
- 다양한 입력으로부터 데이터를 읽어서 제공하는 인터페이스 입니다.
- 플랫 파일 - csv, txt
- XML, Json
- Database
- Message Queuing 서비스
- Custom reader
- 다수의 구현체들이 ItemReader와 ItemStream 인터페이스를 동시에 구현하고 있습니다.
- ItemStream은 파일 스트림 연결 종료, DB 커넥션 연결 종료 등의 장치 초기화 등의 작업에 사용됩니다.
- ExecutionContext에 read와 관련된 여러 가지 상태 정보를 저장해두고 재시작 시 참조됩니다.
- ChunkOrientedTasklet 실행 시 필수적 요소로 설정해야 합니다.
- T read()
- 입력 데이터를 읽고 다음 데이터로 이동합니다.
- 아이템 하나를 리턴하며 더 이상 아이템이 없는 경우 null 리턴합니다.
- 아이템 하나는 파일의 한 줄, DB의 한 row, XML 파일에서 하나의 엘리먼트를 의미합니다.
- 더 이상 처리해야 할 item이 없어도 예외가 발생하지 않고 itemProcessor와 같은 다음 단계로 넘어갑니다.
- <I,O>Chunk
- I : Reader가 읽는 데이터 타입
- O : Writer가 받은 데이터 타입

위와 같이 다양한 구현체들을 제공하고 있습니다.
- Json 데이터의 파싱과 바인딩을 JsonObjectReader 인터페이스 구현체에 위임하여 처리하는 인터페이스 입니다.
- 2가지 구현체를 제공합니다.
- JacksonJsonObjectReader
- GsonJsonObjectReader

@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step1")
.<Customer,Customer>chunk(3)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
return new JsonItemReaderBuilder<Customer>()
.name("jsonReader") // ExecutionContext 내에서 구분하기 위한 key로 저장되는 이름 설정
.resource(new ClassPathResource("customer.json")) // 읽을 리소스 위치
.jsonObjectReader(new JacksonJsonObjectReader<>(Customer.class)) // 구현체 설정
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println("item = " + item);
}
};
}
}배치 애플리케이션은 실시간적 처리가 어려운 대용량 데이터를 다루며 이때 DB I/O의 성능 문제와 메모리 자원의 효율성 문제를 해결할 수 있어야 합니다.
스프링 배치에서는 대용량 데이터 처리를 위한 두 가지 해결방안을 제시하고 있습니다.
- JDBC ResultSet의 기본 메커니즘을 사용합니다.
- 현재 행에서 커서를 유지하며 다음 데이터를 호출하면 다음 행으로 커서를 이동하며 데이터 반환이 이뤄지는 Streaming 방식의 I/O 입니다.
- ResultSet이 open될 때마다 next 메서드가 호출되어 DataBase의 데이터 하나가 반환되고 객체와 매핑이 이뤄집니다.
- DB Connection이 연결되면 배치 처리가 완료될 때까지 Connection이 유지되기 때문에 DB와 SocketTimeout을 충분히 큰 값으로 설정해야 합니다.
- 모든 결과를 메모리에 할당하기 때문에 메모리 사용량이 많아지는 단점이 있습니다.
- Connection 연결 유지 시간과 메모리 공간이 충분하다면 대량의 데이터 처리에 적합할 수 있습니다.(fetchSize 조절로 한번에 가져올 수도 있습니다.)
- 페이징 단위로 데이터를 조회하는 방식으로 Page Size만큼 한 번에 메모리로 가져온 다음 한 개씩 데이터를 읽는 방식입니다.
- 한 페이지를 읽을때마다 커넥션을 맺고 끊기를 반복하기 때문에 대량의 데이터를 처리하더라도 SocketTimeout 예외가 거의 발생하지 않습니다.
- 시작 행 번호를 지정하고 페이지에 반환시키고자 하는 행의 수를 지정한 후 사용합니다.(offest, limit)
- 페이징 단위의 결과만 메모리에 할당하기 때문에 메모리 사용량이 적어지는 장점이 있습니다.
- 커넥션 유지 시간이 길지 않고 메모리를 효율적으로 사용해야 하는 데이터 처리에 적합합니다.

