Discussion: operator structure for Druid queries? #11933
Comments
|
That smaller stack trace definitely does seem nicer, I looked through the prototype branch and, honestly, wasn't able to fully wrap my head around the difference just from trying to dive into the code that was done. From your description (and the stack trace) it looks like it's a totally different implementation that might be ignoring the Toolchests and Factories, but it seems like it's still using those? Once I found the Honestly, the more I think about it, the more I think that the reason your stack trace is so much cleaner is because your Operators aren't using generic map/concat type operations but instead all of the logic is bundled together into each class which are implementing the Iterator interface. If someone were to implement the proposed Operators by doing, e.g. a So, going back to your description, in general, I think that you can actually think of the current All that said, I could be missing some major and I don't think there's any love for any specific way of writing the code. If things can be better, let's make them better. Some of the high level concerns:
Depending on which understanding of the proposal is actually correct, the path to introducing the changes in the "safest" possible manner will be different. Rather than speculating on all of the paths, it probably makes the most sense to come to a conclusion on what is actually different about the proposal as that is the primary input into which path to implementation makes the most sense. Just to summarize, I think getting to that understanding of what is different can probably come from answering two questions:
|
|
@cheddar, thanks for the comments. I'm impressed that you dug deep into the code! The issue description is kind of high level because I didn't really expect folks to dive in as far as you did. So, let's go into the details. I suppose what we really need is a table that maps the existing concepts to the corresponding operator concepts. I'll add that at some point. We'll explain the prototype and answer your questions. First, let's address the main question, which is... Why Are We Considering This?Let's answer this first since it motivates everything else. There are several reasons as outlined in the proposal. The first thing to note is that the operator concept is not a new idea: it is the standard approach in a bunch of other tools (Spark, Drill, Presto/Trino, Impala, and many others.) So, we're trying to draft off of what others have learned and see if we can apply some of that learning to Druid.
Again, the above isn't something I made up, or am suggesting as a "good idea." The above is a summary of what other tools have experienced. The point of this discussion is: can we get some of this operator goodness for Druid? What About the Current Code?An implicit assumption of this proposal is that the operator model provides benefits. You ask a good question: doesn't the current code provide those same benefits? This is tricky: the goal here is not to critique that code: it works and has worked for many years. It will probably work well for many more. All I can really say is that, as a newbie coming from competing tools, the query pipeline code in Druid seems more complex than it needs to be. Obviously, all working code is complex (as observed by someone many years ago.) However, is that complexity necessary, an essential part of solving the problem at hand, or is it incidental, just happens we've chosen a complex way to solve the problem. The gist of this proposal is that 1) query engines are complex, 2) the Druid code is more complex than other similar code bases for the same task, and that 3) there may be benefits from refactoring to a simpler solution so we reduce unnecessary, incidental complexity. That's what this issue asks us to consider and discuss. |
|
Let's discuss some of the prototype bits you mentioned to give context for anyone else reading along. Prototype OverviewYou found the key abstraction: the Once we have an Operators are entirely run-time concepts: they just start, process batches, and close. The planner works roughly like the In the prototype, the decisions happen in the planner. The planner has functions to create the corresponding operator given the child (input) operator(s). There is basically one method in the prototype planner for each Note that, when we say "plan time" and "run time" in this proposal we mean in the Druid context: both occur as part of a REST message to run a query. The prototype uses a "shim" to adapt the A goal of the prototype was to avoid changing any existing code. So, the "shim" just diverted query construction to the new mechanism, only for scan queries, and only when enabled. To avoid changing existing code, some bits were replicated. For example, the There are two more minor bits. The fragment runner, which ensures operators are closed whether the query succeeds or fails. The |
