diff --git a/README.md b/README.md
index 3ee8633858c3c3..fa665f808054b3 100644
--- a/README.md
+++ b/README.md
@@ -397,7 +397,7 @@ Current number of checkpoints: ** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/README_es.md b/README_es.md
index c1a029c7f352e1..dfed9033276844 100644
--- a/README_es.md
+++ b/README_es.md
@@ -372,7 +372,7 @@ Número actual de puntos de control: ** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/README_hd.md b/README_hd.md
index 43d8295a4f4423..636d02b99a1e44 100644
--- a/README_hd.md
+++ b/README_hd.md
@@ -346,7 +346,7 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (दक्षिण चीन प्रौद्योगिकी विश्वविद्यालय से) साथ में कागज [LiLT: एक सरल लेकिन प्रभावी भाषा-स्वतंत्र लेआउट ट्रांसफार्मर संरचित दस्तावेज़ समझ के लिए](https://arxiv.org/abs/2202.13669) जियापेंग वांग, लियानवेन जिन, काई डिंग द्वारा पोस्ट किया गया।
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI से) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. द्वाराअनुसंधान पत्र [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) के साथ जारी किया गया
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI से) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. द्वाराअनुसंधान पत्र [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) के साथ जारी किया गया
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison से) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. द्वाराअनुसंधान पत्र [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) के साथ जारी किया गया
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison से) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. द्वाराअनुसंधान पत्र [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) के साथ जारी किया गया
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (मैंडी गुओ, जोशुआ आइंस्ली, डेविड यूथस, सैंटियागो ओंटानन, जियानमो नि, यूं-हुआन सुंग, यिनफेई यांग द्वारा पोस्ट किया गया।
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (स्टूडियो औसिया से) साथ में पेपर [LUKE: डीप कॉन्टेक्स्टुअलाइज्ड एंटिटी रिप्रेजेंटेशन विद एंटिटी-अवेयर सेल्फ-अटेंशन](https ://arxiv.org/abs/2010.01057) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto द्वारा।
diff --git a/README_ja.md b/README_ja.md
index b811aaf1d20afd..03b2f84b038cd7 100644
--- a/README_ja.md
+++ b/README_ja.md
@@ -406,7 +406,7 @@ Flax、PyTorch、TensorFlowをcondaでインストールする方法は、それ
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI から) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. から公開された研究論文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI から) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom.. から公開された研究論文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744)
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison から) Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee. から公開された研究論文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
diff --git a/README_ko.md b/README_ko.md
index c4d72235f34c00..3cfe66be056d9a 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -321,7 +321,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology 에서) Jiapeng Wang, Lianwen Jin, Kai Ding 의 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 논문과 함께 발표했습니다.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.의 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)논문과 함께 발표했습니다.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (The FAIR team of Meta AI 에서 제공)은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..의 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX)논문과 함께 발표했습니다.
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison 에서 제공)은 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.의 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744)논문과 함께 발표했습니다.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (Microsoft Research & University of Wisconsin-Madison 에서 제공)은 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.의 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485)논문과 함께 발표했습니다.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI 에서) Iz Beltagy, Matthew E. Peters, Arman Cohan 의 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 논문과 함께 발표했습니다.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI 에서) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 의 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 논문과 함께 발표했습니다.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia 에서) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 의 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 논문과 함께 발표했습니다.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index dac4d1cb68c9a6..a555d8d05dc589 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -345,7 +345,7 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (来自 South China University of Technology) 伴随论文 [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) 由 Jiapeng Wang, Lianwen Jin, Kai Ding 发布。
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (来自 The FAIR team of Meta AI) 伴随论文 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) 由 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample 发布。
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (来自 The FAIR team of Meta AI) 伴随论文 [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) 由 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom. 发布。
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (来自 Microsoft Research & University of Wisconsin-Madison) 伴随论文 [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) 由 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee 发布。
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (来自 Microsoft Research & University of Wisconsin-Madison) 伴随论文 [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) 由 Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee 发布。
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (来自 AllenAI) 伴随论文 [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) 由 Iz Beltagy, Matthew E. Peters, Arman Cohan 发布。
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (来自 Google AI) released 伴随论文 [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) 由 Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang 发布。
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (来自 Studio Ousia) 伴随论文 [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) 由 Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 8aaeda231d39f0..02eca0c3e7026e 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -357,7 +357,7 @@ conda install -c huggingface transformers
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[LLaMA](https://huggingface.co/docs/transformers/model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
1. **[Llama2](https://huggingface.co/docs/transformers/model_doc/llama2)** (from The FAIR team of Meta AI) released with the paper [Llama2: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/XXX) by Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushka rMishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom..