- Cursor 기반
- 기본적으로 데이터를 하나씩 처리(fetchSize를 이용해서 한번에 처리가 가능하긴 함)
- 모든 데이터를 처리할 때까지 커넥션 유지
- 모든 결과를 메모리에 할당
- Paging 기반
- Page Size만큼의 데이터를 한번에 처리
- Page Size만큼의 처리를 할 때마다 커넥션을 맺고 끊음
- 페이징 단위 결과만 메모리에 할당
Cursor 기반의 JDBC 구현체 로서 ResultSet과 함께 사용되며 Datasource에서 connection을 얻어와서 SQL을 실행합니다.
Thread 안정성을 보장하지 않기 때문에 멀티 스레드 환경에서 사용할 경우 동시성 이슈가 발생하지 않도록 동기화 처리를 별도로 진행 해야 합니다.

- 커서를 오픈하면서 DB 커넥션 연결, PrepareStatement 생성, ResultSet 생성 등 준비 작업을 합니다.
- JdbcCursorItemReader에서 데이터를 한건씩 가져오는 작업을 Chunk Size만큼 반복합니다.
- 모든 배치 작업이 완료되고 더이상 읽을 데이터가 없어지면 커넥션 종료 등 리소스를 해제하고 작업을 종료합니다.

@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
return new JdbcCursorItemReaderBuilder<Customer>()
.name("jdbcCursorItemReader")
.fetchSize(chunkSize)
.sql("select id, name, age from customer where age >= ?")
.beanRowMapper(Customer.class)
.queryArguments(25)
.dataSource(dataSource)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println("item = " + item.toString());
}
};
}
}DB에 Customer 객체를 100개 넣어두고 조건에 맞게 가져와서 출력하는 간단한 예시입니다.
Cursor 기반의 JPA 구현체 로서 EntityManagerFactory 객체가 필요하여 쿼리는 JPQL을 사용합니다.
Spring Batch 4.3버전부터 지원합니다.
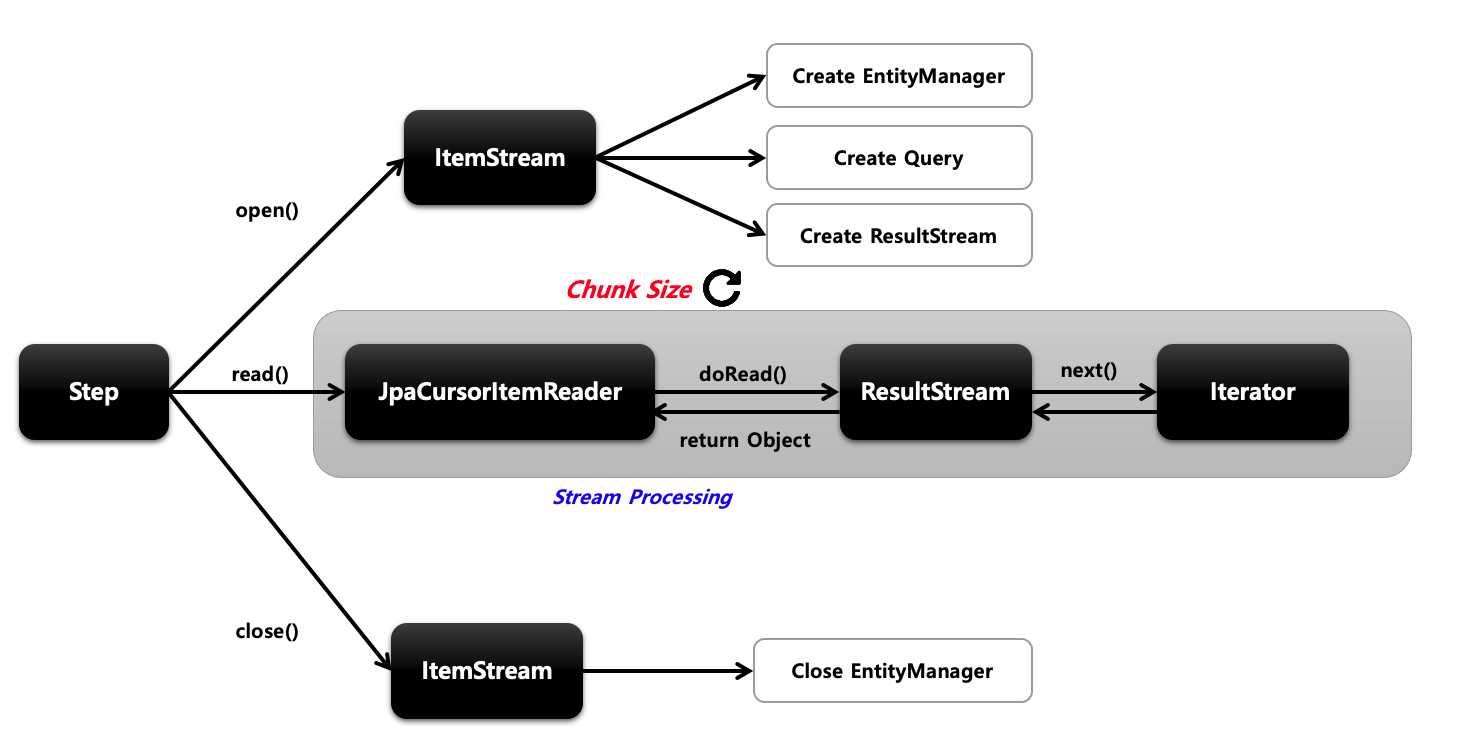
- open하는 과정에서 엔티티 매니저 생성, 작성한 JPQL을 실행시켜서 DB에서 값을 받아와서 ResultStream에 데이터를 담아놓습니다. 실상 open 작업에서 데이터를 가져오는 작업이 다 끝납니다.
- JpaCursorItemReader는 ResultStream에서 이터레이터로 하나씩 데이터를 가져옵니다.
- close에서는 EntityManager만 닫습니다.