AnswersWith that background, let's answer the questions you raised. Different implementation: The prototype is a refactoring of the existing scan query code, as described above. Since the planner works differently than how the toolchest, etc. works, it was not possible to directly use those in the prototype. Instead, the prototype uses those parts which work as-is, and made a refactored copy of those bits that need to change to work in the context of the new planner. Basically, those parts, such as Operator vs. Sequence: Clearly, the By contrast, the Which is "right"? Neither. The question is, which is fastest and simplest. Hence this discussion. Semantic difference: To see the difference in the two approaches, one has to pop up from the code to see the design. We've discussed the design above. The proposal separates planning and execution. It also combines a pile of sequences, yielders, lambdas, closures and other knick-knacks into a simple, clean operator structure. Why? For the reasons above: simpler to understand, easier to test, easier to debug, easier to reuse. Said another way, both the current design and the prototype run a scan query. In that sense they are the "same." The proposal suggests how we can do the same work with far less code and complexity by leveraging the idea of accepting that a query is a pipeline of stateful operators. The current code tries to follow the functional programming model to be stateless. But, since queries are, in fact, stateful, the code becomes very complex: state is often added via the "back door" of closures. The operator model accepts that queries have state and manages that state cleanly. Stack trace is so much cleaner: you are on the right track. The reason the stack trace is simpler is that, at runtime, we do only the required work and no overhead, no unnecessary abstractions. A limit operator counts its rows and says its done when its done. That's all. That can be implemented right in the operator. Since operators are very light weight, no reason to have multiple layers of abstraction. The stack trace is smaller because operator are the KISS solution for queries. Yes, if someone were to implement operators by adding multiple layers of abstraction, then it would be ugly. The point is, those layers are not necessary. Every operator has one very simple task: get some input, do a transform, produce an output. If you want to do two different things, create two operators. We can do this because the planner will choose wisely about which operator to include: we don't include operators we don't need. Operators don't have to be two things. The result is a very simple runtime stack. And, as we've all learned, the name of the game in performance is to minimize the amount of code in the per-row path. WrappingSequence, etc.: You point out the many uses of wrapping sequences. Yes, those are a pain. Many seem to want to do something on sequence start or end, but end up having to insert themselves into the per-batch stream to do that. (We're really in the weeds now.) To address this, the Could we do the same with the current code? Sure, its software after all. Would doing so achieve the other objective? That’s the discussion we’re having. QueryToolChest and QueryRunnerFactories are extension points: Absolutely. This is modeled, in the prototype, by the Swapping out the underlying implementation in-place creates a relatively high burden: You have hit on the major discussion point. The reason that the prototype is a refactoring of the scan query path is to minimize the risk of breaking anything. Of course, the scan query is far simpler than the other types. We'd want to investigate if those others lend them selves to the same ease of refactoring as the scan query. One answer is testing. Let's assume we have good tests for each query type. Then, we simply rerun those tests to ensure things work. This worked quite well when we made these kinds of changes in Drill and Impala to "modernize" some bit of code or other. The first step of the refactoring here replaced just the segment reader. Existing unit tests passed just fine. Then, as each To ensure safety, if we were to proceed, I'd suggest working step-by-step, in whatever sequence makes sense. First rely on unit tests. Then run integration tests. Further, for a while, provide an option to choose the "classic" or "operator" path. That is possible because the refactoring will move code to new classes, leaving the original ones unchanged. Still, risk reduction is a key question: the thought is to take on some risk now to reduce risk later. (That is, we get simpler code, perhaps faster execution, easier extensions, easier testing later, by taking on a bit of risk today.) This is a what we should discuss. The proposal is just a stylistic adjustment to the current code without any new or different semantic constructs being added: Good point. The idea is first to align ourselves with best practices: simple code, easy to test, etc. Then, we can add actual functionality (read Parquet files, materialized views, multi-level DAGs, integrate Druid with other query engines.) If we were to propose moving to operators AND doing any of the above, the proposal would be even larger! There is more than style to this proposal (see above.) This is a different functional way to achieve the goal. In the same way that Druid is not a stylistic difference from Oracle, Teradata, Hadoop or Hive: it is functional difference, and that is what makes Druid successful. In the same way that segments are not just a different style for storing rows (they are a faster way), operators are a faster way to run a query than the current implementation. Both work, operators just have proven to be simpler and faster in other tools. So, another good topic for discussion is: where is Druid going? If we want extensions, let's make extensions super simple. If we want more query types, let's make that super simple. If we want more