- 상태 필드 : 단순히 값을 저장하기 위한 필드, 경로 탐색의 끝 -> 더이상 . 으로 이어지는게 없음
- 연관 필드 : 연관관계를 위한 필드
- 단일 값 연관 필드 : ManyToOne, OneToOne, 대상이 엔티티, 묵시적 내부 조인, .으로 더 탐색 가능
- 컬렉션 값 연관 필드 : OneToMany, ManyToMany, 대상이 컬렉션, 묵시적 내부 조인, .으로 더 탐색 X이지만 from 절에서 명시적 조인을 통해 별칭으로 더 탐색 가능
join은 성능에 큰 영향을 준다. 묵시적 조인을 사용하게 되면 실무에서 수많은 쿼리중에 찾기도 어렵고 튜닝하기도 만만치 않으므로 사실상 실무에서는 모두 명시적 조인을 사용해야 한다.
- SQL 조인 종류가 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 SQL 한 번에 함께 조회하는 기능
- [LEFT[ OUTER ], INNER] JOIN FETCH
실무에서는 기본적으로 FetchType을 LAZY로 둔다고 했다. Member라는 클래스 안에 team을 Lazy로 다대일 관계로 설정했다고 생각해보자. select 쿼리로 Member을 조회하면 Member 조회쿼리만 나간다.(team은 프록시가 들어가있게 됨) 그리고 Member안에 team에 접근할 때가 되면 그 때 team에 대한 쿼리가 다시 나가고 영속성 컨텍스트에 두고 그걸 가져온다고 배웠다. 이렇게 사용했던 이유는 Member를 조회해서 team은 사용할 일이 거의 없어서 굳이 같이 불러온다면 낭비이기 때문이었다. 하지만 Member을 조회하면서 항상 team을 같이 사용한다면 N + 1 문제가 발생하므로 그냥 Member을 조회하는 김에 같이 한 번에 조회하는 것이 좋은 판단이다. JPQL문은 아래와 같다.
// Lazy 설정대로 프록시가 들어오는 쿼리
select m from Member m
// 한 번에 땡겨오는 쿼리
select m from Member m join fetch m.team
// 나가는 sql문 -> Member와 team을 조인해서 한번에 땡겨온다.
select m.*,t.*
from Member m
join team t
on t.id = m.team_id
// 정리하면, Member을 땡기는데 team까지 땡겨진 Member을(조인한 결과) 조회하고
// m으로 조회하니 Member로 결과를 다룬다고 보면 된다.
List<Member> members =
em.createQuery("select m from Member m join fetch m.team",Member.class)
.getResultList();위에서는 다대일 관계에서 fetch 조인을 설명했다. 단순히 join을 생각해보면 다대일 관계에서 데이터는 문제가 없는데 일대다 관계(컬렉션)에서 join을 하면 데이터가 뻥튀기가 된다. 아래 그림처럼 말이다.

// Team을 조회하는데 Member까지 같이 땡겨진(조인한) 결과를 Team으로 다룬다.
select t from Team t join fetch t.members
select t.*,m.*
from team t
join member m
on t.id=m.team_id
select distinct t from Team t join fetch t.members 위와 같이 쿼리를 날리면 team이 일대다이므로 데이터가 뻥튀기 된다. 즉, 같은 team이 여러개 조회되는 것이다. 중복을 제거하기 위해 SQL에 distinct를 추가해도 데이터가 완전히 똑같이 않으므로 쿼리만으로는 중복이 제거되지 않는다. 그러나 JPA에 distinct는 추가로 애플리케이션에서 중복 제거를 시도한다. 즉, 같은 식별자를 가진 Team 엔티티를 제거해준다. 여기서 눈여겨봐야 할 점은 페이징 API다. DB에서는 distinct로 걸러지지 않았고 애플케이션에서 중복이 제거가 된 것이다. 따라서 DB는 그대로 데이터가 뻥튀기 되어있는 상태인데 여기서 페이징 API를 사용하면 당연히 원하는 대로 작동하지 않는다.