-1. **[Llava](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+1. **[LLaVa](https://huggingface.co/docs/transformers/main/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index 2a055e56661ab8..89a80df5b83787 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -169,7 +169,7 @@ Flax), PyTorch, and/or TensorFlow.
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
-| [Llava](model_doc/llava) | ✅ | ❌ | ❌ |
+| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/llava.md b/docs/source/en/model_doc/llava.md
index c21438dc115521..ee7d9bbd1af9be 100644
--- a/docs/source/en/model_doc/llava.md
+++ b/docs/source/en/model_doc/llava.md
@@ -14,19 +14,27 @@ rendered properly in your Markdown viewer.
-->
-# Llava
+# LLaVa
## Overview
-Llava is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
+LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
-The Llava model was proposed in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
The abstract from the paper is the following:
*Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ∼1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available*
-Tips:
+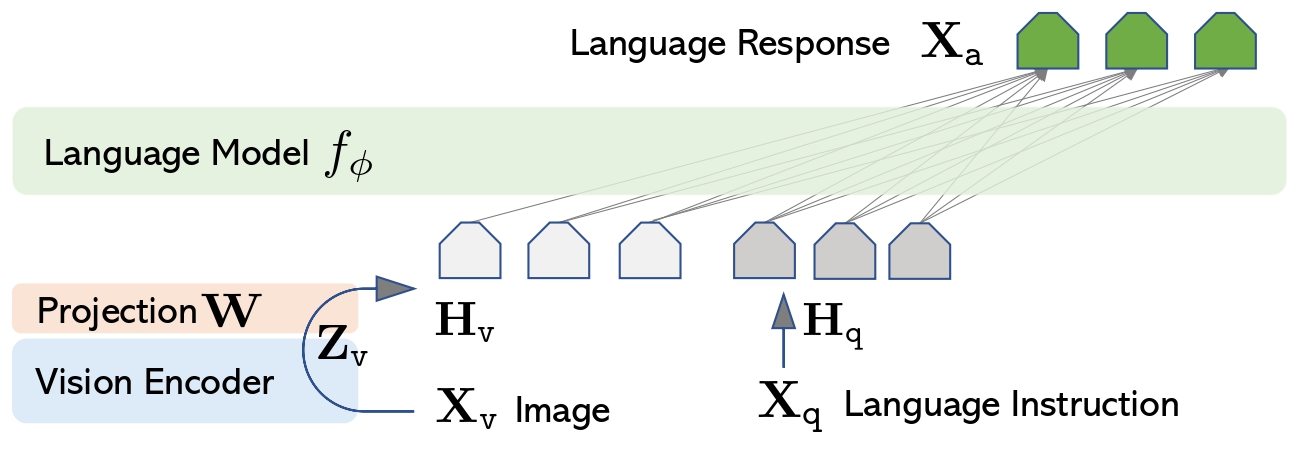 +
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
@@ -44,15 +52,20 @@ For multiple turns conversation:
"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
```
-This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
-The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
-
-Check out also this [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance.