testing, faster development, easier debugging, let's use techniques which have worked well elsewhere. Some parts of the physical plan cannot be determined until the query reaches the segment. Sure. That's called "schema-on-read." A filter operator (say), needs to filter one way if a given column is a string vs. an integer. Drill works that way. However, the filter operator itself can be determined at plan time. (Yes, I know filter is a poor example because of how Druid works, but let's run with it.) Another example is a merge. If we read two or more segments, we have to merge them. If we read one, no merge is needed. This kind of thing can be optimized by inserting a merge which, if it finds it has only one available input, just returns that input with no merge. In reviewing the scan code (which, as noted, is a super-simple query type), most decisions can be made in the plan step, with just a few being reactive at runt time. (Did a segment return any rows? Did it return two cursors or just one? Can we skip a segment because we've reached our limit?) These rather simple reactive decisions were just made part of the operator. Understanding of what is different. To summarize: focus on the goal: leverage proven techniques to gain benefits such as code simplicity, faster per-row execution, easier testing, etc. What are those proven techniques? The operator pipeline model, with the pipeline created by a planner (in Druid's case, a "just in time" planner derived from the To be very succinct: Druid has a query pipeline. Query pipelines have proven be simplest when they use a Volcano-style operator structure. The current code shows that functional programming techniques, while very helpful elsewhere, result in code that is more complex (and likely shower) than the operator technique when used to implement a query pipeline. |
|
@cheddar kindly walked me though the current design. (He is the original author.) Updated the issue description with the result. In a nutshell, he points out that the code complexity we see to day may be the result of over-eager use of anonymous inner classes and closures, not a result of the |
Prototype Based on SequencesPer a suggestion by @cheddar, did an experiment using the The result is a limit sequence, and a base transform sequence. Didn't refactor all of the scan query, just did the scan query limit operation. This one little experiment suggests that, in fact, it probably is the First, let's describe the new prototype, then later comments will outline what was learned. After fiddling about, the simplest implementation was to use the previous operator version as the basis for the new prototype. The reason is that the operator code is about as simple as one can make a limit operation. That code was refactored from the original limit iterator by replacing the original Then, to turn the prototype limit into a The result is that our limit sequence is a simple iterator over batches (doing the needed counting, and truncating the last batch when needed), along with a bunch of extra overhead to implement the In fact, it is probably simpler to split these two concepts, as in the first prototype: an operator is fancy iterator: super simple. If you want a sequence, just wrap the operator in a standard sequence wrapper class. The result would probably be simpler than the current prototype: we'd use composition rather than the inheritance used to convert the limit into a sequence. We can now see why the current Druid limit code is already close to optimal, given the This also suggests why Druid uses so many extra knick-knacks at runtime. One often needs an iterator-like thing that does the work, a sequence wrapper around the iterator, and a yielder/yielding accumulator wrapper around the sequence. For. Every. Transform. In short, the core limit operation is simple. It becomes bogged down, however, when it has to implement the The conclusion from this little exercise is that, while our use of inner classes and closures is a bit extravagant, the extra layers required by the |
Resource ManagementA conversation with @cheddar revealed one of the key goals of the As @cheddar observed, an operator is little more than a closable iterator, with some goodies tacked on, and closeable iterators are resource leaks waiting to happen. There is more than one way to handle the problem, however. As it turned out, Drill originally did the "every operator has to ensure it is closed" thing. It was a complex mess. (We didn't have The operator prototype learned from Drill's experience. The operator "DAG" is managed by a fragment runner which knows of every operator in the DAG, and which ensures that, come hell or high water, the operators are closed. The result is that the data path ( So, operators solve the "close problem" while providing a super-simple (and efficient) data path. This is why the pattern is widely used in many projects. This is reflected in the stack traces above: the current code has extra layers, in part, to ensure that we use accumulators that can close resources. The operator stack is simpler because resource management sits on the side, discretely out of sight of the data path. We could certain use the same trick with a |