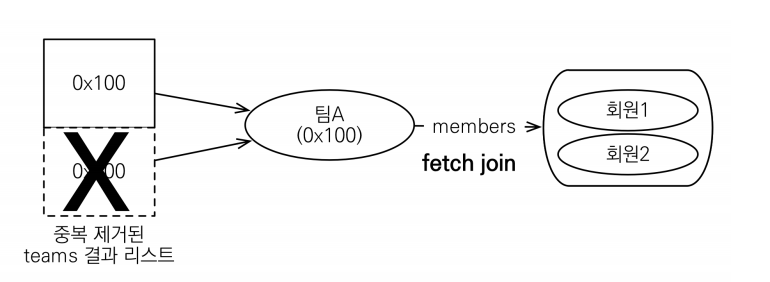
- 일반 조인
- JPQL은 결과를 반환할 때 연관관계를 고려 X
- 단지 select 절에 지정한 엔티티만 조회
- 페치 조인
- 연관된 엔티티도 함께 조회(즉시조회)
- 객체 그래프를 SQL 한번에 조회하는 개념
- fetch 조인 대상에는 별칭을 줄 수 없다.
- 하이버네이트는 가능하지만 가급적이면 사용하지 않는게 좋다. -> 하이버네이트가 허용하는 이유는 아래 따로 작성했다.
- fetch 조인은 나와 연관된 것들을 다 끌고 오겠다는 뜻이다. 대상에 별칭을 주고 그것을 활용해서 where문을 통해 몇개를 걸러서 가져오고 싶다고 한다면 fetch조인으로 접근하는게 아니라 그냥 따로 조회해야 한다. jpa에서 의도한 설계는 .을 통해 객체 그래프를 이어나간다면 모든 것에 접근할 수 있어야 한다. 그런데 fetch join에서 대상에 별칭을 주고 where로 데이터를 걸러서 가져온다면 어떤 것은 접근하지 못하게 된다. 객체 그래프라는 건 데이터를 다 조회한다는게 의도된 설계이다. 따라서 절대로 fetch 조인 대상에는 별칭을 주면 안된다. 따라서 페치 조인의 대상을 where문과 on절에서 사용할 수 없다.
- 둘 이상의 컬렉션은 fetch 조인 할 수 없다. -> 하나의 컬렉션과만 fetch join이 가능하다
- fetch join을 둘 이상의 컬렉션과 하게 되면 곱하기 곱하기가 되어 데이터의 정합성이 맞지 않는다.
- 컬렉션을 fetch 조인하면 경우에 따라 페이징 API를 사용할 수 없다.
- 일대일, 다대일 같은 단일 값 연관 필드는 fetch 조인해도 페이징 API 사용 가능
- 이외의 경우는 fetch 조인하게 되면 데이터가 뻥튀기 된다. 이 경우 하이버네이트는 경고 로그를 날린다. 따라서 페이징 API 사용 불가능하다고 보면 된다.
- 이외의 경우에도 페이징을 사용해야 한다면 X대일로 쿼리를 반대로 날리거나 fetch 대신 @BatchSize를 사용하면 된다.
반대로 날리기
// 일대다 fetch 조인 -> 페이징 API 사용시 문제 발생
String query "select t from Team t join t.members";
List<Team> result = em.createQuery(query,Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();
// 해결 -> 반대로 날리기 -> 다대일로 페이징 문제 없음
Strint query = "select m from Member m join m.team"batchsize 사용
컬렉션인 경우에는 바로 위에 @BatchSize를 붙여주면 되고, XXToOne 관계에서도 사용하고 싶다면 One쪽의 클래스 에 붙여주면 된다.
// 일대다 fetch 조인 -> 페이징 API 사용시 문제 발생
String query "select t from Team t join t.members";
List<Team> result = em.createQuery(query,Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();
// 애초에 fetch 조인 사용하는 목적이
// 실무에서는 Lazy로 두는데 경우에 따라 프록시로 땡겨온 엔티티를
// 계속 사용해야 하는 경우라면 N+1 문제 때문에 한번에 땡겨오려고 fetch 조인을 사용한다.