@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
HashMap<String, Object> parameters = new HashMap<>();
parameters.put("age",25);
return new JpaCursorItemReaderBuilder<Customer>()
.name("jpaCursorItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("select c from Customer c where age >=:age ") // JPQL -> 테이블명은 첫글자만 대문자
.parameterValues(parameters)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println("item = " + item.toString());
}
};
}
}- Paging 기반의 JDBC 구현체로 쿼리에 시작 행 번호(offset)와 페이지에서 변환할 행수(limit)를 지정해서 SQL을 실행합니다.
- 스프링 배치에서 offset과 limit을 PageSize에 맞게 자동으로 생성해 주며 페이징 단위로 데이터를 조회할 때마다 새로운 쿼리가 실행됩니다.
- 페이지 마다 새로운 쿼리를 실행하기 때문에 페이징 시 결과 데이터의 순서가 보장될 수 있도록 order by 구문이 필수 입니다.
- 멀티 스레드 환경에서 Thread 안정성을 보장 하기 때문에 별도의 동기화 처리가 필요하지 않습니다.
- 쿼리 실행에 필요한 쿼리문을 ItemReader에게 제공하는 클래스입니다.
- 데이터베이스마다 페이징 전략이 다르기 때문에 각 데이터 베이스 유형마다 다른 PaingQueryProvider을 사용하게 되는데 이는 DataSource 설정 값을 보고 자동으로 선택합니다.
- Select, from, sortKey는 필수로 설정해야 합니다.

- open에서 update로 ExecutionContext에 상태정보를 업데이트 합니다.
- JdbcPagingItemReader에서 JdbcTemplate을 이용해 쿼리를 날리고 페이지 사이즈 만큼 데이터를 가져옵니다.(커넥션 얻고 종료)
- 이 과정을 청크 사이즈만큼 반복합니다.(보통 청크 사이즈와 페이징 사이즈를 일치시키는 것을 권장합니다.)
- 더이상 처리할 것이 없으면 종료하게 됩니다.

queryProvider가 제공된다면 위의 빨간 박스 내용은 작성하지 않아도 됩니다.
@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private int chunkSize = 10;
@Bean
public Job helloJob() throws Exception {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() throws Exception {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() throws Exception {
Map<String, Object> parameters = new HashMap<>();
parameters.put("age",25);
return new JdbcPagingItemReaderBuilder<Customer>()
.name("jdbcPagingItemReader")
.pageSize(10)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Customer.class))
.queryProvider(createQueryProvider()) // 쿼리 생성
.parameterValues(parameters) // 파라미터 입력
.build();
}
@Bean
public PagingQueryProvider createQueryProvider() throws Exception {
Map<String, Order> sortKeys = new HashMap<>();
sortKeys.put("id", Order.ASCENDING);
// 쿼리 생성
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource);
queryProvider.setSelectClause("id,name,age"); // select 절
queryProvider.setFromClause("from customer"); // from 절
queryProvider.setWhereClause("where age > :age"); // where 절
queryProvider.setSortKeys(sortKeys); // order by 절
return queryProvider.getObject();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println("item = " + item.toString());
}
};
}
}Paging 기반의 JPA 구현체 로 EntityManagerFactory 객체가 필요하며 쿼리는 JPQL을 사용합니다.