Battle of the AbstractionsThe key question this issue raises is: can we make Druid's query code simpler while also making it faster? Is there benefit to simpler/faster code? And (to a lesser degree) what are the trade-offs? We've claimed that operators are simpler because they are the result of many decades of people trying to find what works for a query DAG. They learned to simplify the data path as much as possible. It turned out to be handy to build on the iterator abstraction. To be fair, we should look as closely at the It seems that a The real question is: within a native query, does every transform follow this same pattern? Does a limit dip into the sequence offered by its input? Does a sort dip into its input and pull out a few items? Unfortunately, only the root of a DAG is in a position to do so. All other elements need to grab an input, do their transform, and pass along the results. In a query, the reader returns only the needed data (this is a key part of the Druid magic). All other transforms must process that data, even if the number of rows is large. Perhaps some transforms can throw out rows ( That is, most transforms must yield intermediate results. So, enter the The This is all great if we mostly do aggregation, and have just a few sequence types. However, all the extra code becomes a burden when we want to do non-aggregate transforms such as limit. We seem to have many, many different sequences, so we pay that complexity cost over and over. All this seems to suggest that as a base abstraction, an iterator (operator) is simpler. It is straight-forward to build aggregation on top of an iterator when needed, but more tedious to build an iterator on top of an aggregator. Further, we end up using an iterator anyway just to build the aggregator, which we then wrap to get back an iterator. The KISS principle would suggest that, if both can do the same job, go with the simpler one. |
Migration Approach@cheddar asked another great question: Suppose we wanted to consider the operator approach. How would we do it without breaking things or hurting performance? To prove the operator concept, the full prototype presents a "whole enchilada" solution: convert sequences to operators, and convert query runners into a planner. However, this is far too much work to do in one go in the production code. What steps might we consider that produce value at each step? We'd start with refactoring each query runner when convenient, such as when we need to work in that area anyway, leaving the rest unchanged. Test each step. Once all are converted, consider refactoring the query runners to create an integrated planner. Yet another prototype shows how this could be done. Refactor Query RunnersAt first we only focus on individual query runners and their sequences. Today, the query "DAG" looks a bit like this: Where the query runner does its thing in the ad-hoc code, then wraps it in a sequence. The ad-hoc code is often in the form of anonymous inner classes with state passed in via closures. The result is that the code is a bit hard to understand, debug and test. So, the first step is to fix that by applying the operator pattern within each query runner: Aside on naming: these notes use the term "operator" for the bit that does the actual row/batch transforms since the term "relational operator" is common in the literature. However, it doesn't matter what we call it: "sequence transformer", "data munger" or whatever. Compared with the ad-hoc code, an operator:
In practice, the yielder abstraction is a bit awkward to use as an input iterator. So, add another wrapper: Where the "shim operator" makes a yielder look like an operator, and the "transform operator" is the "guts" of what the query runner does. A The new prototype uses the operators from the first prototype, and adds the needed adapters. Then, rather than wholesale restructuring of the query runners into a query planner, this prototype just fits operators into the existing query runner structure. We create a replacement query runner for the part of the scan query that handles limit and offset. Then, a bit of a hack is added so that the Now that the operators are named classes with few dependencies, it is easy to unit test them using a mock input source. Fragment ContextTthe sequence protocol to ensure resources are released. The next step is to begin to transfer that task to a "fragment context": the thing which manages the fragment of the query running on this one node. At this point, the fragment context is redundant, but we'll need it for the next step. We define a fragment context as a registry of operators. The fragment context is passed into each query runner. The new prototype does this with the help of the Some hackery was done to handle the fragment context, at least for native queries. (Again, not elegant, just a proof-of-concept.) The fragment context, for queries, is a bit like Druid's Optimize Away SequencesAt this point, our little section of the scan query "pipeline" looks a bit like this: Since operators don't care where their input comes from, as long as it looks like an operator and delivers the right data, we can optimize away the middle bits above. When we create that shim, we check if the input sequence is "backed" by an operator. If so, we return that operator instead of creating the shim, resulting in: Which then gives us that compact stack shown in the original post (at least for these two operations). Logically, the sequence is still present, and a query runner that wants to use a sequence can do so. But, if adjacent query runners both create operators, the sequence just melts away, leaving a cleaner, more efficient pipeline. That fragment context we added above ensures that, despite operators being a dreaded "closable iterator", they all are guaranteed to get closed at the completion of each fragment (query running on one node). Query Runners Create OperatorsImagine that the entire query stack is eventually modified to follow the above pattern. Each query runner creates an operator, wraps it in a sequence, which is then unwrapped by the "upstream" operator created by the upstream query runner. At this point, we can just discard the sequences and let each query runner return an operator instead. Any query runner that wants a sequence can have one: it just adds the operator-to-sequence shim. The present prototype does not show this (not all query runners are converted: just one of them), but this gives an idea of where we could go over time. |
