![]()
Enforce the output format (JSON Schema, Regex etc) of a language model
![]()
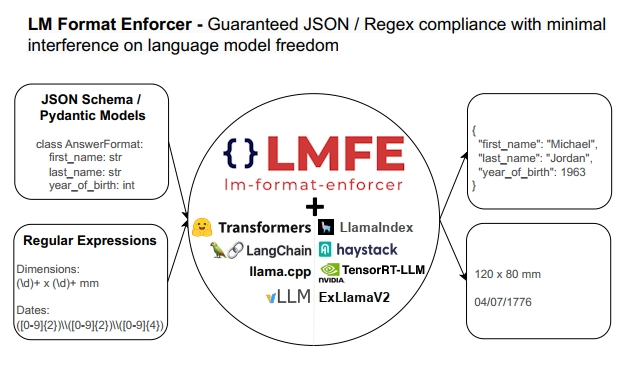
Language models are able to generate text, but when requiring a precise output format, they do not always perform as instructed. Various prompt engineering techniques have been introduced to improve the robustness of the generated text, but they are not always sufficient. This project solves the issues by filtering the tokens that the language model is allowed to generate at every timestep, thus ensuring that the output format is respected, while minimizing the limitations on the language model.
pip install lm-format-enforcer
# Requirements if running from Google Colab with a T4 GPU.
!pip install transformers torch lm-format-enforcer huggingface_hub optimum
!pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
from pydantic import BaseModel
from lmformatenforcer import JsonSchemaParser
from lmformatenforcer.integrations.transformers import build_transformers_prefix_allowed_tokens_fn
from transformers import pipeline
class AnswerFormat(BaseModel):
first_name: str
last_name: str
year_of_birth: int
num_seasons_in_nba: int
# Create a transformers pipeline
hf_pipeline = pipeline('text-generation', model='TheBloke/Llama-2-7b-Chat-GPTQ', device_map='auto')
prompt = f'Here is information about Michael Jordan in the following json schema: {AnswerFormat.schema_json()} :\n'
# Create a character level parser and build a transformers prefix function from it
parser = JsonSchemaParser(AnswerFormat.schema())
prefix_function = build_transformers_prefix_allowed_tokens_fn(hf_pipeline.tokenizer, parser)
# Call the pipeline with the prefix function
output_dict = hf_pipeline(prompt, prefix_allowed_tokens_fn=prefix_function)
# Extract the results
result = output_dict[0]['generated_text'][len(prompt):]
print(result)
# {'first_name': 'Michael', 'last_name': 'Jordan', 'year_of_birth': 1963, 'num_seasons_in_nba': 15}- Works with any Python language model and tokenizer. Already supports transformers, LangChain, LlamaIndex, llama.cpp, vLLM, Haystack, NVIDIA TensorRT-LLM and ExLlamaV2.
- Supports batched generation and beam searches - each input / beam can have different tokens filtered at every timestep
- Supports JSON Schema, JSON Mode (schemaless) and Regular Expression formats
- Supports both required and optional fields in JSON schemas
- Supports nested fields, arrays and dictionaries in JSON schemas
- Gives the language model freedom to control whitespacing and field ordering in JSON schemas, reducing hallucinations.
- Does not modify the high level loop of transformers API, so can be used in any scenario.
| Capability | LM Format Enforcer | Guidance | Jsonformer | Outlines |
|---|---|---|---|---|
| Regular Expressions | ✅ | ✅ | ❌ | ✅ |
| JSON Schema | ✅ | 🟡 (Partial conversion is possible) | ✅ | ✅ |
| Batched Generation | ✅ | ❌ | ❌ | ✅ |
| Beam Search | ✅ | ❌ | ❌ | ✅ |
| Integrates into existing pipelines | ✅ | ❌ | ❌ | ✅ |
| Optional JSON Fields | ✅ | ❌ | ❌ | ❌ |
| LLM Controls JSON field ordering and whitespace | ✅ | ❌ | ❌ | ❌ |
| JSON Schema with recursive classes | ✅ | ❌ | ✅ | ❌ |
| Visual model support | ✅ | ✅ | ❌ | ❌ |
Spotted a mistake? Library updated with new capabilities? Open an issue!