-
### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
+- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
+
+
## LlavaConfig
[[autodoc]] LlavaConfig
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 2094752fdd73d8..8483b6e8e89e88 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -577,7 +577,7 @@
("lilt", "LiLT"),
("llama", "LLaMA"),
("llama2", "Llama2"),
- ("llava", "Llava"),
+ ("llava", "LLaVa"),
("longformer", "Longformer"),
("longt5", "LongT5"),
("luke", "LUKE"),
diff --git a/src/transformers/models/llava/modeling_llava.py b/src/transformers/models/llava/modeling_llava.py
index 200f46e5389078..56306757f4a150 100644
--- a/src/transformers/models/llava/modeling_llava.py
+++ b/src/transformers/models/llava/modeling_llava.py
@@ -270,22 +270,22 @@ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None, pad_to_m
def _merge_input_ids_with_image_features(
self, image_features, inputs_embeds, input_ids, attention_mask, position_ids
):
- nb_images, image_hidden_dim, embed_dim = image_features.shape
+ num_images, num_image_patches, embed_dim = image_features.shape
batch_size, sequence_length = input_ids.shape
left_padding = not torch.sum(input_ids[:, -1] == torch.tensor(self.pad_token_id))
- # 1. Create a mask to know where image tokens are
- image_token_mask = input_ids == self.config.image_token_index
- num_image_tokens = torch.sum(image_token_mask, dim=-1)
+ # 1. Create a mask to know where special image tokens are
+ special_image_token_mask = input_ids == self.config.image_token_index
+ num_special_image_tokens = torch.sum(special_image_token_mask, dim=-1)
# Compute the maximum embed dimension
- max_embed_dim = (num_image_tokens.max() * (image_hidden_dim - 1)) + sequence_length
+ max_embed_dim = (num_special_image_tokens.max() * (num_image_patches - 1)) + sequence_length
batch_indices, non_image_indices = torch.where(input_ids != self.config.image_token_index)
# 2. Compute the positions where text should be written
# Calculate new positions for text tokens in merged image-text sequence.
- # `image_token_mask` identifies image tokens. Each image token will be replaced by `nb_text_tokens_per_images - 1` text tokens.
+ # `special_image_token_mask` identifies image tokens. Each image token will be replaced by `nb_text_tokens_per_images - 1` text tokens.
# `torch.cumsum` computes how each image token shifts subsequent text token positions.
# - 1 to adjust for zero-based indexing, as `cumsum` inherently increases indices by one.
- new_token_positions = torch.cumsum((image_token_mask * (image_hidden_dim - 1) + 1), -1) - 1
+ new_token_positions = torch.cumsum((special_image_token_mask * (num_image_patches - 1) + 1), -1) - 1
nb_image_pad = max_embed_dim - 1 - new_token_positions[:, -1]
if left_padding:
new_token_positions += nb_image_pad[:, None] # offset for left padding
@@ -310,8 +310,8 @@ def _merge_input_ids_with_image_features(
if image_to_overwrite.sum() != image_features.shape[:-1].numel():
raise ValueError(
- f"The input provided to the model are wrong. The number of image tokens is {torch.sum(image_token_mask)} while"
- f" the number of image given to the model is {nb_images}. This prevents correct indexing and breaks batch generation."
+ f"The input provided to the model are wrong. The number of image tokens is {torch.sum(special_image_token_mask)} while"
+ f" the number of image given to the model is {num_images}. This prevents correct indexing and breaks batch generation."
)
final_embedding[image_to_overwrite] = image_features.contiguous().reshape(-1, embed_dim)
@@ -353,8 +353,8 @@ def forward(
>>> import requests
>>> from transformers import AutoProcessor, LlavaForConditionalGeneration
- >>> model = LlavaForConditionalGeneration.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> processor = AutoProcessor.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+ >>> model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf")
+ >>> processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> prompt = "\nUSER: What's the content of the image?\nASSISTANT:"
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
diff --git a/src/transformers/models/llava/processing_llava.py b/src/transformers/models/llava/processing_llava.py
index 373fccbce19286..1ba1b30e65906b 100644
--- a/src/transformers/models/llava/processing_llava.py
+++ b/src/transformers/models/llava/processing_llava.py
@@ -17,8 +17,7 @@
"""
-import warnings
-from typing import Callable, List, Optional, Union
+from typing import List, Optional, Union
from ...feature_extraction_utils import BatchFeature
from ...image_utils import ImageInput
@@ -45,23 +44,7 @@ class LlavaProcessor(ProcessorMixin):
image_processor_class = "CLIPImageProcessor"
tokenizer_class = ("LlamaTokenizer", "LlamaTokenizerFast")
- # Copied from transformers.models.clip.processing_clip.CLIPProcessor.__init__
- def __init__(self, image_processor=None, tokenizer=None, **kwargs):
- feature_extractor = None
- if "feature_extractor" in kwargs:
- warnings.warn(
- "The `feature_extractor` argument is deprecated and will be removed in v5, use `image_processor`"
- " instead.",
- FutureWarning,
- )
- feature_extractor = kwargs.pop("feature_extractor")
-
- image_processor = image_processor if image_processor is not None else feature_extractor
- if image_processor is None:
- raise ValueError("You need to specify an `image_processor`.")