|
Finally got some time to finish up the approach which @cheddar suggested. For the scan query, each The code uses the trick mentioned above: if an operator only does things on open or close, then it removes itself from the per-row/batch path. Example: the thread renamer and the segment reference counter. Further checks within each runner avoid creating an operator when the operator would do nothing. Example: omit the finalize results operator if the transform is the identity. The resulting "plan time" code (the part which the The resulting stack, when stopped at an innermost Would be nice to abstract away that top sequence/yielder as well which is used to stream results to the client. Query (which is kind of silly): SELECT "__time", "page", "delta"
FROM "wikiticker"
WHERE "__time" >= TIMESTAMP '2015-09-12 13:00:00'
AND "__time" < TIMESTAMP '2015-09-12 15:00:00'
AND "channel" = '#en.wikipedia'
AND "isRobot" = 'false'
AND "page" LIKE 'User talk:D%'
LIMIT 10The next step, when I get a bit more time, is to time each approach for a scan of a large chunk of Wikipedia. That will tell us if the simpler stack does, in fact, translate into faster execution. |
|
Did a bit of performance testing. Created a mock storage adapter and mock cursor that simulates a Wikipedia segment, but just makes up 5M rows of data. Compared performance of operators and yielders. In the default mode, the scan query uses the list-of-maps format, and map creation takes a long time (about 1/4 of the run time), so switched to a compact list. As it turns out, under this scenario, with 245 batches, the operators and yielders take about the same amount of time: about 490 ms average over 100 runs, after 100 runs of warm-up. The 245 batches does not place much emphasis on the parts that differ: the per-batch overhead. The default batch size is 5 * 4K rows, so reduced batch size to 1000 rows, so we get 5000 batches. With this change, the difference in the two approaches becomes clearer. Again, times averaged over 100 queries: Operators: 499 ms. This shows that the reduced number of function call levels in the operator solution takes 82% of the time of stack of sequences and yielders doing the same work. To be fair, in a normal query, testing suggests that the call yielder stack overhead is lost in the noise of the actual work of the query. So, while operators might be a bit faster, the real win is in the code simplification, and the ability to compose operators beyond what the query runners can do today. FWIW, the setup is an ancient Intel I7 with 8 cores, running Linux Mint (Ubuntu), Java 14. A python client sent a native scan query to a historical running in the IDE. The query itself selects three columns from one segment with no filters. This is not the optimal performance setup, but all we're interested in is relative costs. |
|
Work has been ticking away in the background. PR for converting two native queries to use the operator structure: #13187. |
|
Hi @paul-rogers , your operator implementation is based on volcano model right? Not sure if you have investigated the ClickHouse's query execution engine which is based on PUSH model. This model is faster than the PULL-based volcano model. I think it is worth taking a look. |
|
@FrankChen021, thanks for the link & great question! Yes, the proposal is based on the pull model within each fragment. When we get to distribution (i.e. "multi-stage"), we envision a push model between fragments. That way, we get the simplicity of the pull model with the performance of the push model. To explain this a bit more, let's remember that, in a distributed system, we don't run the entire operator DAG single-threaded: we slice the query into fragments, perhaps on the same node, more typically across multiple nodes. (Druid's scatter/gather is the simplest possible distributed DAG: it has two slices.) The Drill version of this idea is explained here. Within a fragment, operators work using the Volcano pull model. The code for this is quite simple as is illustrated by the operators in the PR. Each operator is stateful: it does the work to return one row (or, more typically, one batch) reading as many input rows as it needs. It is trivial to order the inputs, starting them one by one as in a union. The push model is common in search engines, I understand. However, it becomes quite complex once one has multiple branches (i.e. joins, unions, etc.). Suppose we have a single-thread DAG with a join. We've got two leaves, both of which want to push data up to the join. But, a hash join, say, wants to first read the build side, only later the probe side. This is trivial with the Volcano