We created a Google Colab Notebook which contains a full example of how to use this library to enforce the output format of llama2, including interpreting the intermediate results. The notebook can run on a free GPU-backed runtime in Colab.
You can also view the notebook in GitHub.
For the different ways to integrate with huggingface transformers, see the unit tests.
LM Format Enforcer is integrated into the vLLM inference server. vLLM includes an OpenAI compatible server with added capabilities that allow using LM Format Enforcer without writing custom inference code.
Use LM Format Enforcer with the vLLM OpenAI Server either by adding the vLLM command line parameter:
python -m vllm.entrypoints.openai.api_server \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--guided-decoding-backend lm-format-enforcer
Or on a per-request basis, by adding the guided_decoding_backend parameter to the request together with the guided decoding parameters:
completion = client.chat.completions.create(
model="mistralai/Mistral-7B-Instruct-v0.2",
messages=[
{"role": "user", "content": "Classify this sentiment: LMFE is wonderful!"}
],
extra_body={
"guided_regex": "[Pp]ositive|[Nn]egative",
"guided_decoding_backend": "lm-format-enforcer"
}
)
Json schema and choice decoding also supported via guided_json and guided_choice extra parameters.
The library works by combining a character level parser and a tokenizer prefix tree into a smart token filtering mechanism.

Parsing a string into any kind of formatter can be looked at as an implicit tree structure - at any moment in the parsing process, there is a set of allowed next characters, and if any of them are selected, there is a new set of allowed next characters, and so on.
CharacterLevelParser is an interface for parsing according to this implicit structure. add_character() and get_allowed_characters() can be seen as tree traversal methods.
There are several implementations of this interface:
JsonSchemaParser- parses according to a json schema (or pure json output -JsonSchemaParser(None) will result in any json object allowed).StringParser- forces an exact string (used mainly for diagnostics)RegexParser- parses according to a regular expression. Note that this cannot use the built in python regex and uses a manually implemented one (via the interegular library), so it doesn't cover 100% of the regex standard.
Given a tokenizer used by a certain language model, we can build a prefix tree of all the tokens that the language model can generate. This is done by generating all possible sequences of tokens, and adding them to the tree.
See TokenizerPrefixTree
Given a character level parser and a tokenizer prefix tree, we can elegantly and efficiently filter the tokens that the language model is allowed to generate at the next timestep:
We only traverse the characters that are in BOTH the character level parsing node and the tokenizer prefix tree node. This allows us to find all of the tokens (including complex subword tokens such as "," which are critical in JSON parsing).
We do this recursively on both trees and return all of the allowed tokens. When the language model generates a token, we advance the character level parser according to the new characters, ready to filter the next timestep.
This is not the first library to enforce the output format of a language model. However, other similar libraries (such as Guidance, JsonFormer and Outlines) enforce an exact output format. This means that the language model is not allowed to control whitespacing, field optionality and field ordering (in the JSON usecase). While this seems inconsequencial to humans, it means that the language model may not be generating the JSON formats that it "wants to" generate, and could put its internal states in a suboptimal value, reducing the quality of the output in later timesteps.
This forces language model users to know the details of the language model they are using (for example - were JSONs minified before pretraining?) and modify the libraries to generate the precise format.
We avoid this problem by scanning potential next tokens and allowing any token sequence that will be parsed into the output format. This means that the language model can control all of these aspects, and output the token sequence that matches its' style in the most natural way, without requiring the developer to know the details.
Using this library guarantees that the output will match the format, but it does not guarantee that the output will be semantically correct. Forcing the language model to conform to a certain output may lead to increased hallucinations. Guiding the model via prompt engineering is still likely to improve results.