- if tokenizer is None:
- raise ValueError("You need to specify a `tokenizer`.")
-
+ def __init__(self, image_processor=None, tokenizer=None):
super().__init__(image_processor, tokenizer)
def __call__(
@@ -70,7 +53,6 @@ def __call__(
images: ImageInput = None,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
- transform: Callable = None,
max_length=None,
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
) -> BatchFeature:
@@ -103,10 +85,6 @@ def __call__(
Maximum length of the returned list and optionally padding length (see above).
truncation (`bool`, *optional*):
Activates truncation to cut input sequences longer than `max_length` to `max_length`.
- transform (`Callable`, *optional*):
- A custom transform function that accepts a single image can be passed for training. For example,
- `torchvision.Compose` can be used to compose multiple functions. If `None` a preset inference-specific
- set of transforms will be applied to the images
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors of a particular framework. Acceptable values are:
@@ -125,9 +103,7 @@ def __call__(
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
"""
if images is not None:
- pixel_values = self.image_processor(images, transform=transform, return_tensors=return_tensors)[
- "pixel_values"
- ]
+ pixel_values = self.image_processor(images, return_tensors=return_tensors)["pixel_values"]
else:
pixel_values = None
text_inputs = self.tokenizer(
+
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
@@ -44,15 +52,20 @@ For multiple turns conversation:
"USER: \nASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
```
-This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
-The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
-
-Check out also this [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance.
-
### Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
+- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
+
+
## LlavaConfig
[[autodoc]] LlavaConfig
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 2094752fdd73d8..8483b6e8e89e88 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -577,7 +577,7 @@
("lilt", "LiLT"),
("llama", "LLaMA"),
("llama2", "Llama2"),
- ("llava", "Llava"),
+ ("llava", "LLaVa"),
("longformer", "Longformer"),
("longt5", "LongT5"),
("luke", "LUKE"),
diff --git a/src/transformers/models/llava/modeling_llava.py b/src/transformers/models/llava/modeling_llava.py
index 200f46e5389078..56306757f4a150 100644
--- a/src/transformers/models/llava/modeling_llava.py
+++ b/src/transformers/models/llava/modeling_llava.py
@@ -270,22 +270,22 @@ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None, pad_to_m
def _merge_input_ids_with_image_features(
self, image_features, inputs_embeds, input_ids, attention_mask, position_ids
):
- nb_images, image_hidden_dim, embed_dim = image_features.shape
+ num_images, num_image_patches, embed_dim = image_features.shape
batch_size, sequence_length = input_ids.shape
left_padding = not torch.sum(input_ids[:, -1] == torch.tensor(self.pad_token_id))
- # 1. Create a mask to know where image tokens are
- image_token_mask = input_ids == self.config.image_token_index
- num_image_tokens = torch.sum(image_token_mask, dim=-1)
+ # 1. Create a mask to know where special image tokens are
+ special_image_token_mask = input_ids == self.config.image_token_index
+ num_special_image_tokens = torch.sum(special_image_token_mask, dim=-1)
# Compute the maximum embed dimension
- max_embed_dim = (num_image_tokens.max() * (image_hidden_dim - 1)) + sequence_length
+ max_embed_dim = (num_special_image_tokens.max() * (num_image_patches - 1)) + sequence_length
batch_indices, non_image_indices = torch.where(input_ids != self.config.image_token_index)
# 2. Compute the positions where text should be written
# Calculate new positions for text tokens in merged image-text sequence.
- # `image_token_mask` identifies image tokens. Each image token will be replaced by `nb_text_tokens_per_images - 1` text tokens.
+ # `special_image_token_mask` identifies image tokens. Each image token will be replaced by `nb_text_tokens_per_images - 1` text tokens.