model, but quite messy with pull. As it turns out, I once worked on a query engine that used the push model: it was, indeed, quite complex. Far more complex than the Volcano model of Drill and Impala. The benefit of pull is concurrency: each fork in the DAG pretty much demands to be run in a separate thread (or process or node), with some kind of queue-based exchange between operators. If only Druid were written in Go: we'd get the pull model for free! Otherwise, we get this benefit in the Volcano model by introducing distribution. But, what we distribute are slices of operators, not individual operators. Each running slice is a fragment. (Scan slices, for example may be replicated dozens or hundreds of time, each of those copies is a fragment.) The way we visualize this idea is with a query profile. Here is a typical one from Drill. In Drill and Impala, fragments use the push model. Leaf fragments (typically scans) start running immediately and push results to their downstream fragments, pausing if the receiver queue fills. For example, in that hash join example, the build side scan fragment will pump batches to the join which builds the hash table. The probe side scan will get blocked quickly because the hash join won't read from the receive queue until the hash table is built. One can turn the Volcano push model into a pull model simply by making all fragments contain a single operator. This is, in fact, what MSQ does with its frame processors: each frame processor does a single operation. In practice, however, such a design incurs unnecessary overhead. The operator-per-fragment model is great for "big" operators such as distributed sorts, distributed aggregations, etc. (And for the native queries which MSQ runs in its frame processors.) We will find, however, that other operators are "small" and don't provide benefit when run as a separate fragment: the overhead becomes unproductive. For example, a limit, filter, or projection on top of a join: might as well do those in the same fragment as the join itself. You pointed to ClickHouse. Consider this image. In the proposed design, the image would normally be inverted (root at the top). There would likely be exchanges where branches converge, which is a logical place to slice the DAG into fragments. The "Expression", "Project", "Extremes" and "Limit Checking" would likely be combined into a single fragment. In short, the proposed design (borrowed heavily from other projects) proposes to combine the simplicity of the Volcano pull model for individual operators (i.e. within a fragment), with the benefits of the push model between fragments. Does this make sense? |
{kind=link}
|
Thanks you @paul-rogers for the detailed explanation. I have to admit that the push model is much complex to implement. And unlike the volcano models clear call stack, it's hard to track its execution flow especially if it's executed in parallel. Maybe current proposal is a much easier way for us to achieve DAG-based query engine. |
|
This issue has been marked as stale due to 280 days of inactivity. |
|
This issue has been marked as stale due to 280 days of inactivity. |
|
This issue has been closed due to lack of activity. If you think that |
This issue seeks to spur discussion around an idea to make the Druid code a bit easier and faster: borrow ideas from the standard operator structure for the historical nodes (at least) to simplify the current code a bit.
Druid's query engine is based on a unique structure built around the
QueryRunner,Sequence,Yielderand related concepts. The original design is that aQueryRunnercreated (plans) what to do, and returns aSequencewhich does the work. Over time, the code has added more and more layers ofQueryRunners. Also, the code adopts a set of clever functional-programming ideas which uses closures and anonymous inner classes to manage state. The result evolved the original, simple concept into the complex, tightly-bound code we find today.Here, we illustrate that options exist to simplify the code by observing that the resulting Druid code is far more complex than that of similar tools that use the well-known operator structure. (We assume that the advantages of simple code speak for themselves.)
This is not (yet) a proposal. Instead, it is meant to start the conversation.
Background
Most query engines use a structure derived from the earliest System R architecture and clarified by the well-known Volcano paper. The idea is that a query is a sequence of operators, each of which reads from its input, transforms the data, and makes that data available to the output.
When used in a query with joins, the result is a DAG of operators. When used in a query without joins, or in an ETL pipeline, the result is a simple pipeline of operators. For example:
The Volcano paper suggested a specific way to implement the above: each operator is, essentially an iterator: it provides a
next()call which returns the next record (or, in many systems, the next batch of records.) When implemented in the Volcano style, the code is relatively simple, easy to debug and easy to instrument.The solution also works for parallel execution. For example, the Apache Storm project runs each operator concurrently. Apache Drill and Apache Impala parallelize "slices" (or "fragments") of a query (where a slice/fragment is a collection of operators.) Presto/Trino seems to try to get closer to the Storm ability to run (some?) operators concurrently.