In order to help you understand the aggressiveness caused by the format enforcement, if you pass output_scores=True and return_dict_in_generate=True in the kwargs to generate_enforced() (these are existing optional parameters in the transformers library), you will also get a token-by-token dataframe showing which token was selected, its score, and what was the token that would have been chosen if the format enforcement was not applied. If you see that the format enforcer forced the language model to select tokens with very low weights, it is a likely contributor to the poor results. Try modifying the prompt to guide the language model to not force the format enforcer to be so aggressive.
Example using the regular expression format Michael Jordan was Born in (\d)+.
| idx | generated_token | generated_token_idx | generated_score | leading_token | leading_token_idx | leading_score |
|---|---|---|---|---|---|---|
| 0 | ▁ | 29871 | 1.000000 | ▁ | 29871 | 1.000000 |
| 1 | Michael | 24083 | 0.000027 | ▁Sure | 18585 | 0.959473 |
| 2 | ▁Jordan | 18284 | 1.000000 | ▁Jordan | 18284 | 1.000000 |
| 3 | ▁was | 471 | 1.000000 | ▁was | 471 | 1.000000 |
| 4 | ▁Born | 19298 | 0.000008 | ▁born | 6345 | 1.000000 |
| 5 | ▁in | 297 | 0.994629 | ▁in | 297 | 0.994629 |
| 6 | ▁ | 29871 | 0.982422 | ▁ | 29871 | 0.982422 |
| 7 | 1 | 29896 | 1.000000 | 1 | 29896 | 1.000000 |
| 8 | 9 | 29929 | 1.000000 | 9 | 29929 | 1.000000 |
| 9 | 6 | 29953 | 1.000000 | 6 | 29953 | 1.000000 |
| 10 | 3 | 29941 | 1.000000 | 3 | 29941 | 1.000000 |
| 11 | . | 29889 | 0.999512 | . | 29889 | 0.999512 |
| 12 | </s> |
2 | 0.981445 | </s> |
2 | 0.981445 |
You can see that the model "wanted" to start the answer using Sure, but the format enforcer forced it to use Michael - there was a big gap in token 1. Afterwards, almost all of the leading scores are all within the allowed token set, meaning the model likely did not hallucinate due to the token forcing. The only exception was timestep 4 - " Born" was forced while the LLM wanted to choose "born". This is a hint for the prompt engineer, to change the prompt to use a lowercase b instead.
LM Format Enforcer makes use of several heuristics to avoid edge cases that may happen with LLM's generating structure outputs. There are two ways to control these heuristics:
There are several environment variables that can be set, that affect the operation of the library. This method is useful when you don't want to modify the code, for example when using the library through the vLLM OpenAI server.
LMFE_MAX_CONSECUTIVE_WHITESPACES- How many consecutive whitespaces are allowed when parsing JsonSchemaObjects. Default: 12.LMFE_STRICT_JSON_FIELD_ORDER- Should the JsonSchemaParser force the properties to appear in the same order as they appear in the 'required' list of the JsonSchema? (Note: this is consistent with the order of declaration in Pydantic models). Default: False.LMFE_MAX_JSON_ARRAY_LENGTH- What is the maximal JSON array length, if not specified by the schema. Helps LLM Avoid infinite loops. Default: 20.
When using the library through code, any CharacterLevelParser (JsonSchemaParser, RegexParser etc) constructor receives an optional CharacterLevelParserConfig object.
Therefore, to configure the heuristics of a single parser, instantiate a CharacterLevelParserConfig object, modify its values and pass it to the CharacterLevelParser's constructor.
- LM Format Enforcer requires a python API to process the output logits of the language model. This means that until the APIs are extended, it can not be used with OpenAI ChatGPT and similar API based solutions.
- Regular expression syntax is not 100% supported. See interegular for more details.
- LM Format Enforcer Regex Parser can only generate characters that exist in the tokenizer vocabulary. This may be solved in a later version, see the issue on GitHub.
See CONTRIBUTORS.md for a list of contributers.