// BatchSize를 사용하면 fetch 조인을 사용하지 않고 N+1문제를 해결 가능
// BatchSize를 이용하면 Team을 불러오면 일단은 프록시로 Member가 들어온다.
// 그런데 Member을 조회하려는 시점에서 하나만 가져오는게 아니라 BactchSize만큼의
// team에 있는 Member을 in쿼리로 한번에 가져온다.
// size가 100이면 team 100개에 대한 members를 쿼리 하나로 가져온다고 보면 된다.
public class Team{
@BatchSize(size=100)
@OneToMany(mappedBy="team")
private List<Member> members = new ArrayList<>();
}
String query "select t from Team t";
List<Team> result = em.createQuery(query,Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();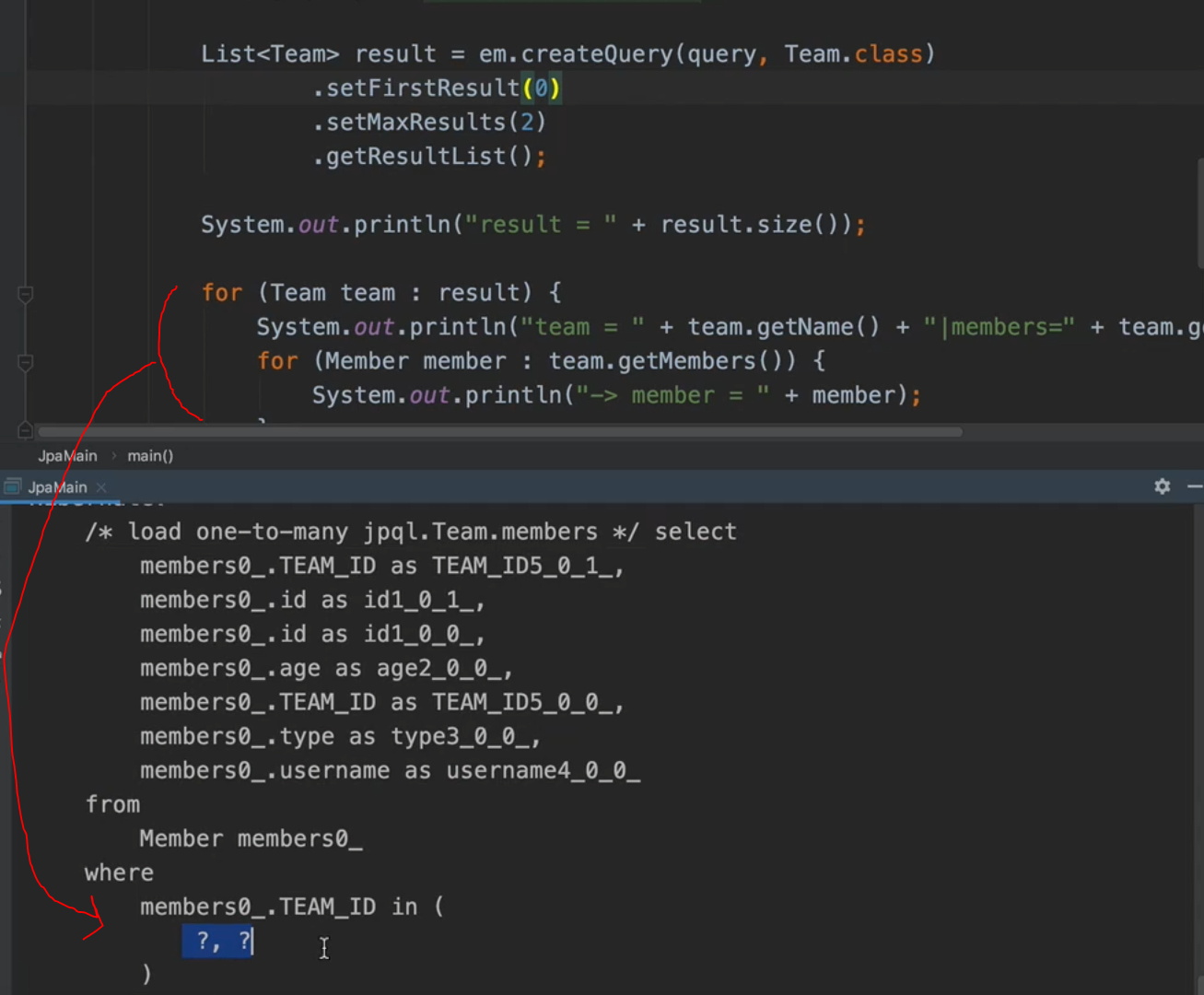
Team을 가져올 때 member는 Lazy 로딩 상태이므로 일단 프록시를 땡겨온다. BatchSize 옵션을 걸어주면 프록시가 첫 사용될 때 in 쿼리문으로 size만큼 땡겨온다. 만약 size가 100이면 한 번에 team 100개에 대한 members를 in쿼리로 딱 한번에 땡겨오는 것이다. 보통은 @BatchSize 애노테이션을 일일이 붙이지 않고 글로벌 세팅으로 가져간다. 아래처럼 세팅을 해놓으면 애노테이션을 안붙여도 된다.