Operators are typically stateful. An aggregation maintains its running totals, a limit maintains a count of the records returned thus far, and an ordered merge maintains information about the current row from each input. Because operators are stateful, they can also maintain instrumentation, such as row/batch counts, time spent, and so on. Many products display the resulting metrics as a query profile (proposal for Druid).
Operators are quite easy to test: they are completely agnostic about their inputs and outputs, allowing simple unit tests outside of the entire query system. Quick and easy testing encourages innovation: it becomes low-risk to invent a new operator, try to improve an existing one, and so on.
In typical SQL systems, the query planner creates the operators (or, more typically, a description of the operator.) The Calcite planner does that in Druid: it creates an execution plan with "logical" operators (that is, descriptions of operators.) Here, however, we'll focus on Druid's native queries which use a different approach to planning.
Most systems provide joins as a fundamental operation. In this case, the structure becomes a tree with each join having two inputs. The operator structure has proven to work quite well in such structures.
Druid's
SequenceAbstractionDruid's query stack is build around two fundamental abstractions:
QueryRunnerwhich, despite its name, plans how to return a query by defining a...Sequencewhich represents the result set from a query runner, and performs the actual data reading, transforms, etc.Here we focus on the way that the
Sequenceabstraction has evolved. First, let's compare how the two concepts do their work:QueryPlanner.run()accumulate: pass in something to consume rowsnext()close()on each operator.At a high level, the two concepts are somewhat similar (which is why we can entertain refactoring from one to the other). The challenge seems to be how the code evolved to realize the
Sequenceprotocol. (Note that were we say "row" above, we also include batches of rows.)Two main differences that appear to cause extra complexity is 1) the
Sequence.accumulate()vs.Operator.next()protocol, and 2) how resources are released, theSequencecleanup vs.Operator.close()protocol.A data pipeline consists of a number of operations chained together. Generally, only one has the luxury of a loop which reads all the rows and does something with them. (In Druid, this is the
QueryResource.) All the others need to get one or rows from its input, apply some transform, and return the result to its output (caller.) TheOperatorabstraction models this directly: eachOperatoris given an input to read from, and offers anext()method to return the next result.To achieve the same with the
Sequenceabstraction, theYielderclass was added. AYielderis an "adapter" that converts theSequence.accumulate()method into something a bit closer to an iterator. (With a few notable differences.) TheYielder, in its simplest form, is simply a class which performs the same function as theOperator.next()protocol.Druid's Query Stack
While the above protocol differences are important, they turn out to be much less critical, in practice, than the way in which the
Sequenceabstraction is actually used. TheOperatorabstraction pretty much demands that each operator be a named class that manages its state. The result is that operators have minimal dependencies, can be unit tested, mixed-and-matched, and so on. As @cheddar, points out,Sequences could be defined the same way. The key challenge is that they are not that way today.Much of the current code (at least in the scan query examined thus far) uses a functional programming approach in which the code tries to be stateless. A
QueryRunner, despite its name, does not run a query, and so theQueryRunnerhas no run-time state. Again, as @cheddar, notes, if we think of theQueryRunneras actually being aQueryPlanner, then this makes perfect sense.State is necessary in a query pipeline and the
Sequenceabstraction would be the logical place to keep it. We could define aSequenceclass for each operation, and use member variables to manage that state, just as is done with operators. In such a case, only theaggregate()vs.next(), cleanup vs.close()protocols would be the main question. (See a note below for a prototype of such an approach.)Instead, most code defines state as variables in the
QueryRunner.run()method and passes that state into an anonymousSequenceimplementation via a closure. The result tightly couples theSequenceto theQueryRunner, making unit testing difficult. Further, since theQueryRunner, as part of planing, wants to define the input sequences, we cannot easily break this dependency for testing. Moreover, since the combinedQueryRunner/Sequenceserves one specific use case (e.g., specific inputQueryRunnerto invoke), it is hard to reuse that code for another use case.The result is far more complex than other, similar query implementations. Quite a bit of time is spent navigating the large number of code layers that result. The runtime stack is cluttered with extra "overhead" methods just to handle the protocol, lambdas, and so on.
