXRuntime`。
- `--pre-topk`: 指定导出 `onnx` 的后处理筛选候选框个数阈值,默认为 `1000`。
- `--keep-topk`: 指定导出 `onnx` 的非极大值抑制输出的候选框个数阈值,默认为 `100`。
- `--iou-threshold`: 非极大值抑制中过滤重复候选框的 `iou` 阈值,默认为 `0.65`。
- `--score-threshold`: 非极大值抑制中过滤候选框得分的阈值,默认为 `0.25`。
+- `--model-only`: 指定仅导出模型 backbone + neck, 不包含后处理,默认关闭。
例子:
@@ -53,4 +58,99 @@ python ./projects/easydeploy/tools/export.py \
--score-threshold 0.25
```
-然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等
+然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等。
+
+`MMYOLO` 目前支持 `TensorRT8`, `TensorRT7`, `ONNXRuntime` 后端的端到端模型转换,目前仅支持静态 shape 模型的导出和转换,动态 batch 或动态长宽的模型端到端转换会在未来继续支持。
+
+端到端转换得到的 `onnx` 模型输入输出如图:
+
+
+

+
+

+
 +
+ YOLOv7-l-P5 model structure
YOLOv7-l-P5 model structure
 -performance
+YOLOv8 performance
-performance
+YOLOv8 performance
 +
+ \n",
+ "
\n",
+ "  \n",
+ " \n",
+ "
\n",
+ " \n",
+ "  \n",
+ "
\n",
+ "  \n",
+ "
\n",
+ "  \n",
+ "
\n",
+ "  \n",
+ "
\n",
+ "  \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ " \n",
+ "
\n",
+ "