<property name="hibernate.jdbc.default_batch_fetch_size" value="100"/>[참고 링크 ]
Team과 Member가 Team이 일 Member가 다 의 관계일 경우로 가정하고 살펴보자.
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member1 = new Member();
member1.setUsername("m1");
member1.setTeam(team);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("m2");
member2.setTeam(team);
em.persist(member2);
em.flush();
em.clear();
List<Team> result = em.createQuery("select t from Team t join fetch t.members m where m.username = 'm1'", Team.class)
.getResultList();
for (Team team1 : result) {
System.out.println("team1 = " + team1.getName());
List<Member> members = team1.getMembers();
for (Member member : members) {
System.out.println("member = " + member.getUsername());
}
}
// 실행결과
// team1 = teamA
// member = m1실제로는 team1에는 m1과 m2가 있어야 하지만 위와 같은 쿼리를 작성하면 결과가 m1만 나오게 되어 객체의 상태와 DB의 상태 일관성이 깨지게 된다. 따라서 잘못된 사용이다.
Select m from Member m join fetch m.team t where t.name=:teamName하지만 위와 같은 쿼리는 조회된 회원과 db와 동일한 일관성을 유지한 팀의 결과를 갖고 있으므로 사용이 가능하다. 위와의 차이점을 보자면 fetch join 대상이 일에 해당한다는 점이다. 항상 그런 것은 아니지만 이것을 고려해서 별칭을 조건문으로 가능한지를 판단해보면 좋을 것 같다.
Member와 Category를 다대다 관계라고 가정하고 일대다 다대일 관계로 풀어내서 만든 엔티티를 MemberCategory, Member와 Membercategory를 양방향 관계라고 해보자. 이 상태에서 Member를 조회하면서 MemberCategory를 같이 땡겨오면서 MemberCategory의 Category까지 한번에 땡겨오고 싶다고 하면 다음과 같은 쿼리를 작성할 수 있다.
select distinct m from Member m join fetch m.memberCategory mc join fetch mc.categorymember와 memberCategory는 일대다 관계이므로 fetch join에서 데이터가 뻥튀기 되니 distinct를 명시해줘야 한다.
정리
- N+1 문제 해결을 위해 fetch 조인과 BatchSize를 사용
- fetch 조인
- 일대일, 다대일의 경우 페이징 API 사용 가능
- X대다 경우 데이터 뻥튀기로 페이징 API 사용 불가
- X대다의 경우 데이터 뻥튀기 발생 -> distinct로 해결
- BatchSize
- X대다의 경우 데이터 뻥튀기로 페이징 API 사용 불가에 대한 해결책
- 가지고 있는 엔티티를 Lazy로 땡겨오지만 첫 프록시를 사용하는 시점에 BatchSize만큼의 데이터를 in 쿼리로 땡겨옴
- fetch 조인
- fetch 조인은 객체 그래프를 유지할 때 사용하면 효과적
- 참고로 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면, fetch 조인 보다는 일반 조인을 사용하고 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적이다.