# `torch.cumsum` computes how each image token shifts subsequent text token positions.
# - 1 to adjust for zero-based indexing, as `cumsum` inherently increases indices by one.
- new_token_positions = torch.cumsum((image_token_mask * (image_hidden_dim - 1) + 1), -1) - 1
+ new_token_positions = torch.cumsum((special_image_token_mask * (num_image_patches - 1) + 1), -1) - 1
nb_image_pad = max_embed_dim - 1 - new_token_positions[:, -1]
if left_padding:
new_token_positions += nb_image_pad[:, None] # offset for left padding
@@ -310,8 +310,8 @@ def _merge_input_ids_with_image_features(
if image_to_overwrite.sum() != image_features.shape[:-1].numel():
raise ValueError(
- f"The input provided to the model are wrong. The number of image tokens is {torch.sum(image_token_mask)} while"
- f" the number of image given to the model is {nb_images}. This prevents correct indexing and breaks batch generation."
+ f"The input provided to the model are wrong. The number of image tokens is {torch.sum(special_image_token_mask)} while"
+ f" the number of image given to the model is {num_images}. This prevents correct indexing and breaks batch generation."
)
final_embedding[image_to_overwrite] = image_features.contiguous().reshape(-1, embed_dim)
@@ -353,8 +353,8 @@ def forward(
>>> import requests
>>> from transformers import AutoProcessor, LlavaForConditionalGeneration
- >>> model = LlavaForConditionalGeneration.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
- >>> processor = AutoProcessor.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+ >>> model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf")
+ >>> processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
>>> prompt = "\nUSER: What's the content of the image?\nASSISTANT:"
>>> url = "https://www.ilankelman.org/stopsigns/australia.jpg"
diff --git a/src/transformers/models/llava/processing_llava.py b/src/transformers/models/llava/processing_llava.py
index 373fccbce19286..1ba1b30e65906b 100644
--- a/src/transformers/models/llava/processing_llava.py
+++ b/src/transformers/models/llava/processing_llava.py
@@ -17,8 +17,7 @@
"""
-import warnings
-from typing import Callable, List, Optional, Union
+from typing import List, Optional, Union
from ...feature_extraction_utils import BatchFeature
from ...image_utils import ImageInput
@@ -45,23 +44,7 @@ class LlavaProcessor(ProcessorMixin):
image_processor_class = "CLIPImageProcessor"
tokenizer_class = ("LlamaTokenizer", "LlamaTokenizerFast")
- # Copied from transformers.models.clip.processing_clip.CLIPProcessor.__init__
- def __init__(self, image_processor=None, tokenizer=None, **kwargs):
- feature_extractor = None
- if "feature_extractor" in kwargs:
- warnings.warn(
- "The `feature_extractor` argument is deprecated and will be removed in v5, use `image_processor`"
- " instead.",
- FutureWarning,
- )
- feature_extractor = kwargs.pop("feature_extractor")
-
- image_processor = image_processor if image_processor is not None else feature_extractor
- if image_processor is None:
- raise ValueError("You need to specify an `image_processor`.")
- if tokenizer is None:
- raise ValueError("You need to specify a `tokenizer`.")
-
+ def __init__(self, image_processor=None, tokenizer=None):
super().__init__(image_processor, tokenizer)
def __call__(
@@ -70,7 +53,6 @@ def __call__(
images: ImageInput = None,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = None,
- transform: Callable = None,
max_length=None,
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
) -> BatchFeature:
@@ -103,10 +85,6 @@ def __call__(
Maximum length of the returned list and optionally padding length (see above).
truncation (`bool`, *optional*):
Activates truncation to cut input sequences longer than `max_length` to `max_length`.
- transform (`Callable`, *optional*):
- A custom transform function that accepts a single image can be passed for training. For example,
- `torchvision.Compose` can be used to compose multiple functions. If `None` a preset inference-specific
- set of transforms will be applied to the images
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors of a particular framework. Acceptable values are:
@@ -125,9 +103,7 @@ def __call__(
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
"""
if images is not None:
- pixel_values = self.image_processor(images, transform=transform, return_tensors=return_tensors)[
- "pixel_values"
- ]
+ pixel_values = self.image_processor(images, return_tensors=return_tensors)["pixel_values"]
else:
pixel_values = None
text_inputs = self.tokenizer(