- open에서 엔티티 매니저를 생성합니다.
- JpaPagingItemReader에서 엔티티 매니저로를 사용해 쿼리를 날려 데이터를 가져옵니다.(커넥션 얻고 종료)
- 이 과정을 청크 사이즈 만큼 반복합니다.
- 더이상 읽을 데이터가 없으면 엔티티 매니저를 종료합니다.

@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<Customer, Customer>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<Customer> customItemReader() {
Map<String, Object> parameters = new HashMap<>();
parameters.put("age",25);
return new JpaPagingItemReaderBuilder<Customer>()
.name("jpaPagingItemReader")
.entityManagerFactory(entityManagerFactory)
.pageSize(10)
.queryString("select c from Customer c where age >= :age order by c.id")
.parameterValues(parameters)
.build();
}
@Bean
public ItemWriter<Customer> customItemWriter() {
return items -> {
for (Customer item : items) {
System.out.println("item = " + item.toString());
}
};
}
}이미 존재하는 DAO나 다른 서비스를 ItemReader 안에서 사용하고자 할 때 위임하는 역할을 합니다.
@Slf4j
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private int chunkSize = 10;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("job")
.start(step1())
.incrementer(new RunIdIncrementer())
.build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get("step")
.<String, String>chunk(chunkSize)
.reader(customItemReader())
.writer(customItemWriter())
.build();
}
@Bean
public ItemReader<String> customItemReader() {
ItemReaderAdapter<String> reader = new ItemReaderAdapter<>();
reader.setTargetObject(customerService()); // 클래스 이름
reader.setTargetObject("customRead"); // 메서드 명
return reader;
}
@Bean
public ItemWriter<String> customItemWriter() {
return items -> {
for (String item : items) {
System.out.println("item = " + item.toString());
}
};
}
}ItemReaderAdapter를 이용해서 클래스의 이름과 메서드명을 명시하면 해당 메서드가 Reader의 역할을 하게 됩니다.
SQL 쿼리가 빈 결과를 반환하는 것은 흔한 일입니다.
따라서 Reader가 입력 소스에서 조회를 시도했는데 처음부터 null이 반환되더라도 스프링 배치는 이를 기본으로 평상시 null을 받았을 때와 동일하게 처리합니다.
즉, 스텝이 완료된 것으로 처리하므로 문제 없이 동작하겠지만 이를 알아야 할 때도 있습니다.
이때는 StepListener를 사용하면 됩니다.
@Slf4j
public class EmptySql(){
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution){
if (stepExecution.getReadCount()> 0){
return stepExecution.getExitStatus();
} else{
return ExitStatus.FAILED;
}
}
}
@Bean
public EmptySql EmptySql(){
return new EmptySql();
}
@Bean
public Step skipStep(){
return stepBuilderFactory.get("skipStep")
.<Customer,Customer>chunk(10)
.reader(customerItemReader())
.writer(itemWriter())
.listener(EmptySql())
.build();
}위와 같이 구성하면 입력이 없을 때 FAILED 상태로 끝나 원래 원하던 입력을 확보하고 다시 재실행 할 수 있습니다.
Chunk Size가 50이고 Page Size가 10이라고 가정했을 때, Chunk Size를 채우기 위해 5번의 Read가 발생합니다.
5번의 Read가 발생한 뒤에 itemProcessor로 넘기게 되는데 itemProcessor에서 만약 item의 LazyLoading이 발생한다면 이때 문제가 생깁니다.
이유는 5번의 Read가 발생하는 동안 각각 트랜잭션이 초기화되기 때문입니다.
이 문제는 Page Size와 Chunk Size를 일치시키면 해결할 수 있습니다.
공식적으로는 아직 지원하지 않습니다.
이동욱님이 이를 직접 구현하는 방식에 대해 포스팅 작성한 글을 참고하시면 좋을 것 같습니다.
Test가 Junit4로 되어있어 저는 테스트를 Junit5로 수정해보면서 사용법을 익혔습니다.
이에 관해서는 여기 를 참고하시면 좋을 것 같습니다.