- 조회 대상을 특정 자식으로 한정
// jpql
select i from Item i
where type(i) in (Book,Movie)
// sql
select i from i
where i.DTYPE in ('Book','Movie')type이 dtype으로 바뀌어서 쿼리가 나간다.
- 자바의 타입 캐스팅과 유사
- 부모 타입을 특정 자식 타입으로 다룰 때 사용
- from, where, select 절에서 사용 가능
// jpql
select i from Item i
where treat(i as Book).author='kim'
// sql
select i.* from Item i
where i.DTYPE = 'Book' and i.author ='kim'부모타입을 자식타입으로 다운 캐스팅해준다고 보면 된다.
- JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키값을 사용한다.
// jpql
// m이나 m.id를 넣으나 똑같이 동작함
select count(m) from Member m
// sql
select count(m.id) as cnt from Member m
// 기본 키 값 사용
// where에서 m.id 로 바꾸고 파라미터로 memberId를 넘기는 것과 똑같이 동작(식별자 직접 전달)
String query = "select m from Member m where m =: member";
List<Member> result = em.createQuery(query,Member.class)
.setParameter("member",member)
.getResultList();
// sql
select m.* from Member m where m.id=?
// 외래 키 값 사용
// Member가 가지고 있는 Team도 엔티티
// 기본 키 값과 마찬가지로 식별자를 직접 전달한 것과 똑같이 동작
String query = "select m from Member m where m.team =: team";
List<Member> result = em.createQuery(query,Member.class)
.setParameter("team",team)
.getResultList();
// sql
select m.* from Member m where m.team_id=?- 미리 정의해서 이름을 부여해두고 사용하는 JPQL
- 애플리케이션 로딩 시점에 초기화 후 재사용
- 애플리케이션 로딩 시점에 쿼리를 검증
- 정적 쿼리
@Entity
@NamedQuery(
// 관례가 엔티티명.이름
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}
// 일반적인 쿼리문 사용법이랑 거의 유사
// createNamedQuery("namedQuery이름",반환 클래스)
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username","회원1")
.getResultList();벌크 연산이란 일반적으로 sql의 update, delete 문이라고 보면 된다. 예를 들어 연봉이 3천만원 이하인 직원의 연봉을 10% 인상하려고 한다. JPA 변경 감지 기능을 실행하려면 3천만원 이하인 직원의 리스트를 조회하고 연봉을 수정하고 트랜잭션 커밋 시점에 변경감지가 동작한다. 만약 변경된 데이터가 1000건이라면 1000번의 update sql이 실행되는 것이다. 벌크 연산을 사용하면 1000번의 쿼리가 아니라 한 번의 쿼리로 해결할 수 있다.
- 쿼리 한 번으로 여러 테이블(엔티티) 로우 변경
- executeUpdate()의 결과는 영향받은 엔티티 수 반환
- UPDATE, DELETE 지원
- INSERT(insert into ... select) 하이버네이트에서 지원
// 영향받은 엔티티 수 반환
// 파라미터 설정 가능
int resultCount = em.createQuery("update Member m set m.age=20")
.executeUpdate();벌크 연산은 영속성 컨텍스트를 무시하고 바로 데이터베이스에 직접 쿼리를 날린다. 따라서 벌크 연산 수행 후에는 반드시 영속성 컨텍스트를 초기화 시켜줘야 한다.(em.clear 등을 통해) 초기화 시켜주지 않으면 DB에는 이미 값이 업데이트 되었지만 영속성 컨텍스트에는 업데이트 전에 값을 가지고 있다. 따라서 이 상태에서 값을 사용하면 영속성 컨텍스트에 있는 값을 가져와서 사용하게 되므로 문제가 생긴다. 또는 애초에 영속성 컨텍스트에 값을 넣지 않고 벌크 연산을 먼저 수행하면 문제가 없다.
참고로 em.createQuery로 query문 날리기 전에 자동으로 flush가 나가므로 이전에 영속성 컨텍스트에 있던 쿼리는 쿼리문 실행 전에 나간다. 따라서 벌크 연산 후 영속성 컨텍스트를 초기화시켜줘도 문제가 없다.