All that said, the code clearly works quite well and has stood the test of time. The question is, can we do even better?
The Question: Operators for Druid?
This issue asks the question: could Druid be faster, easier to maintain and more extensible if we were to adopt the classic operator approach?
Part of any such discussion is the cost: does this mean a complete rewrite of Druid? What is being proposed is not a rewrite: it is simply a refactoring of what already exists: keep the essence of each operator, but host it in an operator rather than in layers of sequences, yielders, etc.
@cheddar suggests we also consider a less intrusive solution: that the current complexity is more the result of over-use of closures and less a result of the
Sequenceabstraction. It is true the operators, by design, force loose coupling. Could we also achieve that same goal withSequences? This then gives another way to analyze the situation. (See the second prototype below for the results.) As it turns out, the sequence abstraction encourages the use of many small helper classes, as we see in the code today.Summary of Possible Approach
A prototype has been completed of the Scan query stack. Scan query was chosen because it is the simplest of Druid's native query types. The general approach is this:
The
QueryRunnerimplementations already perform planning and return a sequence with the results. The prototype splits this functionality: the planner part is moved into a planner abstraction which creates a required set of operators. The operators themselves perform the run-time aspect currently done by theSequenceandYielderclasses. (See the third prototype below for a less invasive way to refactorQueryRunners.)The above approach reflects the way in which Druid does "just-in-time planning": native queries are planned during the
QueryRunner.run()call: we simply move this logic into an explicit "just-in-time" planner. That planner also does what theQuerySegmentWalkerdoes to plan the overall structure of the query.As it turns out, most
QueryRunners don't actually do anything with data: they instead do planning steps. By moving this logic into the planner, the required set of operators becomes far smaller than the current set ofQueryRunners.With planning done in the planner, the operators become very simple. For the scan, we have operators such as the segment scan, merge, and limit. Developers typically try to optimize the data path to eliminate all unnecessary code. With the operator approach, the only code in the data path is that which obtains or transforms events: all "overhead" is abstracted away.
Example
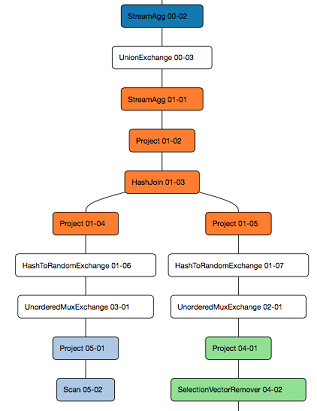
The easiest way to summarize the potential benefits of the operator approach is with an example. Here is the call stack for a scan query with the debugger stopped in the function which retrieves data from segments:
Here is the exact same query using the code refactored to use operators:
Full disclosure: the scan query is, by far, the simplest native query type in Druid. More work is needed to try the same approach in the more heavy-duty query types such as top-n or group-by.
Possible Implementation Path
Changing Druid's query execution path is a bit like brain surgery: Druid is used in production by a large number of people: we can't risk breaking they query path. Hence, we need a low-risk approach if we wanted to explore this option.
The safest option is to implement the operator approach in parallel with the current approach: enable operators via a feature flag. And, indeed that is how the stack traces above were created. A note below expands on the incremental steps we could take.
Conversion of a native query can be incremental as well. Wrappers allow an operator to act like a
Sequenceand visa-versa, allowing us to migrate one piece of query execution at a time.The development approach could thus be to tackle one native query at a time. Within each, convert one operation at a time. At each step, enable the operator version via a feature flag, defaulting to the operator version only after sufficient testing.
Potential Benefits
We've already mentioned some benefits: simpler code, a tighter data execution path, easier debugging, and easier testing. Other possible benefits include:
Summary
The operator approach has many benefits. A prototype shows that the approach works well for the native scan query. The question that this issue raises is this: is this something that would provide sufficient benefit to the Druid community that we'd want to move to a concrete proposal?
The text was updated successfully, but these errors were encountered: